
На днях вышел новый стабильный релиз
mongodb. В этой версии был добавлен ряд нововведений таких как новый GUI для визуальной работы с mongodb, LEFT JOIN, валидация документа и т.д. некоторые из этих свойств мы и рассмотрим на небольших примерах ниже. - Частичный ( partial ) индекс
- Валидация
- Нововведения агрегационного фреймворка
- Новые опции в утилитах импорта экспорта
- Нововведения в CRUD
- WiredTiger и fsyncLock
- Новое GUI compass
Частичный ( partial ) индекс
MongoDB 3.2 предоставляет возможность создавать индексы только для тех документов коллекции, которые которые будут соответствовать указанному фильтру. Индексация только части нужных документов в коллекции, имеет ряд плюсов, таких как более низкие требования к хранению, и снижение затрат на производительность, для создания и поддержания индекса. Вы можете указать опцию partialFilterExpression для всех типов индекса MongoDB.Для создания частичного индекса используется метод
db.collection.createIndex() с новой опцией partialFilterExpression. В следующем примере создадим составной индекс, который будет индексировать только те документы, у которых рейтинг больше 5.db.restaurants.createIndex( { cuisine: 1, name: 1 }, { partialFilterExpression: { rating: { $gt: 5 } } } )
Сравнение с разреженным индексом.
Частичный индекс предоставляет больший набор возможностей, чем разреженный индекс и поэтому является более предпочтительным. Частичный индекс, предлагает более выразительный механизм, для указания какие документы лучше индексировать.
Разреженные индексы выбирают документы для индексации исключительно на основании наличия индексированного поля.
Пример поведения разреженного индекса с помощью частичного индекса:
db.contacts.createIndex( { name: 1 }, { partialFilterExpression: { name: { $exists: true } } } )
Рассмотрим еще один пример с частичным индексом, тут поле по которому будет проводиться индексирование
name, а поле, по которому будут отфильтрованы документы, другое:db.contacts.createIndex( { name: 1 }, { partialFilterExpression: { email: { $exists: true } } } )
Следующий запрос может использовать индекс:
db.contacts.find( { name: "xyz", email: { $regex: /\.org$/ } } )
А для этого запроса индекс не может быть использован:
db.contacts.find( { name: "xyz", email: { $exists: false } } )
Ограничения
В
mongodb нельзя создавать несколько версий индекса, отличающихся только параметрами. Нельзя создавать много частичных индексов, которые отличаются только параметрами фильтра.В более ранних версиях
mongodb не поддерживались частичные индексы. Все sharded кластеры, наборы реплик и все узлы должны работать на mongodb 3.2._id индекс не может быть частичным индексом.Ключ также шарда не может быть частичным индексом.
Рассмотрим коллекцию
restaurants, содержащую следующие документы и выглядящие таким образом:{ "_id" : ObjectId("5641f6a7522545bc535b5dc9"), "address" : { "building" : "1007", "coord" : [ -73.856077, 40.848447 ], "street" : "Morris Park Ave", "zipcode" : "10462" }, "borough" : "Bronx", "cuisine" : "Bakery", "rating" : { "date" : ISODate("2014-03-03T00:00:00Z"), "grade" : "A", "score" : 2 }, "name" : "Morris Park Bake Shop", "restaurant_id" : "30075445" }
Мы могли бы добавить индекс на поля
borough и cuisine отфильтровав только те документы где rating.grade == Adb.restaurants.createIndex( { borough: 1, cuisine: 1 }, { partialFilterExpression: { 'rating.grade': { $eq: "A" } } } )
Следующий запрос по коллекции
restaurants использующий частичный индекс вернет все рестораны находящиеся в Bronx где rating.grade эквивалентный Adb.restaurants.find( { borough: "Bronx", 'rating.grade': "A" } )
А этот запрос, не сможет использовать индекс, потому что нет полей, соответствующих
rating.gradedb.restaurants.find( { borough: "Bronx", cuisine: "Bakery" } )
Частичный индекс с ограничением уникальности
Частичный индекс может быть применен к документам, которые содержат ограничение уникальности.
Для примера возьмем коллекцию
users содержащую следующие документы:{ "_id" : ObjectId("56424f1efa0358a27fa1f99a"), "username" : "david", "age" : 29 } { "_id" : ObjectId("56424f37fa0358a27fa1f99b"), "username" : "amanda", "age" : 35 } { "_id" : ObjectId("56424fe2fa0358a27fa1f99c"), "username" : "rajiv", "age" : 57 }
Следующая операция, создаст индекс, который накладывает уникальное ограничение на поле
username и частичный фильтр для выражения age: { $gte: 21 }db.users.createIndex( { username: 1 }, { unique: true, partialFilterExpression: { age: { $gte: 21 } } } )
Индекс предотвращает вставку следующих документов, потому что документы с указанным именем уже существуют и поле
age больше 21:db.users.insert( { username: "david", age: 27 } ) db.users.insert( { username: "amanda", age: 25 } ) db.users.insert( { username: "rajiv", age: 32 } )
А эти документы будут вставлены:
db.users.insert( { username: "david", age: 20 } ) db.users.insert( { username: "amanda" } ) db.users.insert( { username: "rajiv", age: null } )
Валидация
Начиная с версии
3.2, mongodb, предоставляет возможность проверки документов в процессе обновления и вставки. Правила валидации задаются при явном создании коллекции с помощью опции validator, либо с помощью команды collMod для уже существующей коллекции. Опция validator принимает документ, который соответствует определённым выражениям, за исключением $geoNear, $near, $nearSphere, $text и $where.Рассмотрим следующий пример создания валидации при создании коллекции
contacts:db.createCollection( "contacts", { validator: { $or: [ { phone: { $type: "string" } }, { email: { $regex: /@mongodb\.com$/ } }, { status: { $in: [ "Unknown", "Incomplete" ] } } ] } } )
MongoDB также предоставляет опцию validationLevel, которая определяет, насколько строго MongoDB применяет правила валидации, для существующих документов во время их обновления, и опция validationAction, которая определяет, должен ли mongodb отклонить документы, которые нарушают правила проверки.Поведение
Валидация происходит во время обновления и вставки документов. При добавлении валидации в коллекцию, уже существующие документы не модифицируются.
Существующие документы
Можно контролировать как
mongodb обрабатывает существующие документы используя опцию validationLevel. По умолчанию,
validationLevel является strict, и mongodb применяет правила проверки для всех вставок и обновлений. Если validationLevel установлен как moderate, то тогда правила валидации при вставке и обновлении документов, применяются только к документам, которые полностью соответствуют критериям валидации.Рассмотрим следующие документы в коллекции
contacts:{ "_id": "125876" "name": "Anne", "phone": "+1 555 123 456", "city": "London", "status": "Complete" }, { "_id": "860000", "name": "Ivan", "city": "Vancouver" }
Выполним команду, чтобы добавить валидацию в коллекцию
contacts:db.runCommand( { collMod: "contacts", validator: { $or: [ { phone: { $exists: true } }, { email: { $exists: true } } ] }, validationLevel: "moderate" } )
Теперь в коллекции
contacts есть валидатор. И теперь если мы будем обновлять документ с {_id: 125876}, mongodb будет применять правила валидации, поскольку существующий документ соответствует критериям. А для документа { _id:860000 }, mongodb не применит правила валидации на обновления, так как документ не соответствует правилу проверки.Если нам нужно отключить валидацию, мы можем установить опцию
validationLevel как off.Принять или отклонить бракованные документыВ опции validationAction, определяется как поступить с документами которые нарушили правила валидации.
По умолчанию validationAction, выставлен как error и MongoDB отклоняет любые вставки и обновления документов, если есть нарушение правила проверки. Когда validationAction установлен как warn, MongoDB журналирует документы, но позволяет выполнять вставки и обновления.
В следующем примере создается коллекция contacts с валидатором, указывающим, что вставленные или обновленные документы должны соответствовать по крайней мере одному из трех следующих условий:
- поле
phone должно быть строкой
- поле
email должно проверятся регулярным выражением на соответствие
- поле
status должно быть либо Unknown либо Incomplete.
db.createCollection( "contacts",
{
validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
],
validationAction: "warn"
}
}
)
Следующий инсерт должен привести к сбою, но, поскольку, правило валидации validationAction установлено как warn, то операция записи запишет в журнал и выполнится успешно.
2015-10-15T11:20:44.260-0400 W STORAGE [conn3] Document would fail validation collection: example.contacts doc: { _id: ObjectId('561fc44c067a5d85b96274e4'), name: "Amanda", status: "Updated" }
Ограничения
Нельзя назначать валидацию для коллекций admin, local.
И нельзя указать валидатор для коллекций system.*
Нововведения агрегационного фреймворка и LEFT JOIN
$lookup - связывание нескольких коллекций.
Хоть этот оператор и назвали свой left join для mongodb мне все-таки кажется, что этот вопрос немного шире, и его надо рассматривать в контексте связывания разных типов документов, а не коллекций. Я описывал этот вопрос довольно подробно тут.
Сам $lookup имеет следующий синтаксис:
{
$lookup:
{
from: <коллекция для связывания>,
localField: <поле из входящий документов>,
foreignField: <поле из документов из другой коллекции>,
as: <исходящий массив>
}
}
В примере у нас есть две коллекции:
Коллекция orders в которой находятся следующие документы:
{ "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2 }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1 }
{ "_id" : 3 }
И коллекция inventory содержащая документы:
{ "_id" : 1, "sku" : "abc", description: "product 1", "instock" : 120 }
{ "_id" : 2, "sku" : "def", description: "product 2", "instock" : 80 }
{ "_id" : 3, "sku" : "ijk", description: "product 3", "instock" : 60 }
{ "_id" : 4, "sku" : "jkl", description: "product 4", "instock" : 70 }
{ "_id" : 5, "sku": null, description: "Incomplete" }
{ "_id" : 6 }
Следующая агрегационная операция, для коллекции orders, свяжет документы из orders, с документами из коллекции inventory, используя поле item из orders и поле sku из inventory:
db.orders.aggregate([
{
$lookup:
{
from: "inventory",
localField: "item",
foreignField: "sku",
as: "inventory_docs"
}
}
])
На выходе эта операция возвратит следующие документы:
{
"_id" : 1,
"item" : "abc",
"price" : 12,
"quantity" : 2,
"inventory_docs" : [
{ "_id" : 1, "sku" : "abc", description: "product 1", "instock" : 120 }
]
}
{
"_id" : 2,
"item" : "jkl",
"price" : 20,
"quantity" : 1,
"inventory_docs" : [
{ "_id" : 4, "sku" : "jkl", "description" : "product 4", "instock" : 70 }
]
}
{
"_id" : 3,
"inventory_docs" : [
{ "_id" : 5, "sku" : null, "description" : "Incomplete" },
{ "_id" : 6 }
]
}
$sample - случайным образом, выбирает заданное количество документов из входного потока.
Синтаксис:
{ $sample: { size: <positive integer> } }
В примере у нас есть коллекция users, состоящая из следующих документов:
{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true }
{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false }
{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true }
{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false }
{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true }
{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true }
{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }
Агрегационная операция выберет в случайном порядке три документа из коллекции:
db.users.aggregate(
[ { $sample: { size: 3 } } ]
)
В PostgreSQL 9.5, который вот-вот должен выйти, тоже появилась похожая возможность.
$indexStats - возвращает статистику использования каждого индекса.
Возвращает статистику использования каждого индекса для коллекции. Если запущена с контролем доступа, пользователь должен иметь привилегии, которые включают indexStats.
Синтаксис:
{ $indexStats: { } }
Для примера возьмем коллекцию orders, содержащую следующие документы:
{ "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2, "type": "apparel" }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "type": "electronics" }
{ "_id" : 3, "item" : "abc", "price" : 10, "quantity" : 5, "type": "apparel" }
Создадим на коллекции следующие два индекса:
db.orders.createIndex( { item: 1, quantity: 1 } )
db.orders.createIndex( { type: 1, item: 1 } )
Выполним какие-то запросы:
db.orders.find( { type: "apparel"} )
db.orders.find( { item: "abc" } ).sort( { quantity: 1 } )
Для просмотра статистики по использованию индекса для коллекции orders выполним следующую операцию:
db.orders.aggregate( [ { $indexStats: { } } ] )
Операция возвратит документы, содержащие использование статистики для каждого индекса:
{
"name" : "item_1_quantity_1",
"key" : { "item" : 1, "quantity" : 1 },
"host" : "examplehost.local:27017",
"accesses" : {
"ops" : NumberLong(1),
"since" : ISODate("2015-10-02T14:31:53.685Z")
}
}
{
"name" : "_id_",
"key" : { "_id" : 1 },
"host" : "examplehost.local:27017",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2015-10-02T14:31:32.479Z")
}
}
{
"name" : "type_1_item_1",
"key" : { "type" : 1, "item" : 1 },
"host" : "examplehost.local:27017",
"accesses" : {
"ops" : NumberLong(1),
"since" : ISODate("2015-10-02T14:31:58.321Z")
}
}
$stdDevSamp - вычисляет стандартное отклонение выборки входных значений.
Доступен из $group и $project, игнорирует не цифровые значения и, если такое передано, возвращает null.
Для примера возьмем коллекцию users:
{_id: 0, username: "user0", age: 20}
{_id: 1, username: "user1", age: 42}
{_id: 2, username: "user2", age: 28}
Чтобы рассчитать стандартное отклонение случайной выборки пользователей, сначала используем оператор $sample для выборки 100 пользователей, и тогда используем $stdDevSamp для калькуляции.
db.users.aggregate(
[
{ $sample: { size: 100 } },
{ $group: { _id: null, ageStdDev: { $stdDevSamp: "$age" } } }
]
)
Результат:
{ "_id" : null, "ageStdDev" : 7.811258386185771 }
Новые агрегационные арифметические операторы
$sqrt - вычисляет квадратный корень.
Синтаксис
{ $sqrt: <number> }
Простые примеры:
{ $sqrt: 25 } 5
{ $sqrt: 30 } 5.477225575051661
{ $sqrt: null } null
Есть коллекция points с документами:
{ _id: 1, p1: { x: 5, y: 8 }, p2: { x: 0, y: 5} }
{ _id: 2, p1: { x: -2, y: 1 }, p2: { x: 1, y: 5} }
{ _id: 3, p1: { x: 4, y: 4 }, p2: { x: 4, y: 0} }
Следующий пример, использует $sqrt, для вычисления расстояния между p1 и p2:
db.points.aggregate([
{
$project: {
distance: {
$sqrt: {
$add: [
{ $pow: [ { $subtract: [ "$p2.y", "$p1.y" ] }, 2 ] },
{ $pow: [ { $subtract: [ "$p2.x", "$p1.x" ] }, 2 ] }
]
}
}
}
}
])
На выходе следующий результат:
{ "_id" : 1, "distance" : 5.830951894845301 }
{ "_id" : 2, "distance" : 5 }
{ "_id" : 3, "distance" : 4 }
$abs - возвращает абсолютное значение числа.
Синтаксис
{ $abs: <number> }
Простой пример:
{ $abs: -1 } 1
{ $abs: 1 } 1
{ $abs: null } null
В коллекции ratings есть документы:
{ _id: 1, start: 5, end: 8 }
{ _id: 2, start: 4, end: 4 }
{ _id: 3, start: 9, end: 7 }
{ _id: 4, start: 6, end: 7 }
В следующем примере вычисляется величина разности между начальным и конечным рейтингами:
db.ratings.aggregate([
{
$project: { delta: { $abs: { $subtract: [ "$start", "$end" ] } } }
}
])
На выходе:
{ "_id" : 1, "delta" : 3 }
{ "_id" : 2, "delta" : 0 }
{ "_id" : 3, "delta" : 2 }
{ "_id" : 4, "delta" : 1 }
$log - рассчитывает логарифм.
Синтаксис
{ $log: [ <number>, <base> ] }
Рассчитывает логарифм числа, и возвращает результат в виде дроби.
Есть коллекция examples:
{ _id: 1, positiveInt: 5 }
{ _id: 2, positiveInt: 2 }
{ _id: 3, positiveInt: 23 }
{ _id: 4, positiveInt: 10 }
В следующем примере используется log2, чтобы определить число битов, требуемых для представления значения .
Результат:
{ "_id" : 1, "bitsNeeded" : 3 }
{ "_id" : 2, "bitsNeeded" : 2 }
{ "_id" : 3, "bitsNeeded" : 5 }
{ "_id" : 4, "bitsNeeded" : 4 }
$ln - вычисляет натуральный логарифм числа.
Синтаксис
{ $ln: <number> }
{ _id: 1, year: "2000", sales: 8700000 }
{ _id: 2, year: "2005", sales: 5000000 }
{ _id: 3, year: "2010", sales: 6250000 }
В следующем примере, преобразуются данные о продажах:
db.sales.aggregate( [ { $project: { x: "$year", y: { $ln: "$sales" } } } ] )
Результат:
{ "_id" : 1, "x" : "2000", "y" : 15.978833583624812 }
{ "_id" : 2, "x" : "2005", "y" : 15.424948470398375 }
{ "_id" : 3, "x" : "2010", "y" : 15.648092021712584 }
$pow - возводит число в заданную экспоненту (возведение в степень).
Синтаксис:
{ $pow: [ <number>, <exponent> ] }
Примеры:
{ $pow: [ 5, 0 ] } 1
{ $pow: [ 5, 2 ] } 25
{ $pow: [ 5, -2 ] } 0.04
{
"_id" : 1,
"scores" : [
{ "name" : "dave123", "score" : 85 },
{ "name" : "dave2", "score" : 90 },
{ "name" : "ahn", "score" : 71 }
]
}
{
"_id" : 2,
"scores" : [
{ "name" : "li", "quiz" : 2, "score" : 96 },
{ "name" : "annT", "score" : 77 },
{ "name" : "ty", "score" : 82 }
]
}
Следующий пример, вычисляет расхождения для каждого опроса:
db.quizzes.aggregate([
{ $project: { variance: { $pow: [ { $stdDevPop: "$scores.score" }, 2 ] } } }
])
Результат:
{ "_id" : 1, "variance" : 64.66666666666667 }
{ "_id" : 2, "variance" : 64.66666666666667 }
$exp - возводит в степень Эйлеровское число.
Синтаксис
{ exp: <number> }
Пример:
{ $exp: 0 } 1
{ $exp: 2 } 7.38905609893065
{ $exp: -2 } 0.1353352832366127
$trunc - Усекает число в его целое.
Синтаксис:
{ $trunc: <number> }
{ $trunc: 0 } 0
{ $trunc: 7.80 } 7
{ $trunc: -2.3 } -2
$ceil - Возвращает наименьшее целое значение, большее или равное указанному количеству.
Синтаксис:
{ $ceil: <number> }
{ $ceil: 1 } 1
{ $ceil: 7.80 } 8
{ $ceil: -2.8 } -2
$floor - возвращает наибольшее целое значение, меньшее или равное указанному количеству.
Синтаксис:
{ floor: <number> }
Примеры:
{ $floor: 1 } 1
{ $floor: 7.80 } 7
{ $floor: -2.8 } -3
{ _id: 1, value: 9.25 }
{ _id: 2, value: 8.73 }
{ _id: 3, value: 4.32 }
{ _id: 4, value: -5.34 }
db.samples.aggregate([
{ $project: { value: 1, floorValue: { $floor: "$value" } } }
])
{ "_id" : 1, "value" : 9.25, "floorValue" : 9 }
{ "_id" : 2, "value" : 8.73, "floorValue" : 8 }
{ "_id" : 3, "value" : 4.32, "floorValue" : 4 }
{ "_id" : 4, "value" : -5.34, "floorValue" : -6 }
Новые агрегационные операторы для работы с массивами
$slice - Возвращает подмножество массива.
Синтаксис:
{ $slice: [ <array>, <n> ] }
или
{ $slice: [ <array>, <position>, <n> ] }
{ "_id" : 1, "name" : "dave123", favorites: [ "chocolate", "cake", "butter", "apples" ] }
{ "_id" : 2, "name" : "li", favorites: [ "apples", "pudding", "pie" ] }
{ "_id" : 3, "name" : "ahn", favorites: [ "pears", "pecans", "chocolate", "cherries" ] }
{ "_id" : 4, "name" : "ty", favorites: [ "ice cream" ] }
В следующем примере, возвращается первые три элемента массива в favorites для каждого пользователя:
db.users.aggregate([
{ $project: { name: 1, threeFavorites: { $slice: [ "$favorites", 3 ] } } }
])
{ "_id" : 1, "name" : "dave123", "threeFavorites" : [ "chocolate", "cake", "butter" ] }
{ "_id" : 2, "name" : "li", "threeFavorites" : [ "apples", "pudding", "pie" ] }
{ "_id" : 3, "name" : "ahn", "threeFavorites" : [ "pears", "pecans", "chocolate" ] }
{ "_id" : 4, "name" : "ty", "threeFavorites" : [ "ice cream" ] }
$arrayElemAt - возвращает элемент по указанному индексу в массиве.
Синтаксис:
{ $arrayElemAt: [ <array>, <idx> ] }
Пример:
{ $arrayElemAt: [ [ 1, 2, 3 ], 0 ] } 1
{ $arrayElemAt: [ [ 1, 2, 3 ], -2 ] } 2
{ $arrayElemAt: [ [ 1, 2, 3 ], 15 ] }
$concatArrays - конкатенация массива.
Синтаксис:
{ $concatArrays: [ <array1>, <array2>, ... ] }
Пример:
{ $concatArrays: [ [ "hello", " "], [ "world" ] ] } [ "hello", " ", "world" ]
{ $concatArrays: [ [ "hello", " "], [ [ "world" ], "again"] ] } [ "hello", " ", [ "world" ], "again" ]
$isArray - определяет, является ли операнд является массивом.
Синтаксис
{ $isArray: [ ] }
В примере есть коллекция warehouses содержащая следующие документы:
{ "_id" : 1, instock: [ "chocolate" ], ordered: [ "butter", "apples" ] }
{ "_id" : 2, instock: [ "apples", "pudding", "pie" ] }
{ "_id" : 3, instock: [ "pears", "pecans"], ordered: [ "cherries" ] }
{ "_id" : 4, instock: [ "ice cream" ], ordered: [ ] }
Мы проверяем, что содержимое и поля instock, и поля ordered, являются массивами, и тогда конкатенируем их, иначе выводим надпись, что это не так:
db.warehouses.aggregate([
{ $project:
{ items:
{ $cond:
{
if: { $and: [ { $isArray: "$instock" }, { $isArray: "$ordered" } ] },
then: { $concatArrays: [ "$instock", "$ordered" ] },
else: "One or more fields is not an array."
}
}
}
}
])
{ "_id" : 1, "items" : [ "chocolate", "butter", "apples" ] }
{ "_id" : 2, "items" : "One or more fields is not an array." }
{ "_id" : 3, "items" : [ "pears", "pecans", "cherries" ] }
{ "_id" : 4, "items" : [ "ice cream" ] }
$filter - выбирает подмножество массива по условию.
Синтаксис
{
$filter:
{
input: <array>,
as: <string>,
cond: <expression>
}
}
Пример:
{
$filter: {
input: [ 1, "a", 2, null, 3.1, NumberLong(4), "5" ],
as: "num",
cond: { $and: [
{ $gte: [ "$$num", NumberLong("-9223372036854775807") ] },
{ $lte: [ "$$num", NumberLong("9223372036854775807") ] }
] }
}
}
[ 1, 2, 3.1, NumberLong(4) ]
Новое для оператора $project
В mongodb 3.2, оператор $project, стал поддерживать использование квадратных скобок [], чтобы непосредственно создавать новый массив из полей.
В примере есть документ:
{ "_id" : ObjectId("55ad167f320c6be244eb3b95"), "x" : 1, "y" : 1 }
Оператор $project из элементов x и y создает новое поле myArray:
db.collection.aggregate( [ { $project: { myArray: [ "$x", "$y" ] } } ] )
Результат:
{ "_id" : ObjectId("55ad167f320c6be244eb3b95"), "myArray" : [ 1, 1 ] }
Новые опции в утилитах импорта, экспорта
mongorestore и mongodump теперь поддерживают работу с архивами, и не надо, если в базе много коллекций, каждый раз для копирования упаковывать.
Следующая команда распакует из архива test.20150715.archive базу данных test. И импортирует её.
mongorestore --archive=test.20150715.archive --db test
Чтобы экспортировать данные из ввода, нужно запускать mongorestore с опцией archive не указывая имя файла. Например:
mongodump --archive --db test --port 27017 | mongorestore --archive --port 27018
Нововведения в CRUD
Для согласования с CRUD (Create/Read/Update/Delete) API драйверов, для mongo shell были добавлены дополнительные методы.
db.collection.bulkWrite() - Выполняет несколько операций записи, с элементами управления для порядка исполнения.
Следующий код, представляет собой неупорядоченный bulkWrite(), из шести операций:
db.collection.bulkWrite(
[
{ insertOne : <document> },
{ updateOne : <document> },
{ updateMany : <document> },
{ replaceOne : <document> },
{ deleteOne : <document> },
{ deleteMany : <document> }
],
{ ordered : false }
)
С ordered : false, результаты работы могут отличаться. Например, deleteOne или deleteMany может удалить больше или меньше документов в зависимости от порядка расположения операций insertOne, updateOne, updateMany или replaceOne.
db.collection.deleteMany() - эквивалент db.collection.remove().
db.collection.deleteOne() - эквивалент db.collection.remove() но с justOne установленным как true
Например - db.collection.remove( , true ) или db.collection.remove( , { justOne: true } ).
db.collection.findOneAndDelete() - эквивалент db.collection.findAndModify() но с remove установленным как true.
db.collection.findOneAndReplace() - эквивалент db.collection.findAndModify().
db.collection.findOneAndUpdate() - эквивалент db.collection.findAndModify() но с установленными для update атомарными операторами.
db.collection.insertMany() - эквивалент db.collection.insert() с массивом документов в качестве параметра.
db.collection.insertOne() - эквивалент db.collection.insert() в качестве параметра один документ.
db.collection.replaceOne() - эквивалент метода db.collection.update( , ) для обновления документа как параметра для .
db.collection.updateMany() - эквивалент db.collection.update( , , { multi: true, ... }) с использованием опции multi установленной как true.
db.collection.updateOne() - эквивалент db.collection.update( , )
WiredTiger и fsyncLock
Начиная с MongoDB 3.2, хранилище WiredTiger поддерживает команду fsync с опцией lock или метода mongo shell db.fsyncLock(). То есть, для хранилища WiredTiger, эти операции могут гарантировать, что файлы данных не изменятся, обеспечивая согласованность в при создании резервных копий.
Также в этой версии WiredTiger является хранилищем по умолчанию.
Новое GUI compass
В новом Mongodb, впервые, от разработчиков появилось GUI причем не не одно. Начнем с MongoDB Compass. После первого анонса когда кроме картинки еще ничего не было я подумал что compass скорее всего будет c web интерфейсом. Моей первой nosql базой был couchdb и тогда мне очень нравился futon.
Но оказалось что compass, является обычной десктопной программой, и к сожалению только под Mac OS и Windows. И насколько я понял без возможности редактирования, а только с возможностью просмотра документов, и с возможностью делать запросы.
Итак, чтоб локально немного поиграться с этим GUI поставим под Windows mongoDB и немного настроим, чтобы все заработало:
Скачиваем, при установке лучше выбирать “вручную” и указать место для установки C:\mongodb.
После этого запустим от имени администратора консоль и создадим несколько папок:
mkdir c:\data\db
mkdir c:\data\log
А потом создав в каталоге с установкой C:\mongodb\mongod.cfg файлик впишем там пару строчек:
systemLog:
destination: file
path: c:\data\log\mongod.log
storage:
dbPath: c:\data\db
Дальше сделаем mongodb сервисом:
"C:\mongodb\bin\mongod.exe" --config "C:\mongodb\mongod.cfg" --install
И запустим этот сервис:
net start MongoDB
В принципе, всё. Но у меня не получилось приконнектиться к базе пока я не запустил в консоли клиент к монго, c:\mongodb\mongo.exe
После этого скачиваем по ссылке сам compass, там надо символически заполнить пару полей и устанавливаем. После этого запускаем и видим окошко приветствия:

Если все удачно то коннектимся и в открывшемся окне, видим слева список коллекций и баз, по центру визуальное представление документов находящихся в выделенной коллекции. Представление предназначено исключительно для составления запросов, кои сверху в строке видны.
Ну а справа, в колонке, если её открыть с помощью специальной стрелочки (наверное, единственная полезная штука) эти самые документы в виде json.
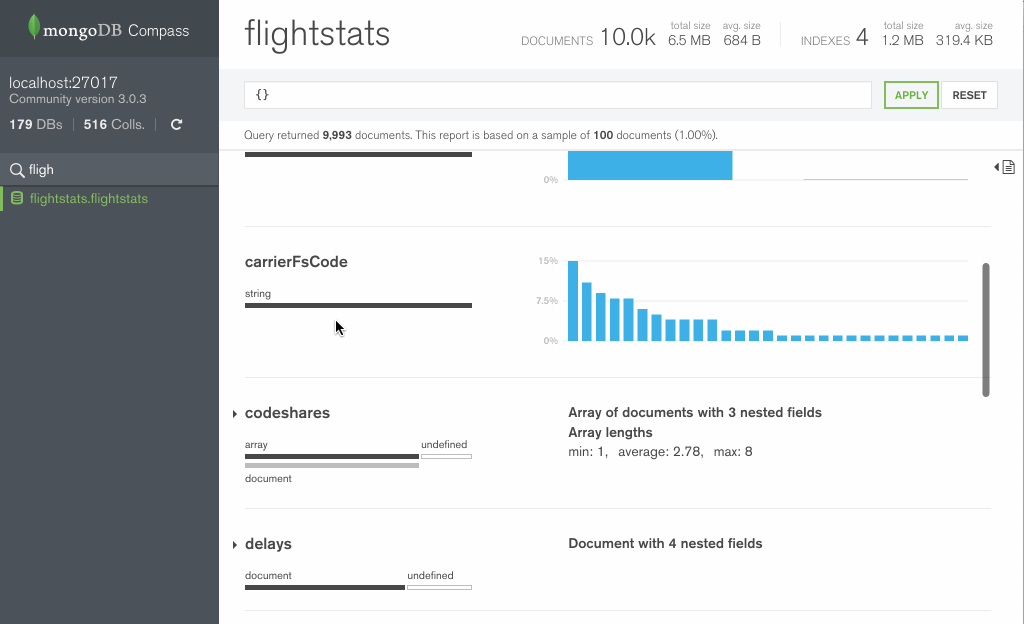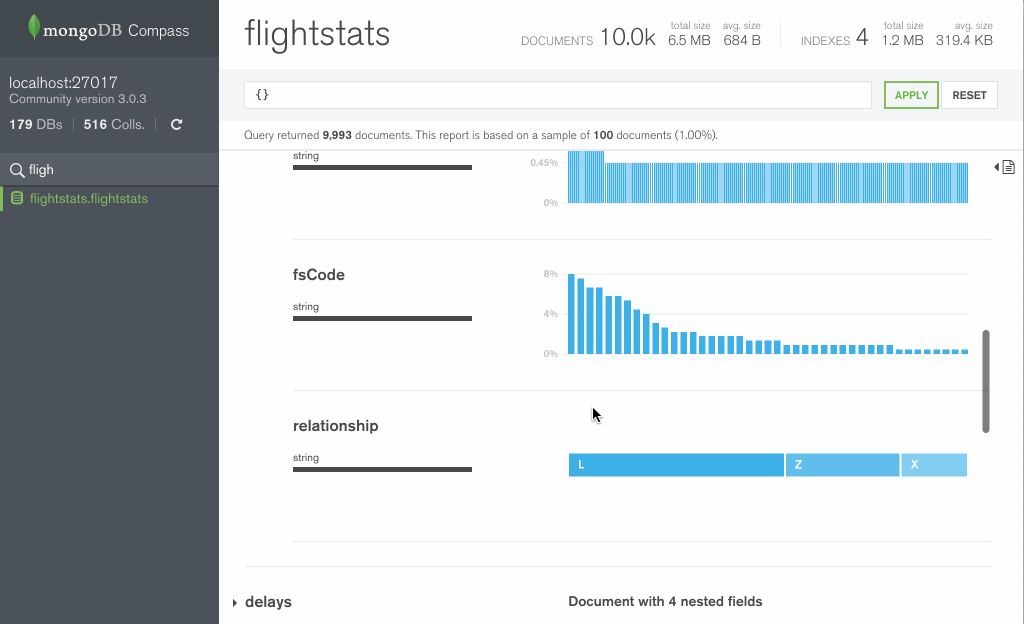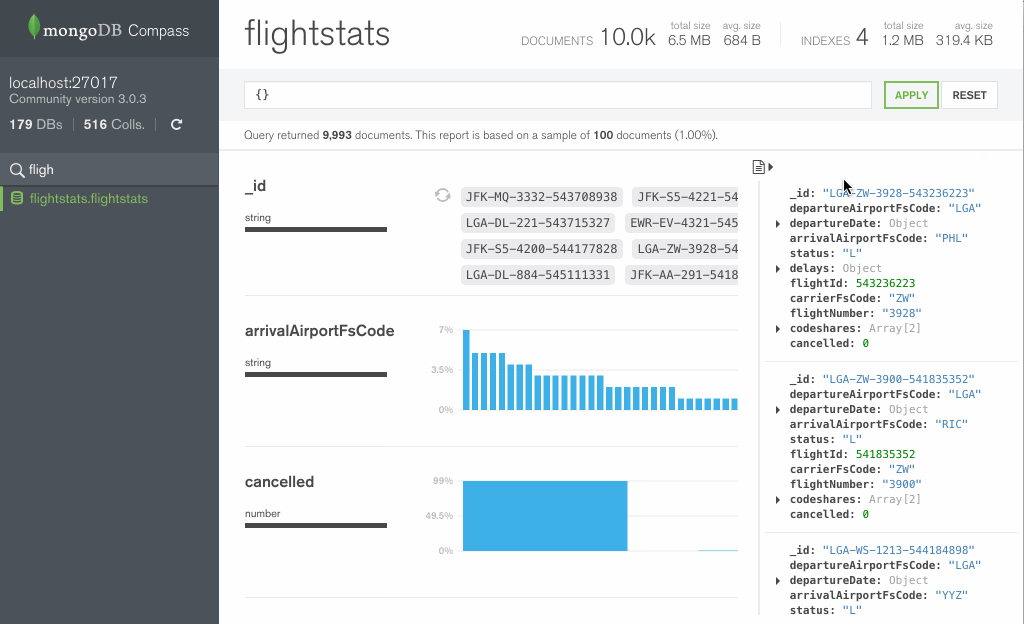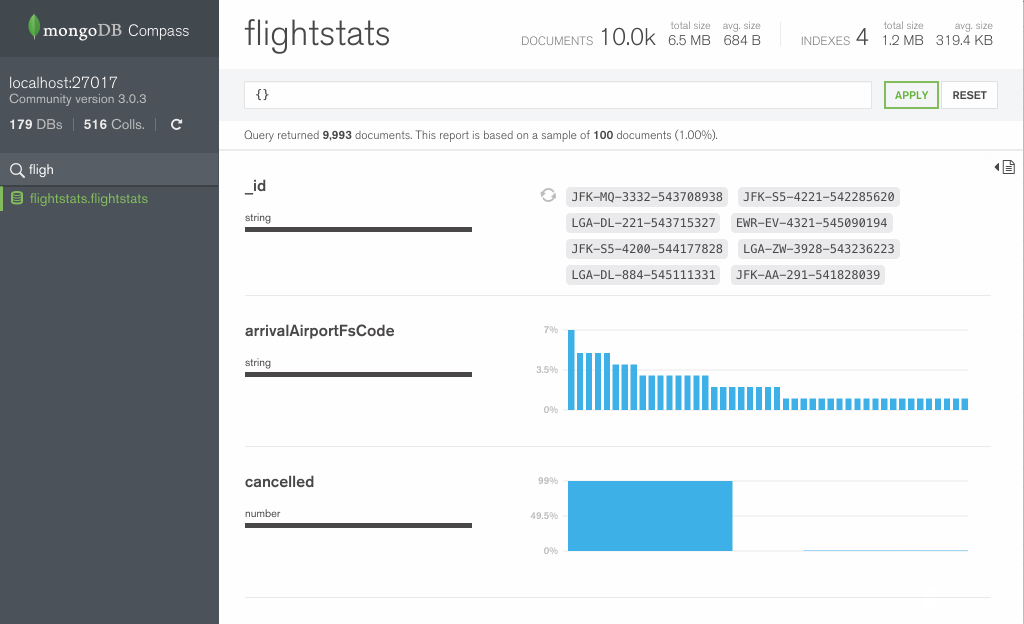
В целом, общие впечатления такие, что GUI это скорее имиджевый ход, чем несущий какую-то реальную пользу сообществу.
P.S. Просьба о грамматических ошибках и ошибках перевода писать в личку.
Установка mongodb под windows
Справка по compass
Скачать mongodb compass
Документация по новым свойствам
Частичный индекс
Валидация документов
validationAction, определяется как поступить с документами которые нарушили правила валидации. По умолчанию
validationAction, выставлен как error и MongoDB отклоняет любые вставки и обновления документов, если есть нарушение правила проверки. Когда validationAction установлен как warn, MongoDB журналирует документы, но позволяет выполнять вставки и обновления.В следующем примере создается коллекция
contacts с валидатором, указывающим, что вставленные или обновленные документы должны соответствовать по крайней мере одному из трех следующих условий:- поле
phoneдолжно быть строкой - поле
emailдолжно проверятся регулярным выражением на соответствие - поле
statusдолжно быть либо Unknown либо Incomplete.
db.createCollection( "contacts", { validator: { $or: [ { phone: { $type: "string" } }, { email: { $regex: /@mongodb\.com$/ } }, { status: { $in: [ "Unknown", "Incomplete" ] } } ], validationAction: "warn" } } )
Следующий инсерт должен привести к сбою, но, поскольку, правило валидации
validationAction установлено как warn, то операция записи запишет в журнал и выполнится успешно.
2015-10-15T11:20:44.260-0400 W STORAGE [conn3] Document would fail validation collection: example.contacts doc: { _id: ObjectId('561fc44c067a5d85b96274e4'), name: "Amanda", status: "Updated" }
Ограничения
Нельзя назначать валидацию для коллекций admin, local.
И нельзя указать валидатор для коллекций system.*
Нововведения агрегационного фреймворка и LEFT JOIN
$lookup - связывание нескольких коллекций.
Хоть этот оператор и назвали свой left join для mongodb мне все-таки кажется, что этот вопрос немного шире, и его надо рассматривать в контексте связывания разных типов документов, а не коллекций. Я описывал этот вопрос довольно подробно тут.
Сам $lookup имеет следующий синтаксис:
{
$lookup:
{
from: <коллекция для связывания>,
localField: <поле из входящий документов>,
foreignField: <поле из документов из другой коллекции>,
as: <исходящий массив>
}
}
В примере у нас есть две коллекции:
Коллекция orders в которой находятся следующие документы:
{ "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2 }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1 }
{ "_id" : 3 }
И коллекция inventory содержащая документы:
{ "_id" : 1, "sku" : "abc", description: "product 1", "instock" : 120 }
{ "_id" : 2, "sku" : "def", description: "product 2", "instock" : 80 }
{ "_id" : 3, "sku" : "ijk", description: "product 3", "instock" : 60 }
{ "_id" : 4, "sku" : "jkl", description: "product 4", "instock" : 70 }
{ "_id" : 5, "sku": null, description: "Incomplete" }
{ "_id" : 6 }
Следующая агрегационная операция, для коллекции orders, свяжет документы из orders, с документами из коллекции inventory, используя поле item из orders и поле sku из inventory:
db.orders.aggregate([
{
$lookup:
{
from: "inventory",
localField: "item",
foreignField: "sku",
as: "inventory_docs"
}
}
])
На выходе эта операция возвратит следующие документы:
{
"_id" : 1,
"item" : "abc",
"price" : 12,
"quantity" : 2,
"inventory_docs" : [
{ "_id" : 1, "sku" : "abc", description: "product 1", "instock" : 120 }
]
}
{
"_id" : 2,
"item" : "jkl",
"price" : 20,
"quantity" : 1,
"inventory_docs" : [
{ "_id" : 4, "sku" : "jkl", "description" : "product 4", "instock" : 70 }
]
}
{
"_id" : 3,
"inventory_docs" : [
{ "_id" : 5, "sku" : null, "description" : "Incomplete" },
{ "_id" : 6 }
]
}
$sample - случайным образом, выбирает заданное количество документов из входного потока.
Синтаксис:
{ $sample: { size: <positive integer> } }
В примере у нас есть коллекция users, состоящая из следующих документов:
{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true }
{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false }
{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true }
{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false }
{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true }
{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true }
{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }
Агрегационная операция выберет в случайном порядке три документа из коллекции:
db.users.aggregate(
[ { $sample: { size: 3 } } ]
)
В PostgreSQL 9.5, который вот-вот должен выйти, тоже появилась похожая возможность.
$indexStats - возвращает статистику использования каждого индекса.
Возвращает статистику использования каждого индекса для коллекции. Если запущена с контролем доступа, пользователь должен иметь привилегии, которые включают indexStats.
Синтаксис:
{ $indexStats: { } }
Для примера возьмем коллекцию orders, содержащую следующие документы:
{ "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2, "type": "apparel" }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "type": "electronics" }
{ "_id" : 3, "item" : "abc", "price" : 10, "quantity" : 5, "type": "apparel" }
Создадим на коллекции следующие два индекса:
db.orders.createIndex( { item: 1, quantity: 1 } )
db.orders.createIndex( { type: 1, item: 1 } )
Выполним какие-то запросы:
db.orders.find( { type: "apparel"} )
db.orders.find( { item: "abc" } ).sort( { quantity: 1 } )
Для просмотра статистики по использованию индекса для коллекции orders выполним следующую операцию:
db.orders.aggregate( [ { $indexStats: { } } ] )
Операция возвратит документы, содержащие использование статистики для каждого индекса:
{
"name" : "item_1_quantity_1",
"key" : { "item" : 1, "quantity" : 1 },
"host" : "examplehost.local:27017",
"accesses" : {
"ops" : NumberLong(1),
"since" : ISODate("2015-10-02T14:31:53.685Z")
}
}
{
"name" : "_id_",
"key" : { "_id" : 1 },
"host" : "examplehost.local:27017",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2015-10-02T14:31:32.479Z")
}
}
{
"name" : "type_1_item_1",
"key" : { "type" : 1, "item" : 1 },
"host" : "examplehost.local:27017",
"accesses" : {
"ops" : NumberLong(1),
"since" : ISODate("2015-10-02T14:31:58.321Z")
}
}
$stdDevSamp - вычисляет стандартное отклонение выборки входных значений.
Доступен из $group и $project, игнорирует не цифровые значения и, если такое передано, возвращает null.
Для примера возьмем коллекцию users:
{_id: 0, username: "user0", age: 20}
{_id: 1, username: "user1", age: 42}
{_id: 2, username: "user2", age: 28}
Чтобы рассчитать стандартное отклонение случайной выборки пользователей, сначала используем оператор $sample для выборки 100 пользователей, и тогда используем $stdDevSamp для калькуляции.
db.users.aggregate(
[
{ $sample: { size: 100 } },
{ $group: { _id: null, ageStdDev: { $stdDevSamp: "$age" } } }
]
)
Результат:
{ "_id" : null, "ageStdDev" : 7.811258386185771 }
Новые агрегационные арифметические операторы
$sqrt - вычисляет квадратный корень.
Синтаксис
{ $sqrt: <number> }
Простые примеры:
{ $sqrt: 25 } 5
{ $sqrt: 30 } 5.477225575051661
{ $sqrt: null } null
Есть коллекция points с документами:
{ _id: 1, p1: { x: 5, y: 8 }, p2: { x: 0, y: 5} }
{ _id: 2, p1: { x: -2, y: 1 }, p2: { x: 1, y: 5} }
{ _id: 3, p1: { x: 4, y: 4 }, p2: { x: 4, y: 0} }
Следующий пример, использует $sqrt, для вычисления расстояния между p1 и p2:
db.points.aggregate([
{
$project: {
distance: {
$sqrt: {
$add: [
{ $pow: [ { $subtract: [ "$p2.y", "$p1.y" ] }, 2 ] },
{ $pow: [ { $subtract: [ "$p2.x", "$p1.x" ] }, 2 ] }
]
}
}
}
}
])
На выходе следующий результат:
{ "_id" : 1, "distance" : 5.830951894845301 }
{ "_id" : 2, "distance" : 5 }
{ "_id" : 3, "distance" : 4 }
$abs - возвращает абсолютное значение числа.
Синтаксис
{ $abs: <number> }
Простой пример:
{ $abs: -1 } 1
{ $abs: 1 } 1
{ $abs: null } null
В коллекции ratings есть документы:
{ _id: 1, start: 5, end: 8 }
{ _id: 2, start: 4, end: 4 }
{ _id: 3, start: 9, end: 7 }
{ _id: 4, start: 6, end: 7 }
В следующем примере вычисляется величина разности между начальным и конечным рейтингами:
db.ratings.aggregate([
{
$project: { delta: { $abs: { $subtract: [ "$start", "$end" ] } } }
}
])
На выходе:
{ "_id" : 1, "delta" : 3 }
{ "_id" : 2, "delta" : 0 }
{ "_id" : 3, "delta" : 2 }
{ "_id" : 4, "delta" : 1 }
$log - рассчитывает логарифм.
Синтаксис
{ $log: [ <number>, <base> ] }
Рассчитывает логарифм числа, и возвращает результат в виде дроби.
Есть коллекция examples:
{ _id: 1, positiveInt: 5 }
{ _id: 2, positiveInt: 2 }
{ _id: 3, positiveInt: 23 }
{ _id: 4, positiveInt: 10 }
В следующем примере используется log2, чтобы определить число битов, требуемых для представления значения .
Результат:
{ "_id" : 1, "bitsNeeded" : 3 }
{ "_id" : 2, "bitsNeeded" : 2 }
{ "_id" : 3, "bitsNeeded" : 5 }
{ "_id" : 4, "bitsNeeded" : 4 }
$ln - вычисляет натуральный логарифм числа.
Синтаксис
{ $ln: <number> }
{ _id: 1, year: "2000", sales: 8700000 }
{ _id: 2, year: "2005", sales: 5000000 }
{ _id: 3, year: "2010", sales: 6250000 }
В следующем примере, преобразуются данные о продажах:
db.sales.aggregate( [ { $project: { x: "$year", y: { $ln: "$sales" } } } ] )
Результат:
{ "_id" : 1, "x" : "2000", "y" : 15.978833583624812 }
{ "_id" : 2, "x" : "2005", "y" : 15.424948470398375 }
{ "_id" : 3, "x" : "2010", "y" : 15.648092021712584 }
$pow - возводит число в заданную экспоненту (возведение в степень).
Синтаксис:
{ $pow: [ <number>, <exponent> ] }
Примеры:
{ $pow: [ 5, 0 ] } 1
{ $pow: [ 5, 2 ] } 25
{ $pow: [ 5, -2 ] } 0.04
{
"_id" : 1,
"scores" : [
{ "name" : "dave123", "score" : 85 },
{ "name" : "dave2", "score" : 90 },
{ "name" : "ahn", "score" : 71 }
]
}
{
"_id" : 2,
"scores" : [
{ "name" : "li", "quiz" : 2, "score" : 96 },
{ "name" : "annT", "score" : 77 },
{ "name" : "ty", "score" : 82 }
]
}
Следующий пример, вычисляет расхождения для каждого опроса:
db.quizzes.aggregate([
{ $project: { variance: { $pow: [ { $stdDevPop: "$scores.score" }, 2 ] } } }
])
Результат:
{ "_id" : 1, "variance" : 64.66666666666667 }
{ "_id" : 2, "variance" : 64.66666666666667 }
$exp - возводит в степень Эйлеровское число.
Синтаксис
{ exp: <number> }
Пример:
{ $exp: 0 } 1
{ $exp: 2 } 7.38905609893065
{ $exp: -2 } 0.1353352832366127
$trunc - Усекает число в его целое.
Синтаксис:
{ $trunc: <number> }
{ $trunc: 0 } 0
{ $trunc: 7.80 } 7
{ $trunc: -2.3 } -2
$ceil - Возвращает наименьшее целое значение, большее или равное указанному количеству.
Синтаксис:
{ $ceil: <number> }
{ $ceil: 1 } 1
{ $ceil: 7.80 } 8
{ $ceil: -2.8 } -2
$floor - возвращает наибольшее целое значение, меньшее или равное указанному количеству.
Синтаксис:
{ floor: <number> }
Примеры:
{ $floor: 1 } 1
{ $floor: 7.80 } 7
{ $floor: -2.8 } -3
{ _id: 1, value: 9.25 }
{ _id: 2, value: 8.73 }
{ _id: 3, value: 4.32 }
{ _id: 4, value: -5.34 }
db.samples.aggregate([
{ $project: { value: 1, floorValue: { $floor: "$value" } } }
])
{ "_id" : 1, "value" : 9.25, "floorValue" : 9 }
{ "_id" : 2, "value" : 8.73, "floorValue" : 8 }
{ "_id" : 3, "value" : 4.32, "floorValue" : 4 }
{ "_id" : 4, "value" : -5.34, "floorValue" : -6 }
Новые агрегационные операторы для работы с массивами
$slice - Возвращает подмножество массива.
Синтаксис:
{ $slice: [ <array>, <n> ] }
или
{ $slice: [ <array>, <position>, <n> ] }
{ "_id" : 1, "name" : "dave123", favorites: [ "chocolate", "cake", "butter", "apples" ] }
{ "_id" : 2, "name" : "li", favorites: [ "apples", "pudding", "pie" ] }
{ "_id" : 3, "name" : "ahn", favorites: [ "pears", "pecans", "chocolate", "cherries" ] }
{ "_id" : 4, "name" : "ty", favorites: [ "ice cream" ] }
В следующем примере, возвращается первые три элемента массива в favorites для каждого пользователя:
db.users.aggregate([
{ $project: { name: 1, threeFavorites: { $slice: [ "$favorites", 3 ] } } }
])
{ "_id" : 1, "name" : "dave123", "threeFavorites" : [ "chocolate", "cake", "butter" ] }
{ "_id" : 2, "name" : "li", "threeFavorites" : [ "apples", "pudding", "pie" ] }
{ "_id" : 3, "name" : "ahn", "threeFavorites" : [ "pears", "pecans", "chocolate" ] }
{ "_id" : 4, "name" : "ty", "threeFavorites" : [ "ice cream" ] }
$arrayElemAt - возвращает элемент по указанному индексу в массиве.
Синтаксис:
{ $arrayElemAt: [ <array>, <idx> ] }
Пример:
{ $arrayElemAt: [ [ 1, 2, 3 ], 0 ] } 1
{ $arrayElemAt: [ [ 1, 2, 3 ], -2 ] } 2
{ $arrayElemAt: [ [ 1, 2, 3 ], 15 ] }
$concatArrays - конкатенация массива.
Синтаксис:
{ $concatArrays: [ <array1>, <array2>, ... ] }
Пример:
{ $concatArrays: [ [ "hello", " "], [ "world" ] ] } [ "hello", " ", "world" ]
{ $concatArrays: [ [ "hello", " "], [ [ "world" ], "again"] ] } [ "hello", " ", [ "world" ], "again" ]
$isArray - определяет, является ли операнд является массивом.
Синтаксис
{ $isArray: [ ] }
В примере есть коллекция warehouses содержащая следующие документы:
{ "_id" : 1, instock: [ "chocolate" ], ordered: [ "butter", "apples" ] }
{ "_id" : 2, instock: [ "apples", "pudding", "pie" ] }
{ "_id" : 3, instock: [ "pears", "pecans"], ordered: [ "cherries" ] }
{ "_id" : 4, instock: [ "ice cream" ], ordered: [ ] }
Мы проверяем, что содержимое и поля instock, и поля ordered, являются массивами, и тогда конкатенируем их, иначе выводим надпись, что это не так:
db.warehouses.aggregate([
{ $project:
{ items:
{ $cond:
{
if: { $and: [ { $isArray: "$instock" }, { $isArray: "$ordered" } ] },
then: { $concatArrays: [ "$instock", "$ordered" ] },
else: "One or more fields is not an array."
}
}
}
}
])
{ "_id" : 1, "items" : [ "chocolate", "butter", "apples" ] }
{ "_id" : 2, "items" : "One or more fields is not an array." }
{ "_id" : 3, "items" : [ "pears", "pecans", "cherries" ] }
{ "_id" : 4, "items" : [ "ice cream" ] }
$filter - выбирает подмножество массива по условию.
Синтаксис
{
$filter:
{
input: <array>,
as: <string>,
cond: <expression>
}
}
Пример:
{
$filter: {
input: [ 1, "a", 2, null, 3.1, NumberLong(4), "5" ],
as: "num",
cond: { $and: [
{ $gte: [ "$$num", NumberLong("-9223372036854775807") ] },
{ $lte: [ "$$num", NumberLong("9223372036854775807") ] }
] }
}
}
[ 1, 2, 3.1, NumberLong(4) ]
Новое для оператора $project
В mongodb 3.2, оператор $project, стал поддерживать использование квадратных скобок [], чтобы непосредственно создавать новый массив из полей.
В примере есть документ:
{ "_id" : ObjectId("55ad167f320c6be244eb3b95"), "x" : 1, "y" : 1 }
Оператор $project из элементов x и y создает новое поле myArray:
db.collection.aggregate( [ { $project: { myArray: [ "$x", "$y" ] } } ] )
Результат:
{ "_id" : ObjectId("55ad167f320c6be244eb3b95"), "myArray" : [ 1, 1 ] }
Новые опции в утилитах импорта, экспорта
mongorestore и mongodump теперь поддерживают работу с архивами, и не надо, если в базе много коллекций, каждый раз для копирования упаковывать.
Следующая команда распакует из архива test.20150715.archive базу данных test. И импортирует её.
mongorestore --archive=test.20150715.archive --db test
Чтобы экспортировать данные из ввода, нужно запускать mongorestore с опцией archive не указывая имя файла. Например:
mongodump --archive --db test --port 27017 | mongorestore --archive --port 27018
Нововведения в CRUD
Для согласования с CRUD (Create/Read/Update/Delete) API драйверов, для mongo shell были добавлены дополнительные методы.
db.collection.bulkWrite() - Выполняет несколько операций записи, с элементами управления для порядка исполнения.
Следующий код, представляет собой неупорядоченный bulkWrite(), из шести операций:
db.collection.bulkWrite(
[
{ insertOne : <document> },
{ updateOne : <document> },
{ updateMany : <document> },
{ replaceOne : <document> },
{ deleteOne : <document> },
{ deleteMany : <document> }
],
{ ordered : false }
)
С ordered : false, результаты работы могут отличаться. Например, deleteOne или deleteMany может удалить больше или меньше документов в зависимости от порядка расположения операций insertOne, updateOne, updateMany или replaceOne.
db.collection.deleteMany() - эквивалент db.collection.remove().
db.collection.deleteOne() - эквивалент db.collection.remove() но с justOne установленным как true
Например - db.collection.remove( , true ) или db.collection.remove( , { justOne: true } ).
db.collection.findOneAndDelete() - эквивалент db.collection.findAndModify() но с remove установленным как true.
db.collection.findOneAndReplace() - эквивалент db.collection.findAndModify().
db.collection.findOneAndUpdate() - эквивалент db.collection.findAndModify() но с установленными для update атомарными операторами.
db.collection.insertMany() - эквивалент db.collection.insert() с массивом документов в качестве параметра.
db.collection.insertOne() - эквивалент db.collection.insert() в качестве параметра один документ.
db.collection.replaceOne() - эквивалент метода db.collection.update( , ) для обновления документа как параметра для .
db.collection.updateMany() - эквивалент db.collection.update( , , { multi: true, ... }) с использованием опции multi установленной как true.
db.collection.updateOne() - эквивалент db.collection.update( , )
WiredTiger и fsyncLock
Начиная с MongoDB 3.2, хранилище WiredTiger поддерживает команду fsync с опцией lock или метода mongo shell db.fsyncLock(). То есть, для хранилища WiredTiger, эти операции могут гарантировать, что файлы данных не изменятся, обеспечивая согласованность в при создании резервных копий.
Также в этой версии WiredTiger является хранилищем по умолчанию.
Новое GUI compass
В новом Mongodb, впервые, от разработчиков появилось GUI причем не не одно. Начнем с MongoDB Compass. После первого анонса когда кроме картинки еще ничего не было я подумал что compass скорее всего будет c web интерфейсом. Моей первой nosql базой был couchdb и тогда мне очень нравился futon.
Но оказалось что compass, является обычной десктопной программой, и к сожалению только под Mac OS и Windows. И насколько я понял без возможности редактирования, а только с возможностью просмотра документов, и с возможностью делать запросы.
Итак, чтоб локально немного поиграться с этим GUI поставим под Windows mongoDB и немного настроим, чтобы все заработало:
Скачиваем, при установке лучше выбирать “вручную” и указать место для установки C:\mongodb.
После этого запустим от имени администратора консоль и создадим несколько папок:
mkdir c:\data\db
mkdir c:\data\log
А потом создав в каталоге с установкой C:\mongodb\mongod.cfg файлик впишем там пару строчек:
systemLog:
destination: file
path: c:\data\log\mongod.log
storage:
dbPath: c:\data\db
Дальше сделаем mongodb сервисом:
"C:\mongodb\bin\mongod.exe" --config "C:\mongodb\mongod.cfg" --install
И запустим этот сервис:
net start MongoDB
В принципе, всё. Но у меня не получилось приконнектиться к базе пока я не запустил в консоли клиент к монго, c:\mongodb\mongo.exe
После этого скачиваем по ссылке сам compass, там надо символически заполнить пару полей и устанавливаем. После этого запускаем и видим окошко приветствия:
Если все удачно то коннектимся и в открывшемся окне, видим слева список коллекций и баз, по центру визуальное представление документов находящихся в выделенной коллекции. Представление предназначено исключительно для составления запросов, кои сверху в строке видны.
Ну а справа, в колонке, если её открыть с помощью специальной стрелочки (наверное, единственная полезная штука) эти самые документы в виде json.
В целом, общие впечатления такие, что GUI это скорее имиджевый ход, чем несущий какую-то реальную пользу сообществу.
P.S. Просьба о грамматических ошибках и ошибках перевода писать в личку.
Установка mongodb под windows
Справка по compass
Скачать mongodb compass
Документация по новым свойствам
Частичный индекс
Валидация документов
