
Ошибочно рассматривать базу данных как некую эталонную единицу, поскольку, с течением времени, могут проявляться различного рода нежелательные ситуации — деградация производительности, сбои в работе и прочее.
Для минимизации вероятности возникновения таких ситуаций создают планы обслуживания из задач, гарантирующих стабильность и оптимальную производительность базы данных.
Среди подобных задач можно выделить следующие:
1. Дефрагментация индексов
2. Обновление статистики
3. Резервное копирование
Рассмотрим по порядку автоматизацию каждой из этих задач.
UPDATE 2019-06-03:
Но сперва хочется чуток порекламировать опенсорс программу, которую я сделал спустя 5 лет после написания этого поста. Так уж исторически сложилось, что долгое время участвовал в разработке системных тулов для обслуживания SQL Server. За это время накопилось много идей и на определенном этапе захотелось сделать что-то свое.
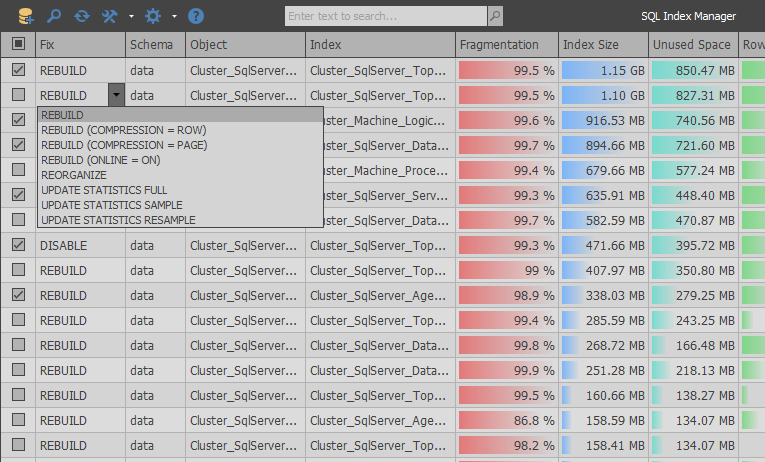
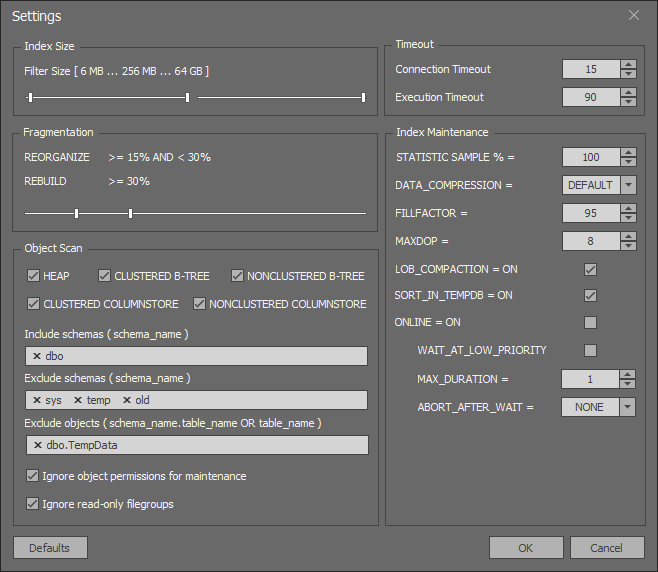
В результате получилось приложение, которое позволяет обслуживать индексы через удобный UI. За основных конкурентов брались платные аналоги от компаний RedGate и Devart.
Ключевые особенности SQL Index Manager:
- Оптимизированный алгоритм получения фрагментированных индексов
- Возможность обслуживания нескольких баз данных за раз
- Автоматический выбор действия для индексов исходя из выбранных настроек
- Поддержка глобального поиска и сложной фильтрации для более удобной аналитики
- Большое число настроек и полезной информации об индексах
- Автоматическая генерация скриптов по обслуживанию индексов
- Поддержка обслуживания кучи и колумнсторов
- Поддержка командной строки
- Возможность включать сжатие индексов и обновление статистики вместо ребилда
- Возможность экспорта результатов
- Кастомизация интерфейса
- Поддержка всех редакций SQL Server 2008+ и Azure SQL Database
На данный момент и в дальнейшем, SQL Index Manager полностью бесплатный.
Последнюю версию приложения можно скачать по этой ссылке, а все исходники лежат на GitHub.
Но вернемся теперь к изначальному посту. Итак, пункт первый…
Помимо фрагментации файловой системы и лог-файла, ощутимое влияние на производительность базы данных оказывает фрагментация внутри файлов данных:
1. Фрагментация внутри отдельных страниц индекса
После операций вставки, обновления и удаления записей неизбежно возникают пустые пространства на страницах. Ничего страшного в этом нет, поскольку данная ситуация вполне нормальная, если бы не одно но…
Очень важную роль играет длина строки. Например, если строка имеет размер, который занимает более половины страницы, свободная половина этой страницы не будет использоваться. В результате при увеличении числа строк будет наблюдаться рост неиспользуемого места в базе данных.
Бороться с данным видом фрагментации стоит на этапе проектировании схемы, т. е. выбирать такие типы данных, которые бы компактно умещались на страницах.
2. Фрагментация внутри структур индекса
Основная причина возникновения этого вида фрагментации — операции разбиения страницы. Например, согласно структуре первичного ключа, новую строку необходимо вставить на определенную страницу индекса, но этой на странице недостаточно места, чтобы разместить вставляемые данные.
В таком случае, создается новая страница, на которую переместиться примерно половина записей со старой страницы. Новая страница, зачастую не является физически смежной со старой и, следовательно, помечается системой как фрагментированная.
В любом случае, фрагментация ведет к росту числа страниц для хранения того же объема информации. Это автоматически приводит к увеличению размера базы данных и росту неиспользуемого места.
При выполнении запросов, в которых идет обращение к фрагментированым индексам, требуется больше IO операций. Кроме того, фрагментация накладывает дополнительные расходы на память самого сервера, которому приходится хранить в кэше лишние страницы.
Для борьбы с фрагментацией индексов в арсенале SQL Server предусмотрены команды: ALTER INDEX REBUILD / REORGANIZE.
Перестройка индекса подразумевает удаление старого и создание нового экземпляра индекса. Эта операция устраняет фрагментацию, восстанавливает дисковое пространство путем уплотнения страницы, резервируя при этом свободное место на странице, которое можно задать опцией FILLFACTOR. Важно отметить, что операция по перестройке индекса весьма затратна.
Поэтому, в случае, когда фрагментация незначительна, предпочтительно реорганизовывать существующий индекс. Данная операция требует меньших системных ресурсов, чем пересоздание индекса и заключается в реорганизации leaf-level страниц. Кроме того реорганизация при возможности сжимает страницы индексов.
Степень фрагментации того или иного индекса можно узнать из динамического системного представления sys.dm_db_index_physical_stats:
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) WHERE avg_fragmentation_in_percent > 0
В данном запросе, последний параметр задает режим, от значения которого возможно быстрое, но не совсем точное определения уровня фрагментации индекса (режимы LIMITED/NULL). Поэтому рекомендуется задавать режимы SAMPLED/DETAILED.
Мы знаем откуда получить список фрагментированных индексов. Теперь необходимо для каждого из них сгенерировать соответствующую ALTER INDEX команду. Традиционно для этого используют курсор:
DECLARE @SQL NVARCHAR(MAX) DECLARE cur CURSOR LOCAL READ_ONLY FORWARD_ONLY FOR SELECT ' ALTER INDEX [' + i.name + N'] ON [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + '] ' + CASE WHEN s.avg_fragmentation_in_percent > 30 THEN 'REBUILD WITH (SORT_IN_TEMPDB = ON)' ELSE 'REORGANIZE' END + ';' FROM ( SELECT s.[object_id] , s.index_id , avg_fragmentation_in_percent = MAX(s.avg_fragmentation_in_percent) FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s WHERE s.page_count > 128 -- > 1 MB AND s.index_id > 0 -- <> HEAP AND s.avg_fragmentation_in_percent > 5 GROUP BY s.[object_id], s.index_id ) s JOIN sys.indexes i WITH(NOLOCK) ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = s.[object_id] OPEN cur FETCH NEXT FROM cur INTO @SQL WHILE @@FETCH_STATUS = 0 BEGIN EXEC sys.sp_executesql @SQL FETCH NEXT FROM cur INTO @SQL END CLOSE cur DEALLOCATE cur
Чтобы ускорить процесс пересоздания индекса рекомендуется дополнительно указывать опцию SORT_IN_TEMPDB. Еще нужно отдельно упомянуть про опцию ONLINE — она замедляет пересоздание индекса. Но иногда бывает полезной. Например, чтение из кластерного индекса очень дорогое. Мы создали покрывающий индекс и решили проблему с производительностью. Далее мы делаем REBUILD некластерного индекса. В этот момент нам придется снова обращаться к кластерному индексу — что снижает перфоманс.
SORT_IN_TEMPDB позволяет перестраивать индексы в базе tempdb, что бывает особенно полезно для больших индексов в случае нехватки памяти и ином случае — опция игнорируется. Кроме того, если база tempdb расположена на другом диске — это существенно сократит время создания индекса. ONLINE позволяет пересоздать индекс не блокируя при этом запросы к объекту для которого этот индекс создается.
Как показала практика, дефрагментирование индексов с низкой степенью фрагментации либо с небольшим количеством страниц не приносит каких-либо заметных улучшений, способствующих повышению производительности при работе с ними.
В дополнении, приведенный выше запрос можно переписать без применения курсора:
DECLARE @IsDetailedScan BIT = 0 , @IsOnline BIT = 0 DECLARE @SQL NVARCHAR(MAX) SELECT @SQL = ( SELECT ' ALTER INDEX [' + i.name + N'] ON [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + '] ' + CASE WHEN s.avg_fragmentation_in_percent > 30 THEN 'REBUILD WITH (SORT_IN_TEMPDB = ON' -- Enterprise, Developer + CASE WHEN SERVERPROPERTY('EditionID') IN (1804890536, -2117995310) AND @IsOnline = 1 THEN ', ONLINE = ON' ELSE '' END + ')' ELSE 'REORGANIZE' END + '; ' FROM ( SELECT s.[object_id] , s.index_id , avg_fragmentation_in_percent = MAX(s.avg_fragmentation_in_percent) FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, CASE WHEN @IsDetailedScan = 1 THEN 'DETAILED' ELSE 'LIMITED' END) s WHERE s.page_count > 128 -- > 1 MB AND s.index_id > 0 -- <> HEAP AND s.avg_fragmentation_in_percent > 5 GROUP BY s.[object_id], s.index_id ) s JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id JOIN sys.objects o ON o.[object_id] = s.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)') PRINT @SQL EXEC sys.sp_executesql @SQL
В результате оба запроса при выполнении будут генерировать запросы по дефрагментации проблемных индексов:
ALTER INDEX [IX_TransactionHistory_ProductID] ON [Production].[TransactionHistory] REORGANIZE; ALTER INDEX [IX_TransactionHistory_ReferenceOrderID_ReferenceOrderLineID] ON [Production].[TransactionHistory] REBUILD WITH (SORT_IN_TEMPDB = ON, ONLINE = ON); ALTER INDEX [IX_TransactionHistoryArchive_ProductID] ON [Production].[TransactionHistoryArchive] REORGANIZE;
Собственно, на этом первая часть по созданию плана обслуживания для базы данных выполнена. В следующей части мы займемся написанием запроса для автоматического обновления статистики.
Если хотите поделиться этой статьей с англоязычной аудиторией:
SQL Server Typical Maintenance Plans: Automated Index Defragmentation
UPDATE 2016-04-22: добавил возможность дефрагментации отдельных секций и исправил некоторые баги
USE ... DECLARE @PageCount INT = 128 , @RebuildPercent INT = 30 , @ReorganizePercent INT = 10 , @IsOnlineRebuild BIT = 0 , @IsVersion2012Plus BIT = CASE WHEN CAST(SERVERPROPERTY('productversion') AS CHAR(2)) NOT IN ('8.', '9.', '10') THEN 1 ELSE 0 END , @IsEntEdition BIT = CASE WHEN SERVERPROPERTY('EditionID') IN (1804890536, -2117995310) THEN 1 ELSE 0 END , @SQL NVARCHAR(MAX) SELECT @SQL = ( SELECT ' ALTER INDEX ' + QUOTENAME(i.name) + ' ON ' + QUOTENAME(s2.name) + '.' + QUOTENAME(o.name) + ' ' + CASE WHEN s.avg_fragmentation_in_percent >= @RebuildPercent THEN 'REBUILD' ELSE 'REORGANIZE' END + ' PARTITION = ' + CASE WHEN ds.[type] != 'PS' THEN 'ALL' ELSE CAST(s.partition_number AS NVARCHAR(10)) END + ' WITH (' + CASE WHEN s.avg_fragmentation_in_percent >= @RebuildPercent THEN 'SORT_IN_TEMPDB = ON' + CASE WHEN @IsEntEdition = 1 AND @IsOnlineRebuild = 1 AND ISNULL(lob.is_lob_legacy, 0) = 0 AND ( ISNULL(lob.is_lob, 0) = 0 OR (lob.is_lob = 1 AND @IsVersion2012Plus = 1) ) THEN ', ONLINE = ON' ELSE '' END ELSE 'LOB_COMPACTION = ON' END + ')' FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s JOIN sys.indexes i ON i.[object_id] = s.[object_id] AND i.index_id = s.index_id LEFT JOIN ( SELECT c.[object_id] , index_id = ISNULL(i.index_id, 1) , is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END) , is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END) FROM sys.columns c LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id AND i.index_id > 0 WHERE c.system_type_id IN (34, 35, 99) OR c.max_length = -1 GROUP BY c.[object_id], i.index_id ) lob ON lob.[object_id] = i.[object_id] AND lob.index_id = i.index_id JOIN sys.objects o ON o.[object_id] = i.[object_id] JOIN sys.schemas s2 ON o.[schema_id] = s2.[schema_id] JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id WHERE i.[type] IN (1, 2) AND i.is_disabled = 0 AND i.is_hypothetical = 0 AND s.index_level = 0 AND s.page_count > @PageCount AND s.alloc_unit_type_desc = 'IN_ROW_DATA' AND o.[type] IN ('U', 'V') AND s.avg_fragmentation_in_percent > @ReorganizePercent FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)') PRINT @SQL --EXEC sys.sp_executesql @SQL

