В предыдущей статье я рассматривал вопросы создания альтернативных клавиатурных раскладок, в т.ч. проблемы, возникающие при построении моделей оптимизации этих раскладок.

Здесь мы пойдем несколько другим путем и рассмотрим возможность сокращения общего числа нажатий на клавиши (кроме использования аккордных способов набора и стенотайпов, т.к. это уже другая большая тема).
Сразу оговорюсь, что применение стенотайпа вкупе со знанием стенографии, конечно, даст гораздо больший эффект в плане прироста производительности. Но способ, рассматриваемый ниже, легко реализуем (нет необходимости в спецоборудовании, сложном программном обеспечении) и требует на порядки меньше времени для изучения (запомнить несколько десятков сокращений обычно несложно).
Автозаменой (АЗ) будем называть такой способ печати сочетания букв/слова/фразы, при котором исходный текст программно переназначается на другие сочетания клавиш. Для целей повышения производительности набираемое сочетание клавиш (назовем его ключом или сокращением) должно иметь минимальную длину по отношению к исходной последовательности букв. Разность в числе нажимаемых клавиш при наборе комбинации в исходном виде и при наборе с сокращениями и будет выигрышем на данной комбинации за счет АЗ.
Например, нужно набрать такое часто используемое слово, как «потому». Если сокращение выглядит как «п», то выигрыш при наборе только одного слова составит 5 символов.
Отметим, что в мире подобная практика уже давно существует. Даже проводятся соревнования в различных зачетах — с использованием системы сокращений и без оной. В первом случае мировой рекорд на 30-минутном интервале равен 955 уд/мин, во втором — 821 уд/мин. Оба рекорда поставила небезызвестная Хелена Матушкова.
Наиболее развита система сокращений для чешского языка, именуемая Завописью (ZAVpis). Есть даже обучающий сайт, и есть информация, что освоение системы сокращений начинается только после приобретения достаточно высокого уровня навыка набора вслепую.
Как видим из отношения чисел 955 и 821, выигрыш при использовании АЗ не такой и высокий (~16%). Однако, в данном случае система АЗ адаптирована под среднестатистическую структуру языка, и не учитывает специфические слова, особенности, характерные для различных областей знаний. Также не учитывается лексикон пользователя, используемый в общении, повседневной переписке. В обиходе или узкой практической области словарный запас гораздо меньше по объему, и эффективность системы АЗ, составленной под конкретные потребности, может значительно возрасти.
Сначала необходимо определиться, для каких целей создается система автозамен. Если требуется система АЗ для уменьшения времени набора среднестатистического предложения в русском языке, то необходимо учитывать структуру языка в целом. Здесь можно пойти двумя путями.
Один из них – собственноручно собрать большую выборку текстов, адекватно представляющую язык (обычно объем такой выборки – от нескольких сотен мегабайт) и проанализировать их статистически – выделить самые частые слова, сочетания букв, символов. Затем на основе анализа построить статистические таблицы.
Отметим, что этот способ больше подходит для случая, когда система АЗ создается для себя, под свои наиболее часто используемые слова — в статьях, в деловой переписке, при общении в чате, на форуме и пр.
Второй – воспользоваться уже готовыми таблицами. Разумеется, такие таблицы уже есть в пригодном для применения виде. Здесь подразумевается использование Национального корпуса русского языка и частотных словарей русского языка (одним из наиболее известных является частотный словарь Шарова: [1]; [2]).
Список 100 наиболее частых словоформ можно просмотреть здесь.
Представляется логичным, что автозаменам должны подвергаться в первую очередь наиболее частотные слова, а среди них – самые длинные. Вообще, все языковые статистики подчиняются закону Ципфа. Это обобщенно-гиперболическое распределение ранжированных статистик, неважно, на каком уровне – будь то уровень отдельных букв, символов; уровень буквосочетаний (n-грамм); уровень слов; фразеологический уровень.
Такие статистики, наряду с гауссовыми, очень часто проявляются в окружающем нас мире, и были обнаружены в самых разных областях знаний. Например, распределение людей по доходу (Парето), распределение ученых по производительности (Лотка), распределение статей по журналам (Брэдфорд), распределение населенных пунктов по численности, распределение землетрясений по интенсивности и пр. Вообще, такие статистики возникают вследствие сильной взаимозависимости событий в системе (аналог положительной обратной связи), по типу цепной реакции, в результате которой может происходить как чрезвычайное усиление, так и сильное ослабление.
Для нас важен тот факт, что пики, положительные отклонения от гиперболического тренда будут как раз указывать на те слова, которые в первую очередь должны войти в систему АЗ. При этом наибольший вклад в итоговую эффективность системы внесут первые несколько сотен наиболее частотных слов.
Рассмотрим и другие особенности построения системы АЗ:
1. Ключи должны быть уникальными (не совпадать со словами и с другими ключами), минимальными по длине, легко запоминаемыми. Такие ключи должны состоять либо из нескольких первых букв слова, либо из первых и последних.
2. Назначение ключей (их длина, используемые буквы, символы) будет зависеть и от размера самой системы АЗ. Рассмотрим простейший пример. Пусть мы хотим создать систему для одного-единственного слова «потом», очевидно, что наилучший вариант — сокращение «п». Если же система будет состоять из двух из более слов (реальный вариант), то нужно учитывать встречаемости, а также п.1. Пусть слово «потом» встретилось 10 000 раз, а слово «потому» — 100 000 раз. Очевидно, что слову с максимальной встречаемостью нужно присвоить сокращение минимальной длины «п», а слову «потом» — сокращение «пм». Конечно, в случае только двух сокращений второму слову тоже можно приписать единственную букву. Но этот случай все еще далек от практического применения, а потому мы применили сокращение «пм», что более правдоподобно.
Нужно также учесть, что однобуквенных ключей максимум 33 (без использования цифр и символов в качестве ключей), двухбуквенных 332=1089. И то, при завышенной оценке. Вряд ли будут ключи вида «ъъ» или «юь».
3. Некоторые ключи могут быть в иерархической форме. Например, «ч»->«что»->«что-либо». При этом ключ может «разворачиваться» как и сразу после набора, так и после нажатия клавиши-активатора.
4. Размер системы АЗ должен быть компромиссом между теоретическим выигрышем и временем, необходимым для изучения системы. Я не использовал АЗ широко, но для развернутой системы приличный потолок оцениваю примерно в 1000 сокращений. Для системы, используемой в обиходе — 100 сокращений вполне хватит для самых часто используемых слов, фраз, оборотов.
Автозамена уменьшает количество набираемых символов. Т.е. длина слова уменьшается на Lсл-LАЗ. Допустим, если мы слово «что» заменяем на «ч», то на одном слове выигрыш будет L(что)-L(ч)=3-1=2 символа. Далее, каждое слово имеет свою определенную частоту, выраженную в процентах. Или, если мы пользуемся корпусом, то в нем обычно приводятся данные о встречаемости слова – т.е. вообще количество таких слов в корпусе.
Например, слово «что» встречается в корпусе 2210373 раза. Тогда общий выигрыш от набора всех слов «что» в корпусе составит
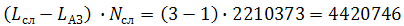
символов.
Чтобы посчитать относительный выигрыш в процентах от общего числа набранных символов, нам нужно знать характеристики русского языка в среднем. Общий объем корпуса составляет 1,93∙108 слов. Логично было бы разделить число слов «что» на общее число слов, но слова имеют разную длину, которую тоже нужно учитывать. Средняя длина слов в русском языке, согласно корпусу, составляет 5,28 символа.
Теперь мы можем теперь посчитать объем корпуса в символах. Но корпус — это еще не весь текст. Реально в тексте встречается много сервисных знаков, таких как пробел, точка, запятая, точка с запятой, кавычки, различные знаки, цифры и т.д. И для нахождения объема всего текста по корпусу нам нужно умножить число найденных символов на некоторый коэффициент, который отражает долю сервисных знаков в русскоязычном тексте. По собственным вычислениям, приближенно, доля сервисных знаков составляет ~20%, с небольшими отклонениями в ту или другую сторону.
Тогда выражение для расчета относительного выигрыша на постоянной автозамене одного слова приобретает вид:
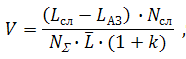
где — общее число слов в корпусе,
— общее число слов в корпусе,
 — средняя длина слова в русском языке,
— средняя длина слова в русском языке,
k — доля сервисных знаков, цифр и прочих символов, не входящих в слова.
Остальные обозначения были расшифрованы ранее.
Таким образом, для одной-единственной автозамены на слове «что» мы получаем относительный выигрыш, равный

Как мы видим, для одного слова выигрыш достаточно большой, и многие могут подумать, что для развитой системы АЗ можно ожидать выигрыша порядка десятков процентов. Но мы использовали одно из самых частотных слов. А так как статистика встречаемости слов подчиняется гиперболическому закону, то вклад (частота) каждого последующего слова будет значительно убывать. Соответственно, выигрыш от АЗ на таких менее частотных словах также будет не очень ощутимым.
Строки отсортированы по суммарному выигрышу, получаемому от всех АЗ указанного слова по всему корпусу.
При выборе числа слов, подвергаемых АЗ, нужно учитывать тот факт, что время на изучение системы АЗ в первом приближении пропорционально числу сокращений. Т.е. список АЗ должен быть разумного размера, где найден компромисс между числом АЗ и выигрышем, который они дают. Для этого необходимо построить приближенный график зависимости относительного выигрыша от числа АЗ.
Априори можно предполагать, что сначала выигрыш будет значительным, и наклон кривой будет максимальным (т.к. слова более частотные). С уменьшением частотности слов, выигрыш от каждого последующего слова будет уменьшаться, наклон кривой также уменьшится. Интересный вопрос, будет ли наблюдаться насыщение? Каждая АЗ будет давать некоторый выигрыш, но не упадет ли при этом частота слова настолько, что каждый очередной относительный прирост будет стремиться к нулю.
В данном пункте основная задача – выяснить, до какого числа АЗ необходимо увеличивать список, чтобы соблюсти компромисс между относительным выигрышем и временем на обучение. Т.е. нужно выявить переходную область, где наклон кривой выигрыша становится относительно небольшим, с тем, чтобы исключить малоэффективные АЗ.
График строился, исходя из некоторых упрощений, для общности анализа. Во-первых, длины всех сокращений АЗ предполагались равными двум символам. Соответственно, из списка наиболее частотных слов исключались слова длиной менее 3-х символов, т.к. выигрыша от них на такой системе АЗ не будет. Далее, предполагалось, что число 2-символьных сокращений будет не более 700. Это должно быть близко к истине, даже с несколько завышенной оценкой, т.к. очевидно, что абсолютно все 1089 диграмм не могут быть использованы в качестве сокращений по вполне понятным причинам (например, ни с чем не ассоциирующиеся сочетания букв, как было указано выше). Трехсимвольные сокращения на данном этапе не рассматривались.

По оси абсцисс отложено общее число слов с АЗ, по оси ординат — относительное сокращение числа нажатий на клавиши.
Как и ожидалось, в самом начале графика, для первых 100 сокращений скорость прироста выигрыша максимальная.
Приведем некоторые данные по графику:
для первых 10 сокращений выигрыш равен 0,82%,
для первых 20 – 1,24%,
для первых 50 – 2,23%,
для первых 100 – 3,50%,
для первых 200 – 5,37%,
для первых 300 – 6,63%,
для первых 400 – 7,52%,
для первых 500 – 8,33%,
для первых 600 – 9,04%,
для первых 700 – 9,76%.
Подсчитаем выигрыши для 1-й, 2-й, 3-й и т.д. сотен АЗ.
Для первой сотни, как уже упоминалось – 3,50%,
для второй – 1,87%,
для третьей – 1,26%,
для четвертой – 0,89,
5-й – 0,81%,
6-й – 0,72%,
7-й – 0,72%.
Как мы видим, скорость роста падает, но потом стабилизируется. Это достаточно неожиданный результат, не совпадающий с априорным предположением. Нет даже намека на насыщение зависимости. Видимо, при достаточном числе сокращений можно обеспечить большой выигрыш. Например, при 700 АЗ выигрыш по графику составит 9,76%. Это уже приемлемая величина.
В реальности выигрыш будет еще большим (примерно на 0,2-0,3%), т.к. используются не только 2-символьные АЗ, а также и 1-символьные для самых частых слов. Но в дальнейшем придется использовать уже 3-символьные сокращения, поэтому скорость прироста выигрыша немного упадет, скачком, относительно наблюдаемой на 6-й и 7-й сотнях АЗ.
Исходя из прироста выигрыша, можно ограничиться списком АЗ, состоящим из 500 сокращений, что даст выигрыш 8,33%. Необходимо еще упомянуть о том, что в повседневной жизни человек пользуется для переписки, общения, написания текстов ограниченным набором слов, вовсе не являющимся эквивалентным по структуре корпусу русского языка. Ежедневно используются слова, находящиеся в числе наиболее частых. Таким образом, для повседневных задач, которые не включают написание научных статей, выигрыш будет еще более значимым, возможно, даже в разы.
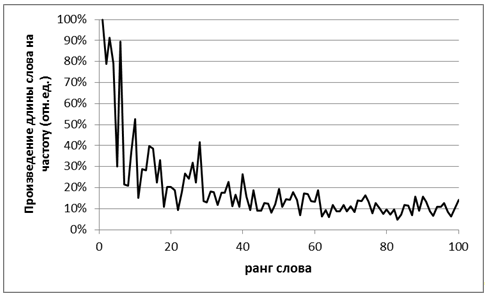
Можно высказать предположение, почему скорость прироста выигрыша не замедляется постоянно. Видимо, уменьшение частоты слова компенсируется тем, что менее частотные слова являются также более длинными, а выигрыш пропорционален произведению разности длин слова и АЗ на частоту слова.
Для визуального анализа необходимо построить график зависимости произведения длины слова на его частоту от ранга слова в частотном списке. Наиболее эффективными будут АЗ слов, образующих пики относительно средней тенденции (разумеется, с некоторыми оговорками — например, слово должно быть достаточно длинным).
Автозамены не будут одинаково эффективны для различных языков вследствие различной сложности самых языков. Печать на тех языках, которые считаются «богаче» (в смысле большего числа словоформ), будут тяжелее поддаваться сокращению при помощи АЗ.
Например, для ряда европейских языков, видимо, АЗ будут более эффективными, чем для русского. В свою очередь, английский язык, наверное, будет более приспособлен к АЗ, чем немецкий.
Возьмем пример: в русском языке есть падежи, числа, в английском падежей нет, но есть число. Например, слово лампа – lamp.

Возможно, приведенный пример не во всех случаях справедлив (например, для глаголов ситуация будет иной). Однако, он показывает несколько характерных особенностей.
Из таблицы видно, что для всех падежей слова «лампа» в единственном и множественном числе для русского языка понадобится 12-3=9 автозамен, а для английского языка – всего 2 автозамены (единственное число и множественное число). Т.е. при сильно развитом, более избыточном, с большим числом словоформ языке задача назначения автозамен сильно усложняется.
Также в английском языке меньше самих букв (26 против 33 в русском), а следовательно, намного меньше сочетаний из этих символов. Максимальная возможная верхняя оценка 262 для английского и 332 для русского. В реальности, конечно, из них используется еще меньше. Для русского всего существует около ~700 смысловых диграмм (двухбуквенных сочетаний). Названные обстоятельства еще раз указывают на то, что языки, энтропия (избыточность) которых выше, хуже поддаются автозаменам.
Наконец, список наиболее частотных слов в английском языке также должен быть значительно короче, чем для русского. Т.е. если, например, взять 10%, 20%-ный охват (самые частые слова, которые образуют 10%, 20% всех слов), то для английского такой список тоже должен быть короче.
Из вышеприведенных примеров уже видно, что задача конструирования гибкой системы автозамен для русского языка является достаточно сложной нетривиальной задачей, а еще сложнее обеспечить хороший прирост производительности. В нашем случае хорошим будет считаться суммарный прирост производительности, начиная от 10%, в среднестатистическом смысле. Это тот минимум, к которому надо стремиться.
Кроме слов, ощутимую долю символов составляют т.н. сервисные, синтаксические символы: знак пробела, знаки пунктуации и пр. На их долю приходится порядка 20% от общего числа символов.
Обратимся к списку наиболее частых 2-символьных сочетаний (для всех символов таких таблиц обычно нет, поэтому их нужно делать самостоятельно, анализируя большие объемы текстовой информации). Наиболее частым 2-символьным сочетанием является сочетание «, », т.е. запятая+пробел. По собственным данным, на его долю приходится 1,64% общего числа диграмм (двухсимвольных сочетаний).
Оценим выигрыш при автозамене этой комбинации одним символом (или одним нажатием). Можно назначить такую комбинацию на клавишу CapsLock, поскольку она достаточно редко используется в повседневной работе (конечно, можно использовать и другие варианты, удобные для конкретного пользователя).
В стандартной раскладке ЙЦУКЕН для набора запятой нужно нажать 2 клавиши – «Shift» и «.». Таким образом, комбинация, для набора которой требовались 3 нажатия, будет набираться одним нажатием. Что эквивалентно сокращению на 2 нажатия.
В данном случае выигрыш подсчитывается следующим образом: если бы диграмма полностью исключалась из набора, то тогда выигрыш равнялся ее частоте. Но в нашем случае происходит просто сокращение комбинации. Т.е. выигрыш будет пропорционален относительному сокращению комбинации и ее частоте:

где — длина комбинации до сокращения,
— длина комбинации до сокращения,
 — длина комбинации после сокращения (с учетом АЗ),
— длина комбинации после сокращения (с учетом АЗ),
 — частота комбинации среди комбинаций такой же длины.
— частота комбинации среди комбинаций такой же длины.
Таким образом, получаем выигрыш от сокращения «, » до одного нажатия

В реальности, учет одной этой диграммы не даст общей картины, т.к. нужно учитывать и то, что запятые исключатся и в диграммах, где они находятся на второй позиции.
Для расчета выигрыша в данном случае удобно воспользоваться унарной (односимвольной) статистикой, если она рассчитывалась в процессе подготовки таблиц. В нашем случае такая таблица рассчитывалась. Несмотря на некоторую вариабельность статистических характеристик для текстов разного жанра, наблюдается все же значительная их устойчивость, что позволяет говорить о некоторой статистической структуре русского языка в среднем.
В текстах, более-менее широко встречающихся на практике, доли точки и запятой в целом равны и составляют приблизительно по 1,5%. Для ориентировочных расчетов выигрыша от замены «, » на CapsLock такой оценки вполне достаточно.
Для того, чтобы понятно, как считать эффективность АЗ в данном случае, можно привести пример. Рассмотрим кусок текста, состоящий из трех предложений, в каждом из которых по 70 символов. Пусть в каждом предложении по одной заглавной букве (начало) и по 2 запятых. Тогда общее число ударов составит 219. Используем замену «, » на CapsLock. Далее выигрыш можно определить так: поскольку мы вместо трех нажатий для набора «, » совершаем только одно (CapsLock), то это эквивалентно исключению запятой из набора, т.к. для нее необходимо 2 нажатия. Итого остается 207 нажатий. Выигрыш составит 12/219≈5,5%, что для одной комбинации с АЗ очень много. Разумеется, это чисто гипотетический пример, в котором частота запятых завышена.
Отсюда, кстати, вытекает еще один аспект применения АЗ — соревновательный, т.к. на коротком легком тексте, с частотными словами можно весьма значительно поднять результат — вплоть до 20-25% (и даже выше). Как уже говорилось в самом начале статьи, при использовании АЗ должен проводиться отдельный зачет.
Вообще, чтобы оценивать реальный выигрыш, необходимо пересчитывать статистику символов в статистику нажатий, т.е. в символах не учитывается такая часто нажимаемая клавиша, как «Shift». Следует упомянуть еще и об «Enter», но при обычном анализе массивов текстовых данных эта клавиша (равнозначная абзацу или переходу на новую строку) обычно не учитывается. И в данной статье этот вопрос не освещается.
Для подсчета числа нажатий на клавишу «Shift» при наборе на стандартной раскладке ЙЦУКЕН нужно знать долю заглавных букв, а также долю знаков «,» и «!», «»», ««», «№», «;», «%», «:», «?», «*», «(», «)», «_», «+», т.е. всех, набираемых на четвертом ряду (цифровом) с использованием «Shift». Для первого приближения (которое, впрочем, должно быть достаточно точным), примем, что доли знаков, набираемых на четвертом ряду, приближенно равны нулю (в достаточной мере это соответствует действительности).
Заглавные буквы в подавляющем большинстве случаев набираются только в начале предложений. Можно добавить одну заглавную в середине предложения для учета имени собственного, если такое употребляется. Упрощенно примем, что на 1 предложение приходятся 2 заглавные буквы. Общая длина предложения в символах, согласно статистике корпуса русского языка, составит

где — среднее число слов в предложении.
— среднее число слов в предложении.
Если принять во внимание, что доля запятой составляет 1,5%, то это соответствует приближенно одной запятой на одно предложение: 65,8∙0,015≈0,9. Кроме того, есть еще в среднем 2 заглавные буквы. То есть, выходит, что нажатий на 3 больше, чем символов или 68,8 нажатий на 1 предложение в среднем. Из этих 68,8 нажатий 2 нажатия приходится на запятую. Как говорилось ранее, АЗ «, » на CapsLock эквивалентна исключению запятой из набора, поэтому выигрыш от такой АЗ в нажатиях составит:
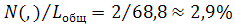
По сравнению с тем выигрышем, который был получен на словах, это весьма ощутимая прибавка только от одного сочетания. В принципе, этого следовало ожидать, ведь чем чаще комбинация, тем больше будет выигрыш от сокращения такой комбинации (при достаточной длине или количестве нажатий). Конечно, минимум, который еще можно сокращать – это двухсимвольные комбинации. А отдельные буквы уже не сокращаются. Здесь можно рассмотреть различные уровни агрегации: 2-символьный, 3-символьный и т.д. После 4-символьного разумнее уже рассматривать уровень слов, а затем фразеологический уровень. Разумеется, есть какие-то частотные сочетания букв, символов, слов, кроме тех, которые уже были нами рассмотрены.
За счет каких еще часто встречающихся синтаксических знаков можно повысить производительность? Например, можно заметить, что в подавляющем большинстве случаев после точки идет пробел (исключая многоточие, которое встречается редко, и его также можно назначить на отдельную клавишу, хотя бы в дополнительном слое). Также пробел всегда идет после знака тире (но не после дефиса). В принципе, по набору в большинстве редакторов тире и дефис набираются одной и той же клавишей «-/_», но, например, в Word тире выставляется, если до него и после были пробелы.
Предлагается ставить автопробел после тире, т.е. по комбинации « –» ставится дополнительный пробел. Это тоже позволит немного сэкономить на наборе сервисных знаков. Также можно ставить автопробелы после таких часто встречающихся знаков, как двоеточие «:» и точка с запятой «;». Можно ставить автопробел и после других знаков окончания предложения – вопросительного и восклицательного «?» и «!».
Бывают случаи, но очень редко, когда необходимо набрать несколько одинаковых знаков, идущих подряд. Для этого случая можно предусмотреть АЗ следующего вида. Пусть нужно набрать пять восклицательных знаков: «!!!!!», для этого будет использована АЗ вида «5!». Для редко встречающего многоточия можно тоже предусмотреть отдельную клавишу, например, «ё», поскольку на письме «е» и «ё» часто не различаются и «ё» остается неиспользованной (попрошу не кидать в меня камни сторонников повсеместного использования буквы «ё», т.к. АЗ можно назначить и на любую другую клавишу). В принципе, каждый может сам для себя определить неиспользуемые клавиши и назначить на них наиболее эффективные АЗ.
Рассмотрим автопробел после точки, и выигрыш от такой функции. Как упоминалось, вероятность появления точки в тексте равна 1,5%. На каждое предложение приходится приближенно по одной точке, после которой идет пробел. Исключая случаи, когда используются многоточия «…», которые весьма редки. Точка и пробел после нее составляют около 1,5%∙2=3% всех знаков. Используя автоматизированную постановку пробела после точки, мы исключаем половину из этих 3%, т.е. получаем еще 1,5% выигрыша. Это хороший результат для одной функции. Рассматривая автопробелы после других знаков – вопросительного и восклицательного, можно еще увеличить выигрыш. Но, как правило, доля таких знаков очень мала по сравнению с точкой и можно не рассматривать ее как значимую.
Достаточно частой комбинацией является « –» (пробел и тире), после нее идет еще один пробел. Если ставить автопробел после этой комбинации, то выигрыш в символах будет равен числу таких комбинаций, соответственно, выигрыш в процентах будет равен доле таких комбинаций в % от общего числа комбинаций заданной длины.
Можно записать общую формулу для расчета выигрыша от сокращения любой комбинации, зная ее долю (частоту) в общей структуре языка, включая синтаксические символы:

где kк — доля данной комбинации среди всех комбинаций такой же длины; это может быть диграмма (2 символа), триграмма (3 символа), n-грамма (длина n символов); в нашем случае имеем дело с диграммами;
n – количество символов, на которое можно сократить текст после встречи данной комбинации; в данной формулировке учтена как возможность АЗ, так и автопробела и схожих функций;
Vдоп — дополнительный выигрыш от сокращения всех остальных комбинаций, в которые входят исключаемые символы; в каждом конкретном случае должен рассчитываться отдельно.
Как уже упоминалось, можно использовать АЗ не только на уровне слов, но также и на уровне словосочетаний, фразеологическом уровне. Есть устойчивые словосочетания, например, некоторые из них: «как дела», «как жизнь», «добрый день», «потому что», «несмотря на», «во что бы то ни стало» и т.п.; менее частотные — «в любом случае», «исходя из вышесказанного», «из сказанного следует».
У каждого есть свои наиболее частотные фразы, которые он употребляет при разговоре и деловом общении, в переписке. Исходя из этих устойчивых словосочетаний можно разработать дополнение к системе АЗ именно для них. В каждом конкретном случае следует учитывать согласованность с уже существующей системой АЗ и подсчитывать выигрыш, предоставляемый автозаменой каждого нового сочетания.
Но гораздо более частыми, чем слова или словосочетания, являются n-граммы (n-символьные сочетания при небольшом n, n<5). Например, можно выделить такие часто встречаемые сочетания в конце слов, как «ный», «нный», «тся», «ться». Можно предусмотреть АЗ для них.
Например, если не использована клавиша с буквой «ё» (да простят меня сторонники её использования), то назначить одну из АЗ на эту клавишу. А комбинация этой клавиши с Shift'ом даст другую комбинацию, т.е. Shitf+ё=тся; ё=ться. Опять же, каждую из таких комбинаций нужно рассматривать отдельно, в соответствии с их частотой и согласованностью с уже составленной системой сокращений. Важно, чтобы не было путаницы, и не было похожих по написанию сокращений на слова, которые пишутся целиком совершенно по-разному.
Далее можно связать систему АЗ и процедуру оптимизации раскладки.
Процедура оптимизации, описанная в предыдущей статье, в качестве входных параметров имеет систему штрафов и статистику диграмм. Система штрафов/поощрений останется такой же, а вследствие применения системы АЗ статистика диграмм каким-то образом изменится.
Соответственно, оптимальная раскладка для некоторой системы АЗ будет отличаться от оптимальной раскладки, используемой без АЗ. Необходимо пересчитать изменения статистики по каждой позиции автозамены – для каждого слова с АЗ, сочетания, комбинации синтаксических символов.
Для расчета изменения частоты сочетания нужно рассмотреть конкретный пример, из которого затем можно вывести общие закономерности. Возьмем слово «больше». Частота вхождения слова в корпус – 124201 раз. Общее число слов корпуса =1,93∙108. Средняя длина слова ≈5,28 симв. Доля синтаксических символов k≈20%. Теперь у нас есть все данные, чтобы посчитать количество символов в корпусе. Такой пересчет нужен, чтобы привести статистику слов к статистике диграмм (а число диграмм в тексте равно числу символов в нем минус 1). Общее число символов в корпусе:
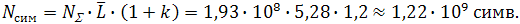
Зная число вхождений конкретного слова в корпус, мы автоматически знаем число вхождений каждой диграммы именно от этого слова в корпус. Т.е. для слова «больше» это будет не общая частота диграмм «бо», «ол», «ль» и т.д., а только частота диграмм «бо», «ол», «ль», … именно этого слова. Данная частота запишется:

где — частота любой диграммы рассматриваемого слова;
— частота любой диграммы рассматриваемого слова;
 — частота вхождения слова в корпус;
— частота вхождения слова в корпус;
 — общее число символов корпуса, найденное выше.
— общее число символов корпуса, найденное выше.
Для примера посчитаем частоты диграмм, привносимых в корпус словом «больше»:
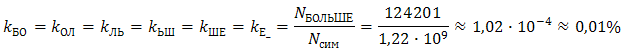
Данные частоты при использовании АЗ будут вычитаться из общего числа соответствующих диграмм, а некоторые новые, привносимые сокращением — добавляться.
Для конкретизации допустим, что слово «больше» будет сокращаться при наборе до «бо». Тогда найденные частоты диграмм «ол», «ль», «ьш», «ше», «е » будут вычитаться из общей таблицы частот диграмм. Сочетание «бо» остается неизменным, и его пересчитывать не надо. Но добавится новая диграмма, ранее не существующая в слове – «о ».
Ее частота будет такой же, как и у остальных, (т.е. число ее вхождений в корпус равно частоте вхождений слова) – 0,01%. Значение этой частоты добавится в общую таблицу частот диграмм. Для завершения рассмотрения посчитаем результирующие частоты, полученные только для АЗ «бо»=«больше».
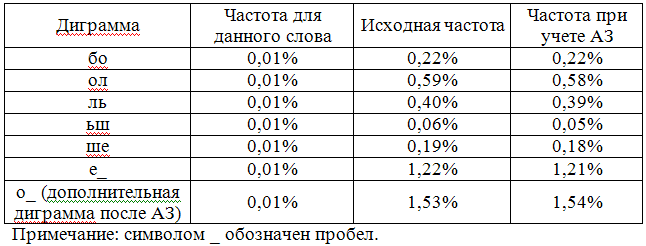
Если строго, то нужно также учитывать и то, что объем набранного текста при увеличении числа АЗ будет уменьшаться. Т.е. эффект лучше считать в абсолютных величинах, приходящихся на текст какого-либо объема. Таким образом, точнее будет, если считать не относительные изменения (проценты), а абсолютные величины: сколько диграмм данного типа было в тексте и сколько стало. Перевод в относительные величины нужен только на финальном этапе подсчета, перед тем, как запускать процедуру оптимизации.
Поскольку объем данных достаточно большой, данный этап (впрочем, как и все), нуждается в частичной или полной автоматизации.
Описанная процедура должна повторяться для каждой автозамены. В результате мы получим пересчитанную статистику диграмм, которую можно использовать как входную переменную для процедуры оптимизации раскладки.
При использовании раскладки, оптимизированной с учетом АЗ, и соответствующей системы АЗ, в совокупности можно добиться ощутимого улучшения параметров набора как по удобству, так и по скорости.
Для практического использования автозамен можно задействовать популярные программы AutoHotKey или PuntoSwitcher.
Документацию по программе AutoHotKey можно посмотреть здесь, некоторые из возможностей — здесь.
Оформление отдельных строк общего скрипта с АЗ:
слово «время» появится после нажатия «в» и клавиши-активатора, обычно это пробел.
в этом случае слово «время» появится сразу после набора «в».
; — необязательный символ, отделяет комментарии.
В качестве послесловия отмечу, что данная статья, как и предыдущая, имеет в основном академическую направленность. Практическое применение ограничено только профессиональными или полупрофессиональными наборщиками, которых крайне мало в общей массе пользователей ПК. Тем не менее, выражаю надежду, что некоторые наиболее удобные замены уже используются или могут быть использованы почти каждым. Приветствуется конструктивная критика по вопросам расчетов и логики изложения.
Здесь мы пойдем несколько другим путем и рассмотрим возможность сокращения общего числа нажатий на клавиши (кроме использования аккордных способов набора и стенотайпов, т.к. это уже другая большая тема).
Сразу оговорюсь, что применение стенотайпа вкупе со знанием стенографии, конечно, даст гораздо больший эффект в плане прироста производительности. Но способ, рассматриваемый ниже, легко реализуем (нет необходимости в спецоборудовании, сложном программном обеспечении) и требует на порядки меньше времени для изучения (запомнить несколько десятков сокращений обычно несложно).
Что такое автозамены?
Автозаменой (АЗ) будем называть такой способ печати сочетания букв/слова/фразы, при котором исходный текст программно переназначается на другие сочетания клавиш. Для целей повышения производительности набираемое сочетание клавиш (назовем его ключом или сокращением) должно иметь минимальную длину по отношению к исходной последовательности букв. Разность в числе нажимаемых клавиш при наборе комбинации в исходном виде и при наборе с сокращениями и будет выигрышем на данной комбинации за счет АЗ.
Например, нужно набрать такое часто используемое слово, как «потому». Если сокращение выглядит как «п», то выигрыш при наборе только одного слова составит 5 символов.
Отметим, что в мире подобная практика уже давно существует. Даже проводятся соревнования в различных зачетах — с использованием системы сокращений и без оной. В первом случае мировой рекорд на 30-минутном интервале равен 955 уд/мин, во втором — 821 уд/мин. Оба рекорда поставила небезызвестная Хелена Матушкова.
Наиболее развита система сокращений для чешского языка, именуемая Завописью (ZAVpis). Есть даже обучающий сайт, и есть информация, что освоение системы сокращений начинается только после приобретения достаточно высокого уровня навыка набора вслепую.
Как видим из отношения чисел 955 и 821, выигрыш при использовании АЗ не такой и высокий (~16%). Однако, в данном случае система АЗ адаптирована под среднестатистическую структуру языка, и не учитывает специфические слова, особенности, характерные для различных областей знаний. Также не учитывается лексикон пользователя, используемый в общении, повседневной переписке. В обиходе или узкой практической области словарный запас гораздо меньше по объему, и эффективность системы АЗ, составленной под конкретные потребности, может значительно возрасти.
Выбор слов и другие вопросы создания системы автозамен
Сначала необходимо определиться, для каких целей создается система автозамен. Если требуется система АЗ для уменьшения времени набора среднестатистического предложения в русском языке, то необходимо учитывать структуру языка в целом. Здесь можно пойти двумя путями.
Один из них – собственноручно собрать большую выборку текстов, адекватно представляющую язык (обычно объем такой выборки – от нескольких сотен мегабайт) и проанализировать их статистически – выделить самые частые слова, сочетания букв, символов. Затем на основе анализа построить статистические таблицы.
Отметим, что этот способ больше подходит для случая, когда система АЗ создается для себя, под свои наиболее часто используемые слова — в статьях, в деловой переписке, при общении в чате, на форуме и пр.
Второй – воспользоваться уже готовыми таблицами. Разумеется, такие таблицы уже есть в пригодном для применения виде. Здесь подразумевается использование Национального корпуса русского языка и частотных словарей русского языка (одним из наиболее известных является частотный словарь Шарова: [1]; [2]).
Список 100 наиболее частых словоформ можно просмотреть здесь.
Представляется логичным, что автозаменам должны подвергаться в первую очередь наиболее частотные слова, а среди них – самые длинные. Вообще, все языковые статистики подчиняются закону Ципфа. Это обобщенно-гиперболическое распределение ранжированных статистик, неважно, на каком уровне – будь то уровень отдельных букв, символов; уровень буквосочетаний (n-грамм); уровень слов; фразеологический уровень.
Такие статистики, наряду с гауссовыми, очень часто проявляются в окружающем нас мире, и были обнаружены в самых разных областях знаний. Например, распределение людей по доходу (Парето), распределение ученых по производительности (Лотка), распределение статей по журналам (Брэдфорд), распределение населенных пунктов по численности, распределение землетрясений по интенсивности и пр. Вообще, такие статистики возникают вследствие сильной взаимозависимости событий в системе (аналог положительной обратной связи), по типу цепной реакции, в результате которой может происходить как чрезвычайное усиление, так и сильное ослабление.
Для нас важен тот факт, что пики, положительные отклонения от гиперболического тренда будут как раз указывать на те слова, которые в первую очередь должны войти в систему АЗ. При этом наибольший вклад в итоговую эффективность системы внесут первые несколько сотен наиболее частотных слов.
Рассмотрим и другие особенности построения системы АЗ:
1. Ключи должны быть уникальными (не совпадать со словами и с другими ключами), минимальными по длине, легко запоминаемыми. Такие ключи должны состоять либо из нескольких первых букв слова, либо из первых и последних.
2. Назначение ключей (их длина, используемые буквы, символы) будет зависеть и от размера самой системы АЗ. Рассмотрим простейший пример. Пусть мы хотим создать систему для одного-единственного слова «потом», очевидно, что наилучший вариант — сокращение «п». Если же система будет состоять из двух из более слов (реальный вариант), то нужно учитывать встречаемости, а также п.1. Пусть слово «потом» встретилось 10 000 раз, а слово «потому» — 100 000 раз. Очевидно, что слову с максимальной встречаемостью нужно присвоить сокращение минимальной длины «п», а слову «потом» — сокращение «пм». Конечно, в случае только двух сокращений второму слову тоже можно приписать единственную букву. Но этот случай все еще далек от практического применения, а потому мы применили сокращение «пм», что более правдоподобно.
Нужно также учесть, что однобуквенных ключей максимум 33 (без использования цифр и символов в качестве ключей), двухбуквенных 332=1089. И то, при завышенной оценке. Вряд ли будут ключи вида «ъъ» или «юь».
3. Некоторые ключи могут быть в иерархической форме. Например, «ч»->«что»->«что-либо». При этом ключ может «разворачиваться» как и сразу после набора, так и после нажатия клавиши-активатора.
4. Размер системы АЗ должен быть компромиссом между теоретическим выигрышем и временем, необходимым для изучения системы. Я не использовал АЗ широко, но для развернутой системы приличный потолок оцениваю примерно в 1000 сокращений. Для системы, используемой в обиходе — 100 сокращений вполне хватит для самых часто используемых слов, фраз, оборотов.
Расчет выигрыша от использования автозамен
Автозамена уменьшает количество набираемых символов. Т.е. длина слова уменьшается на Lсл-LАЗ. Допустим, если мы слово «что» заменяем на «ч», то на одном слове выигрыш будет L(что)-L(ч)=3-1=2 символа. Далее, каждое слово имеет свою определенную частоту, выраженную в процентах. Или, если мы пользуемся корпусом, то в нем обычно приводятся данные о встречаемости слова – т.е. вообще количество таких слов в корпусе.
Например, слово «что» встречается в корпусе 2210373 раза. Тогда общий выигрыш от набора всех слов «что» в корпусе составит
символов.
Чтобы посчитать относительный выигрыш в процентах от общего числа набранных символов, нам нужно знать характеристики русского языка в среднем. Общий объем корпуса составляет 1,93∙108 слов. Логично было бы разделить число слов «что» на общее число слов, но слова имеют разную длину, которую тоже нужно учитывать. Средняя длина слов в русском языке, согласно корпусу, составляет 5,28 символа.
Теперь мы можем теперь посчитать объем корпуса в символах. Но корпус — это еще не весь текст. Реально в тексте встречается много сервисных знаков, таких как пробел, точка, запятая, точка с запятой, кавычки, различные знаки, цифры и т.д. И для нахождения объема всего текста по корпусу нам нужно умножить число найденных символов на некоторый коэффициент, который отражает долю сервисных знаков в русскоязычном тексте. По собственным вычислениям, приближенно, доля сервисных знаков составляет ~20%, с небольшими отклонениями в ту или другую сторону.
Тогда выражение для расчета относительного выигрыша на постоянной автозамене одного слова приобретает вид:
где
— общее число слов в корпусе, — средняя длина слова в русском языке,k — доля сервисных знаков, цифр и прочих символов, не входящих в слова.
Остальные обозначения были расшифрованы ранее.
Таким образом, для одной-единственной автозамены на слове «что» мы получаем относительный выигрыш, равный
Как мы видим, для одного слова выигрыш достаточно большой, и многие могут подумать, что для развитой системы АЗ можно ожидать выигрыша порядка десятков процентов. Но мы использовали одно из самых частотных слов. А так как статистика встречаемости слов подчиняется гиперболическому закону, то вклад (частота) каждого последующего слова будет значительно убывать. Соответственно, выигрыш от АЗ на таких менее частотных словах также будет не очень ощутимым.
Начало таблицы сокращений
Строки отсортированы по суммарному выигрышу, получаемому от всех АЗ указанного слова по всему корпусу.
Влияние объема системы автозамен на ее эффективность
При выборе числа слов, подвергаемых АЗ, нужно учитывать тот факт, что время на изучение системы АЗ в первом приближении пропорционально числу сокращений. Т.е. список АЗ должен быть разумного размера, где найден компромисс между числом АЗ и выигрышем, который они дают. Для этого необходимо построить приближенный график зависимости относительного выигрыша от числа АЗ.
Априори можно предполагать, что сначала выигрыш будет значительным, и наклон кривой будет максимальным (т.к. слова более частотные). С уменьшением частотности слов, выигрыш от каждого последующего слова будет уменьшаться, наклон кривой также уменьшится. Интересный вопрос, будет ли наблюдаться насыщение? Каждая АЗ будет давать некоторый выигрыш, но не упадет ли при этом частота слова настолько, что каждый очередной относительный прирост будет стремиться к нулю.
В данном пункте основная задача – выяснить, до какого числа АЗ необходимо увеличивать список, чтобы соблюсти компромисс между относительным выигрышем и временем на обучение. Т.е. нужно выявить переходную область, где наклон кривой выигрыша становится относительно небольшим, с тем, чтобы исключить малоэффективные АЗ.
График строился, исходя из некоторых упрощений, для общности анализа. Во-первых, длины всех сокращений АЗ предполагались равными двум символам. Соответственно, из списка наиболее частотных слов исключались слова длиной менее 3-х символов, т.к. выигрыша от них на такой системе АЗ не будет. Далее, предполагалось, что число 2-символьных сокращений будет не более 700. Это должно быть близко к истине, даже с несколько завышенной оценкой, т.к. очевидно, что абсолютно все 1089 диграмм не могут быть использованы в качестве сокращений по вполне понятным причинам (например, ни с чем не ассоциирующиеся сочетания букв, как было указано выше). Трехсимвольные сокращения на данном этапе не рассматривались.
По оси абсцисс отложено общее число слов с АЗ, по оси ординат — относительное сокращение числа нажатий на клавиши.
Как и ожидалось, в самом начале графика, для первых 100 сокращений скорость прироста выигрыша максимальная.
Приведем некоторые данные по графику:
для первых 10 сокращений выигрыш равен 0,82%,
для первых 20 – 1,24%,
для первых 50 – 2,23%,
для первых 100 – 3,50%,
для первых 200 – 5,37%,
для первых 300 – 6,63%,
для первых 400 – 7,52%,
для первых 500 – 8,33%,
для первых 600 – 9,04%,
для первых 700 – 9,76%.
Подсчитаем выигрыши для 1-й, 2-й, 3-й и т.д. сотен АЗ.
Для первой сотни, как уже упоминалось – 3,50%,
для второй – 1,87%,
для третьей – 1,26%,
для четвертой – 0,89,
5-й – 0,81%,
6-й – 0,72%,
7-й – 0,72%.
Как мы видим, скорость роста падает, но потом стабилизируется. Это достаточно неожиданный результат, не совпадающий с априорным предположением. Нет даже намека на насыщение зависимости. Видимо, при достаточном числе сокращений можно обеспечить большой выигрыш. Например, при 700 АЗ выигрыш по графику составит 9,76%. Это уже приемлемая величина.
В реальности выигрыш будет еще большим (примерно на 0,2-0,3%), т.к. используются не только 2-символьные АЗ, а также и 1-символьные для самых частых слов. Но в дальнейшем придется использовать уже 3-символьные сокращения, поэтому скорость прироста выигрыша немного упадет, скачком, относительно наблюдаемой на 6-й и 7-й сотнях АЗ.
Исходя из прироста выигрыша, можно ограничиться списком АЗ, состоящим из 500 сокращений, что даст выигрыш 8,33%. Необходимо еще упомянуть о том, что в повседневной жизни человек пользуется для переписки, общения, написания текстов ограниченным набором слов, вовсе не являющимся эквивалентным по структуре корпусу русского языка. Ежедневно используются слова, находящиеся в числе наиболее частых. Таким образом, для повседневных задач, которые не включают написание научных статей, выигрыш будет еще более значимым, возможно, даже в разы.
Можно высказать предположение, почему скорость прироста выигрыша не замедляется постоянно. Видимо, уменьшение частоты слова компенсируется тем, что менее частотные слова являются также более длинными, а выигрыш пропорционален произведению разности длин слова и АЗ на частоту слова.
Для визуального анализа необходимо построить график зависимости произведения длины слова на его частоту от ранга слова в частотном списке. Наиболее эффективными будут АЗ слов, образующих пики относительно средней тенденции (разумеется, с некоторыми оговорками — например, слово должно быть достаточно длинным).
О сравнительной эффективности автозамен для русского и английского языков
Автозамены не будут одинаково эффективны для различных языков вследствие различной сложности самых языков. Печать на тех языках, которые считаются «богаче» (в смысле большего числа словоформ), будут тяжелее поддаваться сокращению при помощи АЗ.
Например, для ряда европейских языков, видимо, АЗ будут более эффективными, чем для русского. В свою очередь, английский язык, наверное, будет более приспособлен к АЗ, чем немецкий.
Возьмем пример: в русском языке есть падежи, числа, в английском падежей нет, но есть число. Например, слово лампа – lamp.
Возможно, приведенный пример не во всех случаях справедлив (например, для глаголов ситуация будет иной). Однако, он показывает несколько характерных особенностей.
Из таблицы видно, что для всех падежей слова «лампа» в единственном и множественном числе для русского языка понадобится 12-3=9 автозамен, а для английского языка – всего 2 автозамены (единственное число и множественное число). Т.е. при сильно развитом, более избыточном, с большим числом словоформ языке задача назначения автозамен сильно усложняется.
Также в английском языке меньше самих букв (26 против 33 в русском), а следовательно, намного меньше сочетаний из этих символов. Максимальная возможная верхняя оценка 262 для английского и 332 для русского. В реальности, конечно, из них используется еще меньше. Для русского всего существует около ~700 смысловых диграмм (двухбуквенных сочетаний). Названные обстоятельства еще раз указывают на то, что языки, энтропия (избыточность) которых выше, хуже поддаются автозаменам.
Наконец, список наиболее частотных слов в английском языке также должен быть значительно короче, чем для русского. Т.е. если, например, взять 10%, 20%-ный охват (самые частые слова, которые образуют 10%, 20% всех слов), то для английского такой список тоже должен быть короче.
Из вышеприведенных примеров уже видно, что задача конструирования гибкой системы автозамен для русского языка является достаточно сложной нетривиальной задачей, а еще сложнее обеспечить хороший прирост производительности. В нашем случае хорошим будет считаться суммарный прирост производительности, начиная от 10%, в среднестатистическом смысле. Это тот минимум, к которому надо стремиться.
Использование автозамен для сервисных символов
Кроме слов, ощутимую долю символов составляют т.н. сервисные, синтаксические символы: знак пробела, знаки пунктуации и пр. На их долю приходится порядка 20% от общего числа символов.
Обратимся к списку наиболее частых 2-символьных сочетаний (для всех символов таких таблиц обычно нет, поэтому их нужно делать самостоятельно, анализируя большие объемы текстовой информации). Наиболее частым 2-символьным сочетанием является сочетание «, », т.е. запятая+пробел. По собственным данным, на его долю приходится 1,64% общего числа диграмм (двухсимвольных сочетаний).
Оценим выигрыш при автозамене этой комбинации одним символом (или одним нажатием). Можно назначить такую комбинацию на клавишу CapsLock, поскольку она достаточно редко используется в повседневной работе (конечно, можно использовать и другие варианты, удобные для конкретного пользователя).
В стандартной раскладке ЙЦУКЕН для набора запятой нужно нажать 2 клавиши – «Shift» и «.». Таким образом, комбинация, для набора которой требовались 3 нажатия, будет набираться одним нажатием. Что эквивалентно сокращению на 2 нажатия.
В данном случае выигрыш подсчитывается следующим образом: если бы диграмма полностью исключалась из набора, то тогда выигрыш равнялся ее частоте. Но в нашем случае происходит просто сокращение комбинации. Т.е. выигрыш будет пропорционален относительному сокращению комбинации и ее частоте:
где
— длина комбинации до сокращения, — длина комбинации после сокращения (с учетом АЗ), — частота комбинации среди комбинаций такой же длины.Таким образом, получаем выигрыш от сокращения «, » до одного нажатия
В реальности, учет одной этой диграммы не даст общей картины, т.к. нужно учитывать и то, что запятые исключатся и в диграммах, где они находятся на второй позиции.
Для расчета выигрыша в данном случае удобно воспользоваться унарной (односимвольной) статистикой, если она рассчитывалась в процессе подготовки таблиц. В нашем случае такая таблица рассчитывалась. Несмотря на некоторую вариабельность статистических характеристик для текстов разного жанра, наблюдается все же значительная их устойчивость, что позволяет говорить о некоторой статистической структуре русского языка в среднем.
В текстах, более-менее широко встречающихся на практике, доли точки и запятой в целом равны и составляют приблизительно по 1,5%. Для ориентировочных расчетов выигрыша от замены «, » на CapsLock такой оценки вполне достаточно.
Для того, чтобы понятно, как считать эффективность АЗ в данном случае, можно привести пример. Рассмотрим кусок текста, состоящий из трех предложений, в каждом из которых по 70 символов. Пусть в каждом предложении по одной заглавной букве (начало) и по 2 запятых. Тогда общее число ударов составит 219. Используем замену «, » на CapsLock. Далее выигрыш можно определить так: поскольку мы вместо трех нажатий для набора «, » совершаем только одно (CapsLock), то это эквивалентно исключению запятой из набора, т.к. для нее необходимо 2 нажатия. Итого остается 207 нажатий. Выигрыш составит 12/219≈5,5%, что для одной комбинации с АЗ очень много. Разумеется, это чисто гипотетический пример, в котором частота запятых завышена.
Отсюда, кстати, вытекает еще один аспект применения АЗ — соревновательный, т.к. на коротком легком тексте, с частотными словами можно весьма значительно поднять результат — вплоть до 20-25% (и даже выше). Как уже говорилось в самом начале статьи, при использовании АЗ должен проводиться отдельный зачет.
Вообще, чтобы оценивать реальный выигрыш, необходимо пересчитывать статистику символов в статистику нажатий, т.е. в символах не учитывается такая часто нажимаемая клавиша, как «Shift». Следует упомянуть еще и об «Enter», но при обычном анализе массивов текстовых данных эта клавиша (равнозначная абзацу или переходу на новую строку) обычно не учитывается. И в данной статье этот вопрос не освещается.
Для подсчета числа нажатий на клавишу «Shift» при наборе на стандартной раскладке ЙЦУКЕН нужно знать долю заглавных букв, а также долю знаков «,» и «!», «»», ««», «№», «;», «%», «:», «?», «*», «(», «)», «_», «+», т.е. всех, набираемых на четвертом ряду (цифровом) с использованием «Shift». Для первого приближения (которое, впрочем, должно быть достаточно точным), примем, что доли знаков, набираемых на четвертом ряду, приближенно равны нулю (в достаточной мере это соответствует действительности).
Заглавные буквы в подавляющем большинстве случаев набираются только в начале предложений. Можно добавить одну заглавную в середине предложения для учета имени собственного, если такое употребляется. Упрощенно примем, что на 1 предложение приходятся 2 заглавные буквы. Общая длина предложения в символах, согласно статистике корпуса русского языка, составит
где
— среднее число слов в предложении.Если принять во внимание, что доля запятой составляет 1,5%, то это соответствует приближенно одной запятой на одно предложение: 65,8∙0,015≈0,9. Кроме того, есть еще в среднем 2 заглавные буквы. То есть, выходит, что нажатий на 3 больше, чем символов или 68,8 нажатий на 1 предложение в среднем. Из этих 68,8 нажатий 2 нажатия приходится на запятую. Как говорилось ранее, АЗ «, » на CapsLock эквивалентна исключению запятой из набора, поэтому выигрыш от такой АЗ в нажатиях составит:
По сравнению с тем выигрышем, который был получен на словах, это весьма ощутимая прибавка только от одного сочетания. В принципе, этого следовало ожидать, ведь чем чаще комбинация, тем больше будет выигрыш от сокращения такой комбинации (при достаточной длине или количестве нажатий). Конечно, минимум, который еще можно сокращать – это двухсимвольные комбинации. А отдельные буквы уже не сокращаются. Здесь можно рассмотреть различные уровни агрегации: 2-символьный, 3-символьный и т.д. После 4-символьного разумнее уже рассматривать уровень слов, а затем фразеологический уровень. Разумеется, есть какие-то частотные сочетания букв, символов, слов, кроме тех, которые уже были нами рассмотрены.
За счет каких еще часто встречающихся синтаксических знаков можно повысить производительность? Например, можно заметить, что в подавляющем большинстве случаев после точки идет пробел (исключая многоточие, которое встречается редко, и его также можно назначить на отдельную клавишу, хотя бы в дополнительном слое). Также пробел всегда идет после знака тире (но не после дефиса). В принципе, по набору в большинстве редакторов тире и дефис набираются одной и той же клавишей «-/_», но, например, в Word тире выставляется, если до него и после были пробелы.
Предлагается ставить автопробел после тире, т.е. по комбинации « –» ставится дополнительный пробел. Это тоже позволит немного сэкономить на наборе сервисных знаков. Также можно ставить автопробелы после таких часто встречающихся знаков, как двоеточие «:» и точка с запятой «;». Можно ставить автопробел и после других знаков окончания предложения – вопросительного и восклицательного «?» и «!».
Бывают случаи, но очень редко, когда необходимо набрать несколько одинаковых знаков, идущих подряд. Для этого случая можно предусмотреть АЗ следующего вида. Пусть нужно набрать пять восклицательных знаков: «!!!!!», для этого будет использована АЗ вида «5!». Для редко встречающего многоточия можно тоже предусмотреть отдельную клавишу, например, «ё», поскольку на письме «е» и «ё» часто не различаются и «ё» остается неиспользованной (попрошу не кидать в меня камни сторонников повсеместного использования буквы «ё», т.к. АЗ можно назначить и на любую другую клавишу). В принципе, каждый может сам для себя определить неиспользуемые клавиши и назначить на них наиболее эффективные АЗ.
Рассмотрим автопробел после точки, и выигрыш от такой функции. Как упоминалось, вероятность появления точки в тексте равна 1,5%. На каждое предложение приходится приближенно по одной точке, после которой идет пробел. Исключая случаи, когда используются многоточия «…», которые весьма редки. Точка и пробел после нее составляют около 1,5%∙2=3% всех знаков. Используя автоматизированную постановку пробела после точки, мы исключаем половину из этих 3%, т.е. получаем еще 1,5% выигрыша. Это хороший результат для одной функции. Рассматривая автопробелы после других знаков – вопросительного и восклицательного, можно еще увеличить выигрыш. Но, как правило, доля таких знаков очень мала по сравнению с точкой и можно не рассматривать ее как значимую.
Достаточно частой комбинацией является « –» (пробел и тире), после нее идет еще один пробел. Если ставить автопробел после этой комбинации, то выигрыш в символах будет равен числу таких комбинаций, соответственно, выигрыш в процентах будет равен доле таких комбинаций в % от общего числа комбинаций заданной длины.
Можно записать общую формулу для расчета выигрыша от сокращения любой комбинации, зная ее долю (частоту) в общей структуре языка, включая синтаксические символы:
где kк — доля данной комбинации среди всех комбинаций такой же длины; это может быть диграмма (2 символа), триграмма (3 символа), n-грамма (длина n символов); в нашем случае имеем дело с диграммами;
n – количество символов, на которое можно сократить текст после встречи данной комбинации; в данной формулировке учтена как возможность АЗ, так и автопробела и схожих функций;
Vдоп — дополнительный выигрыш от сокращения всех остальных комбинаций, в которые входят исключаемые символы; в каждом конкретном случае должен рассчитываться отдельно.
Автозамены на уровне отдельных сочетаний букв и слов
Как уже упоминалось, можно использовать АЗ не только на уровне слов, но также и на уровне словосочетаний, фразеологическом уровне. Есть устойчивые словосочетания, например, некоторые из них: «как дела», «как жизнь», «добрый день», «потому что», «несмотря на», «во что бы то ни стало» и т.п.; менее частотные — «в любом случае», «исходя из вышесказанного», «из сказанного следует».
У каждого есть свои наиболее частотные фразы, которые он употребляет при разговоре и деловом общении, в переписке. Исходя из этих устойчивых словосочетаний можно разработать дополнение к системе АЗ именно для них. В каждом конкретном случае следует учитывать согласованность с уже существующей системой АЗ и подсчитывать выигрыш, предоставляемый автозаменой каждого нового сочетания.
Но гораздо более частыми, чем слова или словосочетания, являются n-граммы (n-символьные сочетания при небольшом n, n<5). Например, можно выделить такие часто встречаемые сочетания в конце слов, как «ный», «нный», «тся», «ться». Можно предусмотреть АЗ для них.
Например, если не использована клавиша с буквой «ё» (да простят меня сторонники её использования), то назначить одну из АЗ на эту клавишу. А комбинация этой клавиши с Shift'ом даст другую комбинацию, т.е. Shitf+ё=тся; ё=ться. Опять же, каждую из таких комбинаций нужно рассматривать отдельно, в соответствии с их частотой и согласованностью с уже составленной системой сокращений. Важно, чтобы не было путаницы, и не было похожих по написанию сокращений на слова, которые пишутся целиком совершенно по-разному.
Оптимизация раскладки с учетом автозамен
Далее можно связать систему АЗ и процедуру оптимизации раскладки.
Процедура оптимизации, описанная в предыдущей статье, в качестве входных параметров имеет систему штрафов и статистику диграмм. Система штрафов/поощрений останется такой же, а вследствие применения системы АЗ статистика диграмм каким-то образом изменится.
Соответственно, оптимальная раскладка для некоторой системы АЗ будет отличаться от оптимальной раскладки, используемой без АЗ. Необходимо пересчитать изменения статистики по каждой позиции автозамены – для каждого слова с АЗ, сочетания, комбинации синтаксических символов.
Для расчета изменения частоты сочетания нужно рассмотреть конкретный пример, из которого затем можно вывести общие закономерности. Возьмем слово «больше». Частота вхождения слова в корпус – 124201 раз. Общее число слов корпуса
=1,93∙108. Средняя длина слова ≈5,28 симв. Доля синтаксических символов k≈20%. Теперь у нас есть все данные, чтобы посчитать количество символов в корпусе. Такой пересчет нужен, чтобы привести статистику слов к статистике диграмм (а число диграмм в тексте равно числу символов в нем минус 1). Общее число символов в корпусе:Зная число вхождений конкретного слова в корпус, мы автоматически знаем число вхождений каждой диграммы именно от этого слова в корпус. Т.е. для слова «больше» это будет не общая частота диграмм «бо», «ол», «ль» и т.д., а только частота диграмм «бо», «ол», «ль», … именно этого слова. Данная частота запишется:
где
— частота любой диграммы рассматриваемого слова; — частота вхождения слова в корпус; — общее число символов корпуса, найденное выше.Для примера посчитаем частоты диграмм, привносимых в корпус словом «больше»:
Данные частоты при использовании АЗ будут вычитаться из общего числа соответствующих диграмм, а некоторые новые, привносимые сокращением — добавляться.
Для конкретизации допустим, что слово «больше» будет сокращаться при наборе до «бо». Тогда найденные частоты диграмм «ол», «ль», «ьш», «ше», «е » будут вычитаться из общей таблицы частот диграмм. Сочетание «бо» остается неизменным, и его пересчитывать не надо. Но добавится новая диграмма, ранее не существующая в слове – «о ».
Ее частота будет такой же, как и у остальных, (т.е. число ее вхождений в корпус равно частоте вхождений слова) – 0,01%. Значение этой частоты добавится в общую таблицу частот диграмм. Для завершения рассмотрения посчитаем результирующие частоты, полученные только для АЗ «бо»=«больше».
Если строго, то нужно также учитывать и то, что объем набранного текста при увеличении числа АЗ будет уменьшаться. Т.е. эффект лучше считать в абсолютных величинах, приходящихся на текст какого-либо объема. Таким образом, точнее будет, если считать не относительные изменения (проценты), а абсолютные величины: сколько диграмм данного типа было в тексте и сколько стало. Перевод в относительные величины нужен только на финальном этапе подсчета, перед тем, как запускать процедуру оптимизации.
Поскольку объем данных достаточно большой, данный этап (впрочем, как и все), нуждается в частичной или полной автоматизации.
Описанная процедура должна повторяться для каждой автозамены. В результате мы получим пересчитанную статистику диграмм, которую можно использовать как входную переменную для процедуры оптимизации раскладки.
При использовании раскладки, оптимизированной с учетом АЗ, и соответствующей системы АЗ, в совокупности можно добиться ощутимого улучшения параметров набора как по удобству, так и по скорости.
Реализация автозамен
Для практического использования автозамен можно задействовать популярные программы AutoHotKey или PuntoSwitcher.
Документацию по программе AutoHotKey можно посмотреть здесь, некоторые из возможностей — здесь.
Оформление отдельных строк общего скрипта с АЗ:
::в::время;
слово «время» появится после нажатия «в» и клавиши-активатора, обычно это пробел.
в::время;
в этом случае слово «время» появится сразу после набора «в».
:*:в::время; - то же самое, что и в предыдущем случае.
; — необязательный символ, отделяет комментарии.
В качестве послесловия отмечу, что данная статья, как и предыдущая, имеет в основном академическую направленность. Практическое применение ограничено только профессиональными или полупрофессиональными наборщиками, которых крайне мало в общей массе пользователей ПК. Тем не менее, выражаю надежду, что некоторые наиболее удобные замены уже используются или могут быть использованы почти каждым. Приветствуется конструктивная критика по вопросам расчетов и логики изложения.

