Я собрал здесь некоторые не очень очевидные факты о заглавных и строчных буквах, с которыми может столкнуться программист в работе. Многие из вас переводили строки во «все заглавные» (uppercase), «все строчные» (lowercase), «первую заглавную, а остальные строчные» (titlecase). Ещё более популярна операция сравнения без учёта регистра. В мировом масштабе такие операции могут быть весьма нетривиальны. Пост построен в виде «сборника заблуждений» с контрпримерами.
Нет. В тексте могут попасться строчные лигатуры, которым не соответствует один символ в верхнем регистре. Например, при переводе в uppercase: fi (U+FB00) -> FI (U+0046, U+0049)
Нет. Некоторым буквам с диакритикой нет точного соответствия в другом регистре, поэтому приходится использовать комбинированный символ. Скажем, в языке африкаанс есть буква ʼn (U+0149). В верхнем регистре ей соответствует комбинация из двух символов: (U+02BC, U+004E). Если вам попадётся транслитерация арабского текста, вы можете столкнуться с
(U+02BC, U+004E). Если вам попадётся транслитерация арабского текста, вы можете столкнуться с 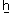 (U+1E96), которой в верхнем регистре также нет односимвольного соответствия, поэтому придётся заменять на
(U+1E96), которой в верхнем регистре также нет односимвольного соответствия, поэтому придётся заменять на  (U+0048, U+0331). В ваханском языке есть буква
(U+0048, U+0331). В ваханском языке есть буква  (U+01F0) с аналогичной проблемой. Вы можете возразить, что это экзотика, однако на африкаанс в википедии 23000 статей.
(U+01F0) с аналогичной проблемой. Вы можете возразить, что это экзотика, однако на африкаанс в википедии 23000 статей.
Нет. Есть, например, в немецком языке буква «эсцет» ß (U+00DF). При переводе в верхний регистр, она превращается в два символа SS (U+0053, U+0053).
Нет. Бывают специфические греческие буквы, например, (U+0390), которые превращаются в три Unicode-символа
(U+0390), которые превращаются в три Unicode-символа 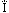 (U+0399, U+0308, U+0301)
(U+0399, U+0308, U+0301)
Нет. Вспомним те же лигатуры. Если слово в lowercase начинается с fl (U+FB02), то в uppercase лигатура превратится в FL (U+0046, U+004C), но в titlecase — в Fl (U+0046, U+006C). То же самое с ß, но с неё, теоретически, слова начинаться не могут.
Не сработает. Есть, например, диграф dz (U+01F3), который может использоваться в тексте на польском, словацком, македонском или венгерском языке. В uppercase ему соответствует диграф DZ (U+01F1), а в titlecase — диграф Dz (U+01F2). Есть ещё разные диграфы. Греческий же язык порадует вас приколами с ипогеграммени и просгеграммени (к счастью, в современных текстах такое редко встречается). В общем случае варианты uppercase и titlecase для символа могут быть различны, для них есть отдельные записи в стандарте Unicode.
Нет. К примеру, греческая заглавная сигма Σ (U+03A3) на конце слова превращается в строчную ς (U+03C2), а в середине — в σ (U+03C3).
Нет. Скажем, в большинстве языков с латиницей строчный вариант для I (U+0049) — это i (U+0069), но не в турецком и азербайджанском. Там строчный вариант для I — это ı (U+0131), а заглавный вариант для i — это İ (U+0130). В Турции из-за этого в разнообразном софте порой наблюдаются фееричные баги. А если вам попадётся текст на литовском с проставленными ударениями, то, к примеру, заглавная Ì (U+00CC), которая превратится не в ì (U+00EC), а в (U+0069, U+0307, U+0300). В общем, результат преобразования зависит ещё и от языка. Большинство сложных случаев описано здесь.
(U+0069, U+0307, U+0300). В общем, результат преобразования зависит ещё и от языка. Большинство сложных случаев описано здесь.
Здесь тоже немало подводных камней, которые вытекают из вышесказанного. Например, не сработает с немецкими straße и STRASSE (первое не изменится, второе превратится в strasse). Со многими другими описанными выше буквами тоже будут проблемы.
И это не всегда сработает (хотя и гораздо чаще). Но, скажем, если вам попадётся запись STRA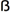 E (да, большая эсцет тоже есть в немецком и в Unicode), она не совпадёт со straße. Для сравнений буквы преобразуются по специальной таблице Unicode — CaseFolding, по ней и обе ß, и SS превратятся в ss.
E (да, большая эсцет тоже есть в немецком и в Unicode), она не совпадёт со straße. Для сравнений буквы преобразуются по специальной таблице Unicode — CaseFolding, по ней и обе ß, и SS превратятся в ss.
Вот тут согласен.
Если у кого-то не отображаются какие-то символы, напишите мне личное сообщение, я заменю на картинку.
1. Если я переведу строку в uppercase или lowercase, число Unicode-символов не изменится.
Нет. В тексте могут попасться строчные лигатуры, которым не соответствует один символ в верхнем регистре. Например, при переводе в uppercase: fi (U+FB00) -> FI (U+0046, U+0049)
2. Лигатуры — изврат, ими никто не пользуется. Если их не учитывать, то я прав.
Нет. Некоторым буквам с диакритикой нет точного соответствия в другом регистре, поэтому приходится использовать комбинированный символ. Скажем, в языке африкаанс есть буква ʼn (U+0149). В верхнем регистре ей соответствует комбинация из двух символов:
(U+02BC, U+004E). Если вам попадётся транслитерация арабского текста, вы можете столкнуться с (U+1E96), которой в верхнем регистре также нет односимвольного соответствия, поэтому придётся заменять на (U+0048, U+0331). В ваханском языке есть буква (U+01F0) с аналогичной проблемой. Вы можете возразить, что это экзотика, однако на африкаанс в википедии 23000 статей.3. Ну хорошо, но давайте считать комбинированный символ (с участием modifying или combining code points) одним символом. Тогда длина всё же сохранится.
Нет. Есть, например, в немецком языке буква «эсцет» ß (U+00DF). При переводе в верхний регистр, она превращается в два символа SS (U+0053, U+0053).
4. Ладно-ладно, понял. Будем считать, что количество Unicode-символов может увеличиться, но не больше, чем вдвое.
Нет. Бывают специфические греческие буквы, например,
(U+0390), которые превращаются в три Unicode-символа (U+0399, U+0308, U+0301)5. Давайте про titlecase. Здесь всё просто: взял первый символ из слова, перевёл в uppercase, взял все последующие, перевёл в lowercase.
Нет. Вспомним те же лигатуры. Если слово в lowercase начинается с fl (U+FB02), то в uppercase лигатура превратится в FL (U+0046, U+004C), но в titlecase — в Fl (U+0046, U+006C). То же самое с ß, но с неё, теоретически, слова начинаться не могут.
6. Опять эти лигатуры! Хорошо, берём первый символ из слова, переводим в uppercase, если получилось больше одного символа, то первый оставляем, а остальные назад в lowercase. Тогда точно сработает.
Не сработает. Есть, например, диграф dz (U+01F3), который может использоваться в тексте на польском, словацком, македонском или венгерском языке. В uppercase ему соответствует диграф DZ (U+01F1), а в titlecase — диграф Dz (U+01F2). Есть ещё разные диграфы. Греческий же язык порадует вас приколами с ипогеграммени и просгеграммени (к счастью, в современных текстах такое редко встречается). В общем случае варианты uppercase и titlecase для символа могут быть различны, для них есть отдельные записи в стандарте Unicode.
7. Хорошо, но, по крайней мере, результат преобразования регистра символа в uppercase или lowercase не зависит от его позиции в слове.
Нет. К примеру, греческая заглавная сигма Σ (U+03A3) на конце слова превращается в строчную ς (U+03C2), а в середине — в σ (U+03C3).
8. Ох, ну ладно, греческую сигму обработаем отдельно. Но во всяком случае, один и тот же символ в одной и той же позиции в тексте преобразуется одинаково.
Нет. Скажем, в большинстве языков с латиницей строчный вариант для I (U+0049) — это i (U+0069), но не в турецком и азербайджанском. Там строчный вариант для I — это ı (U+0131), а заглавный вариант для i — это İ (U+0130). В Турции из-за этого в разнообразном софте порой наблюдаются фееричные баги. А если вам попадётся текст на литовском с проставленными ударениями, то, к примеру, заглавная Ì (U+00CC), которая превратится не в ì (U+00EC), а в
(U+0069, U+0307, U+0300). В общем, результат преобразования зависит ещё и от языка. Большинство сложных случаев описано здесь.9. Какой ужас! Ну хорошо, пусть мы теперь правильно преобразуем в uppercase и lowercase. Сравнить два слова без учёта регистра не представляет проблем: переводим оба в lowercase и сравниваем.
Здесь тоже немало подводных камней, которые вытекают из вышесказанного. Например, не сработает с немецкими straße и STRASSE (первое не изменится, второе превратится в strasse). Со многими другими описанными выше буквами тоже будут проблемы.
10. М-да… Может, тогда всё в uppercase?
И это не всегда сработает (хотя и гораздо чаще). Но, скажем, если вам попадётся запись STRA
E (да, большая эсцет тоже есть в немецком и в Unicode), она не совпадёт со straße. Для сравнений буквы преобразуются по специальной таблице Unicode — CaseFolding, по ней и обе ß, и SS превратятся в ss.11. А-а-а, это ж капец какой-то!
Вот тут согласен.
Если у кого-то не отображаются какие-то символы, напишите мне личное сообщение, я заменю на картинку.

