Данная статья рассказывает о разработке узкоспециализированного аппаратного устройства для целей HFT. Его специализация направлена на достижение минимально возможных временных задержек для обработки рыночных данных и, следовательно, на уменьшение времени раунд-трипа при осуществлении сделок. Реализация, описанная в этой работе, осуществляет разбор пакетов Ethernet, IP и UDP, а также FAST протокола, который является наиболее распространенным при передаче рыночной информации. Для подобных целей был разработан собственный движок микрокода, с поддержкой набора команд и компилятором, благодаря чему достигается поддержка широкого круга применяемых в трейдинге протоколов. Конечная система была реализована в RTL коде и исполняется на FPGA. Данный подход показывает преимущество в 4 раза, по сравнению с полностью программными решениями.
Высокочастотному трейдингу (HFT) уделяется большое внимание в последнее время, и он становится важнейшим игроком на финансовых рынках. Под термином HFT понимается набор техник при торговле акциями и деривативами, когда большой поток заявок отправляется на рынок с раунд-трипом меньше миллисекунды[1]. Цель высокочастотников, это подойди к концу дня без каких-либо позиций ценных бумаг в наличии, а получать прибыль от своих стратегий покупая и продавая акции на очень высокой скорости. Исследования показывают, что HFT трейдеры держат акцию в среднем всего 22 секунды[2]. Aite Group утверждает, что HFT оказывает существенное влияние на рынок, более чем 50% сделок по акциям в США было совершенно HFT в 2010 году, при этом рост только за 2009 год составил 70%[3].
HFT трейдеры используют несколько вариантов стратегий, как например — стратегия по обеспечению ликвидности, стратегия статистического арбитража и стратегия по поиску ликвидности [2]. В стратегии по обеспечению ликвидности, высокочастотники пытаются заработать на спреде спроса-предложения(bid-ask), который отражает разницу, по которой продавцы готовы продать, а покупатели купить. Высокая волатильность и широкий bid-ask спред могут обернуться прибылью для HFT трейдера, и в то же время он становится поставщиком ликвидности и сужает bid-ask спред, как бы исполняя роль маркетмейкера. Ликвидность и маленький ask-bid спред являются важными вещами, поскольку они снижают торговые издержки и позволяют точнее определить стоимость актива[4]. Трейдеры, которые используют арбитражные стратегии, используют корреляцию между ценами производных инструментов и их базовых активов[5]. Стратегии по поиску ликвидности исследуют рынок в поисках крупных заявок, путем посылки небольших приказов, которые помогают обнаружить большие скрытые заявки. Все стратегии объединяет одно, для работы им требуются бескомпромиссно низкие временные задержки, поскольку только самые быстрые HFT компании в состоянии воспользоваться возникающими на рынке возможностями.
Электронная торговля акциями происходит путем посылки запросов в электронной форме на биржу. Заявки на покупку и продажу затем сопоставляются на бирже, и осуществляется сделка. Выставляемые заявки видны всем участникам торгов через так называемые фиды. Фид – это сжатый или несжатый поток данных, поставляемый в реальном времени некой независимой организацией, как например Options Price Reporting Authority (OPRA). Фид содержит финансовую информацию по акциям и передается с помощью мультикаста участникам рынка через стандартизированные протоколы, в основном через Ethernet посредством UDP. Стандартным протоколом поставки рыночных данных является Financial Information Exchange (FIX) Adapted for Streaming (FAST), который используется на большинстве бирж[18].
Для того чтобы добиться минимального времени задержки, HFT движок должен быть оптимизирован на всех уровнях. Для уменьшения времени задержки при передачи по сети используется collocation, когда HFT сервер устанавливается рядом со шлюзом биржи. Фид с данными должен распространятся с минимальными задержками до серверов HFT. Эффективная обработка UDP и FAST пакетов также является необходимой. И наконец, решение о создании заявки и ее передача должны осуществляется с наименьшими возможными задержками. Для достижения этих целей был разработан новый HFT движок, реализованный на плате FPGA. Благодаря использованию FPGA, появилась возможность снять нагрузку по обработке UDP и FAST с центрального процессора и перенести ее на специально оптимизированные блоки платы. В представленной системе, на аппаратном уровне реализован весь цикл обработки, за исключением принятий торговых решений, включая крайне гибкий движок с поддержкой микрокода для обработки FAST сообщений. Подход дает значительное снижение задержек более чем на 70% по сравнению с софтверными решениями и в то же время позволяет гораздо проще изменять или добавлять обработку новых протоколов, чем интегральные схемы специального назначения(Application-specific integrated circuit).
Текущий раздел рассказывает о базовых концепциях и реализации биржевой инфраструктуры. В дополнение, будет рассказано о базовых свойствах протокола FAST, чтобы определить требования к аппаратной реализации.
Типичная инфраструктура для трейдинга состоит из нескольких компонентов, контролируемых различными участниками. Это – биржа, поставщик фида и участники рынка, как показано на Figure 1. Движок для сопоставления заявок (матчинга), маршрутизатор дата-центра, и шлюз контролируются биржей. Механизм для фидов предоставляет другая организация. Маршрутизатор для доступа участников рынка – это собственность этих участников, в данном случае HFT фирм.
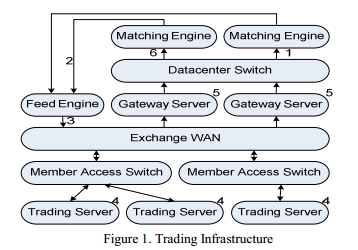
Порядок работы следующий:
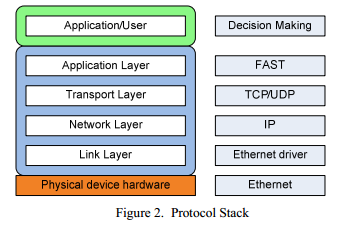
Для осуществления электронной торговли приходится задействовать несколько уровней сетевого стека. Иллюстрация этих слоев отображена на Figure 2.
FAST протокол используется поставщиком фидов для передачи финансовой информации участникам рынка. Для снижения нагрузки, несколько сообщений FAST могут быть объединены в одном UDP пакете. Эти сообщения не используют фрейминг и не содержат в себе информацию о размере сообщения. Вместо этого, каждый тип сообщения описывается в шаблоне, который должен быть известен, чтобы правильно обработать поток данных. Большинство поставщиков фидов объявляют свою собственную реализацию протокола, путем поставки собственных независимых спецификаций для шаблонов. Обработка должна проводиться с должным вниманием, так как ошибка в одном сообщении приведет к тому, что будет потерян весь UDP пакет. Шаблоны описывают набор полей, последовательностей и групп. Группы это – набор полей, где каждое поле может содержаться только по одному разу, а последовательности могут содержать наборы повторяющихся полей.

Каждое сообщение начинается с presence map (PMAP) и идентификатора шаблона (TID) как показано на Figure 3. PMAP является маской, и указывает какие именно из объявленных полей, групп и последовательностей содержатся в текущем потоке. Поля могут быть как обязательными, так и необязательными, а также могут содержать связанный с ними оператор. Причем это факт зависит от атрибута presence, а также и от битового флага в PMAP, если к полю привязан оператор. Это добавляет дополнительную сложность, так как заранее неизвестно, потребуется ли обработка PMAP или нет.
TID используется для идентификации шаблона, который потребуется для обработки сообщения. Шаблоны описываются в XML, например,
В этом примере TID равен 1, а шаблон состоит из двух полей и одной группы. Тип поля может быть строкой, целым числом, дробным числом, 32 или 64 битным, а также типом decimal, где 32 бита будет выделено на показатель степени и 64 бита на мантиссу.
Для снижения нагрузки на сеть передаются только те байты, которые содержат явные значения. Например, только один байт будет передан для 64-битного целого числа со значением ‘1’, несмотря на то, что в памяти это число занимает 64 бита.
Только первые семь бит из каждого переданного байта используются для записи полезных данных, восьмой же бит используется как стоп-бит и служит для разделения полей. Стоп-бит должен быть удален, а оставшиеся 7 бит должны быть объединены, если поле состоит более чем из одного байта.
Допустим, был получен следующий бинарный поток:
10000111 00101010 10111111
На основании подчеркнутых стоп-битов, следует, что эти три байта содержат два поля. Чтобы получить значение первого поля следует заменить восьмой бит значением 0. Результатом будет:
Бинарное значение: 00111111
Шестнадцатеричное значение: 0x63
Второе поле состоит из 2 байт. Чтобы получить настоящее значение, требуется в каждом байте заменить восьмой бит на 0 и совместить оставшиеся части. Результатом будет:
Бинарное значение: 00000011 10101010
Шестнадцатеричное значение: 0x03 0xAA
На самом деле все еще более сложно, так например, поля должны быть обработаны по-разному, в зависимости от их атрибута presence. Необязательное целое число должно уменьшаться на единицу, а обязательное нет.
Операторы предписывают выполнение какого-либо действия c полем, после того как оно было получено, или если поле вовсе не представлено в потоке. Доступные операторы constant, copy, default, delta и increment. Например, constant, говорит о том, что поле всегда содержит одинаковое значение, и, следовательно, никогда не передается в фиде.
Спецификация FAST также предусматривает объявление массива байт, в котором не используются стоп-биты, а все восемь бит в байте используются для передачи полезных данных. Данный массив в свою очередь содержит поле, в котором задается общее количество байт. Это часть спецификации не была реализована в связи с высокой сложностью, и с тем фактом, что она не используется на целевой бирже, в данном случае во Франкфурте.
В последнее время появилось много литературы по теме, но все-таки большая часть работы выполняется внутри организаций и не публикуется. Очень хороший обзор по оптимизации HFT дан в [6]. Более того, предоставлена система для оптимизации обработки ORPA FAST фида с использованием устройства Myrinet MX. Многопоточный «faster FAST» движок, для использования на многоядерных системах представлен в [7]. Несмотря на то, что обе системы сфокусированы на оптимизации обработки FAST, подход из данной статьи является первым, который использует FPGA. Morris [8] описывает HFT систему, которая использует FPGA для оптимизации обработки UDP/IP, похожую на [9]. Другие связанные темы, это использование FPGA для техник алгоритмической торговли основанной на методе Монте Карло[10], [11], [12]. Sadoghi [13] использует основанные на FPGA технологии для эффективной обработки событий в алгоритмической торговле. Mittal представляет программный FAST декодер, который исполняется на PowerPC 405, который встроен в несколько плат FPGA [13]. И последнее, Tandon опубликовал работу «A Programmable Architecture for Real-time Derivative Trading» [14].
Предлагается три различных подхода для уменьшения времени задержек в HFT приложениях. Первый – это оптимизация UDP, второе – аппаратная реализация обработки сообщений FAST, и третье – задействование параллельных аппаратных структур для одновременной обработки нескольких потоков.
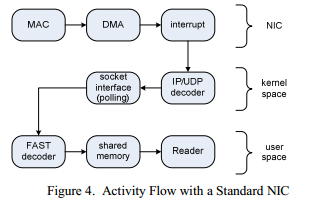
В обычных системах UDP данные приходят на сетевую карту(NIC) в виде необработанных пакетов ETH. Затем NIC передает пакеты в ядро ОС, которое производит проверку контрольной суммы и обрабатывает пакет. Поток выполнения для этого процесса показан на Figure 4. Данный подход показывает высокие временные задержки, вследствие того что используются прерывания для информирования ОС о поступивших пакетах, а также из-за внедрения еще одного дополнительного уровня, который служит для передачи данных в пользовательское пространство – сокетов. Более того, ядро ОС может быть занято другими активностями, что тоже неблагоприятно влияет на времена обработки. Детальный список различных временных задержек, которые появляются в процессе обработки TCP/IP можно найти в [15]. В случае UDP ситуация очень схожа, поскольку разница с TCP начинает появляться только на более высоких уровнях.
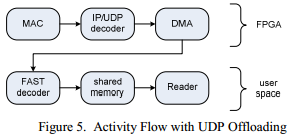
Первым и наиболее эффективным подходом для уменьшения задержки будет обход ядра ОС и обработка поступающих пакетов в аппаратной части, как это показано в Figure 5. Следовательно, потребуется поддержка Address Resolution Protocol (ARP), чтобы корректно получать и отправлять пакеты. ARP используется для сопоставления IP адресов с физическими MAC адресами участников.
Для получения мультикаста также потребуется поддержка Internet Group Management Protocol (IGMP), который требуется для подключения и отключения мультикаст групп. Другие протоколы, которые потребуют реализации это ETH, IP и UDP. Все эти протоколы эффективно реализованы, с фокусом на минимально возможные задержки для ETH, IP и UDP. Реализация IGMP и ARP протоколов не является критичной к скорости, поскольку при трейдинге они не участвуют в непосредственной передаче данных. Все контрольные суммы заголовков различных протоколов и ETH CRC вычисляются параллельно, в то время как проверка этих контрольных сумм производится на самом последнем этапе.
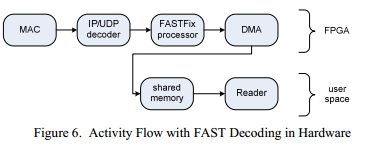
Проверенный пакет далее передается на FAST обработчик или на движок DMA, который способен записать необработанные данные в адресное пространство торгового ПО. Пример, когда обработка FAST производится на FPGA, и затем через DMA движок передается в пользовательское приложение, показан на Figure 6.
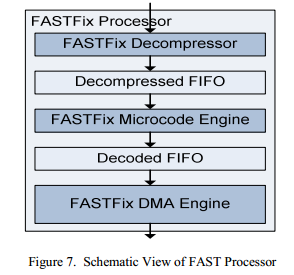
Из-за высокой сложности FAST декодер разбит на три независимые части. Как показано на Figure 7, все три части развязаны через FIFO буферы, чтобы компенсировать различную и иногда непредвиденную задержу в каждом из модулей. Поскольку декомпрессия повышает объемы данных для обработки, то FAST процессор может работать на более высокой частоте, чем ядро ETH, что позволит повысить пропускную способность и компенсировать высокий объем данных.
FAST протокол строго последовательный, поскольку начало каждого поля в потоке зависит от предыдущего поля. Даже после того как FAST декодер выровняет данные, все равно будет невозможно обрабатывать поток параллельно. Это ограничения протокола.
К счастью, биржи поставляют данные сразу в несколько фидов. Поэтому можно увеличить пропускную способность и снизить задержки путем параллельной обработки фидов FAST процессором. Каждый FAST процессор работает с отдельным FAST потоком. Пропускная способность может быть значительно увеличена благодаря данному подходу. Каждый FAST процессор использует схему из 5620 таблиц поиска.

Для дальнейшего снижения задержек, когда счет идет на наносекунды, используется интерфейс HyperTransport, предлагаемый компанией AMD для Opetron процессоров. Данная технология позволяет достичь гораздо меньших задержек, чем PCI Express, благодаря тому, что FPGA напрямую подключается к центральному процессору в обход различных промежуточных шин[16]. Данная технология использует HTX слот в системах AMD Opetron.
Устройство было реализовано с помощью синтезируемых конструкций verilog RTL кода и протестировано на FPGA карте основанной на Xilinx Virtex-4 FX100.
Figure 8 схематично иллюстрирует архитектуру HFT устройства. Крайний слева – это HT-ядро, работающее на частоте 200МГц. Далее идет HTAX, соединяющий FAST процессоры, UDP и RegisterFile с HT-ядром. Эта часть работает на максимальной частоте в 160МГц. В правой части, красным цветом показана инфраструктура для обработки сетевых пакетов, соединенная с Gigabit Ethernet MAC, которая работает на частоте 125МГц. Вся архитектура, включая 4 FAST процессора, используют 77 слайсов(slices).
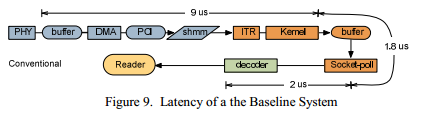
Для выполнения измерений, записанные данные, поставляемые поставщиком фидов, были отправлены на стандартную сетевую карту сервера, расположенному первым, чтобы определить исходную точку для последующих расчетов. Figure 9 показывает поток сообщений в подобной системе. Измеренная задержка для NIC части 9 мкс, для пространства ядра 1.8 мкс и для пользовательского пространства 2 мкс. Общая величина задержки равна 12.8 мкс.
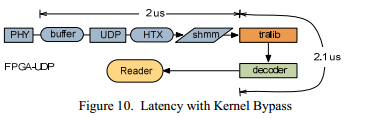
Тот же самый фид затем был послан на FPGA устройство. В первом эксперименте убрали только прохождение фида через ядерное пространство, как показано на Figure 10. Измеренная задержка при прохождении сетевого стека на плате FPGA равна 2 мкс, задержка в пользовательском пространстве 2.1 мкс. Таким образом, величина задержки уже уменьшилась до 4.1 мкс, что уменьшает время выполнения на 62 процента, по сравнению со стандартной реализацией.
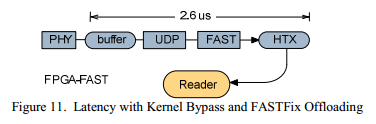
Во втором эксперименте включили FAST процессор, что позволило обрабатывать сообщения в аппаратном устройстве и затем передавать результат в адресное пространство ПО, этот процесс показан на Figure 11. Измеренная величина задержки, когда и сетевой стек и FAST обработка вынесены на FPGA, получилась на 28 процентов меньше, и равняется всего 2.6 мкс. В результате, достигнуто уменьшение задержки в 4 раза, по сравнению со стандартным решением.
Была показана реализация устройства, направленного на оптимизацию HFT, которое способно значительно уменьшить количество времени, требуемого на получение и обработку торговой информации, основанной на FAST. В частности, задержки были снижены в четыре раза, что позволило существенно снизить время раунд-трипа для осуществления сделок.
Особая природа FAST протокола, не позволяющая производить его эффективную обработку на стандартных CPU, делает его весьма привлекательным для реализации на FPGA, со значительным уменьшением временных задержек. Успешная реализация такого подхода и была показана в этой статье.
[1] J.A. Brogaard, “High Frequency Trading and its Impact on Market Quality,” 5th Annual Conference on Empirical Legal Studies, 2010.
[2] M. Chlistalla, “High-frequency trading Better than its reputation?,” Deutsche Bank research report, 2011.
[3] A. Group, New World Order: The High Frequency Trading Community and Its Impact on Market Structure, 2009.
[4] K.H. Chung and Y. Kim, “Volatility, Market Structure, and the Bid-Ask Spread,” Asia-Pacific Journal of Financial Studies, vol. 38, Feb. 2009.
[5] J. Chiu, D. Lukman, K. Modarresi, and A. Velayutham, “Highfrequency trading,” Stanford University Research Report, 2011.
[6] H. Subramoni, F. Petrini, V. Agarwal, and D. Pasetto, “Streaming, lowlatency communication in on-line trading systems,” International Symposium on Parallel & Distributed Processing, Workshops (IPDPSW), 2010.
[7] V. Agarwal, D. a Bader, L. Dan, L.-K. Liu, D. Pasetto, M. Perrone, and F. Petrini, “Faster FAST: multicore acceleration of streaming financial data,” Computer Science — Research and Development, vol. 23, May. 2009.
[8] G.W. Morris, D.B. Thomas, and W. Luk, “FPGA Accelerated LowLatency Market Data Feed Processing,” 2009 17th IEEE Symposium on High Performance Interconnects, Aug. 2009.
[9] F. Herrmann and G. Perin, “An UDP/IP Network Stack in FPGA,” Electronics, Circuits, and Systems (ICECS), 2009.
[10] G.L. Zhang, P.H.W. Leong, C.H. Ho, K.H. Tsoi, C.C.C. Cheung, D. Lee, R.C.C. Cheung, and W. Luk, “Reconfigurable acceleration for Monte Carlo based financial simulation,” IEEE International Conference on Field-Programmable Technology, 2005.
[11] D.B. Thomas, “Acceleration of Financial Monte-Carlo Simulations using FPGAs,” Workshop on High Performance Computational Finance (WHPCF), 2010.
[12] N. a Woods and T. VanCourt, “FPGA acceleration of quasi-Monte Carlo in finance,” 2008 International Conference on Field Programmable Logic and Applications, 2008, pp. 335-340.
[13] M. Sadoghi, M. Labrecque, H. Singh, W. Shum, and H.-arno Jacobsen, “Efficient Event Processing through Reconfigurable Hardware for Algorithmic Trading,” Journal Proceedings of the VLDB Endowment,2010.
[14] S. Tandon, “A Programmable Architecture for Real-time Derivative Trading,” Master Thesis, University of Edinburgh, 2003.
[15] S. Larsen and P. Sarangam, “Architectural Breakdown of End-to-End Latency in a TCP/IP Network,” International Journal of Parallel Programming, Springer, 2009.
[16] D. Slogsnat, A. Giese, M. Nüssle, and U. Brüning, “An open-source HyperTransport core,” ACM Transactions on Reconfigurable Technology and Systems, vol. 1, Sep. 2008, pp. 1-21.
[17] G. Mittal, D.C Zaretsky, P. Banerjee, “Streaming implementation of a sequential decompression algorithm on an FPGA,” International Symposium on Field Programmable Gate Arrays – FPGA09, 2009.
[18] FIX adapted for Streaming, www.fixprotocol.org/fast
Введение
Высокочастотному трейдингу (HFT) уделяется большое внимание в последнее время, и он становится важнейшим игроком на финансовых рынках. Под термином HFT понимается набор техник при торговле акциями и деривативами, когда большой поток заявок отправляется на рынок с раунд-трипом меньше миллисекунды[1]. Цель высокочастотников, это подойди к концу дня без каких-либо позиций ценных бумаг в наличии, а получать прибыль от своих стратегий покупая и продавая акции на очень высокой скорости. Исследования показывают, что HFT трейдеры держат акцию в среднем всего 22 секунды[2]. Aite Group утверждает, что HFT оказывает существенное влияние на рынок, более чем 50% сделок по акциям в США было совершенно HFT в 2010 году, при этом рост только за 2009 год составил 70%[3].
HFT трейдеры используют несколько вариантов стратегий, как например — стратегия по обеспечению ликвидности, стратегия статистического арбитража и стратегия по поиску ликвидности [2]. В стратегии по обеспечению ликвидности, высокочастотники пытаются заработать на спреде спроса-предложения(bid-ask), который отражает разницу, по которой продавцы готовы продать, а покупатели купить. Высокая волатильность и широкий bid-ask спред могут обернуться прибылью для HFT трейдера, и в то же время он становится поставщиком ликвидности и сужает bid-ask спред, как бы исполняя роль маркетмейкера. Ликвидность и маленький ask-bid спред являются важными вещами, поскольку они снижают торговые издержки и позволяют точнее определить стоимость актива[4]. Трейдеры, которые используют арбитражные стратегии, используют корреляцию между ценами производных инструментов и их базовых активов[5]. Стратегии по поиску ликвидности исследуют рынок в поисках крупных заявок, путем посылки небольших приказов, которые помогают обнаружить большие скрытые заявки. Все стратегии объединяет одно, для работы им требуются бескомпромиссно низкие временные задержки, поскольку только самые быстрые HFT компании в состоянии воспользоваться возникающими на рынке возможностями.
Электронная торговля акциями происходит путем посылки запросов в электронной форме на биржу. Заявки на покупку и продажу затем сопоставляются на бирже, и осуществляется сделка. Выставляемые заявки видны всем участникам торгов через так называемые фиды. Фид – это сжатый или несжатый поток данных, поставляемый в реальном времени некой независимой организацией, как например Options Price Reporting Authority (OPRA). Фид содержит финансовую информацию по акциям и передается с помощью мультикаста участникам рынка через стандартизированные протоколы, в основном через Ethernet посредством UDP. Стандартным протоколом поставки рыночных данных является Financial Information Exchange (FIX) Adapted for Streaming (FAST), который используется на большинстве бирж[18].
Для того чтобы добиться минимального времени задержки, HFT движок должен быть оптимизирован на всех уровнях. Для уменьшения времени задержки при передачи по сети используется collocation, когда HFT сервер устанавливается рядом со шлюзом биржи. Фид с данными должен распространятся с минимальными задержками до серверов HFT. Эффективная обработка UDP и FAST пакетов также является необходимой. И наконец, решение о создании заявки и ее передача должны осуществляется с наименьшими возможными задержками. Для достижения этих целей был разработан новый HFT движок, реализованный на плате FPGA. Благодаря использованию FPGA, появилась возможность снять нагрузку по обработке UDP и FAST с центрального процессора и перенести ее на специально оптимизированные блоки платы. В представленной системе, на аппаратном уровне реализован весь цикл обработки, за исключением принятий торговых решений, включая крайне гибкий движок с поддержкой микрокода для обработки FAST сообщений. Подход дает значительное снижение задержек более чем на 70% по сравнению с софтверными решениями и в то же время позволяет гораздо проще изменять или добавлять обработку новых протоколов, чем интегральные схемы специального назначения(Application-specific integrated circuit).
История вопроса
Текущий раздел рассказывает о базовых концепциях и реализации биржевой инфраструктуры. В дополнение, будет рассказано о базовых свойствах протокола FAST, чтобы определить требования к аппаратной реализации.
Инфраструктура для трейдинга
Типичная инфраструктура для трейдинга состоит из нескольких компонентов, контролируемых различными участниками. Это – биржа, поставщик фида и участники рынка, как показано на Figure 1. Движок для сопоставления заявок (матчинга), маршрутизатор дата-центра, и шлюз контролируются биржей. Механизм для фидов предоставляет другая организация. Маршрутизатор для доступа участников рынка – это собственность этих участников, в данном случае HFT фирм.
Порядок работы следующий:
- В движке матчинга образуется благоприятная возможность
- Движок матчинга отправляет об этом уведомление для поставщика фидов
- Движок фидов передает мультикастом эту информацию всем участникам
- Клиент оценивает ситуацию и отвечает заявкой
- Шлюз получает заявку и передает ее в движок матчинга
- Движок матчинга исполняет первую полученную заявку, и сделка считается состоявшейся
Стек протоколов
Для осуществления электронной торговли приходится задействовать несколько уровней сетевого стека. Иллюстрация этих слоев отображена на Figure 2.
- Ethernet(ETH) слой
Самый нижний слой сетевого стека. Предоставляет базовую функциональность для отправки пакетов по сети. Содержит поддержку фреймов и Cyclic Redundancy Check (CRC) для поддержки целостности данных. В дополнение к этому, ETH обеспечивает идентификацию обоих участников с помощью Media Access Control (MAC) адресов.
- IP слой
IP находится на один уровень выше ETH. Широко используемый протокол, группирует компьютеры в логические группы и присваивает каждому конечному узлу уникальный адрес внутри такой группы. Также может использоваться для посылки сообщений многим участникам сразу(мультикаст), и благодаря этому используется на подавляющем большинстве торговых площадок.
- UDP слой
User Datagram Protocol (UDP) используется программными приложениями для посылки сообщений между участниками. Позволяет использовать множественных получателей и отправителей на одном узле и использует проверку целостности данных с помощью контрольной суммы.
- FAST
Протокол FAST был разработан для передачи рыночных данных от биржи до пользователей с помощью фидов. Протокол описывает различные поля и операторы для идентификации ценных бумаг и их цен. Важный аспект данного протокола, это возможность компрессии данных, для снижения объема передаваемых данных, однако же, это привносит дополнительную нагрузку на процессор. Обработка фидов является довольно узким местом, и поэтому вынос этой функциональности на FPGA является хорошей идеей. Более подробное описание протокола будет предоставлено в следующих частях документа.
- Принятие торговых решений
Принятие торговых решений может быть очень сложной и затратной задачей, в зависимости от сложности алгоритмов. В сущности, процесс принятия решение состоит в сравнении заданных параметров с поступающими данными, с использованием математических методов или статистики. Детальный анализ подобных механизмов выходит за рамки этой статьи. В связи с высокой сложностью, принятие торговых решений не выносят на FPGA, а реализуют программными средствами.
Основы FAST протокола
FAST протокол используется поставщиком фидов для передачи финансовой информации участникам рынка. Для снижения нагрузки, несколько сообщений FAST могут быть объединены в одном UDP пакете. Эти сообщения не используют фрейминг и не содержат в себе информацию о размере сообщения. Вместо этого, каждый тип сообщения описывается в шаблоне, который должен быть известен, чтобы правильно обработать поток данных. Большинство поставщиков фидов объявляют свою собственную реализацию протокола, путем поставки собственных независимых спецификаций для шаблонов. Обработка должна проводиться с должным вниманием, так как ошибка в одном сообщении приведет к тому, что будет потерян весь UDP пакет. Шаблоны описывают набор полей, последовательностей и групп. Группы это – набор полей, где каждое поле может содержаться только по одному разу, а последовательности могут содержать наборы повторяющихся полей.
Каждое сообщение начинается с presence map (PMAP) и идентификатора шаблона (TID) как показано на Figure 3. PMAP является маской, и указывает какие именно из объявленных полей, групп и последовательностей содержатся в текущем потоке. Поля могут быть как обязательными, так и необязательными, а также могут содержать связанный с ними оператор. Причем это факт зависит от атрибута presence, а также и от битового флага в PMAP, если к полю привязан оператор. Это добавляет дополнительную сложность, так как заранее неизвестно, потребуется ли обработка PMAP или нет.
TID используется для идентификации шаблона, который потребуется для обработки сообщения. Шаблоны описываются в XML, например,
<template name="This_is_a_template" id="1"> <uInt32 name="first_field"/> <group name="some_group" presence="optional"> <sint64 name="second_field"/> </group> <string name="third_field" presence="optional"/> </template>
В этом примере TID равен 1, а шаблон состоит из двух полей и одной группы. Тип поля может быть строкой, целым числом, дробным числом, 32 или 64 битным, а также типом decimal, где 32 бита будет выделено на показатель степени и 64 бита на мантиссу.
Для снижения нагрузки на сеть передаются только те байты, которые содержат явные значения. Например, только один байт будет передан для 64-битного целого числа со значением ‘1’, несмотря на то, что в памяти это число занимает 64 бита.
Только первые семь бит из каждого переданного байта используются для записи полезных данных, восьмой же бит используется как стоп-бит и служит для разделения полей. Стоп-бит должен быть удален, а оставшиеся 7 бит должны быть объединены, если поле состоит более чем из одного байта.
Допустим, был получен следующий бинарный поток:
10000111 00101010 10111111
На основании подчеркнутых стоп-битов, следует, что эти три байта содержат два поля. Чтобы получить значение первого поля следует заменить восьмой бит значением 0. Результатом будет:
Бинарное значение: 00111111
Шестнадцатеричное значение: 0x63
Второе поле состоит из 2 байт. Чтобы получить настоящее значение, требуется в каждом байте заменить восьмой бит на 0 и совместить оставшиеся части. Результатом будет:
Бинарное значение: 00000011 10101010
Шестнадцатеричное значение: 0x03 0xAA
На самом деле все еще более сложно, так например, поля должны быть обработаны по-разному, в зависимости от их атрибута presence. Необязательное целое число должно уменьшаться на единицу, а обязательное нет.
Операторы предписывают выполнение какого-либо действия c полем, после того как оно было получено, или если поле вовсе не представлено в потоке. Доступные операторы constant, copy, default, delta и increment. Например, constant, говорит о том, что поле всегда содержит одинаковое значение, и, следовательно, никогда не передается в фиде.
Спецификация FAST также предусматривает объявление массива байт, в котором не используются стоп-биты, а все восемь бит в байте используются для передачи полезных данных. Данный массив в свою очередь содержит поле, в котором задается общее количество байт. Это часть спецификации не была реализована в связи с высокой сложностью, и с тем фактом, что она не используется на целевой бирже, в данном случае во Франкфурте.
Похожие работы
В последнее время появилось много литературы по теме, но все-таки большая часть работы выполняется внутри организаций и не публикуется. Очень хороший обзор по оптимизации HFT дан в [6]. Более того, предоставлена система для оптимизации обработки ORPA FAST фида с использованием устройства Myrinet MX. Многопоточный «faster FAST» движок, для использования на многоядерных системах представлен в [7]. Несмотря на то, что обе системы сфокусированы на оптимизации обработки FAST, подход из данной статьи является первым, который использует FPGA. Morris [8] описывает HFT систему, которая использует FPGA для оптимизации обработки UDP/IP, похожую на [9]. Другие связанные темы, это использование FPGA для техник алгоритмической торговли основанной на методе Монте Карло[10], [11], [12]. Sadoghi [13] использует основанные на FPGA технологии для эффективной обработки событий в алгоритмической торговле. Mittal представляет программный FAST декодер, который исполняется на PowerPC 405, который встроен в несколько плат FPGA [13]. И последнее, Tandon опубликовал работу «A Programmable Architecture for Real-time Derivative Trading» [14].
Реализация
Предлагается три различных подхода для уменьшения времени задержек в HFT приложениях. Первый – это оптимизация UDP, второе – аппаратная реализация обработки сообщений FAST, и третье – задействование параллельных аппаратных структур для одновременной обработки нескольких потоков.
Оптимизация UDP
В обычных системах UDP данные приходят на сетевую карту(NIC) в виде необработанных пакетов ETH. Затем NIC передает пакеты в ядро ОС, которое производит проверку контрольной суммы и обрабатывает пакет. Поток выполнения для этого процесса показан на Figure 4. Данный подход показывает высокие временные задержки, вследствие того что используются прерывания для информирования ОС о поступивших пакетах, а также из-за внедрения еще одного дополнительного уровня, который служит для передачи данных в пользовательское пространство – сокетов. Более того, ядро ОС может быть занято другими активностями, что тоже неблагоприятно влияет на времена обработки. Детальный список различных временных задержек, которые появляются в процессе обработки TCP/IP можно найти в [15]. В случае UDP ситуация очень схожа, поскольку разница с TCP начинает появляться только на более высоких уровнях.
Первым и наиболее эффективным подходом для уменьшения задержки будет обход ядра ОС и обработка поступающих пакетов в аппаратной части, как это показано в Figure 5. Следовательно, потребуется поддержка Address Resolution Protocol (ARP), чтобы корректно получать и отправлять пакеты. ARP используется для сопоставления IP адресов с физическими MAC адресами участников.
Для получения мультикаста также потребуется поддержка Internet Group Management Protocol (IGMP), который требуется для подключения и отключения мультикаст групп. Другие протоколы, которые потребуют реализации это ETH, IP и UDP. Все эти протоколы эффективно реализованы, с фокусом на минимально возможные задержки для ETH, IP и UDP. Реализация IGMP и ARP протоколов не является критичной к скорости, поскольку при трейдинге они не участвуют в непосредственной передаче данных. Все контрольные суммы заголовков различных протоколов и ETH CRC вычисляются параллельно, в то время как проверка этих контрольных сумм производится на самом последнем этапе.
Проверенный пакет далее передается на FAST обработчик или на движок DMA, который способен записать необработанные данные в адресное пространство торгового ПО. Пример, когда обработка FAST производится на FPGA, и затем через DMA движок передается в пользовательское приложение, показан на Figure 6.
Аппаратная обработка FAST
Из-за высокой сложности FAST декодер разбит на три независимые части. Как показано на Figure 7, все три части развязаны через FIFO буферы, чтобы компенсировать различную и иногда непредвиденную задержу в каждом из модулей. Поскольку декомпрессия повышает объемы данных для обработки, то FAST процессор может работать на более высокой частоте, чем ядро ETH, что позволит повысить пропускную способность и компенсировать высокий объем данных.
- FAST декомпрессор
FAST декомпрессор обрабатывает стоп-биты и выравнивает каждое поле по длине 64 бит. Это сделано, чтобы все поля имели одинаковый размер, что упрощает обработку на дальнейших этапах.
- Движок микрокода FAST
Так как FAST сообщения сильно различаются, в зависимости от применяемого шаблона, то было принято решение использовать движок микрокода, который был бы достаточно гибок, чтобы использоваться с любой вариацией FAST протокола. Использование частичной реконфигурации, вместо движка микрокода было отвержено из-за высоких временных задержек реконфигурации в несколько миллисекунд.
Данный движок при загрузке устройства запускает программу, которая находится на FPGA, с отдельной процедурой на каждый шаблон. Таблица переходов содержит указатели на нужную процедуру, в зависимости от ID шаблона, этот ID указывается вначале каждого FAST сообщения. Все поля FAST сообщения обрабатываются соответствующей подпрограммой. В зависимости от подпрограммы, содержание поля либо отбрасывается, либо передается на обработку следующему модулю. Бинарный код для движка микрокода реализован в виде языка ассемблера, с помощью простого предметно-ориентированного языка (DSL), который был специально разработан для данных целей. Ассемблерный код для шаблона, который был представлен в примере выше, будет выглядеть следующим образом:
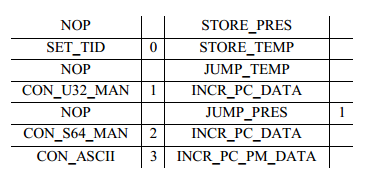
Как можно увидеть, предложенный предметно-ориентированный язык содержит четыре колонки. Две левые колонки описывают данные, которые должны быть обработаны на указанном шаге. Две правые – указывают на команду, которая должна быть исполнена движком микрокода. В частности, первая колонка описывает поле с его атрибутом наличия, вторая сопоставляет поле с уникальным идентификатором, который в дальнейшем может быть обработан программным обеспечением. Третья колонка объявляет конкретную команду управления, которая может увеличивать текущий указатель, перепрыгивать команды, выбирать данные из FIFO буфера или проверять PMAP. Последняя колонка используется для указания цели перехода.
Использование языка ассемблера совместно с движком микрокода упрощает адаптацию FPGA при изменении шаблонов, или даже при переходе на другую биржевую площадку, при этом не потребуется пересматривать архитектуру. Это значительно облегчает работу с FPGA при любых изменениях протокола.
- Движок FAST DMA
Для поставки обработанных данных в программное обеспечение для торговли был разработан движок DMA. Каждое поле в различных шаблонах помечается уникальным идентификатором для его однозначного определения в торговом ПО. Движок DMA передает полученную информацию в кольцевой буфер, который находится в адресном пространстве ПО. Каждая запись состоит из восьми четверных слов, ровно такому значению равен размер кэш-линии в x86 процессоре. Семь из этих четверных слов используются в качестве содержания полей, а восьмое содержит семь идентификаторов для полей представленных во второй колонке таблицы, а также дополнительную информацию по статусу. Информация о статусе также содержит дополнительный бит, который инвертируется каждый раз, когда происходит запись в кольцевой буфер. Использование данного бита позволяет эффективно определять, когда появляются новые данные, без необходимости перезаписывать буфер.
Данная реализация позволяет получить минимально возможный уровень временных задержек при использовании постоянного опроса буфера (поллинга). Поллинг показывает гораздо меньшие времена задержек, чем прерывания. Основная причина высоких задержек при использовании прерываний лежит в том, что приходится переключать контекст исполнения. Однако же выбранный подход приводит к повышенной нагрузке на CPU и повышенному энергопотреблению, но низкие времена задержки перевешивают эти недостатки.
Параллелизм
FAST протокол строго последовательный, поскольку начало каждого поля в потоке зависит от предыдущего поля. Даже после того как FAST декодер выровняет данные, все равно будет невозможно обрабатывать поток параллельно. Это ограничения протокола.
К счастью, биржи поставляют данные сразу в несколько фидов. Поэтому можно увеличить пропускную способность и снизить задержки путем параллельной обработки фидов FAST процессором. Каждый FAST процессор работает с отдельным FAST потоком. Пропускная способность может быть значительно увеличена благодаря данному подходу. Каждый FAST процессор использует схему из 5620 таблиц поиска.
Интерфейс взаимодействия с компьютером
Для дальнейшего снижения задержек, когда счет идет на наносекунды, используется интерфейс HyperTransport, предлагаемый компанией AMD для Opetron процессоров. Данная технология позволяет достичь гораздо меньших задержек, чем PCI Express, благодаря тому, что FPGA напрямую подключается к центральному процессору в обход различных промежуточных шин[16]. Данная технология использует HTX слот в системах AMD Opetron.
Конечная архитектура
Устройство было реализовано с помощью синтезируемых конструкций verilog RTL кода и протестировано на FPGA карте основанной на Xilinx Virtex-4 FX100.
Figure 8 схематично иллюстрирует архитектуру HFT устройства. Крайний слева – это HT-ядро, работающее на частоте 200МГц. Далее идет HTAX, соединяющий FAST процессоры, UDP и RegisterFile с HT-ядром. Эта часть работает на максимальной частоте в 160МГц. В правой части, красным цветом показана инфраструктура для обработки сетевых пакетов, соединенная с Gigabit Ethernet MAC, которая работает на частоте 125МГц. Вся архитектура, включая 4 FAST процессора, используют 77 слайсов(slices).
Выполнение
Для выполнения измерений, записанные данные, поставляемые поставщиком фидов, были отправлены на стандартную сетевую карту сервера, расположенному первым, чтобы определить исходную точку для последующих расчетов. Figure 9 показывает поток сообщений в подобной системе. Измеренная задержка для NIC части 9 мкс, для пространства ядра 1.8 мкс и для пользовательского пространства 2 мкс. Общая величина задержки равна 12.8 мкс.
Тот же самый фид затем был послан на FPGA устройство. В первом эксперименте убрали только прохождение фида через ядерное пространство, как показано на Figure 10. Измеренная задержка при прохождении сетевого стека на плате FPGA равна 2 мкс, задержка в пользовательском пространстве 2.1 мкс. Таким образом, величина задержки уже уменьшилась до 4.1 мкс, что уменьшает время выполнения на 62 процента, по сравнению со стандартной реализацией.
Во втором эксперименте включили FAST процессор, что позволило обрабатывать сообщения в аппаратном устройстве и затем передавать результат в адресное пространство ПО, этот процесс показан на Figure 11. Измеренная величина задержки, когда и сетевой стек и FAST обработка вынесены на FPGA, получилась на 28 процентов меньше, и равняется всего 2.6 мкс. В результате, достигнуто уменьшение задержки в 4 раза, по сравнению со стандартным решением.
Заключение
Была показана реализация устройства, направленного на оптимизацию HFT, которое способно значительно уменьшить количество времени, требуемого на получение и обработку торговой информации, основанной на FAST. В частности, задержки были снижены в четыре раза, что позволило существенно снизить время раунд-трипа для осуществления сделок.
Особая природа FAST протокола, не позволяющая производить его эффективную обработку на стандартных CPU, делает его весьма привлекательным для реализации на FPGA, со значительным уменьшением временных задержек. Успешная реализация такого подхода и была показана в этой статье.
Ссылки
[1] J.A. Brogaard, “High Frequency Trading and its Impact on Market Quality,” 5th Annual Conference on Empirical Legal Studies, 2010.
[2] M. Chlistalla, “High-frequency trading Better than its reputation?,” Deutsche Bank research report, 2011.
[3] A. Group, New World Order: The High Frequency Trading Community and Its Impact on Market Structure, 2009.
[4] K.H. Chung and Y. Kim, “Volatility, Market Structure, and the Bid-Ask Spread,” Asia-Pacific Journal of Financial Studies, vol. 38, Feb. 2009.
[5] J. Chiu, D. Lukman, K. Modarresi, and A. Velayutham, “Highfrequency trading,” Stanford University Research Report, 2011.
[6] H. Subramoni, F. Petrini, V. Agarwal, and D. Pasetto, “Streaming, lowlatency communication in on-line trading systems,” International Symposium on Parallel & Distributed Processing, Workshops (IPDPSW), 2010.
[7] V. Agarwal, D. a Bader, L. Dan, L.-K. Liu, D. Pasetto, M. Perrone, and F. Petrini, “Faster FAST: multicore acceleration of streaming financial data,” Computer Science — Research and Development, vol. 23, May. 2009.
[8] G.W. Morris, D.B. Thomas, and W. Luk, “FPGA Accelerated LowLatency Market Data Feed Processing,” 2009 17th IEEE Symposium on High Performance Interconnects, Aug. 2009.
[9] F. Herrmann and G. Perin, “An UDP/IP Network Stack in FPGA,” Electronics, Circuits, and Systems (ICECS), 2009.
[10] G.L. Zhang, P.H.W. Leong, C.H. Ho, K.H. Tsoi, C.C.C. Cheung, D. Lee, R.C.C. Cheung, and W. Luk, “Reconfigurable acceleration for Monte Carlo based financial simulation,” IEEE International Conference on Field-Programmable Technology, 2005.
[11] D.B. Thomas, “Acceleration of Financial Monte-Carlo Simulations using FPGAs,” Workshop on High Performance Computational Finance (WHPCF), 2010.
[12] N. a Woods and T. VanCourt, “FPGA acceleration of quasi-Monte Carlo in finance,” 2008 International Conference on Field Programmable Logic and Applications, 2008, pp. 335-340.
[13] M. Sadoghi, M. Labrecque, H. Singh, W. Shum, and H.-arno Jacobsen, “Efficient Event Processing through Reconfigurable Hardware for Algorithmic Trading,” Journal Proceedings of the VLDB Endowment,2010.
[14] S. Tandon, “A Programmable Architecture for Real-time Derivative Trading,” Master Thesis, University of Edinburgh, 2003.
[15] S. Larsen and P. Sarangam, “Architectural Breakdown of End-to-End Latency in a TCP/IP Network,” International Journal of Parallel Programming, Springer, 2009.
[16] D. Slogsnat, A. Giese, M. Nüssle, and U. Brüning, “An open-source HyperTransport core,” ACM Transactions on Reconfigurable Technology and Systems, vol. 1, Sep. 2008, pp. 1-21.
[17] G. Mittal, D.C Zaretsky, P. Banerjee, “Streaming implementation of a sequential decompression algorithm on an FPGA,” International Symposium on Field Programmable Gate Arrays – FPGA09, 2009.
[18] FIX adapted for Streaming, www.fixprotocol.org/fast

