После посещения Yet another Conference 2013 у меня возникла идея написать API для всех сервисов яндекс лингвистики под .NET. После недлительного гугления, таких библиотек к счастью не оказалось. Несмотря на то, что может она никому особо и не понадобится, я все же решил реализовать ее хотя бы для того, чтобы попрактиковаться с RestSharp, тестированием и различными функциями гитхаба (issuers, release, markdown и др.). Кроме того, в процессе реализации пришлось столкнуться с интересным алгоритмом сравнения строк, о котором я упомяну в топике.
Сразу кидаю ссылки на исходники и бинарики на GitHub: Code, Binary
RestSharp позволяет очень легко писать код для синхронных и асинхронных HTTP GET и POST запросов, а также преобразовывать полученные ответы в формате XML или JSON в .NET объекты (в данном проекте использовался XML).
В процессе реализации спеллера мне захотелось, чтобы пользователю отображался не только исправленный вариант текста, но и ошибки в нем. В голову сразу пришла мысль о расстоянии Левейштейна. Однако:
Первый недостаток был нивелирован с помощью расстояния Дамерау—Левенштейна, а второй — с помощью анализа матрицы, полученной в процессе работы алгоритма (расстояние — это значение элемента последнего ряда в последнем столбце матрицы. Соответственно в моем случае расстоянием будет общее количество ошибок, возвращенной этой функцией).
Таким образом были реализован алгоритм для поиска следующих ошибок в ошибочном (word) и корректном (correctedWord) словах:
Кроме того, веса различных ошибок могут настраиваться (по-умолчанию все имеют одинаковый вес, равный единице).
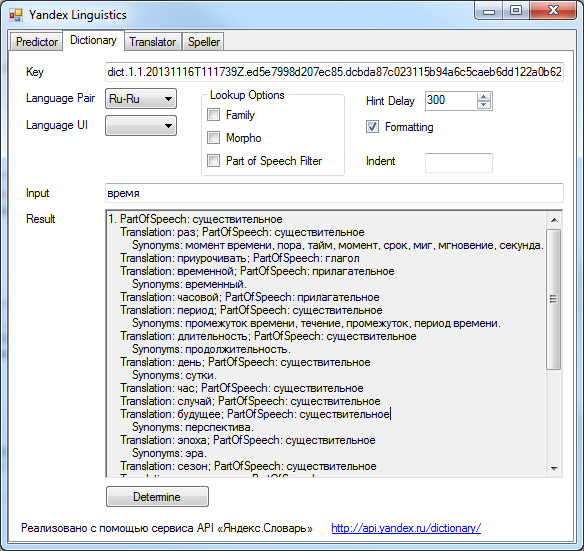
Интерфейс был реализован на WinForms с надеждой, что приложение будет запускаться и на Mono. Однако на нем тестирование не проводилось.
Данную библиотеку можно использовать в любых проектах, но с указанием авторства (Apache 2.0).
Сразу кидаю ссылки на исходники и бинарики на GitHub: Code, Binary
Реализованные API
- Яндекс.Предиктор. Данный сервис позволяет приложениям получать в виде подсказок наиболее вероятное продолжение слова или фразы. Предиктор также учитывает опечатки в исходном запросе. Это упрощает процесс ввода текста, особенно на мобильных устройствах.
- Яндекс.Словарь. Данный сервис позволяет приложениям получать подробные словарные статьи из машинных словарей Яндекса. Статьи содержат сгруппированные переводы, информацию о частях речи, примеры, а также транскрипцию для английских слов.
- Яндекс.Перевод. Перевод текста для более чем 30 языков.
- Яндекс.Спеллер. Сервис проверки правописания, который помогает находить и исправлять орфографические ошибки. Работа сервиса основана на использовании орфографического словаря. В настоящее время Спеллер проверяет тексты на русском, украинском и английском языках.
RestSharp позволяет очень легко писать код для синхронных и асинхронных HTTP GET и POST запросов, а также преобразовывать полученные ответы в формате XML или JSON в .NET объекты (в данном проекте использовался XML).
Расширенная функция подсчета расстояния Дамерау—Левенштейна
В процессе реализации спеллера мне захотелось, чтобы пользователю отображался не только исправленный вариант текста, но и ошибки в нем. В голову сразу пришла мысль о расстоянии Левейштейна. Однако:
- Данный алгоритм не учитывает транспозиционные ошибки, которыми являются 80% при наборе текста (данные с википедии).
- Данный алгоритм он возвращает расстояние, а не позиции ошибок в новом слове.
Первый недостаток был нивелирован с помощью расстояния Дамерау—Левенштейна, а второй — с помощью анализа матрицы, полученной в процессе работы алгоритма (расстояние — это значение элемента последнего ряда в последнем столбце матрицы. Соответственно в моем случае расстоянием будет общее количество ошибок, возвращенной этой функцией).
Таким образом были реализован алгоритм для поиска следующих ошибок в ошибочном (word) и корректном (correctedWord) словах:
- Замена. Пример: синхрафазатрон -> синхрофазотрон
- Вставка. Пример: синхрофазотр -> синхрофазотрон
- Удаление. Пример: синнхрофаазотрон -> синхрофазотрон
- Транспозиция. Пример: синхрофазортон -> синхрофазотрон
Кроме того, веса различных ошибок могут настраиваться (по-умолчанию все имеют одинаковый вес, равный единице).
Код расширенной функции подсчета расстояния Дамерау—Левенштейна
public static List<Mistake> DamerauLevenshteinDistance( string word, string correctedWord, bool transposition = true, int substitutionCost = 1, int insertionCost = 1, int deletionCost = 1, int transpositionCost = 1) { int w_length = word.Length; int cw_length = correctedWord.Length; var d = new KeyValuePair<int, CharMistakeType>[w_length + 1, cw_length + 1]; var result = new List<Mistake>(Math.Max(w_length, cw_length)); if (w_length == 0) { for (int i = 0; i < cw_length; i++) result.Add(new Mistake(i, CharMistakeType.Insertion)); return result; } for (int i = 0; i <= w_length; i++) d[i, 0] = new KeyValuePair<int, CharMistakeType>(i, CharMistakeType.None); for (int j = 0; j <= cw_length; j++) d[0, j] = new KeyValuePair<int, CharMistakeType>(j, CharMistakeType.None); for (int i = 1; i <= w_length; i++) { for (int j = 1; j <= cw_length; j++) { bool equal = correctedWord[j - 1] == word[i - 1]; int delCost = d[i - 1, j].Key + deletionCost; int insCost = d[i, j - 1].Key + insertionCost; int subCost = d[i - 1, j - 1].Key; if (!equal) subCost += substitutionCost; int transCost = int.MaxValue; if (transposition && i > 1 && j > 1 && word[i - 1] == correctedWord[j - 2] && word[i - 2] == correctedWord[j - 1]) { transCost = d[i - 2, j - 2].Key; if (!equal) transCost += transpositionCost; } int min = delCost; CharMistakeType mistakeType = CharMistakeType.Deletion; if (insCost < min) { min = insCost; mistakeType = CharMistakeType.Insertion; } if (subCost < min) { min = subCost; mistakeType = equal ? CharMistakeType.None : CharMistakeType.Substitution; } if (transCost < min) { min = transCost; mistakeType = CharMistakeType.Transposition; } d[i, j] = new KeyValuePair<int, CharMistakeType>(min, mistakeType); } } int w_ind = w_length; int cw_ind = cw_length; while (w_ind >= 0 && cw_ind >= 0) { switch (d[w_ind, cw_ind].Value) { case CharMistakeType.None: w_ind--; cw_ind--; break; case CharMistakeType.Substitution: result.Add(new Mistake(cw_ind - 1, CharMistakeType.Substitution)); w_ind--; cw_ind--; break; case CharMistakeType.Deletion: result.Add(new Mistake(cw_ind, CharMistakeType.Deletion)); w_ind--; break; case CharMistakeType.Insertion: result.Add(new Mistake(cw_ind - 1, CharMistakeType.Insertion)); cw_ind--; break; case CharMistakeType.Transposition: result.Add(new Mistake(cw_ind - 2, CharMistakeType.Transposition)); w_ind -= 2; cw_ind -= 2; break; } } if (d[w_length, cw_length].Key > result.Count) { int delMistakesCount = d[w_length, cw_length].Key - result.Count; for (int i = 0; i < delMistakesCount; i++) result.Add(new Mistake(0, CharMistakeType.Deletion)); } result.Reverse(); return result; }
Интерфейс
Интерфейс был реализован на WinForms с надеждой, что приложение будет запускаться и на Mono. Однако на нем тестирование не проводилось.
Данную библиотеку можно использовать в любых проектах, но с указанием авторства (Apache 2.0).

