Некоторое время назад, я решил, что хочу знать больше подробностей о работе многопоточности в .NET и что я уделял этому незаслуженно мало внимания в прошлом. Информации на эту тему великое множество (отправной точкой я для себя выбрал этот раздел книги «C# in a nutshell»), но, как оказалось, только малая часть ресурсов пытаются объяснить что-то в деталях.
Каждый мастер должен знать свои инструменты, а что может использоваться чаще коллекций? Поэтому я решил сделать небольшой обзор многопоточных коллекций и начать с ConcurrentDictionary (беглый обзор уже встречался здесь, но его там совсем мало). Вообще, я несколько удивился, что такой статьи для .NET еще нет (зато хватает по Java).
Итак, поехали.
Если вы уже знакомы с самим Dictionary, то можете пропустить следующий раздел.
Dictionary представляет собой реализацию стандартной Hashtable.
Здесь интересны следующие функции:
Инициализация происходит либо при создании (если передана начальный размер коллекции), либо при добавлении первого элемента, причем в качестве размера будет выбрано ближайшее простое число (3). При этом создаются 2 внутренние коллекции — int[] buckets и Entry[] entries. Первая будет содержать индексы элементов во второй коллекции, а она, в свою очередь, — сами элементы в таком виде:
При добавлении элемента вычисляется хэшкод его ключа и затем — индекс корзины в которую он будет добавлен по модулю от величины коллекции:
Выглядеть это будет примерно так:
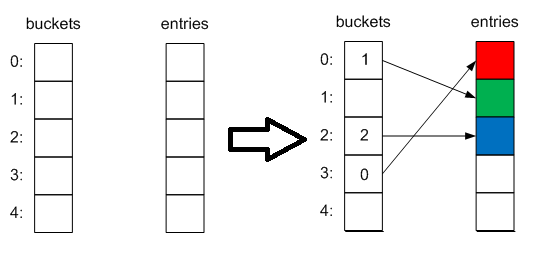
Затем проверяется нет ли уже такого ключа в коллекции, если есть — то операция Add выбросит исключение, а присваивание по индексу просто заменит элемент на новый. Если достигнут максимальный размер словаря, то происходит расширение (выбирается новый размер ближайшим простым числом).
Сложность оперции соответственно — O(n).
Если происходит коллизия (то есть в корзине с индексов bucketNum уже есть элемент), то новый элемент добавляется в коллекцию, его индекс сохраняется в корзине, а индекс старого элемента — в его поле next.

Таким образом получаем однонаправленный связный список. Данный механизм разрешения коллизий называется chaining. Если при добавлении элемента число коллизий велико (больше 100 в текущей версии), то при расширении коллекции происходит операция перехэширования, перед выполнением которой случайным образом выбирается новый генератор хэшкодов.
Сложность добавления O(1) или O(n) в случае коллизии.
При удалении элементов мы затираем его содержимое значениями по умолчанию, меняем указатели next других элементов при неоходимости и сохраняем индекс этого элемента во внутреннее поле freeList, а старое значение — в поле next. Таким образом, при добавлении нового элемента мы можем повторно использовать такие свободные ячейки:
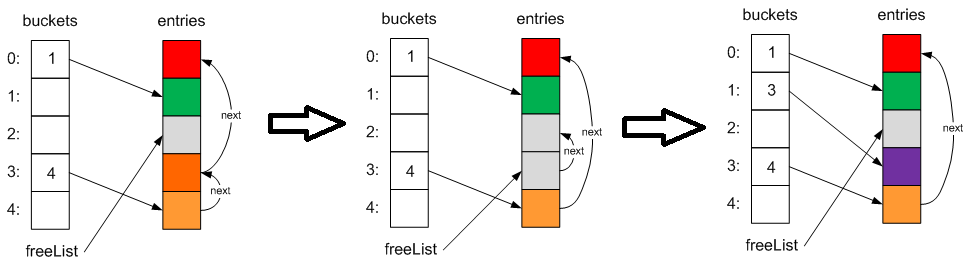
Сложность снова O(1) или O(n) в случае коллизии.
Так же стоит отметить 2 момента:
1) При очистке словаря, его внутренний размер не изменяется. То есть, потенциально, вы просто тратите место.
2) GetEnumerator просто возвращает итератор по коллекции entires (сложность O(1)). Если вы только добавляли элементы — они вернутся в том же порядке. Однако если вы удаляли элементы и добавляли новые — порядок соответственно изменится, поэтому на него полагаться не стоит (тем более, что в будущих версиях фреймворка это может измениться).
Казалось бы, есть 2 решения в лоб для обеспечения потокобезопасности — обернуть все обращения к словарю в блокировки или обернуть все его методы в них же. Однако, по понятным причинам, такое решение будет медленным — задержки, добавляемые lock, да и ограничение на 1 поток, который мог бы работать с коллекцией не добавляют быстродействия.
В Microsoft пошли более оптимальным путем и Dictionary притерпел некоторые изменения. Так, благодаря внутренней структуре словаря и его корзин, блокировка осуществляется по ним, с помощью метода
В то же время обычный словарь не смог бы работать с этой схемой, потому что все корзины используют один и тот же массив entries, поэтому корзины стали представлять собой обычный single linked list: volatile Entry[] m_buckets (поле объявлено как volitale, чтобы обеспечить неблокирующую синхронизацию в ситуации когда один поток пытается выполнить какую-то операцию, а другой в этот момент изменяет размер коллекции).
В итоге корзины стали выглядеть вот так:
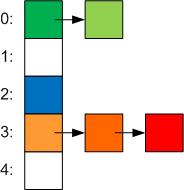
lockNo — это индекс в новом массиве, который содержит объекты синхронизации — object[] m_locks. Его использование позволяет разным потокам изменять разные корзины в одно и то же время. Размер этой коллекции зависит от параметра ConcurrencyLevel который можно задать через конструктор. Он определяет примерное число потоков которые будут одновременное работать с коллекцией (по умолчанию это число_процессоров * 4). Чем выше это значение, тем проще будут происходить операции записи, но так же станут гораздо дороже операции, которые требуют полной блокировки всей коллекции (Resize, ToArray, Count, IsEmpty, Keys, Values, CopyTo, Clear). Также этот параметр определяет сколько элементов коллекции приходится на один lock (как отношение числа корзин к размеру этой коллекции) и когда элементов становится больше, чем надо — коллекция расширяется, потому что в противном случае поиск элемента требует не O(1), а уже O(n) за счет обхода связных списков. Чтобы немного снизить число первоначальных расширений коллекции, начальный размер словаря уже не 3, а 31.
Все операции приобрели вид:
При добавлении нового элемента приходится обойти весь связанный список просто чтобы определить есть ли уже такой ключ и если нет — добавить. Аналогично при удалении — сперва надо найти узел который удалить.
Впрочем, для некоторых операций блокировка не нужна в принципе — это TryGetValue, GetEnumerator, ContainsKey и индексация. Почему? Потому что все изменения размера корзин видны за счет того что поле volatile, любые добавления или изменения элементов происходят путем создания нового элемента и замены им старого, а удаления происходят просто заменой указателя на следующий узел.
1) В отличие от обычного Dictionary, вызов метода Clear, сбрасывает размер коллекции на значение по умолчанию.
2) GetEnumerator — может возвращать старые значения в случае, если изменения были сделаны другим потоком после вызова метода и того как итератор прошел этот элемент. В упомянутой в начале статье было отмечено, что
Спасибо за внимание.
В статье использованы:
1. The .NET Dictionary
2. Inside the Concurrent Collections: ConcurrentDictionary
3. Concurrent Collections
4. .NET Reflector
Каждый мастер должен знать свои инструменты, а что может использоваться чаще коллекций? Поэтому я решил сделать небольшой обзор многопоточных коллекций и начать с ConcurrentDictionary (беглый обзор уже встречался здесь, но его там совсем мало). Вообще, я несколько удивился, что такой статьи для .NET еще нет (зато хватает по Java).
Итак, поехали.
Если вы уже знакомы с самим Dictionary, то можете пропустить следующий раздел.
Что такое Dictionary<TKey, TValue>?
Dictionary представляет собой реализацию стандартной Hashtable.
Здесь интересны следующие функции:
Инициализация
Инициализация происходит либо при создании (если передана начальный размер коллекции), либо при добавлении первого элемента, причем в качестве размера будет выбрано ближайшее простое число (3). При этом создаются 2 внутренние коллекции — int[] buckets и Entry[] entries. Первая будет содержать индексы элементов во второй коллекции, а она, в свою очередь, — сами элементы в таком виде:
private struct Entry { public int hashCode; public int next; public TKey key; public TValue value; }
Добавление элементов
При добавлении элемента вычисляется хэшкод его ключа и затем — индекс корзины в которую он будет добавлен по модулю от величины коллекции:
int bucketNum = (hashcode & 0x7fffffff) % capacity;
Выглядеть это будет примерно так:
Затем проверяется нет ли уже такого ключа в коллекции, если есть — то операция Add выбросит исключение, а присваивание по индексу просто заменит элемент на новый. Если достигнут максимальный размер словаря, то происходит расширение (выбирается новый размер ближайшим простым числом).
Сложность оперции соответственно — O(n).
Если происходит коллизия (то есть в корзине с индексов bucketNum уже есть элемент), то новый элемент добавляется в коллекцию, его индекс сохраняется в корзине, а индекс старого элемента — в его поле next.
Таким образом получаем однонаправленный связный список. Данный механизм разрешения коллизий называется chaining. Если при добавлении элемента число коллизий велико (больше 100 в текущей версии), то при расширении коллекции происходит операция перехэширования, перед выполнением которой случайным образом выбирается новый генератор хэшкодов.
Сложность добавления O(1) или O(n) в случае коллизии.
Удаление элементов
При удалении элементов мы затираем его содержимое значениями по умолчанию, меняем указатели next других элементов при неоходимости и сохраняем индекс этого элемента во внутреннее поле freeList, а старое значение — в поле next. Таким образом, при добавлении нового элемента мы можем повторно использовать такие свободные ячейки:
Сложность снова O(1) или O(n) в случае коллизии.
Другое
Так же стоит отметить 2 момента:
1) При очистке словаря, его внутренний размер не изменяется. То есть, потенциально, вы просто тратите место.
2) GetEnumerator просто возвращает итератор по коллекции entires (сложность O(1)). Если вы только добавляли элементы — они вернутся в том же порядке. Однако если вы удаляли элементы и добавляли новые — порядок соответственно изменится, поэтому на него полагаться не стоит (тем более, что в будущих версиях фреймворка это может измениться).
Так и что же с ConcurrentDictionary?
Казалось бы, есть 2 решения в лоб для обеспечения потокобезопасности — обернуть все обращения к словарю в блокировки или обернуть все его методы в них же. Однако, по понятным причинам, такое решение будет медленным — задержки, добавляемые lock, да и ограничение на 1 поток, который мог бы работать с коллекцией не добавляют быстродействия.
В Microsoft пошли более оптимальным путем и Dictionary притерпел некоторые изменения. Так, благодаря внутренней структуре словаря и его корзин, блокировка осуществляется по ним, с помощью метода
private void GetBucketAndLockNo(int hashcode, out int bucketNo, out int lockNo, int bucketCount, int lockCount) { bucketNo = (hashcode & 0x7fffffff) % bucketCount; lockNo = bucketNo % lockCount; }
В то же время обычный словарь не смог бы работать с этой схемой, потому что все корзины используют один и тот же массив entries, поэтому корзины стали представлять собой обычный single linked list: volatile Entry[] m_buckets (поле объявлено как volitale, чтобы обеспечить неблокирующую синхронизацию в ситуации когда один поток пытается выполнить какую-то операцию, а другой в этот момент изменяет размер коллекции).
В итоге корзины стали выглядеть вот так:
lockNo — это индекс в новом массиве, который содержит объекты синхронизации — object[] m_locks. Его использование позволяет разным потокам изменять разные корзины в одно и то же время. Размер этой коллекции зависит от параметра ConcurrencyLevel который можно задать через конструктор. Он определяет примерное число потоков которые будут одновременное работать с коллекцией (по умолчанию это число_процессоров * 4). Чем выше это значение, тем проще будут происходить операции записи, но так же станут гораздо дороже операции, которые требуют полной блокировки всей коллекции (Resize, ToArray, Count, IsEmpty, Keys, Values, CopyTo, Clear). Также этот параметр определяет сколько элементов коллекции приходится на один lock (как отношение числа корзин к размеру этой коллекции) и когда элементов становится больше, чем надо — коллекция расширяется, потому что в противном случае поиск элемента требует не O(1), а уже O(n) за счет обхода связных списков. Чтобы немного снизить число первоначальных расширений коллекции, начальный размер словаря уже не 3, а 31.
Все операции приобрели вид:
void ChangeBacket(TKey key) { while (true) { Node[] buckets = m_buckets; int bucketNo, lockNo; GetBucketAndLockNo(m_comparer.GetHashCode(key), out bucketNo, out lockNo, buckets.Length); lock (m_locks[lockNo]) { if (buckets != m_buckets) { // Race condition. Пока мы ждали блокировки, другой поток расширил коллекцию. continue; } Node node = m_buckets[bucketNo]; // Вносим изменения в нод. } } }
При добавлении нового элемента приходится обойти весь связанный список просто чтобы определить есть ли уже такой ключ и если нет — добавить. Аналогично при удалении — сперва надо найти узел который удалить.
Впрочем, для некоторых операций блокировка не нужна в принципе — это TryGetValue, GetEnumerator, ContainsKey и индексация. Почему? Потому что все изменения размера корзин видны за счет того что поле volatile, любые добавления или изменения элементов происходят путем создания нового элемента и замены им старого, а удаления происходят просто заменой указателя на следующий узел.
Другое
1) В отличие от обычного Dictionary, вызов метода Clear, сбрасывает размер коллекции на значение по умолчанию.
2) GetEnumerator — может возвращать старые значения в случае, если изменения были сделаны другим потоком после вызова метода и того как итератор прошел этот элемент. В упомянутой в начале статье было отмечено, что
лучше использовать dictionary.Select(x => x.Value).ToArray(), чем dictionary.Values.ToArray()И это не совсем верно — вместо «лучше» тут должно быть «быстрее» — за счет отсутствия блокировок, но надо принять во внимание, что данные подходы могут вернуть разные данные.
Спасибо за внимание.
В статье использованы:
1. The .NET Dictionary
2. Inside the Concurrent Collections: ConcurrentDictionary
3. Concurrent Collections
4. .NET Reflector

