Про кэш процессоров написано много, в том числе и на Хабре, но все больше общими словами. Предлагаю вашему вниманию конкретный пример того, как работает кэш в реальной жизни.
В качестве примера я возьму простенькую систему на кристалле, основанную на 32-битном гарвардском RISC-процессоре с одноуровневой кэш-памятью и без MMU (что-то типа ARM Cortex-R). Процессор подключен к контроллеру внешней памяти через 32-битную шину AMBA AHB, работающую на частоте процессора.
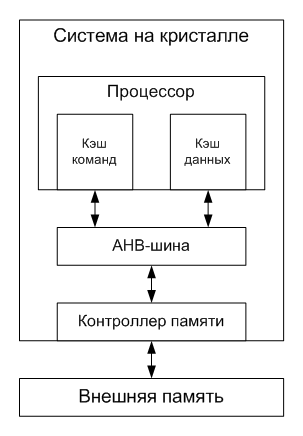
Кэши команд и данных раздельные, прямого отображения, размером по 16 килобайт каждый. Длина строки кэша — 32 байта, то есть каждый кэш содержит по 512 строк. Напомню, что смещение определяет порядковый номер байта внутри строки кэша, а индекс — номер строки кэша в кэш-памяти. Так как кэш прямого отображения, то в нем не могут одновременно находиться несколько строк с одинаковым индексом, даже если тэги у них разные.

Самый простой способ понять, как все это работает — разобраться, что делает процессор сразу после включения питания. Предположим, что кэши по умолчанию включены и инвалидированы (то есть пусты), а во внешней памяти каким-то образом оказалась такая вот программа, складывающая два числа:
После включения процессор начинает выполнять команды с адреса, соответствующего адресу таблицы векторов прерываний. Этот адрес обычно жестко зашит в процессоре. В общем случае он может быть равен чему угодно, но для простоты предположим, что он равен нулю.
Таким образом первая команда нашей программы — «jump _start» — расположена по адресу 0х0, и процессор априори знает ее адрес.
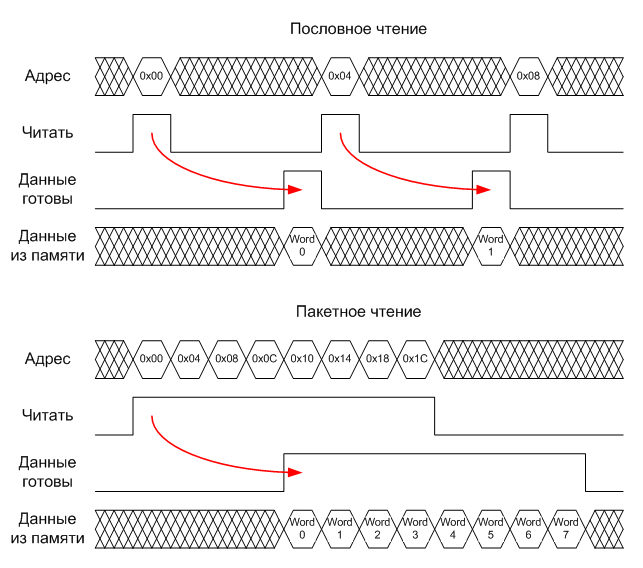
Этап 1. Процессор ищет в кэше команд строку, содержащую команду с адресом 0х0. Поскольку кэш пуст, контроллер кэша внутри процессора сигнализирует о промахе и тут же приостанавливает процессор, одновременно инициируя так называемый «read burst», то есть запрос на чтение пакета данных из внешней памяти. Данные никогда не загружаются в кэш пословно — только пакетами, иначе смысла в кэше вообще нет! Размер пакета данных равен длине строки кэша. Таким образом, запрос занимает 8 тактов, потому что в нашей системе шина AHB может передавать не более 32 битов данных за такт. В идеальном случае запросу понадобится один такт, чтобы дойти до контроллера памяти (если шина будет занята обработкой другого запроса, то тактов понадобится больше). В зависимости от типа внешней памяти контроллер может начать передавать прочитанные данные либо сразу после прихода запроса (если память SSRAM), либо через несколько десятков тактов (в случае SDRAM) — это время называется латентностью памяти. Еще один такт потребуется прочитанным данным, чтобы пройти обратный путь от контроллера памяти до процессора. Ниже приведены временные диаграммы чтения строки кэша из внешней памяти с латентностью в четыре такта.
Этап 2. Контроллер кэша записывает слова, приходящие из памяти, в буфер строки («line buffer»), размер которого равен длине строки кэша. Когда буфер строки будет заполнен, его содержимое будет сохранено в нулевой строке кэша команд (т.к. индекс у адреса 0х0 — это 0). Однако процессор может выполнять команды из буфера напрямую, поэтому как только в буфер будет записана команда, вызвавшая промах, контроллер кэша тут же разблокирует процессор. Поскольку процессор конвейеризирован, он должен будет выбрать из памяти вторую команду еще до того, как первая будет декодирована. Чтобы добится этого, адрес второй команды будет предсказан, и, скорее всего, будет предсказан неверно, в результате чего процессор продолжит выбирать команды с адреса 0х4. Поскольку вторая команда («jump _handler1») к этому моменту также будет находится в буфере, промаха не произойдет, а процессор начнет выбирать третью команду («jump _handler2»). Так будет продолжаться, пока процессор не поймет, что он ошибся с предсказанием и вторая команда должна была быть выбрана по адресу 0х1234.
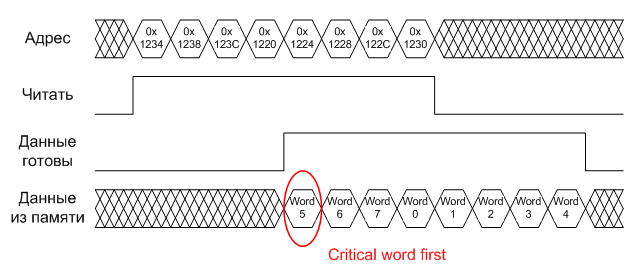
Этап 3. Как только процессор прозреет (а в процессоре со, скажем, семистадийным конвейером команд это займет около семи тактов), он тут же выдаст очередной промах кэша, на этот раз вызванный отсутсвием в кэше строки, содержащей команду по адресу 0х1234 («move R0, 0x10000000»), и пошлет новый «read burst», который по возвращении будет сохранен в 145-ой строке кэша (т.к. индекс у адреса 0х1220 — это 0х91=145). В зависимости от реализации процессор может начать загружать данные в кэш либо с начала строки (т.е. сначала слово по адресу 0х1220, потом 0х1224, 0х1228 и так далее вплоть до 0х123С), либо с того слова, которое вызвало промах (так называемый режим «critical word first» — сначала читается слово по адресу 0х1234, потом 0х1238, 0х123С, 0х1220, 0х1224 и т.д.) В обоих вариантах строка в любом случае загружается полностью, но в первом случае процессор потратит пять лишних тактов на ожидание. Нужно заметить, что многие микроконтроллеры до сих пор не поддерживают «critical word first», поэтому при должном везении программист может добиться значительного падения производительности.
Этап 4. Вне зависимости от того, поддерживается «critical word first» или нет, в кэш будут загружены сразу три корректных команды (до «move R1, 0x10010000» включительно). Когда очередь дойдет до команды «load R10, [R0]», процессор обнаружит промах кэша данных (ведь кэш данных-то пуст — все предыдущие манипуляции происходили с кэшем команд) и пошлет еще один «read burst», который будет записан в нулевую строку (т.к. индекс у адреса 0х10000000 — это 0). Если процессор достаточно умен и сообразителен (а большинство процессоров, чуть более сложных, чем студенческие поделки, достаточно умны для этого), он поймет, что следующая за «load R10, [R0]» команда не зависит от нее и может быть выполнена одновременно с копированием данных в кэш. После этого процессор захочет выбрать команду по адресу 0х1240 и мы получим еще один «read burst», который «зависнет», так как шина все еще будет занята предыдущим запросом от кэша данных. Конечно, рано или поздно команда «load R11, [R1]» попадет таки в кэш команд, и процессор тут же обнаружит новый промах кэша данных, который вдобавок вытеснит из кэша загруженную ранее строку с тэгом 0x04000 (так как адреса 0х10000000 и 0х10010000 отличаются только тэгами — 0x04000 и 0x04800 соответственно, а индекс у обоих равен нулю).
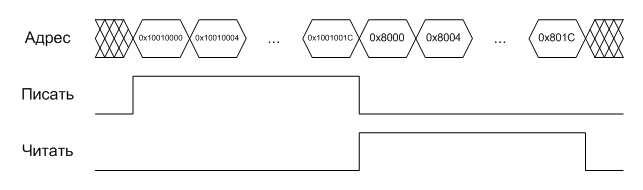
Этап 5. В конце концов процессор выполнит команду «store R2, [R3]», которая вызовет еще один промах кэша данных и, как следствие, еще один «read burst», и вдобавок вытеснит из кэша строку с тэгом 0x04800, заменив ее на строку с тэгом 0x08000. Кроме того, нужно помнить, что эта команда ничего не запишет во внешнюю память, потому что запись будет произведена только в кэш! Никакого «write burst» не будет до тех пор, пока программист явно не позабоится о том, чтобы «слить» обновленную строку кэша обратно в память (то есть сделать cache line flush), либо пока строка не будет вытеснена из кэша другой строкой. Например, если бы вместо команды «halt» была команда «load r4, [0x8000]», то процесс чтения выглядел бы так:
Напоследок хотелось бы сказать вот что: ошибки, связанные с неправильным использованием кэшей, можно искать месяцами. Компиляторы, кэширующие volatile-ы, и память, которая вопреки заветам товарища фон Неймана изменяет сама себя, тому свидетели. «Прозрачность» кэшей — это миф, который годится разве что для сферических программистов на вакуумном PHP. Поэтому если в вашем процессоре есть кэш — выключите его от греха подальше!
В качестве примера я возьму простенькую систему на кристалле, основанную на 32-битном гарвардском RISC-процессоре с одноуровневой кэш-памятью и без MMU (что-то типа ARM Cortex-R). Процессор подключен к контроллеру внешней памяти через 32-битную шину AMBA AHB, работающую на частоте процессора.
Кэши команд и данных раздельные, прямого отображения, размером по 16 килобайт каждый. Длина строки кэша — 32 байта, то есть каждый кэш содержит по 512 строк. Напомню, что смещение определяет порядковый номер байта внутри строки кэша, а индекс — номер строки кэша в кэш-памяти. Так как кэш прямого отображения, то в нем не могут одновременно находиться несколько строк с одинаковым индексом, даже если тэги у них разные.
Самый простой способ понять, как все это работает — разобраться, что делает процессор сразу после включения питания. Предположим, что кэши по умолчанию включены и инвалидированы (то есть пусты), а во внешней памяти каким-то образом оказалась такая вот программа, складывающая два числа:
# таблица векторов прерываний расположена с адреса 0х0
_reset_vector:
0x0000: jump _start
_interrupt1:
0x0004: jump _handler1
_interrupt2:
0x0008: jump _handler2
...
# основной код программы расположен с адреса 0x1234
_start:
# загружаем первый операнд из памяти в регистр R10
0x1234: moveh R0, 0x1000 # загружаем 0х1000 в R0[31:16]
0x1238: load R10, [R0] # загружаем в R10 значение из 0x10000000
# загружаем второй операнд из памяти в регистр R11
0x123C: moveh R1, 0x1001 # загружаем 0х1001 в R1[31:16]
0x1240: load R11, [R1] # загружаем в R11 значение из 0x10010000
# складываем операнды и записываем результат в память
0x1244: add R2, R0, R1
0x1248: moveh R3, 0x2000 # загружаем 0х2000 в R3[31:16]
0x124C: store R2, [R3] # сохраняем R2 по адресу из R3
# останавливаем процессор
0x1250: haltПосле включения процессор начинает выполнять команды с адреса, соответствующего адресу таблицы векторов прерываний. Этот адрес обычно жестко зашит в процессоре. В общем случае он может быть равен чему угодно, но для простоты предположим, что он равен нулю.
Таким образом первая команда нашей программы — «jump _start» — расположена по адресу 0х0, и процессор априори знает ее адрес.
Этап 1. Процессор ищет в кэше команд строку, содержащую команду с адресом 0х0. Поскольку кэш пуст, контроллер кэша внутри процессора сигнализирует о промахе и тут же приостанавливает процессор, одновременно инициируя так называемый «read burst», то есть запрос на чтение пакета данных из внешней памяти. Данные никогда не загружаются в кэш пословно — только пакетами, иначе смысла в кэше вообще нет! Размер пакета данных равен длине строки кэша. Таким образом, запрос занимает 8 тактов, потому что в нашей системе шина AHB может передавать не более 32 битов данных за такт. В идеальном случае запросу понадобится один такт, чтобы дойти до контроллера памяти (если шина будет занята обработкой другого запроса, то тактов понадобится больше). В зависимости от типа внешней памяти контроллер может начать передавать прочитанные данные либо сразу после прихода запроса (если память SSRAM), либо через несколько десятков тактов (в случае SDRAM) — это время называется латентностью памяти. Еще один такт потребуется прочитанным данным, чтобы пройти обратный путь от контроллера памяти до процессора. Ниже приведены временные диаграммы чтения строки кэша из внешней памяти с латентностью в четыре такта.
Этап 2. Контроллер кэша записывает слова, приходящие из памяти, в буфер строки («line buffer»), размер которого равен длине строки кэша. Когда буфер строки будет заполнен, его содержимое будет сохранено в нулевой строке кэша команд (т.к. индекс у адреса 0х0 — это 0). Однако процессор может выполнять команды из буфера напрямую, поэтому как только в буфер будет записана команда, вызвавшая промах, контроллер кэша тут же разблокирует процессор. Поскольку процессор конвейеризирован, он должен будет выбрать из памяти вторую команду еще до того, как первая будет декодирована. Чтобы добится этого, адрес второй команды будет предсказан, и, скорее всего, будет предсказан неверно, в результате чего процессор продолжит выбирать команды с адреса 0х4. Поскольку вторая команда («jump _handler1») к этому моменту также будет находится в буфере, промаха не произойдет, а процессор начнет выбирать третью команду («jump _handler2»). Так будет продолжаться, пока процессор не поймет, что он ошибся с предсказанием и вторая команда должна была быть выбрана по адресу 0х1234.
Этап 3. Как только процессор прозреет (а в процессоре со, скажем, семистадийным конвейером команд это займет около семи тактов), он тут же выдаст очередной промах кэша, на этот раз вызванный отсутсвием в кэше строки, содержащей команду по адресу 0х1234 («move R0, 0x10000000»), и пошлет новый «read burst», который по возвращении будет сохранен в 145-ой строке кэша (т.к. индекс у адреса 0х1220 — это 0х91=145). В зависимости от реализации процессор может начать загружать данные в кэш либо с начала строки (т.е. сначала слово по адресу 0х1220, потом 0х1224, 0х1228 и так далее вплоть до 0х123С), либо с того слова, которое вызвало промах (так называемый режим «critical word first» — сначала читается слово по адресу 0х1234, потом 0х1238, 0х123С, 0х1220, 0х1224 и т.д.) В обоих вариантах строка в любом случае загружается полностью, но в первом случае процессор потратит пять лишних тактов на ожидание. Нужно заметить, что многие микроконтроллеры до сих пор не поддерживают «critical word first», поэтому при должном везении программист может добиться значительного падения производительности.
Этап 4. Вне зависимости от того, поддерживается «critical word first» или нет, в кэш будут загружены сразу три корректных команды (до «move R1, 0x10010000» включительно). Когда очередь дойдет до команды «load R10, [R0]», процессор обнаружит промах кэша данных (ведь кэш данных-то пуст — все предыдущие манипуляции происходили с кэшем команд) и пошлет еще один «read burst», который будет записан в нулевую строку (т.к. индекс у адреса 0х10000000 — это 0). Если процессор достаточно умен и сообразителен (а большинство процессоров, чуть более сложных, чем студенческие поделки, достаточно умны для этого), он поймет, что следующая за «load R10, [R0]» команда не зависит от нее и может быть выполнена одновременно с копированием данных в кэш. После этого процессор захочет выбрать команду по адресу 0х1240 и мы получим еще один «read burst», который «зависнет», так как шина все еще будет занята предыдущим запросом от кэша данных. Конечно, рано или поздно команда «load R11, [R1]» попадет таки в кэш команд, и процессор тут же обнаружит новый промах кэша данных, который вдобавок вытеснит из кэша загруженную ранее строку с тэгом 0x04000 (так как адреса 0х10000000 и 0х10010000 отличаются только тэгами — 0x04000 и 0x04800 соответственно, а индекс у обоих равен нулю).
Этап 5. В конце концов процессор выполнит команду «store R2, [R3]», которая вызовет еще один промах кэша данных и, как следствие, еще один «read burst», и вдобавок вытеснит из кэша строку с тэгом 0x04800, заменив ее на строку с тэгом 0x08000. Кроме того, нужно помнить, что эта команда ничего не запишет во внешнюю память, потому что запись будет произведена только в кэш! Никакого «write burst» не будет до тех пор, пока программист явно не позабоится о том, чтобы «слить» обновленную строку кэша обратно в память (то есть сделать cache line flush), либо пока строка не будет вытеснена из кэша другой строкой. Например, если бы вместо команды «halt» была команда «load r4, [0x8000]», то процесс чтения выглядел бы так:
Напоследок хотелось бы сказать вот что: ошибки, связанные с неправильным использованием кэшей, можно искать месяцами. Компиляторы, кэширующие volatile-ы, и память, которая вопреки заветам товарища фон Неймана изменяет сама себя, тому свидетели. «Прозрачность» кэшей — это миф, который годится разве что для сферических программистов на вакуумном PHP. Поэтому если в вашем процессоре есть кэш — выключите его от греха подальше!

