При разработке ПО часто возникают интересные задачи. Одна из таких: работа с гео-координатами пользователей. Если вашим сервисом пользуются миллионы пользователей и запросы к РСУБД происходят часто, то выбор алгоритма играет важную роль. О том как оптимально обрабатывать большое количество запросов и искать ближайшие гео-позиции рассказано под катом.

В процессе разработки сервиса push-уведомлений Pushwoosh возникла достаточно известная задача. Имеется много геозон. Геозона задается географическими координатами. Когда пользователь проходит мимо одной из таких геозон(например закусочная) ему должно приходить push-уведомление(«Йоу, заходи к нам и подкрепись с 20% скидкой). Для простоты будем считать радиус всех геозон одинаковым. В условиях большого количества геозон и большого количества пользователей(у нас их 500 миллионов!), которые постоянно перемещаются — поиск ближайшей геозоны должен осуществляться максимально быстро. В англоязычной литературе эта задача известна как Nearest neighbor search. На первый взгляд кажется, что чтобы решить эту задачу нужно посчитать расстояния от пользователя до каждой геозоны и сложность данного алгоритма линейна O(n), где n — количество геозон. Но давайте решим эту задачу за логарифм O(log n)!
Начнем с простого — широты и долготы. Чтобы указать положение точки на поверхности Земли можно воспользоваться:
Нужно обратить внимание что x — это долгота, y — широта(Google Maps, Яндекс.Карты и все остальные сервисы указывают долготу первой).
Географические координаты можно перевести в пространственные — просто точка (x,y,z). Кому интересно более подробно можно посмотреть википедию.
Количество знаков после запятой определяет точность:
Если нужна точность до одного метра, то следует хранить 5 знаков после запятой.
Пусть у нас есть сервис, которым пользуются миллионы людей, и мы хотим хранить их географические координаты. Очевидный подход в данном случае завести в таблице два поля — широта/долгота. Можно использовать double precision(float8), который занимает 8 байт. В итоге нам потребуется 16 байт для хранения координат одного пользователя.
Но есть и другой подход, который называется geohashing. Идея простая. Широта и долгота кодируется в число, которое затем кодируется в base-32. Карта разбивается на матрицу размера 4x8 и каждой ячейке присваивается некоторый символ(alphanumeric).

Чтобы повысить точность, каждая ячейка разбивается на более мелкие, при этом к коду добавляются символы(если быть точным цифры, а после происходит кодирование в base-32).

Разбиение можно производить до необходимой точности. Такой код уникален для каждой точки.
Подробно алгоритм построения я описывать не буду, о нем можно почитать в википедии. Его идея похожа на арифметическое кодирование. Данный код обратим. Многие технологии уже имеют встроенные методы для работы с гео-хешами, например, MongoDB.
Пример: координаты 57.64911,10.40744 будут закодированы в u4pruydqqvj (11 символов). Если требуется меньшая точность, то и код будет меньше.
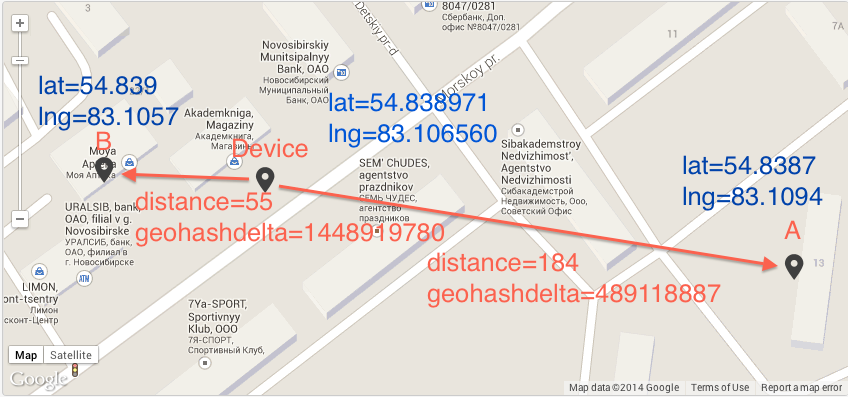
Особенность данного кода в том, что ОБЫЧНО близлежащие точки имеют одинаковый префикс. И можно посчитав разницу между гео-хешами определить близость двух точек. Но к сожалению данный алгоритм не точен, это хорошо видно из предыдущих изображений. Ячейки с кодами 7 и 8 находятся дальше друг от друга, чем ячейки 2 и 8.
В качестве примера приведу картинку, где гео-хеш дает неверный результат(geohashdelta — разность между геохешами без base32)
Если точностью в задаче можно пренебречь, то можно создать в таблице поле geohash, добавить по нему индекс и производить поиск за логарифм.
Можно написать хранимую процедуру
и использовать её
Но в итоге будет Seq Scan, что очень не приятно.
Что делать, когда точностью пренебречь не получается? Для этого уже есть специальная структура данных K-d tree. Можно перевести широту и долготу в (x,y,z) построить по ним дерево и производить поиск по дереву в среднем за логарифм.
PostGIS — это расширение, которое значительно расширяет обработку географических объектов в РСУБД PostgreSQL.
Для решения нашей задачи будет использовать трехмерную систему координат SRID 4326(WGS 84). Данная система координат определяет координаты относительно центра масс Земли, погрешность составляет менее 2 см.
Если у вас ubuntu-подобная система, то PostGIS можно установить из пакета(для PostgreSQL 9.1):
И подключить необходимые экстеншены:
С помощью \dx можно посмотреть все установленные экстеншены.
Создадим отношение с индексом по полю location
После чего для поиска ближайшей геозоны можно воспользоваться следующим запросом
Здесь <-> — distance operator. Мы посчитали дистанцию и нашли ближайшие 10 геозон!
СТОП скажите Вы! Ведь данный запрос должен просмотреть все записи в таблице и посчитать расстояние до каждой геозоны O(n).
Давайте посмотрим EXPLAIN ANALYZE запроса
Index Scan! Где же магия?
А она находится в GiST индексе.
PostgreSQL поддерживает 3 типа индексов:
GiST-индекс реализованный PostGIS поддерживает distance operator <-> при поиске. Также данный индекс может быть составным!
Данный функционал можно реализовать и без использования PostGIS, воспользовавшись индексом btree-gist, но PostGIS предоставляет удобные методы для перевода широты и долготы в WGS 84.
[1] Интересные примеры запросов postgresql.ru.net/postgis/ch04_6.html
[2] Восхищение простотой использования boundlessgeo.com/2011/09/indexed-nearest-neighbour-search-in-postgis
[3] Презентация о том, что данный подход можно использовать не только для широты/долготы, но и для улиц и других интересных объектов www.hagander.net/talks/Find%20your%20neighbours.pdf
[4] Презентация разработчиков KNN GIst-index www.sai.msu.su/~megera/postgres/talks/pgcon-2010-1.pdf
P.S.
Postgres version >= 9.1
PostGIS version >= 2.0
Задача поиска ближайшего соседа
В процессе разработки сервиса push-уведомлений Pushwoosh возникла достаточно известная задача. Имеется много геозон. Геозона задается географическими координатами. Когда пользователь проходит мимо одной из таких геозон(например закусочная) ему должно приходить push-уведомление(«Йоу, заходи к нам и подкрепись с 20% скидкой). Для простоты будем считать радиус всех геозон одинаковым. В условиях большого количества геозон и большого количества пользователей(у нас их 500 миллионов!), которые постоянно перемещаются — поиск ближайшей геозоны должен осуществляться максимально быстро. В англоязычной литературе эта задача известна как Nearest neighbor search. На первый взгляд кажется, что чтобы решить эту задачу нужно посчитать расстояния от пользователя до каждой геозоны и сложность данного алгоритма линейна O(n), где n — количество геозон. Но давайте решим эту задачу за логарифм O(log n)!
Географические координаты
Начнем с простого — широты и долготы. Чтобы указать положение точки на поверхности Земли можно воспользоваться:
- Широтой(latitude) — идет с севера на юг. 0 — экватор. Изменяется от -90 до 90 градусов.
- Долготой(longitude) — идет с запада на восток. 0 — нулевой меридиан(Гринвич). Изменяется от -180 до 180 градусов.
Нужно обратить внимание что x — это долгота, y — широта(Google Maps, Яндекс.Карты и все остальные сервисы указывают долготу первой).
Географические координаты можно перевести в пространственные — просто точка (x,y,z). Кому интересно более подробно можно посмотреть википедию.
Количество знаков после запятой определяет точность:
| Градусы | Дистанция |
|---|---|
| 1 | 111 km |
| 0.1 | 11.1 km |
| 0.01 | 1.11 km |
| 0.001 | 111 m |
| 0.0001 | 11.1 m |
| 0.00001 | 1.11 m |
| 0.000001 | 11.1 cm |
Если нужна точность до одного метра, то следует хранить 5 знаков после запятой.
Geohashing
Пусть у нас есть сервис, которым пользуются миллионы людей, и мы хотим хранить их географические координаты. Очевидный подход в данном случае завести в таблице два поля — широта/долгота. Можно использовать double precision(float8), который занимает 8 байт. В итоге нам потребуется 16 байт для хранения координат одного пользователя.
Но есть и другой подход, который называется geohashing. Идея простая. Широта и долгота кодируется в число, которое затем кодируется в base-32. Карта разбивается на матрицу размера 4x8 и каждой ячейке присваивается некоторый символ(alphanumeric).
Чтобы повысить точность, каждая ячейка разбивается на более мелкие, при этом к коду добавляются символы(если быть точным цифры, а после происходит кодирование в base-32).
Разбиение можно производить до необходимой точности. Такой код уникален для каждой точки.
Подробно алгоритм построения я описывать не буду, о нем можно почитать в википедии. Его идея похожа на арифметическое кодирование. Данный код обратим. Многие технологии уже имеют встроенные методы для работы с гео-хешами, например, MongoDB.
Пример: координаты 57.64911,10.40744 будут закодированы в u4pruydqqvj (11 символов). Если требуется меньшая точность, то и код будет меньше.
Особенность данного кода в том, что ОБЫЧНО близлежащие точки имеют одинаковый префикс. И можно посчитав разницу между гео-хешами определить близость двух точек. Но к сожалению данный алгоритм не точен, это хорошо видно из предыдущих изображений. Ячейки с кодами 7 и 8 находятся дальше друг от друга, чем ячейки 2 и 8.
В качестве примера приведу картинку, где гео-хеш дает неверный результат(geohashdelta — разность между геохешами без base32)
Если точностью в задаче можно пренебречь, то можно создать в таблице поле geohash, добавить по нему индекс и производить поиск за логарифм.
Полный перебор
Можно написать хранимую процедуру
create or replace function gc_dist(_lat1 float8, _lon1 float8, _lat2 float8, _lon2 float8) returns float8 as $$ DECLARE radian CONSTANT float8 := PI()/360; BEGIN return ACOS(SIN($1*radian) * SIN($3*radian) + COS($1*radian) * COS($3*radian) * COS($4*radian-$2*radian)) * 6371; END; $$ LANGUAGE plpgsql;
и использовать её
explain SELECT *, gc_dist(54.838971, 83.106560, lat, lng) AS pdist FROM geozones WHERE applicationid = 3890 ORDER BY pdist ASC LIMIT 10;
Но в итоге будет Seq Scan, что очень не приятно.
Limit (cost=634.72..634.75 rows=10 width=69) -> Sort (cost=634.72..639.72 rows=2001 width=69) Sort Key: (gc_dist(54.838971::double precision, 83.10656::double precision, (lat)::double precision, (lng)::double precision)) -> Seq Scan on geozones (cost=0.00..591.48 rows=2001 width=69)
K-d tree и R tree
Что делать, когда точностью пренебречь не получается? Для этого уже есть специальная структура данных K-d tree. Можно перевести широту и долготу в (x,y,z) построить по ним дерево и производить поиск по дереву в среднем за логарифм.
PostGIS
PostGIS — это расширение, которое значительно расширяет обработку географических объектов в РСУБД PostgreSQL.
Для решения нашей задачи будет использовать трехмерную систему координат SRID 4326(WGS 84). Данная система координат определяет координаты относительно центра масс Земли, погрешность составляет менее 2 см.
Если у вас ubuntu-подобная система, то PostGIS можно установить из пакета(для PostgreSQL 9.1):
sudo apt-get install python-software-properties; sudo apt-add-repository ppa:ubuntugis/ppa; sudo apt-get update; sudo apt-get install postgresql-9.1-postgis;
И подключить необходимые экстеншены:
CREATE EXTENSION postgis; CREATE EXTENSION btree_gist; -- for GIST compound index
С помощью \dx можно посмотреть все установленные экстеншены.
Создадим отношение с индексом по полю location
CREATE TABLE geozones_test ( uid SERIAL PRIMARY KEY, lat DOUBLE PRECISION NOT NULL CHECK(lat > -90 and lat <= 90), lng DOUBLE PRECISION NOT NULL CHECK(lng > -180 and lng <= 180), location GEOMETRY(POINT, 4326) NOT NULL -- PostGIS geom field with SRID 4326 ); CREATE INDEX geozones_test_location_idx ON geozones_test USING GIST(location);
После чего для поиска ближайшей геозоны можно воспользоваться следующим запросом
SELECT *, ST_Distance(location::geography, 'SRID=4326;POINT(83.106560 54.838971)'::geography)/1000 as dist_km FROM geozones_test ORDER BY location <-> 'SRID=4326;POINT(83.106560 54.838971)' limit 10;
Здесь <-> — distance operator. Мы посчитали дистанцию и нашли ближайшие 10 геозон!
СТОП скажите Вы! Ведь данный запрос должен просмотреть все записи в таблице и посчитать расстояние до каждой геозоны O(n).
Давайте посмотрим EXPLAIN ANALYZE запроса
EXPLAIN ANALYZE SELECT *, ST_Distance(location::geography, 'SRID=4326;POINT(83.106560 54.838971)'::geography)/1000 as dist_km FROM geozones_test ORDER BY location <-> 'SRID=4326;POINT(83.106560 54.838971)' limit 10; Limit (cost=0.00..40.36 rows=10 width=227) (actual time=0.236..0.510 rows=10 loops=1) -> Index Scan using geozones_test_location_idx on geozones_test (cost=0.00..43460.37 rows=10768 width=227) (actual time=0.235..0.506 rows=10 loops=1) Order By: (location <-> '0101000020E6100000F4C308E1D1C654406EA5D766636B4B40'::geometry) Total runtime: 0.579 ms
Index Scan! Где же магия?
А она находится в GiST индексе.
PostgreSQL поддерживает 3 типа индексов:
- B-Tree — используются, когда данные могут быть отсортированы вдоль одной оси; например, числа, символы, даты. Данные ГИС не могут быть рациональным способом отсортированы вдоль одной оси (что больше: (0,0) или (0,1) или (1,0)?), а потому для их индексирования B-Tree не помогут. B-Tree работают с операторами <, <=, =, >=, > и др.
- Hash — может работать только с сравнением на равенство. Так же данный индекс не Write-Ahead logging — тоесть из бекапа индекс может и не поднятся.
- Индексы GIN — »перевёрнутые" индексы, которые могут обрабатывать значения, содержащие более одного ключа, например, массивов.
- Индексы GiST (Generalized Search Trees — обобщенные деревья поиска) — представляет собой некую инфраструктуру, в которой могут быть реализованы много различных стратегий индексирования. GiST-индексы разделяют данные на объекты по одну сторону (things to one side), пересекающиеся объекты(things which overlap), объекты внутри(things which are inside) и могут быть использованы для многих типов данных, включая данные ГИС.
GiST-индекс реализованный PostGIS поддерживает distance operator <-> при поиске. Также данный индекс может быть составным!
Данный функционал можно реализовать и без использования PostGIS, воспользовавшись индексом btree-gist, но PostGIS предоставляет удобные методы для перевода широты и долготы в WGS 84.
Ссылки:
[1] Интересные примеры запросов postgresql.ru.net/postgis/ch04_6.html
[2] Восхищение простотой использования boundlessgeo.com/2011/09/indexed-nearest-neighbour-search-in-postgis
[3] Презентация о том, что данный подход можно использовать не только для широты/долготы, но и для улиц и других интересных объектов www.hagander.net/talks/Find%20your%20neighbours.pdf
[4] Презентация разработчиков KNN GIst-index www.sai.msu.su/~megera/postgres/talks/pgcon-2010-1.pdf
P.S.
Postgres version >= 9.1
PostGIS version >= 2.0
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Оцените полезность статьи
62.68%Я узнал много нового220
27.64%Я узнал немного нового97
9.69%Я не узнал ничего нового из этой статьи34
Проголосовал 351 пользователь. Воздержались 49 пользователей.

