
Этот цикл статей описывает волновую модель мозга, серьезно отличающуюся от традиционных моделей. Настоятельно рекомендую тем, кто только присоединился, начинать чтение с первой части.
В 1970 году Эдгар Кодд опубликовал статью (Codd, 1970), в которой описал основы реляционной модели хранения данных. Практической реализацией этой модели стали все современные реляционные базы данных. Формализация модели привела к созданию реляционного исчисления и реляционной алгебры.
Основной элемент реляционной модели – это кортеж. Кортеж – это упорядоченный набор элементов, каждый из которых принадлежит определенному множеству или, иначе говоря, имеет свой тип. Совокупность однородных по структуре кортежей образует отношение.
Несколько более наглядно все это выглядит в терминах, используемых в базах данных (рисунок ниже). Отношение – это таблица с данными. Кортеж — строка таблицы. Какого типа кортежи содержатся в отношении, или, что то же самое, каков формат строк в таблице, определяется заголовком отношения или таблицы. Каждый из столбцов таблицы образует домен. Значения, которое могут принимать элементы домена, называются атрибутами. Строки таблицы – это совокупность атрибутов, соответствующих доменам.
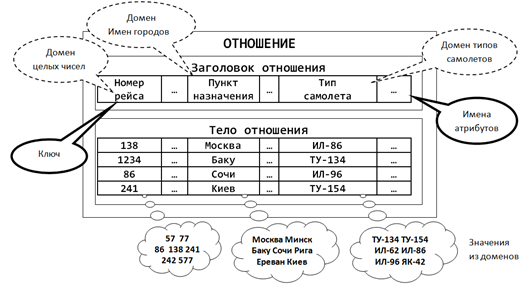
Пример отношения (Заборов)
Строки таблицы могут быть идентифицированы по своим атрибутам, то есть по тому, какие значения принимают элементы кортежа. Само содержание кортежа делает его непохожим на остальные. Но может так оказаться, что некоторые строки совпадут по своим атрибутам. Само по себе совпадение не страшно, но оно уже не позволяет использовать такой набор атрибутов, для однозначной идентификации кортежей в отношении. Чтобы идентификация была однозначной, вводят такое ключевое поле, которое для каждой строки принимает уникальное значение. Такой ключ может нести смысловую нагрузку, а может быть просто искусственно сгенерированным числом.
Совокупность всех отношений определяет базу данных. Каждое отношение хранит свою логическую часть информации. Чтобы получить определенные сведения может потребоваться сопоставление информации из разных отношений. Кодд описал восемь основных операций реляционной алгебры, позволяющих манипулировать с кортежами:
- Объединение;
- Пересечение;
- Вычитание;
- Декартово произведение;
- Выборка;
- Проекция;
- Соединение;
- Деление.
Замечательное свойство реляционной алгебры – это ее замкнутость, то есть операции над отношениями задаются таким образом, чтобы результат сам был отношением. То есть, имея несколько таблиц и производя соответствующие операции над ними, мы получим результатом тоже таблицу.
Смысл многих операций совпадает с соответствующими операциями из теории множеств. Общее представление об их сути дает рисунок ниже.
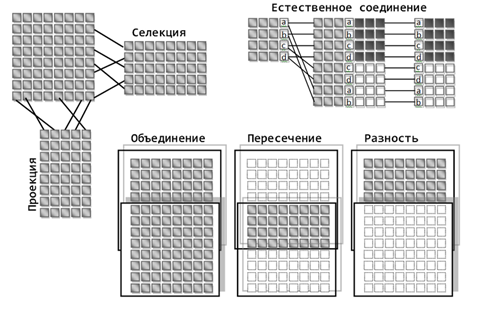
Пример операций над кортежами (Заборов)
Важно, что разные отношения могут содержать домены одного типа. Это значит, что если в двух кортежах встречаются одинаковые домены, внутри них одинаковые атрибуты, то можно говорить об определенной связи кортежей, содержащих эти атрибуты. Иначе говоря, если разные строки одной таблицы в одном из столбцов имеют одинаковые значения, то можно говорить об определенной связи этих строк. Или если в разных таблицах есть столбцы (домены) с одинаковым смыслом, то строки с одинаковыми значениями в этих столбцах оказываются связанными между собой.
Операция проекции позволяет получать отношения, состоящие из части элементов исходных отношений, ограничивая набор используемых доменов. Выборка или селекция позволяет получать отношения, содержащие только те кортежи, поля которых удовлетворяют условиям выборки. Например, можно выбрать только те кортежи, указанные домены которых имеют заданные значения атрибутов.
Совокупность всех операций над отношениями позволяет извлечь из базы данных любую интересующую информацию и сформировать ее в виде отношения (таблицы) с наперед заданными свойствами (заголовком).
Реляционной модель данных возникла не случайно, а явилась следствием необходимости оперировать с большими объемами разнообразных данных. Оказалось, что такая структура хранения данных и определенные в этой структуре операции удобны для решения широкого спектра прикладных задач. Можно предположить, что аналогичное удачное решение могла нащупать и природа в результате естественного отбора.
Описываемая нами система идентификаторов, понятий и событийной памяти во многом очень похожа на реляционную модель. Можно привести ряд аналогий:
- Нейрон оперирует информацией с нескольких дендритных сегментов, каждый из которых настроен на данные определенного типа. Дендритные сегменты одного типа можно сопоставить с определенным доменом;
- Сочетания понятий, которые описывают информацию, характерную для дендритного сегмента, соответствуют атрибутам, встречающимся в домене;
- Понятия, используемые зоной коры, и идентификаторы, задающие структуру пакетов, характерную для этой зоны, определяют структуру доменов (заголовок);
- Использование общих понятий при проекции информации между зонами соответствует использованию общих доменов в разных отношениях;
- Совокупность зон коры, формирующих мозг, соответствует совокупности отношений, формирующих базу данных;
- Ассоциативность, между воспоминаниями, соответствует связанности через общие атрибуты различных кортежей;
- Распределенность воспоминания по зонам коры соответствует тому, как одно событие может породить несколько кортежей в разных отношениях, объединенных единым уникальным ключом;
- Волна, описывающая текущее состояние мозга, может выступать аналогом запроса к базе данных. Так же, как результат операции над отношениями есть отношение, так и ответ мозга может быт совокупностью ассоциативно связанных описаний, совмещенных в одной волновой картине.
Конечно, между нашей моделью мозга и реляционными системами нет точного соответствия. Архитектура мозга значительно богаче, так как решает не только задачи хранения и извлечения данных, но и массу других совмещенных с этим функций. Однако даже имеющееся сходство позволяет лучше понять суть информационных процессов, происходящих в коре.
Использованная литература
Продолжение
Предыдущие части:
Часть 1. Нейрон
Часть 2. Факторы
Часть 3. Персептрон, сверточные сети
Часть 4. Фоновая активность
Часть 5. Волны мозга
Часть 6. Система проекций
Часть 7. Интерфейс человек-компьютер
Часть 8. Выделение факторов в волновых сетях
Часть 9. Паттерны нейронов-детекторов. Обратная проекция
Часть 10. Пространственная самоорганизация
Часть 11. Динамические нейронные сети. Ассоциативность
Часть 12. Следы памяти
Часть 13. Ассоциативная память
Часть 14. Гиппокамп
Часть 15. Консолидация памяти
Часть 16. Пакетное представление информации
Алексей Редозубов (2014)

