В этом топике я хотел бы рассказать о том, как устроена кассандра (cassandra) — децентрализованная, отказоустойчивая и надёжная база данных “ключ-значение”. Хранилище само позаботится о проблемах наличия единой точки отказа (single point of failure), отказа серверов и о распределении данных между узлами кластера (cluster node). При чем, как в случае размещения серверов в одном центре обработки данных (data center), так и в конфигурации со многими центрами обработки данных, разделенных расстояниями и, соответственно, сетевыми задержками. Под надёжностью понимается итоговая согласованность (eventual consistency) данных с возможностью установки уровня согласования данных (tune consistency) каждого запроса.
NoSQL базы данных требуют в целом большего понимания их внутреннего устройства чем SQL. Эта статья будет описывать базовое строение, а в следующих статьях можно будет рассмотреть: CQL и интерфейс программирования; техники проектирования и оптимизации; особенности кластеров размещённых в многих центрах обработки данных.
Модель данных
В терминологии кассандры приложение работает с пространством ключей (keyspace), что соответствует понятию схемы базы данных (database schema) в реляционной модели. В этом пространстве ключей могут находиться несколько колоночных семейств (column family), что соответствует понятию реляционной таблицы. В свою очередь, колоночные семейства содержат колонки (column), которые объединяются при помощи ключа (row key) в записи (row). Колонка состоит из трех частей: имени (column name), метки времени (timestamp) и значения (value). Колонки в пределах записи упорядочены. В отличие от реляционной БД, никаких ограничений на то, чтобы записи (а в терминах БД это строки) содержали колонки с такими же именами как и в других записях — нет. Колоночные семейства могут быть нескольких видов, но в этой статье мы будем опускать эту детализацию. Также в последних версиях кассандры появилась возможность выполнять запросы определения и изменения данных (DDL, DML) при помощи языка CQL, а также создавать вторичные индексы (secondary indices).
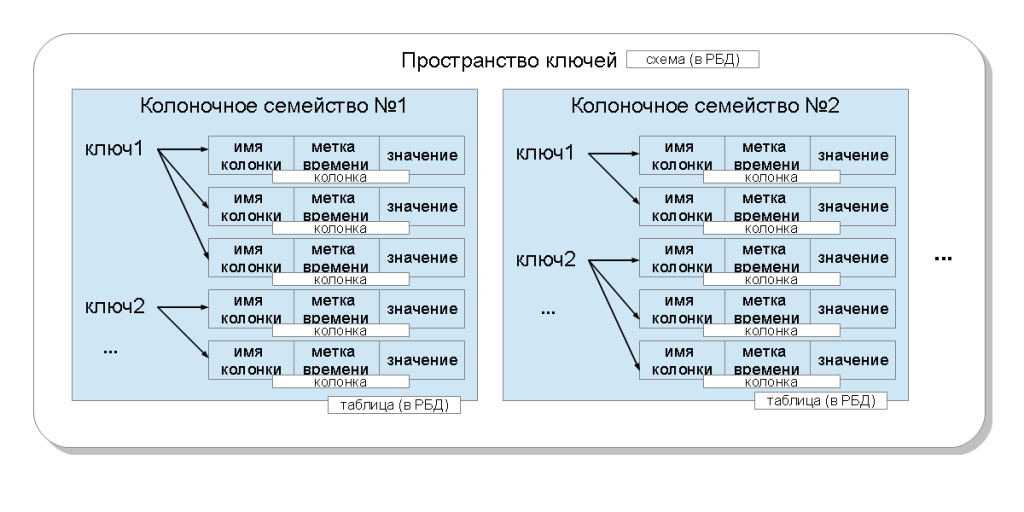
Конкретное значение, хранимое в кассандре идентифицируется:
- пространством ключей — это привязка к приложению (предметной области). Позволяет на одном кластере размещать данные разных приложений;
- колоночным семейством — это привязка к запросу;
- ключом — это привязка к узлу кластера. От ключа зависит на какие узлы попадут сохранённые колонки;
- именем колонки — это привязка к атрибуту в записи. Позволяет в одной записи хранить несколько значений.
С каждым значением связана метка времени — задаваемое пользователем число, которое используется для разрешения конфликтов во время записи: чем больше число, тем колонка считается новее, а при сравнении перетирает старые колонки.
По типам данных: пространство ключей и колоночное семейство — это строки (имена); метка времени — это 64-битное число; а ключ, имя колонки и значение колонки — это массив байтов. Также кассандра имеет понятие типов данных (data type). Эти типы могут по желанию разработчика (опционально) задаваться при создании колоночного семейства. Для имён колонок это называется сравнителем (comparator), для значений и ключей — валидатором (validator). Первый определяет какие байтовые значения допустимы для имён колонок и как их упорядочить. Второй — какие байтовые значение допустимы для значений колонок и ключей. Если эти типы данных не заданы, то кассандра хранит значения и сравнивает их как байтовые строки (BytesType) так как, по сути, они сохраняются внутри.
Типы данных бывают такими:
- BytesType: любые байтовые строки (без валидации)
- AsciiType: ASCII строка
- UTF8Type: UTF-8 строка
- IntegerType: число с произвольным размером
- Int32Type: 4-байтовое число
- LongType: 8-байтовое число
- UUIDType: UUID 1-ого или 4-ого типа
- TimeUUIDType: UUID 1-ого типа
- DateType: 8-байтовое значение метки времени
- BooleanType: два значения: true = 1 или false = 0
- FloatType: 4-байтовое число с плавающей запятой
- DoubleType: 8-байтовое число с плавающей запятой
- DecimalType: число с произвольным размером и плавающей запятой
- CounterColumnType: 8-байтовый счётчик
В кассандре все операции записи данных это всегда операции перезаписи, то есть, если в колоночную семью приходит колонка с таким же ключом и именем, которые уже существуют, и метка времени больше, чем та которая сохранена, то значение перезаписывается. Записанные значения никогда не меняются, просто приходят более новые колонки с новыми значениями.
Запись в кассандру работает с большей скоростью, чем чтение. Это меняет подход, который применяется при проектировании. Если рассматривать кассандру с точки зрения проектирования модели данных, то проще представить колоночное семейство не как таблицу, а как материализованное представление (materialized view) — структуру, которая представляет данные некоторого сложного запроса, но хранит их на диске. Вместо того, чтобы пытаться как-либо скомпоновать данные при помощи запросов, лучше постараться сохранить в коночное семейство все, что может понадобиться для этого запроса. То есть, подходить необходимо не со стороны отношений между сущностями или связями между объектами, а со стороны запросов: какие поля требуются выбрать; в каком порядке должны идти записи; какие данные, связанные с основными, должны запрашиваться совместно — всё это должно уже быть сохранено в колоночное семейство. Количество колонок в записи ограничено теоретически 2 миллиардами. Это краткое отступление, а подробней — в статье о техниках проектирования и оптимизации. А теперь давайте углубимся в процесс сохранения данных в кассандру и их чтения.
Распределение данных
Рассмотрим каким образом данные распределяются в зависимости от ключа по узлам кластера (cluster nodes). Кассандра позволяет задавать стратегию распределения данных. Первая такая стратегия распределяет данные в зависимости от md5 значения ключа — случайный разметчик (random partitioner). Вторая учитывает само битовое представление ключа — порядковый разметчик (byte-ordered partitioner). Первая стратегия, в большинстве своем, даёт больше преимуществ, так как вам не нужно заботиться о равномерном распределение данных между серверами и подобных проблемах. Вторую стратегию используют в редких случаях, например если необходимы интервальные запросы (range scan). Важно заметить, что выбор этой стратегии производится перед созданием кластера и фактически не может быть изменён без полной перезагрузки данных.
Для распределения данных кассандра использует технику, известную как согласованное хеширование (consistent hashing). Этот подход позволяет распределить данные между узлами и сделать так, что при добавлении и удалении нового узла количество пересылаемых данных было небольшим. Для этого каждому узлу ставится в соответствие метка (token), которая разбивает на части множество всех md5 значений ключей. Так как в большинстве случаев используется RandomPartitioner, рассмотрим его. Как я уже говорил, RandomPartitioner вычисляет 128-битный md5 для каждого ключа. Для определения в каких узлах будут храниться данные, просто перебираются все метки узлов от меньшего к большему, и, когда значение метки становится больше, чем значение md5 ключа, то этот узел вместе с некоторым количеством последующих узлов (в порядке меток) выбирается для сохранения. Общее число выбранных узлов должно быть равным уровню репликации (replication factor). Уровень репликации задаётся для каждого пространства ключей и позволяет регулировать избыточность данных (data redundancy).
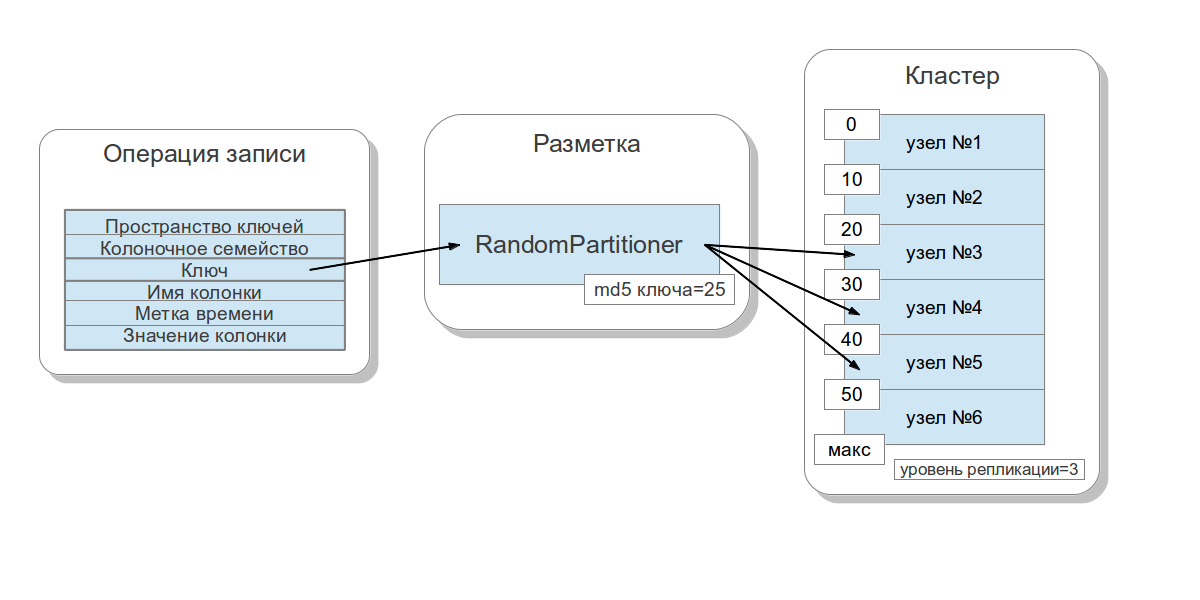
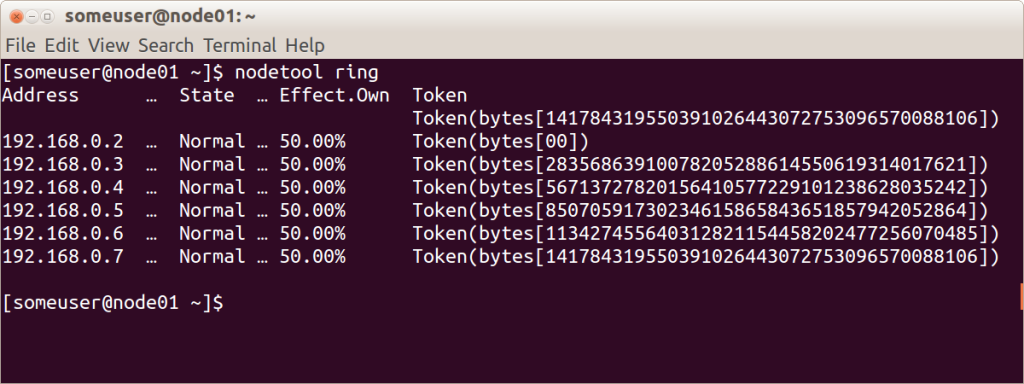
Перед тем, как добавить узел в кластер, необходимо задать ему метку. От того, какой процент ключей покрывает промежуток между этой меткой и следующей, зависит сколько данных будет храниться на узле. Весь набор меток для кластера называется кольцом (ring).
Вот иллюстрация отображающая при помощи встроенной утилиты nodetool кольцо кластера из 6 узлов с равномерно распределенными метками.
Согласованность данных
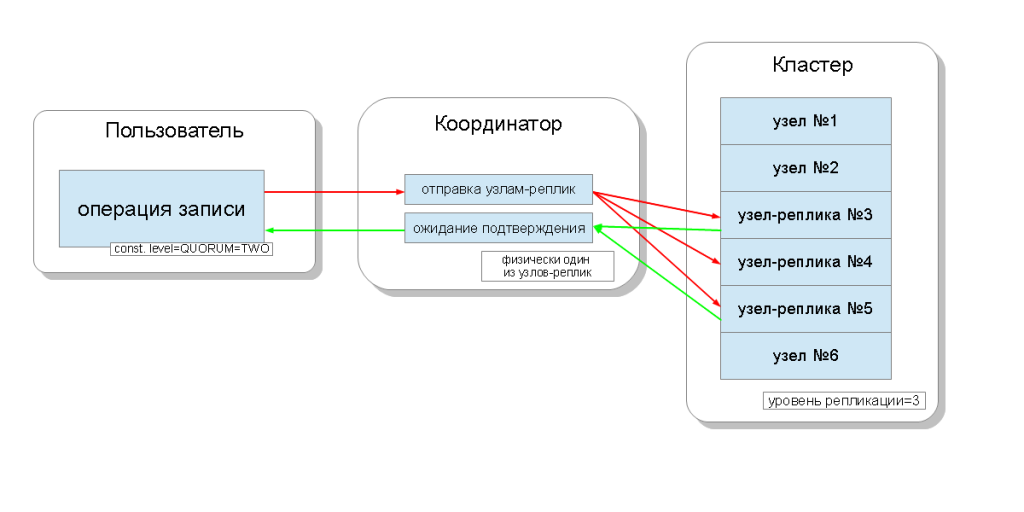
Узлы кластера кассандры равноценны, и клиенты могут соединятся с любым из них, как для записи, так и для чтения. Запросы проходят стадию координации, во время которой, выяснив при помощи ключа и разметчика на каких узлах должны располагаться данные, сервер посылает запросы к этим узлам. Будем называть узел, который выполняет координацию — координатором (coordinator), а узлы, которые выбраны для сохранения записи с данным ключом — узлами-реплик (replica nodes). Физически координатором может быть один из узлов-реплик — это зависит только от ключа, разметчика и меток.
Для каждого запроса, как на чтение, так и на запись, есть возможность задать уровень согласованности данных.
Для записи этот уровень будет влиять на количество узлов-реплик, с которых будет ожидаться подтверждение удачного окончания операции (данные записались) перед тем, как вернуть пользователю управление. Для записи существуют такие уровни согласованности:
- ONE — координатор шлёт запросы всем узлам-реплик, но, дождавшись подтверждения от первого же узла, возвращает управление пользователю;
- TWO — то же самое, но координатор дожидается подтверждения от двух первых узлов, прежде чем вернуть управление;
- THREE — аналогично, но координатор ждет подтверждения от трех первых узлов, прежде чем вернуть управление;
- QUORUM — собирается кворум: координатор дожидается подтверждения записи от более чем половины узлов-реплик, а именно round(N / 2) + 1, где N — уровень репликации;
- LOCAL_QUORUM — координатор дожидается подтверждения от более чем половины узлов-реплик в том же центре обработки данных, где расположен координатор (для каждого запроса потенциально свой). Позволяет избавиться от задержек, связанных с пересылкой данных в другие центры обработки данных. Вопросы работы с многими центрами обработки данных рассматриваются в этой статье вскользь;
- EACH_QUORUM — кооринатор дожидается подтверждения от более чем половины узлов-реплик в каждом центре обработки данных независимо;
- ALL — координатор дожидается подтверждения от всех узлов-реплик;
- ANY — даёт возможность записать данные, даже если все узлы-реплики не отвечают. Координатор дожидается или первого ответа от одного из узлов-реплик, или когда данные сохранятся при помощи направленной отправки (hinted handoff) на координаторе.
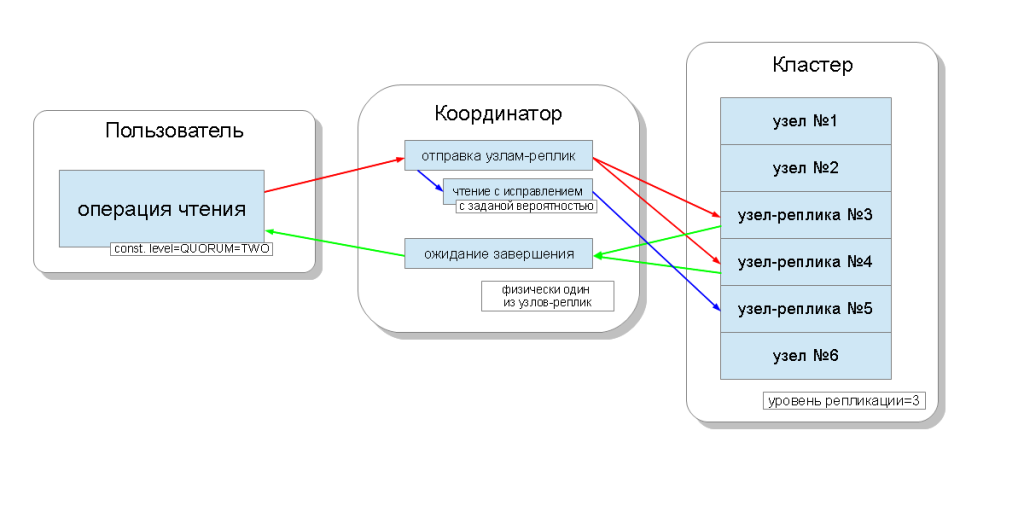
Для чтения уровень согласованности будет влиять на количество узлов-реплик, с которых будет производиться чтение. Для чтения существуют такие уровни согласованности:
- ONE — координатор шлёт запросы к ближайшему узлу-реплике. Остальные реплики также читаются в целях чтения с исправлением (read repair) с заданной в конфигурации кассандры вероятностью;
- TWO — то же самое, но координатор шлёт запросы к двум ближайшим узлам. Выбирается то значение, которое имеет большую метку времени;
- THREE — аналогично предыдущему варианту, но с тремя узлами;
- QUORUM — собирается кворум, то есть координатор шлёт запросы к более чем половине узлов-реплик, а именно round(N / 2) + 1, где N — уровень репликации;
- LOCAL_QUORUM — собирается кворум в том центре обработки данных, в котором происходит координация, и возвращаются данные с последней меткой времени;
- EACH_QUORUM — координатор возвращает данные после собрания кворума в каждом из центров обработки данных;
- ALL — координатор возвращает данные после прочтения со всех узлов-реплик.
Таким образом, можно регулировать временные задержки операций чтения, записи и настраивать согласованность (tune consistency), а также доступность (availability) каждой из видов операций. По сути, доступность напрямую зависит от уровня согласованности операций чтения и записи, так как он определяет, сколько узлов-реплик может выйти из строя, и при этом эти операции все ещё будут подтверждены.
Если число узлов, с которых приходит подтверждения о записи, в сумме с числом узлов, с которых происходит чтение, больше, чем уровень репликации, то у нас есть гарантия, что после записи новое значение всегда будет прочитано, и это называется строгой согласованностью (strong consistency). При отсутствии строгой согласованности существует возможность того, что операция чтения возвратит устаревшие данные.
В любом случае, значение в конце концов распространится между репликами, но уже после того, как закончится координационное ожидание. Такое распространение называется итоговой согласованностью (eventual consistency). Если не все узлы-реплики будут доступны во время записи, то рано или поздно будут задействованы средства восстановления, такие как чтение с исправлением и анти-энтропийное восстановление узла (anti-entropy node repair). Об этом чуть позже.
Таким образом, при уровне согласованности QUORUM на чтение и на запись всегда будет поддерживаться строгая согласованность, и это будет некий баланс между задержкой операции чтения и записи. При записи ALL, а чтении ONE будет строгая согласованность, и операции чтения будут выполняться быстрее и будут иметь большую доступность, то есть количество вышедших из строя узлов, при котором чтение все еще будет выполнено, может быть большим, чем при QUORUM. Для операций записи же потребуются все рабочие узлы-реплик. При записи ONE, чтении ALL тоже будет строгая согласованность, и операции записи будут выполняться быстрее и доступность записи будет большой, ведь будет достаточно подтвердить лишь, что операция записи прошла хотя бы на одном из серверов, а чтение — медленней и требовать всех узлов-реплик. Если же к приложению нету требования о строгой согласованности, то появляется возможность ускорить и операции чтения и операции записи, а также улучшить доступность за счет выставления меньших уровней согласованности.
Восстановление данных
Кассандра поддерживает три механизма восстановления данных:
- чтение с восстановлением (read repair) — во время чтения данные запрашиваются со всех реплик и сравниваются уже после завершения координации. Та колонка, которая имеет последнюю метку времени, распространится на узлы, где метки устаревшие.
- направленной отправки (hinted handoff) — позволяет сохранить информацию об операции записи на координаторе в том случае, если запись на какой-либо из узлов не удалась. Позже, когда это будет возможно, запись повторится. Позволяет быстро производить восстановление данных в случае краткосрочного отсутствия узла в кластере. Кроме того, при уровне согласованности ANY позволяет добиться полной доступности для записи (absolute write availability), когда даже все узлы-реплик недоступны, операция записи подтверждается, а данные сохранятся на узле-координаторе.
- анти-энтропийное восстановление узла (anti-entropy node repair) — это некий процесс восстановления всех реплик, который должен запускаться регулярно вручную при помощи команды “nodetool repair” и позволяет поддержать количество реплик всех данных, которые возможно были не восстановлены первыми двумя способами, на требуемом уровне репликации.
Запись на диск
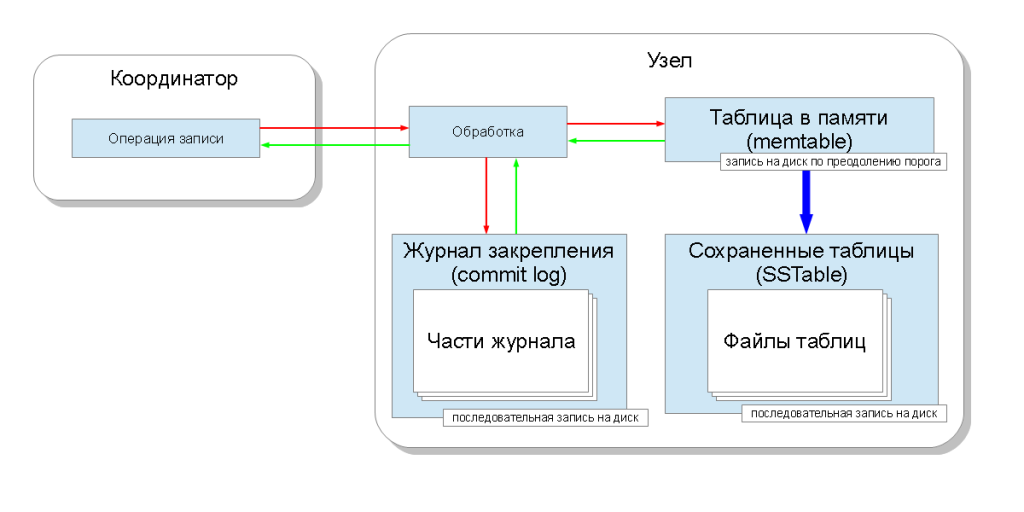
Когда данные приходят после координации на узел непосредственно для записи, то они попадают в две структуры данных: в таблицу в памяти (memtable) и в журнал закрепления (commit log). Таблица в памяти существует для каждого колоночного семейства и позволяет запомнить значение моментально. Технически это хеш-таблица (hashmap) с возможностью одновременного доступа (concurrent access) на основе структуры данных, называемой “списками с пропусками” (skip list). Журнал закрепления один на всё пространство ключей и сохраняется на диске. Журнал представляет собой последовательность операций модификации. Так же он разбивается на части при достижении определённого размера.
Такая организация позволяет сделать скорость записи ограниченной скоростью последовательной записи на жесткий диск и при этом гарантировать долговечность данных (data durability). Журнал закрепления в случае аварийного останова узла читается при старте сервиса кассандры и восстанавливает все таблицы в памяти. Получается, что скорость упирается во время последовательной записи на диск, а у современных жёстких дисков это порядка 100МБ/с. По этой причине журнал закрепления советуют вынести на отдельный дисковый носитель.
Понятно, что рано или поздно память может заполниться. Поэтому таблицу в памяти также необходимо сохранить на диск. Для определения момента сохранения существует ограничение объёма занимаемыми таблицами в памяти (memtable_total_spacein_mb), по умолчанию это ⅓ максимального размера кучи Java (Java heapspace). При заполнении таблицами в памяти объёма больше чем это ограничение, кассандра создает новую таблицу и записывает старую таблицу в памяти на диск в виде сохраненной таблицы (SSTable). Сохранённая таблица после создания больше никогда не модифицируется (is immutable). Когда происходит сохранение на диск, то части журнала закрепления помечаются как свободные, таким образом освобождая занятое журналом место на диске. Нужно учесть, что журнал имеет переплетённую структуру из данных разных колоночных семейств в пространстве ключей, и какие-то части могут быть не освобождены, так как некоторым областям будут соответствовать другие данные, все ещё находящиеся в таблицах в памяти.
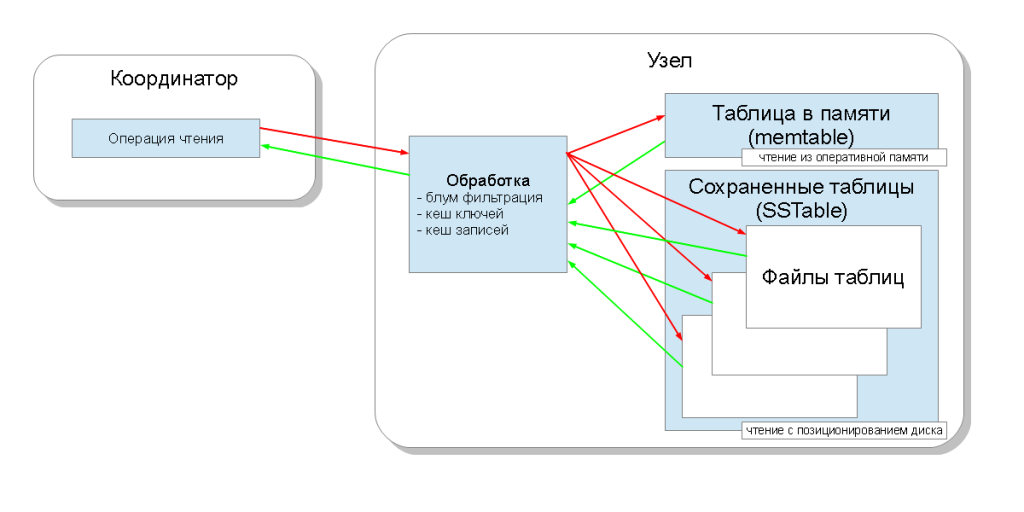
В итоге, каждому колоночному семейству соответствует одна таблица в памяти и некоторое число сохранённых таблиц. Теперь, когда узел обрабатывает запрос чтения, ему необходимо запросить все эти структуры и выбрать самое последнее по метке времени значение. Для ускорения этого процесса существует три механизма: блум-фильтрация (bloom filter), кэш ключей (key cache) и кэш записей (record cache):
- блум-фильтр — это структура данных, которая занимает немного места и позволяет ответить на вопрос: содержится ли элемент, а в нашем случае это ключ, в множестве или нет. При чем, если ответ — “нет”, то это 100%, а если ответ “да”, то это, возможно, ложно-положительный ответ. Это позволяет уменьшить количество чтений из сохранённых таблиц;
- кэш ключей сохраняет позицию на диске записи для каждого ключа, таким образом уменьшая количество операций позиционирования (seek operations) во время поиска по сохранённой таблице;
- кэш записей сохраняет запись целиком, позволяя совсем избавиться от операций чтения с диска.
Уплотнение
В определенный момент времени данные в колоночном семействе перезапишутся — придут колонки, которые будут иметь те же имя и ключ. То есть, возникнет ситуация, когда в более старой сохранённой таблице и более новой будут содержаться старые и новые данные. Для того, чтобы гарантировать целостность, кассандра обязана читать все эти сохранённые таблицы и выбирать данные с последней меткой времени. Получается, что количество операций позиционирования жёсткого диска при чтении пропорционально количеству сохранённых таблиц. Поэтому для того, чтобы освободить перезаписанные данные и уменьшить количество сохранённых таблиц, существует процесс уплотнения (compaction). Он читает последовательно несколько сохранённых таблиц и записывает новую сохранённую таблицу, в которой объединены данные по меткам времени. Когда таблица полностью записана и введена в использование, кассандра может освободить таблицы-источники(таблицами, которые её образовали). Таким образом, если таблицы содержали перезаписанные данные, то эта избыточность устраняется. Понятно, что во время такой операции объем избыточности увеличивается — новая сохранённая таблица существует на диске вместе с таблицами-источниками, а это значит, что объем места на диске всегда должен быть такой, чтобы можно было произвести уплотнение.
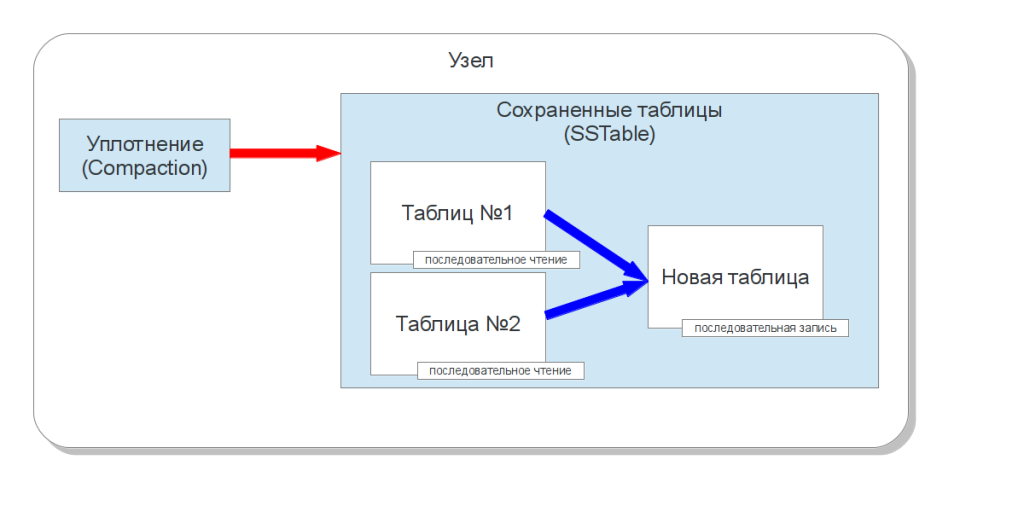
Кассандра позволяет выбрать одну из двух стратегий проведения уплотнения:
- стратегия уплотнения сохраненных таблиц связанных размером (size-tiered compaction) — эта стратегия уплотняет определенным образом выбранные две таблицы. Применяется автоматически в виде фонового уплотнения (minor compaction) и в ручном режиме, для полного уплотнения (major compaction). Допускает ситуацию нахождения ключа во многих таблицах и, соответственно, требует выполнять операцию поиска для каждой такой таблицы.
- стратегия уплотнение сохраненных таблиц уровнями (leveled compaction) — уплотняет сохраненные таблицы, которые изначально создаются небольшими — 5 МБ, группируя их в уровни. Каждый уровень в 10 раз больший чем предыдущий. Причем, существуют такие гарантии: 90% запросов чтения будут происходить к одной сохраненной таблице, и только 10% пространства на диске будет использоваться под устаревшие данные. В этом случае для выполнения уплотнения под временную таблицу достаточно только 10-кратного размера таблицы, то есть 50 Мб. Подробнее в этой статье
Операции удаления
С точки зрения внутреннего устройства, операции удаление колонок — это операции записи специального значения — затирающего значения (tombstone). Когда такое значение получается в результате чтения, то оно пропускается, словно такого значения никогда и не существовало. В результате же уплотнения, такие значения постепенно вытесняют устаревшие реальные значения и, возможно, исчезают вовсе. Если же появятся колонки с реальными данными с еще более новыми метками времени, то они перетрут, в конце концов, и эти затирающие значения.
Транзакционность
Кассандра поддерживает транзакционность на уровне одной записи, то есть для набора колонок с одним ключом. Вот как выполняются четыре требования ACID:
- атомарность (atomicity) — все колонки в одной записи за одну операцию будут или записаны, или нет;
- согласованность (consistency) — как уже было сказано выше, есть возможность использовать запросы с строгой согласованностью взамен доступности, и тем самым выполнить это требование;
- изолированность (isolation) — начиная с кассандры версии 1.1, появилась поддержка изолированности, когда во время записи колонок одной записи другой пользователь, который читает эту же запись, увидит или полностью старую версию записи или, уже после окончания операции, новую версию, а не часть колонок из одной и часть из второй;
- долговечность (durability) обеспечивается наличием журнала закрепления, который будет воспроизведён и восстановит узел до нужного состояния в случае какого-либо отказа.
Послесловие
Итак, мы рассмотрели как устроены основные операции — чтение и запись значений в кассандру.
В дополнение, важные, по моему мнению, ссылки:
- Страница на apache.org cassandra.apache.org
- Документация на datastax.com www.datastax.com/docs/1.1/index#apache-cassandra-1-1-documentation
- Про BigTable research.google.com/archive/bigtable.html
- Про Amazon Dynamo www.allthingsdistributed.com/2007/10/amazons_dynamo.html
- Просто один из блогов, про модель данных maxgrinev.com/2010/07/09/a-quick-introduction-to-the-cassandra-data-model
Просьба: замечания по орфографии и идеи по улучшению статьи высказывайте в личном сообщении.