
В последнее время набирают популярность различные NoSQL базы данных. Эта статья начиналась как изучение особенностей
В ходе этого небольшого исследования, были выбраны для подробного рассмотрения СУБД, успешно применяющиеся в области Web. И, поскольку в тегах присутствует «PHP», я выбирал СУБД, которые уже можно использовать с этим языком.
Статья получилась объемной, для удобства навигации предлагаю воспользоваться оглавлением:
Виды NoSQL
Все NoSQL СУБД разделяются на несколько категорий:
- Key-value stores / Хранилища типа «ключ-значение»
- Column Family (Bigtable) stores / Масштабируемые распределенные хранилища
- Graph Stores / Графовые СУБД
- Document Stores / Документо-ориентированные СУБД
Ниже на рисунке схематично обозначены объемы используемых данных и сложность этих данных в этих видах NoSQL
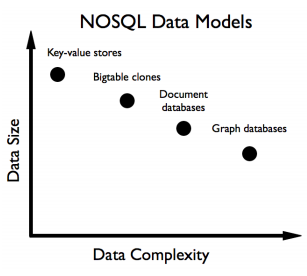
В каждом разделе я старался располагать СУБД в порядке увеличения функциональности. Возможно, получилось несколько субъективно.
Существуют базы данных, объединяющие в себе несколько категорий, например, OrientDB. Согласно официальному описанию по ссылке выше, она одновременно и графовая, и документо-ориентированная. Иногда её относят даже к Key-value stores и Column Family stores. Подробнее о ней позже в разделе графовых СУБД.
Рассмотрим подорбнее каждую категорию:
Key-value stores / Хранилища типа «ключ-значение»
Key-value stores — то самое направление, в котором NoSQL решения показывают свое превосходство над SQL.
И многие считают именно это направление наиболее востребованным в краткосрочной и долгосрочной перспективе.
Вот, например, автор оригинальной версии открытой СУБД MySQL, Майкл Видениус, так считает.
Key-value NoSQL очень популярны и они быстро и хорошо развиваются, видимо, из-за большого их количества и сильной конкуренции. Наибольшее количество NoSQL баз данных, которые были изучены в процессе написания статьи, относились именно к key-value stores.
На хабре есть статья по поводу key-value хранилищ для PHP, с которой я не во всем согласен. Общий выбор представленных в ней хранилищ (Voldemort, Scalaris, MemcacheDB, ThruDB, CouchDB ) мне показался уже не так актуальным спустя почти пять лет, которые прошли с момента публикации статьи. А описанная там CouchDB — совсем не key-value хранилище, а документо-ориентированная СУБД (см. секцию про документо-ориентированные СУБД).
MemcacheDB
Описание: тот же memcached, только с бэкграундом в виде BerkeleyDB.
Производительность: разработчиками представлены результаты тестов, по результатам которых средняя производительность в одном потоке составляет 18868 w/s (операций записи в секунду) и 44444 r/s (операций чтения в секунду). Тестировали на сервере Dell 2950III, который даже в самой слабой комплектации представляет собой нехилый аппарат.
Установка: все собирается из исходников. В PHP пользуемся обычным Memcached из PECL.
Лицензия: BSD-like License — использование бесплатно для коммерческих и некоммерческих проектов.
Redis
Описание: На хабре есть вводная статья с
Производительность: ~110.000 w/s, ~81.000 r/s на среднем железе.
Установка: сам Redis и клиент для PHP рекомендуют собирать из исходников. Клиентов существует немало (список), от себя рекомендовал бы phpredis за хорошее описание и поддержку всего (или почти всего) существующего функционала Redis.
Лиценция: BSD license — все бесплатно, но если что-то сломалось, то никаких претензий к разработчикам.
Tarantool
Описание: In-memory хранилище. Противопоставляется Redis, от которого отличается, по словам разработчиков, увеличенным быстродействием, благодаря тому, что все данные находятся в памяти. Есть встроенный механизм очередей. Есть хорошая хабростатья, описывающая основные возможности.
Установка: на Ubuntu ставится с помощью apt-get и капельки волшебства (официальная страница), клиент для PHP собираем из исходников (github)
Производительность: на уровне с Redis, результаты тестов противоречивые: Tarantool быстрее Redis у своего разработчика, Tarantool на уровне с Redis у обычного человека
Лиценция: Simplified BSD — все бесплатно.
Riak
Описание: база данных с сильным упором на отказоустойчивость и распределенность. Упор этот настолько силен, что компания-разработчик рекомендует выделить под Riak не менее пяти серверов для того, чтобы иметь возможность оценить его способности. На первый взгляд — это key-value хранилище, но в нем присутствует поиск по всем полям, вторичные ключи, MapReduce. Транзакции отсутствуют. Подробная и обстоятельная хабростатья.
Установка: много способов вплоть до установки из пакетов для Debian/Ubuntu. Для PHP есть PECL пакет, а так же официальный PHP-client.
Производительность: ей уделено не самое важное место, но есть упоминания о 2.500 операций в секунду.
Лиценция: Apache 2 License — бесплатно для простых людей, но для коммерческого использования цены за одну копию Riak Enterprise начинаются от $2,800/год.
Aerospike
Описание: масштабируемое хранилище для огромных объемов данных с минимальной задержкой (latency). Транзакции по умолчанию, поддержке ACID выделена отдельная страница. В версии 3 появились вторичные индексы. Впечатляет количество собственных технологий масштабирования, репликации и кластеризации (ссылка). Для себя эту систему запомнил как мощный промышленный Memcached.
Установка: Aerospike устанавливается из дистрибутива, официальный клиент для PHP существует только для Aerospike2, собирается из исходников.
Производительность: заявлена скорость от 180,000 до 400,000 операций в секунду с задержкой в микросекунды (источник).
Лиценция:
- Community Edition — бесплатный вариант с ограничениями: максимум два сервера по 200Гб данных на каждом;
- Enterprise Edition — триал 30 дней, никаких ограничений. По слухам, стоимость составляет от $50.000 за датацентр.
FoundationDB
Описание: позиционируется как комплексное и максимально простое в установке и настройке решение. Легкая масштабируемость, легкое управление — ключевые слова, которые цепляют. Пользователям предлагают «бескомпромисные ACID транзакции». Возможность использовать различные модели данных — key/value, document и даже SQL. Эта СУБД показалась мне особенно интересной, когда прочитал про ее производительность.
Производительность: 3,750,000 r/s*. *Чтение рандомных записей из оперативной памяти(кэша). На официальном сайте в разделе performance есть много интересных тестов, самый «медленный» из которых показывает результат ~235,000 операций в секунду (50/50 операций чтения и записи). Задержка чтения менее 2ms, задержка коммита менее 15ms. Результаты получены на кластере из 24 машин, в каждой по 16Gb RAM, 2x200Gb SSD, тестовая база состояла из 2млн key-value записей, все операции были транзакционными с максимальным уровнем изоляции и тройной репликацией.
Установка: и тут все просто: DEB-пакет для Ubuntu, PEAR-пакет для PHP.
Лиценция:
- Community License — бесплатное использование. Никаких ограничений при разработке и тестировании, но максимум 6 запущенных процессов на production, т.е. по одному процессу на шести серверах, по два на трех и т.д.;
- Enterprise License — без ограничений, от $99 до $199, в зависимости от качества поддержки.
Некоторые интересные проекты не были включены в этот список из-за отсутствия поддержки PHP. Так же не были включены проекты Voldemort, Scalaris, ThruDB. Из-за слабой производительности, либо скудной документации и из-за того, что с 2009 года в них ничего не изменилось к лучшему.
Column Family (Bigtable) stores / Масштабируемые распределенные хранилища
Представленные в этом разделе хранилища, в основном, спроектированы на основе дизайна оригинальной Google Bigtable.
Главная особенность этих NoSQL — работа с даннымх, объемы которых измеряются терабайтами.
Здесь уже не так важна моментальная скорость доступа, куда больший упор сделан на распределенность, отказоустойчивость и возможность обработки огромных объемов информации.
HBase
Описание: Open Source разработка на основе оригинального дизайна Google Bigtable от Apache. Разработана в рамках проекта Hadoop. Используется самим Facebook в качестве основы сервиса обмена сообщениями. У HBase выбор производится по одному проиндексированному полю. Присутствует частичная поддержка ACID, получается, что транзакционность вроде бы есть, но поддерживается она не самым очевидным способом.
Установка: устанавливается с помощью волшебной пилюли по имени Thrift, процесс установки и использования хорошо описан в этой хабростатье.
Производительность: полевые испытания с необычной методикой измерения производительности: на кластере из 7 серверов (16Gb RAM, 8x core CPU, HDD) проводились операции в таблице с 3 милиардами записей. Было запущено 300 процессов чтения/записи одновременно, измерялось время, затраченное на операцию. В результате, среднее время записи составило 10ms, чтения — 18ms.
Лиценция: Apache License 2.0 — использования в любых целях бесплатно.
Hypertable
Описание: интересная разработка, похожая на HBase. Имеет чуть большую производительность и значительно более привычный по синтаксису запросов HQL. Пример запроса:
select * from QueryLogByUserID where row =^ '003269359' AND "2008-11-13 05:00:00" <= TIMESTAMP < "2008-11-13 06:00:00"
Транцакции отсутствуют, о чем четко сказано в первых строчках документации на официальном сайте.
Установка: с PHP соединяем с помощью Thrift и официального ThriftClient(github).
Производительность: несколько графиков на официальном сайте. Как упоминалось выше, производительность похожа на HBase.
Лиценция: GNU General Public License Version 3. — использования в любых целях бесплатно. За дополнительную плату предлагается круглосуточная поддержка.
Cassandra
Описание: Распределенное хранилище, изначально разрабываемое в Facebook, впоследствии переданное в Apache. В отличие от вышеупомянутых, Cassandra является распределенной децентрализованной хэш-таблицой (DHT) и основана на Amazon's Dynamo. Имеет язык запросов CQL, очень похожий на SQL с некоторыми ограничениями. Можно строить запросы с выборкой по нескольким колонкам, добавлять вторичные индексы. В версии 2.0 появились «транзакции», которые работают по принципу «compare-and-swap».
Синтаксис транзакционного запроса будет приметно такой:
- Добавление записи
INSERT INTO users (login, email, name, login_count) values ('jbellis', 'jbellis@datastax.com', 'Jonathan Ellis', 1) IF NOT EXISTS - Обновление записи
UPDATE users SET reset_token = null, password = ‘newpassword’ WHERE login = ‘jbellis’ IF reset_token = ‘some-generated-reset-token’
Установка: есть несколько способов установить взаимодействие между PHP и Cassandra(тот же Trift, Cassandra-PHP-Client-Library, cassandra-pdo). Последний вариант показался мне наиболее приятным.
Производительность: хорошие сравнительные тесты с графиками, по результатам которых, на 8 серверах при соотношении 50/50 операций чтения/записи Cassandra совершает около 9.000 операций в секунду. HBase делает около 2.500 при тех же условиях.
Лиценция: Apache License 2.0 — использования в любых целях бесплатно.
Существуют другие BigTable решения, например, Stratosphere, HPCC, Cloudera, Cloudata. Они не рассмотрены подробно по разным причинам, например: отсутствие поддержки PHP, низкая распространенность, плохая документация.
Graph Stores / Графовые СУБД
Именно ради них и затевалась эта статья. Недавно я открыл для себя графовые NoSQL как новый вариант структуры хранения данных и был немало обрадован, потому как в ряде проектов базовый функционал графовых СУБД приходилось реализовывать с помощью не самых простых запросов к MySQL.
В графовой СУБД структура хранимых данных может выглядеть примерно так:

Если занести в графовую СУБД все фильмы и связать с каждым снимавшихся в нем актеров, можно легко найти
фильмы, в которых снимались актеры, которые когда-либо снимались с актерами из "Матрицы", и никогда не снимались с актерами из "Пиратов Карибского Моря"
Neo4j
Описание: наиболее успешная и востребованная разработка в области графовых СУБД. Она полностью поддерживает ACID. Просто устанавливается и без особых усилий масштабируется. У нее уже сформировалось развитое комьюнити, по большинству возникающих вопросов можно быстро найти ответы. О ее возможностях в связке с PHP можно прочитать в этой статье.
Установка: ставится из своего репозитория, для PHP используется клиент Neo4jPHP
Производительность: ввиду особой специфики, мне показалось странным приводить конкретные показатели скорости чтения/записи. Она позволяет выбрать сложно связанные данные и делает это в разы быстрее, чем реляционные СУБД.
Лиценция:
- Community Edition — GPL-licensed open source, бесплатное использование
- Commercial Subscription — имеем высокопроизводительный кэш, расширенные возможности горизонтального масштабирования, поддержку и еще некоторые плюшки. Стоимость варьируется от $0 (если вы — стартап из трех человек с годовым оборотом проекта менее $100.000) до бесконечности (для очень больших компаний)
В этом разделе я описал только одну СУБД, а ее наиболее интересный конкурент, OrientDB, находится ниже. Как оказалось, существует на так много графовых СУБД для Web и для PHP в частности.
Есть еще Titan, который в качестве back-end использует HBase, BerkleyDB или Cassandra. Информации по его этому чуду не очень много, о способах подружить его с PHP еще меньше.
Стоит вспомнить и о FlockDB от Twitter, который можно подключить к php c помощью клиента, работающего на базе Thirt. Но, опять же, связи с небольшим количеством информации об этой СУБД, сложно составить о ней полное и объективное мнение.
Document Stores / Документо-ориентированные хранилища
В этом разделе рассмотрим документо-ориентированные хранилища — СУБД для иерархических структур данных. Эти хранилища универсальны: они обладают высокой скоростью чтения/записи, имеют гибкий подход к форматам хранимых данных, легко работают с неструктурированными данными и предоставляют широкие возможности для масштабирования.
MongoDB
Описание: пожалуй, самая популярная документо-ориентированная NoSQL СУБД. Данные хранятся в формате JSON/BSON. Хорошее масштабирование, репликации, индексы, Map-Reduce. Транзакции представлены в виде compare-and-swap.
Установка: MongoDB из репозитория, php-client из PECL.
Производительность: чуть выше были сравнительные тесты, в которых были результаты и по MongoDB.
Лиценция: GNU AGPL — open source, использование бесплатно.
CouchDB
Описание: разработка от Apache. Во многом похожа на MongoDB. Отличается отсутствием блокировки при операциях чтения, и более сложной в настройке технологией шардинга.
Установка: CouchDB из репозитория, для php клиента есть несколько вариантов(PHPillow, PHP Object Freezer, PHP-on-Couch, расширение из PECL).
Производительность: по результатам одного теста, она заметно медленнее MongoDB
Лиценция: Apache 2.0 — использование бесплатно.
Есть еще много разработок в этой области, но они показались мне очень однообразными. Хотя, возможно, я просто не достаточно глубоко изучил их.
OrientDB
Описание: документ-ориентированная и, в то же время, графовая CУБД.
Её ближайший конкурент как документ-ориентированной — MongoDB. Этому сравнению посвящена отдельная страница.
Главные преимущества OrientDB:
- полная поддержка ACID
- возможность использовать внешние ключи в документах(так же, как в реляционных СУБД)
- три типа используемых индексов (SB-Tree, Hash, MVRB-Tree) против B-Tree в MongoDB
- большая производительность(OrientDB выполняет 150.000 w/s на обычном железе)
- простой язык запросов, схожий с SQL
Отдельно хочу отметить язык запросов, сравните, как выглядят идентичные update-запросы:
- MongoDB
db.product.update( { “stock.qty”: { $gt: 2 } }, { $set: { price: 9.99 } } ) - OrientDB
UPDATE product SET price = 9.99 WHERE stock.qty > 2
Основной ее конкурент как графовой — Neo4j. И должен сказать, что освоить графовые возможности в OrientDB куда сложнее, чем в Neo4j. Первые представления об этом можно получить в этой статье.
Установка: с установкой нужно немного поколдовать, вот есть вполне рабочий мануал, а в качестве PHP-клиента рекомендована эта библиотека.
Производительность: обещают 150.000 w/s, также есть cравнение графовых СУБД
Лиценция:
- Community Edition — Apache 2 license open source, бесплатное использование для любых целей, включая коммерческое
- Enterprise Edition — расширенная поддержка и такие плюшки как Query Profiler, Metrics recording, Live Monitor with configurable alerts за £1,000 за первый сервер и £500 за каждый последующий. Для стартапов вдвое дешевле.
Некоторые выводы
В ходе написания статьи, я нашел много интересной полезной и полезной информации, и рад поделиться ей с хабровчанами.
Мне очень понравились такие решения как FoundationDB, Neo4j, OrientDB. Хочется посвятить каждой из них отдельную статью.
В заключение, хотелось бы поделиться веселой картинкой, которая помогает быстро выбрать NoSQL решение для своего проекта. Картинку увидел в комментарии пользователя 4dmonster, за что ему спасибо.


