 На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется тэгирование кэша. Но если вы попробуете, то заметите, что в MongoDB не хватает функции удаления из кэша записей, которые читаются реже всего (LRU — Least Recently Used). Как поддерживать размер кэша в разумных рамках? LRU — это, кстати, «конек» memcached; вы можете писать в memcached, не задумываясь о том, что ваш кэш переполнится; но как же быть с MongoDB?
На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется тэгирование кэша. Но если вы попробуете, то заметите, что в MongoDB не хватает функции удаления из кэша записей, которые читаются реже всего (LRU — Least Recently Used). Как поддерживать размер кэша в разумных рамках? LRU — это, кстати, «конек» memcached; вы можете писать в memcached, не задумываясь о том, что ваш кэш переполнится; но как же быть с MongoDB?Раздумывая над этим, я написал на Python небольшую утилиту CacheLRUd (выложена на GitHub). Это демон для поддержки LRU-удаления записей в различных СУБД (в первую очередь, конечно, в MongoDB). Ферма таких демонов (по одному на каждой MongoDB-реплике) следит за размером коллекции, периодически удаляя записи, к которым доступ на чтение производится реже всего. Отслеживание фактов чтения той или иной записи кэша происходит децентрализовано (без единой точки отказа) по протоколу, основанному на UDP (почему так? потому что «наивный» вариант — писать из приложения в мастер-базу MongoDB при каждой операции чтения — плохая идея, особенно если мастер-база окажется в другом датацентре). Читайте подробности чуть ниже.
Но зачем?
Зачем может потребоваться заменять memcached на MongoDB? Попробуем разобраться. Понятие «кэш» имеет два различных типа использования.
- Кэш применяют, чтобы снизить нагрузку на перестающую справляться базу данных (или другие подсистемы). Например, пусть у нас есть 100 запросов в секунду на чтение некоторого ресурса. Включив кэширование и выставив маленькое время устаревания кэша (например, 1 секунду), мы тем самым снижаем нагрузку на базу в 100 раз: ведь теперь до СУБД доходит только один запрос из ста. И нам почти не нужно опасаться, что пользователь увидит устаревшие данные: ведь время устаревания очень мало.
- Есть и другой тип кэша: это кэш более-менее статических кусков страницы (или даже всей страницы целиком), и применяют его, чтобы снизить время формирования страницы (в том числе редко посещаемой). Он отличается от первого тем, что время жизни кэшированных записей велико (часы или даже дни), а значит, во весь рост встает вопрос: как же гарантировать, что кэш содержит актуальные данные, как его чистить? Для этого применяют тэги: каждый кусочек данных в кэше, имеющий отношение к некоторому крупному ресурсу X, помечают теми или иными тэгами. При изменении ресурса X дают команду «очистить тэг X».
Для первого варианта использования кэша ничего лучше, чем memcached, похоже, не изобретено. А вот для второго memcached буксует, и тут на помощь может прийти идея «MongoDB вместо memcached». Возможно, это как раз ваш случай, если ваш кэш:
- Относительно невелик (верхний предел — сотни гигабайт).
- Содержит много «долгоживущих» записей, устаревающих за часы и дни (или вообще никогда не устаревающих).
- Вы существенно используете тэги и полагаетесь на то, что операция очистки тэга должна работать надежно.
- Кэш хотелось бы сделать общим и одинаково легко доступным (т.е. реплицируемым) на всех машинах кластера, в том числе в нескольких датацентрах.
- Вам не хочется беспокоиться, когда одна из машин для кэша на какое-то время перестанет быть доступной.
MongoDB и ее репликация с автоматическим failover мастера (превращением реплики в мастера при «смерти» последнего) позволяют гарантировать надежность очистки того или иного тэга. В memcached же с этим проблема: серверы memcached независимы друг от друга, и для удаления тэга вам нужно «пойти» на каждый из них с командой очистки. Но что, если в этот момент какой-то из серверов memcached окажется недоступным? Он «потеряет» команду очистки и начнет отдавать старые данные; MongoDB данную проблему решает.
Ну и, наконец, MongoDB очень быстра в операциях чтения, ведь она использует событийно-ориентированный механизм работы с соединениями и memory mapped files, т.е. чтение производится напрямую из оперативной памяти при достаточном ее количестве, а не с диска. (Многие пишут, что MongoDB настолько же быстра, как memcached, но я не думаю, что это так: просто разница между ними с огромным запасом тонет на фоне сетевых задержек.)
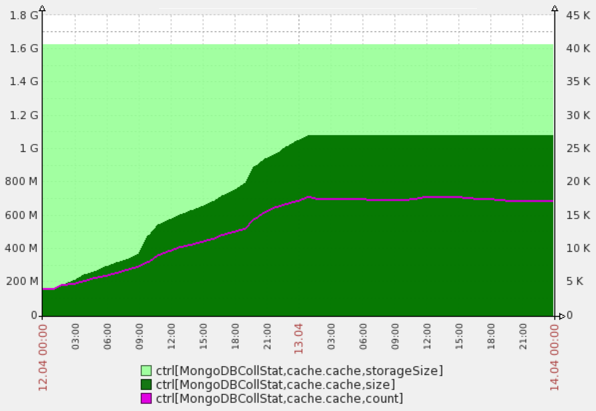
Вот как выглядит результат работы CacheLRUd на одном не слишком нагруженном проекте. Видно, что размер коллекции с кэшем действительно поддерживается постоянным на заданном в конфиге уровне 1G.
Установка CacheLRUd
## Install the service on EACH MongoDB NODE:
cd /opt
git clone git@github.com:DmitryKoterov/cachelrud.git
ln -s /opt/cachelrud/bin/cachelrud.init /etc/init.d/cachelrud
## Configure:
cp /opt/cachelrud/cachelrud.conf /etc/cachelrud.conf # and then edit
## For RHEL (RedHat, CentOS):
chkconfig --add cachelrud
chkconfig cachelrud on
## ...or for Debian/Ubuntu:
update-rc.d cachelrud defaults
Как работает демон
Чудес не бывает, и ваше приложение должно сообщать демону CacheLRUd (ферме демонов), какие записи в кэше оно читает. Приложение, очевидно, не может это делать в синхронном режиме (например, обновляя в мастер-базе MongoDB поле last_read_at в кэш-документе), потому что а) мастер-база может оказаться в другом датацентре относительно текущей веб-морды приложения, б) MongoDB использует протокол TCP, грозящий timeout-ами и «подвисанием» клиента при нестабильности связи, в) негоже выполнять запись при каждом чтении, не работает это в распределенных системах.
Для решения задачи применяется протокол UDP: приложение посылает UDP-пакеты со списком недавно прочитанных ключей тому или иному демону CacheLRUd. Какому именно — вы можете решить самостоятельно в зависимости от нагрузки:
- Если нагрузка сравнительно невысока, посылайте UDP-пакеты тому демону CacheLRUd, который «сидит» на текущей мастер-ноде MongoDB (остальные просто будут простаивать и ждать своей очереди). Определить, кто в текущий момент мастер, на стороне приложения очень легко: например, в PHP для этого применяют MongoClient::getConnections.
- Если же один демон не справляется, то вы можете отправлять UDP-сообщения, например, демонам CacheLRUd в текущем датацентре.
Подробности описаны в документации.
Что еще есть полезного
CacheLRUdWrapper: это простенький класс для общения с CacheLRUd из кода приложения на PHP, оборачивающий стандартный Zend_Cache_Backend (правда, этот класс для Zend Framework 1; если перепишете его для ZF2 или вообще для других языков, буду рад pull-request'ам).
Zend_Cache_Backend_Mongo: это реализация Zend_Cache_Bachend для MongoDB из соседнего GitHub-репозитория. Оберните объект данного класса в CacheLRUdWrapper, и получите интерфейс для работы с LRU-кэшем в MongoDB в стиле ZF1:
$collection = $mongoClient->yourDatabase->cacheCollection;
$collection->w = 0;
$collection->setReadPreference(MongoClient::RP_NEAREST); // allows reading from the master as well
$primaryHost = null;
foreach ($mongoClient->getConnections() as $info) {
if (in_array($info['connection']['connection_type_desc'], array("STANDALONE", "PRIMARY"))) {
$primaryHost = $info['server']['host'];
}
}
$backend = new Zend_Cache_Backend_Mongo(array('collection' => $collection));
if ($primaryHost) {
// We have a primary (no failover in progress etc.) - use it.
$backend = new Zend_Cache_Backend_CacheLRUdWrapper(
$backend,
$collection->getName(),
$primaryHost,
null,
array($yourLoggerClass, 'yourLoggerFunctionName')
);
}
// You may use $backend below this line.
Поделитесь в комментариях: что вы думаете по поводу всего этого?

