Как известно в одной папке не стоит хранить большое количество файлов т.к. очень быстро может произойти сбой в системе или попросту файлы будут очень медленно считываться.
Для решения этой задачи многие программисты берут md5 имени файла f789f789abc898d6892df98d09a8f8, после чего разбивают имя примерно таким образом:
/f7/89/f789abc898d6892df98d09a8f8.jpg
Математика тут очень проста — один символ это 16 вариантов.
Таким образом 2 символа это уже 16*16=256 вариантов.
В нашем случае у нас 2 вложенности по 2 символа, таким образом максимальное количество папок будет 256*256=65536 папок.
Если нам потребуется сохранить 1000000 файлов то число файлов в каждой папке не превысит 1000000/65536=15 файлов.
Да, вариант прост, но что если нам требуется не только хорошо сохранять файлы, но и еще быстро их находить?
Например у нас социальная сеть и мы хотим для каждого пользователя создать отдельную папку с номером его id и хранить в ней файлы которые в свою очередь тоже имеют свой id.
И для нас важно не только сохранить файл но и быстро найти где он лежит по его id.
Для решения этой задачи я написал класс, который позволяет сохранять на сервере большое количество файлов или папок в древовидной структуре папок.
Вот какую структуру создает класс:
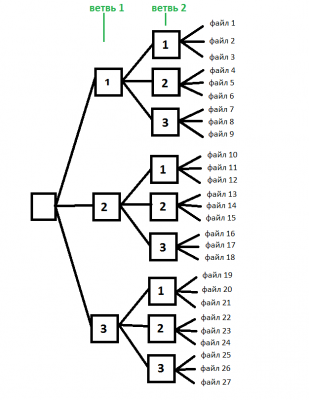
Чтобы посчитать максимально число файлов которое уместится в этой структуре нужно возвести максимальное количество файлов в папке в степень количества ветвей плюс один.
На изображении мы видим 2 ветви и по 3 файла в каждой папке.
Таким образом 3 нужно возвести в степень 2+1 = 3*3*3=27 файлов.
Для сохранения не более 1000000 файлов в такой структуре нам хватит 2 ветви по 100 файлов в каждой папке (100*100*100).
В класс нужно передать массив параметров — путь к папке где будет строиться дерево, максимальное число файлов в папке, число ветвей, либо можно применить паттерн (параметр pattern) максимального числа файлов, который уже был заранее просчитан — bigint, int, mediumint, smallint:
array('upload_dir'=>Q_PATH.'/uploads/','max_file_count'=>1000,'branches'=>2,'pattern'=>'')
Сам класс:
Скачать в архиве
Для варианта социальной сети описанной выше, требуется 2 раза использовать класс: вначале для построения дерева папок, потом для построения в каждой папке дерева для файлов.
Так же обращаю ваше внимание, что в этом посте я опустил (а не не знал) тему «Максимально допустимое количество файлов на жестком диске».
Для решения этой задачи многие программисты берут md5 имени файла f789f789abc898d6892df98d09a8f8, после чего разбивают имя примерно таким образом:
/f7/89/f789abc898d6892df98d09a8f8.jpg
Математика тут очень проста — один символ это 16 вариантов.
Таким образом 2 символа это уже 16*16=256 вариантов.
В нашем случае у нас 2 вложенности по 2 символа, таким образом максимальное количество папок будет 256*256=65536 папок.
Если нам потребуется сохранить 1000000 файлов то число файлов в каждой папке не превысит 1000000/65536=15 файлов.
Да, вариант прост, но что если нам требуется не только хорошо сохранять файлы, но и еще быстро их находить?
Например у нас социальная сеть и мы хотим для каждого пользователя создать отдельную папку с номером его id и хранить в ней файлы которые в свою очередь тоже имеют свой id.
И для нас важно не только сохранить файл но и быстро найти где он лежит по его id.
Для решения этой задачи я написал класс, который позволяет сохранять на сервере большое количество файлов или папок в древовидной структуре папок.
Вот какую структуру создает класс:
Чтобы посчитать максимально число файлов которое уместится в этой структуре нужно возвести максимальное количество файлов в папке в степень количества ветвей плюс один.
На изображении мы видим 2 ветви и по 3 файла в каждой папке.
Таким образом 3 нужно возвести в степень 2+1 = 3*3*3=27 файлов.
Для сохранения не более 1000000 файлов в такой структуре нам хватит 2 ветви по 100 файлов в каждой папке (100*100*100).
В класс нужно передать массив параметров — путь к папке где будет строиться дерево, максимальное число файлов в папке, число ветвей, либо можно применить паттерн (параметр pattern) максимального числа файлов, который уже был заранее просчитан — bigint, int, mediumint, smallint:
array('upload_dir'=>Q_PATH.'/uploads/','max_file_count'=>1000,'branches'=>2,'pattern'=>'')
Сам класс:
<?php //file index define("Q_PATH",dirname(__FILE__)); // class Functions { public static function arr_union(array $def_arr,array $new_arr) { foreach($new_arr as $key => $value) { if(array_key_exists($key, $def_arr) && is_array($value)) { $def_arr[$key]=self::arr_union($def_arr[$key], $new_arr[$key]); } else { $def_arr[$key]=$value; } } return $def_arr; } } /** * Класс построения дерева */ class Upload { public $id; private $upload_dir; private $max_file_count; private $branches; public function __construct(array $param=array()) { $def_param=array('upload_dir'=>Q_PATH.'/uploads/','max_file_count'=>1000,'branches'=>2,'pattern'=>''); $upload_param=Functions::arr_union($def_param,$param); $this->upload_dir=$upload_param['upload_dir']; $this->max_file_count=$upload_param['max_file_count']; $this->branches=$upload_param['branches']; //сложность надумана, все зависит от инодов df -i и tune2fs -l /dev/hda1 и df -Ti switch($upload_param['pattern']) { case 'bigint': $this->max_file_count=512; $this->branches=6; break; case 'int': $this->max_file_count=216; $this->branches=3; break; case 'mediumint': $this->max_file_count=204; $this->branches=2; break; case 'smallint': $this->max_file_count=182; $this->branches=1; break; } $this->del_id(); } public function set_id($id) { $this->id=$id; } public function del_id() { $this->id=0; } public function find_upload($url) { if(is_file($url)) { return true; } else { return false; } } public function get_upload($id,$fl) { $this->set_id($id); for($i=$this->branches;$i>=1;$i--) { $dir=ceil($this->id/pow($this->max_file_count,$i))%$this->max_file_count; $dir_file_arr[]=$dir>0?$dir:$this->max_file_count; } $dir_file_str=implode("/", $dir_file_arr); return $this->upload_dir.$dir_file_str.'/'.$this->id.$fl; } public function put_upload($id,$fl,$data) { $this->set_id($id); for($i=$this->branches;$i>=1;$i--) { $dir=ceil($this->id/pow($this->max_file_count,$i))%$this->max_file_count; $dir_file_arr[]=$dir>0?$dir:$this->max_file_count; $dir_file_str=implode("/", $dir_file_arr); if(!is_dir($this->upload_dir.$dir_file_str)) { mkdir($this->upload_dir.$dir_file_str, 0777); //chmod($this->upload_dir.$dir_file_str, 0777); } } file_put_contents($this->upload_dir.$dir_file_str.'/'.$this->id.$fl, $data); return $this->upload_dir.$dir_file_str.'/'.$this->id.$fl; } public function set_upload($id,$fl) { $this->set_id($id); for($i=$this->branches;$i>=1;$i--) { $dir=ceil($this->id/pow($this->max_file_count,$i))%$this->max_file_count; $dir_file_arr[]=$dir>0?$dir:$this->max_file_count; $dir_file_str=implode("/", $dir_file_arr); if(!is_dir($this->upload_dir.$dir_file_str)) { mkdir($this->upload_dir.$dir_file_str, 0777); //chmod($this->upload_dir.$dir_file_str, 0777); } } return $this->upload_dir.$dir_file_str.'/'.$this->id.$fl; } public function get_upload_dir($id) { $this->set_id($id); for($i=$this->branches;$i>=1;$i--) { $dir=ceil($this->id/pow($this->max_file_count,$i))%$this->max_file_count; $dir_file_arr[]=$dir>0?$dir:$this->max_file_count; } $dir_file_str=implode("/", $dir_file_arr); return $this->upload_dir.$dir_file_str.'/'.$this->id; } public function set_upload_dir($id) { $this->set_id($id); for($i=$this->branches;$i>=1;$i--) { $dir=ceil($this->id/pow($this->max_file_count,$i))%$this->max_file_count; $dir_file_arr[]=$dir>0?$dir:$this->max_file_count; $dir_file_str=implode("/", $dir_file_arr); if(!is_dir($this->upload_dir.$dir_file_str)) { mkdir($this->upload_dir.$dir_file_str, 0777); //chmod($this->upload_dir.$dir_file_str, 0777); } } if(!is_dir($this->upload_dir.$dir_file_str.'/'.$this->id)) { mkdir($this->upload_dir.$dir_file_str.'/'.$this->id, 0777); //chmod($this->upload_dir.$dir_file_str.'/'.$this->id, 0777); } return $this->upload_dir.$dir_file_str.'/'.$this->id; } }
Скачать в архиве
Для варианта социальной сети описанной выше, требуется 2 раза использовать класс: вначале для построения дерева папок, потом для построения в каждой папке дерева для файлов.
Так же обращаю ваше внимание, что в этом посте я опустил (а не не знал) тему «Максимально допустимое количество файлов на жестком диске».

