В продолжение предыдущей статьи "Ethernet & FC", хотел бы дать конкретные рекомендации по оптимизации Ethernet сети для работы с СХД NetApp FAS. Хотя, полагаю, многие вещи описанные здесь могут быть полезны и для других решений.
Для тех, кто сильно сомневается в «надёжности» Ethernet. Не то чтобы хочу переубедить тотально переходить с FC8G на 10GBE, но хочу убрать некий ареол недоверия и непонимания технологии. Любой технический специалист должен всегда подходить к вопросу рационально и с «холодной головой». В тоже время заявления о том, что «Ethernet теряет фреймы» сложно назвать «не предвзятым подходом» и «не субъективным мышлением». Предлагаю рассмотреть откуда же взялось это устойчивое мнение о ненадёжности Ethernet, чтобы или развенчать все сомнения или их подтвердить имея на то конкретные обоснования.
Итак началось всё с рождения стандарта, когда Ethernet был 10МБит/с который использовал разделяемую среду коаксиального кабеля. При этом передача информации была «полудуплексная», т.е. в один момент время могла осуществляться одним узлом или передача или приём информации. Чем больше узлов сети в одном таком домене, тем больше было коллизий усугубляя ситуацию «полудуплексностью», здесь действительно терялись фреймы. Потом Ethernet шагнул дальше начал использовать витую пару дав задел на будущее, но глупые хабы точно также объединяли все узлы сети в один домен коллизии и ситуация по сути не изменилась. Появились умные устройства, с гордым названием «коммутаторы», они не просто дублировали фреймы с одного своего порта на другой, они залазили внутрь фрейма и запоминали адреса и порты откуда фреймы приходили и передавали их только на порт получателя. И всё было бы хорошо, но коллизии по-прежнему в каком-то виде остались даже в 100МБит/с сетях, не смотря на то что домен коллизии дробился и сводился только к узлу с портом коммутатора, которые в однодуплексном режиме «натыкались» на коллизии когда пытались одновременно отослать друг-другу свой фрейм. То что произошло дальше — появилась «дуплексность» (10BASE-T, IEEE 802.3i), т.е. каждый узел мог одновременно и принимать и передавать фреймы по разным линкам: две пары RX и TX для узала и две для коммутатора. В 1GBE полудуплексного режима больше вообще не существует. Что это значит? Коллизии пропали навсегда… Их больше нет. Осталось две детские болезни Ethernet, тесно связанные друг с другом это то, что коммутаторы при переполнении своего буфера могли «забывать» фреймы, а случалось это как правило из-за «закольцовок» (Ethernet Loop). Эти проблемы решили соответственно: 1) DCB дополнение для протокола Ethernet известное также как Lossless Ethernet — это набор протоколов козволяющих как и в случае FC не терять фреймы. 2) Просто добавили больше памяти в коммутаторы уровня ЦОД. 3) А сеть 10GBE и компания Cisco в частности шагнули дальше и предложили TRILL в своей линейке Nexus коммутаторов для ЦОД. Протокол TRILL и FabricPath, которые просто определяет назначение нового поля hop count в Ethernet фрейме по аналогии с полем time to live в IP пакете для предотвращения закольцовок, а также некоторых других функций «заимствованных» у IP, избавив таким образом Ethernet от последних детских болезней.
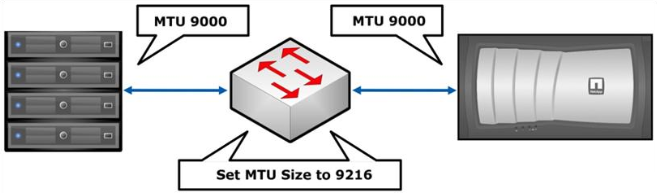
В случае использования протоколов NFS, iSCSI, CIFS рекомендуется по возможности включать jumbo frame, на коммутаторах и хостах. СХД NetApp поддерживает на данный момент размер MTU 9000, что пока что является максимальным значением для Ethernet 10GB. В этом случае jumbo frame должны быть включены на всём пути следования Ethernet фреймов: от источника до получателя. К сожалению не во всех коммутаторах и не на всех сетевых адаптерах хостов поддерживается «максимальный» на данный момент MTU, так к примену некоторые блейд-шасси HP с серверами и встроенными 10GB коммутаторами поддерживают максимум 8000 MTU, для таких случаев на стороне СХД необходимо подбирать наиболее подходящее значение MTU. Так как есть некотарая путаница в том, что такое MTU, есть трудности с пониманием какое значение MTU нужно настроить. Так к примеру для нормальной работы СХД NetApp с установленным значением MTU 9000 на Ethernet интерфейсе будет «нормально» работать со свичами у которы значение MTU установлено в одно из значений: 9000 (Catalyst 2970/2960/3750/3560 Series), 9198 (Catalyst 3850), 9216 (Cisco Nexus 3000/5000/7000/9000, Catalyst 6000/6500 / Cisco 7600 OSR Series), на других это значение вообще должно быть 9252. Как правило, установив MTU на свиче в максимально допустимое значение (выше или равно 9000), всё будет работать. Для разъяснения, рекомендую прочесть соответствующую статью Maximum Transmission Unit (MTU). Мифы и рифы.
Выполняем инастройку из командной строки на каждом Fabric Interconnect:
Настройки flowcontrol должны соответствовать для обоих: портов СХД и подключённых к ним портов свича. Другими словами если flowcontrol на портах СХД установлен в none, то и на свиче flowcontrol должен быть установлен в off и наоборот. Другой пример: если СХД отправляет flowcontrol send, то свитч должен обязательно быть настроен для их приёма (flowcontrol receive on). Не соответствие настроек flowcontrol приводит к разрыву установленных сессий протоколов, к примеру CIFS или iSCSI, связь будет присутствовать, но из-за постоянных разрывов сессий будет работать очень медленно во время увеличения нагрузки на линк, а во время небольших нагрузок проблема проявляться не будет вовсе.
Не путать «Обычный» FlowControl с PFC (IEEE 802.1Qbb) для DCB (Lossless) Eternet.
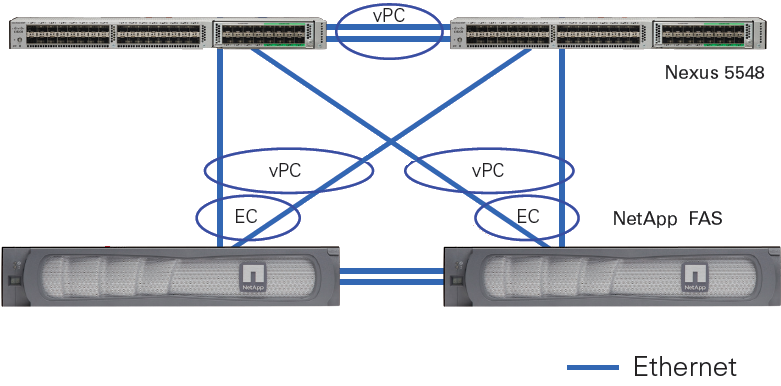
В случае использования NetApp с «классическим Ethernet» (т.е. Ethernet который так сказать «не уровня „Datacenter“) крайне рекомендуется включить RSTP, а Ethernet порты, в которые подключены конечные узлы (СХД и хосты) настроить с включенным режимом portfast, TR-3749. Ethernet сети уровня „Datacenter“ вообще не нуждаются в Spanning Tree, примером такого оборудования могут служить коммутаторы Cisco серии Nexus с технологией vPC.
Учитывая „универсальность“ 10GBE, когда по одной физике могут ходить одновременно FCoE, NFS, CIFS, iSCSI, на ряду с применением таких технологий как vPC и LACP, а также простоту обслуживания Ethernet сетей выгодно отличает протокол и коммутаторы от FC таким образом предоставляя возможность „манёвра“ и сохранения инвестиций в случае изменения бизнес потребностей.
Внутренние тестирования СХД NetApp (у других вендоров СХД эта ситуация может отличаться) FC8G и 10GBE iSCSI, CIFS и NFS показывают практически одинаковую производительность и латенси, характерным для OLTP и виртуализации серверов и десктопов, т.е. для нагрузок с мелкими блоками и случайным чтением записью.
Рекомендую ознакомится со стаьёй описывающей сходства, отличия и перспективы Ethernet & FC.
В случае когда инфраструктура заказчика подразумевает два коммутатора, то можно говорить об одинаковой сложности настройки как SAN так и Ethernet сети. Но у многих заказчиков SAN сеть не сводится к двум SAN коммутаторам где „все видят всех“, на этом как правило, настройка далеко не заканчивается, в этом плане обслуживание Ethernet намного проще. Как правило SAN сети заказчиков это множество коммутаторов с избыточными линками и связями с удалёнными сайтами, что отнюдь не тривиально в обслуживании. И если что-то пойдёт не так, Wireshark'ом трафик не „послушаешь“.
Современные конвергентные коммутаторы, такие как Cisco Nexus 5500 способны коммутировать как трафик Ethernet так и FC позволяя иметь большую гибкость в будущем благодаря решению „два-в-одном“.
Также не забываете о возможности агрегации портов при помощи EtherChannel LACP. Нужно также понимать, что агрегация не объединяет волшебным образом Ethernet порты, а всего лишь распределяет (балансирует) трафик между ними, другими словами два агрегированных 10GBE порта далеко не всегда „дотягивают“ до 20GBE. Здесь стоит отметить, что в зависимости от того, находится ли СХД в отдельной IP подсети от хостов, нужно выбирать правильный метод балансировки. В случае когда СХД находится в отдельной подсети от хостов нельзя выбирать балансировку по MAC (дестинейшина), так как он будет всегда один и тот-же — MAC адрес шлюза. В случае когда хостов меньше, чем количество агрегированных линков на СХД, балансировка работает не оптимальным образом в виду не совершенства и ограничений сетевых алгоритмов балансировки нагрузки. И наоборот: чем больше узлов сети используют агрегированный линк и чем „правильнее“ подобран алгоритм балансировки, тем больше максимальная пропускная способность агрегированного линка приближается к сумме пропускных способностей всех линков. Подробнее про белансировку LACP смотрите в статье „Агрегация каналов и балансирова трафика по IP“.
Документ TR-3749 описывает нюансы настройки VMWare ESXi с СХД NetApp и коммутаторами Cisco.
Уверен, что со временем мне будет что добавить в эту статью по оптимизации сети, спустя время, так что заглядывайте сюда время от времени.
Замечания по ошибкам в тексте и предложения прошу направлять в ЛС.
Ненадёжный Ethernet
Для тех, кто сильно сомневается в «надёжности» Ethernet. Не то чтобы хочу переубедить тотально переходить с FC8G на 10GBE, но хочу убрать некий ареол недоверия и непонимания технологии. Любой технический специалист должен всегда подходить к вопросу рационально и с «холодной головой». В тоже время заявления о том, что «Ethernet теряет фреймы» сложно назвать «не предвзятым подходом» и «не субъективным мышлением». Предлагаю рассмотреть откуда же взялось это устойчивое мнение о ненадёжности Ethernet, чтобы или развенчать все сомнения или их подтвердить имея на то конкретные обоснования.
Итак началось всё с рождения стандарта, когда Ethernet был 10МБит/с который использовал разделяемую среду коаксиального кабеля. При этом передача информации была «полудуплексная», т.е. в один момент время могла осуществляться одним узлом или передача или приём информации. Чем больше узлов сети в одном таком домене, тем больше было коллизий усугубляя ситуацию «полудуплексностью», здесь действительно терялись фреймы. Потом Ethernet шагнул дальше начал использовать витую пару дав задел на будущее, но глупые хабы точно также объединяли все узлы сети в один домен коллизии и ситуация по сути не изменилась. Появились умные устройства, с гордым названием «коммутаторы», они не просто дублировали фреймы с одного своего порта на другой, они залазили внутрь фрейма и запоминали адреса и порты откуда фреймы приходили и передавали их только на порт получателя. И всё было бы хорошо, но коллизии по-прежнему в каком-то виде остались даже в 100МБит/с сетях, не смотря на то что домен коллизии дробился и сводился только к узлу с портом коммутатора, которые в однодуплексном режиме «натыкались» на коллизии когда пытались одновременно отослать друг-другу свой фрейм. То что произошло дальше — появилась «дуплексность» (10BASE-T, IEEE 802.3i), т.е. каждый узел мог одновременно и принимать и передавать фреймы по разным линкам: две пары RX и TX для узала и две для коммутатора. В 1GBE полудуплексного режима больше вообще не существует. Что это значит? Коллизии пропали навсегда… Их больше нет. Осталось две детские болезни Ethernet, тесно связанные друг с другом это то, что коммутаторы при переполнении своего буфера могли «забывать» фреймы, а случалось это как правило из-за «закольцовок» (Ethernet Loop). Эти проблемы решили соответственно: 1) DCB дополнение для протокола Ethernet известное также как Lossless Ethernet — это набор протоколов козволяющих как и в случае FC не терять фреймы. 2) Просто добавили больше памяти в коммутаторы уровня ЦОД. 3) А сеть 10GBE и компания Cisco в частности шагнули дальше и предложили TRILL в своей линейке Nexus коммутаторов для ЦОД. Протокол TRILL и FabricPath, которые просто определяет назначение нового поля hop count в Ethernet фрейме по аналогии с полем time to live в IP пакете для предотвращения закольцовок, а также некоторых других функций «заимствованных» у IP, избавив таким образом Ethernet от последних детских болезней.
Jumbo Frame
В случае использования протоколов NFS, iSCSI, CIFS рекомендуется по возможности включать jumbo frame, на коммутаторах и хостах. СХД NetApp поддерживает на данный момент размер MTU 9000, что пока что является максимальным значением для Ethernet 10GB. В этом случае jumbo frame должны быть включены на всём пути следования Ethernet фреймов: от источника до получателя. К сожалению не во всех коммутаторах и не на всех сетевых адаптерах хостов поддерживается «максимальный» на данный момент MTU, так к примену некоторые блейд-шасси HP с серверами и встроенными 10GB коммутаторами поддерживают максимум 8000 MTU, для таких случаев на стороне СХД необходимо подбирать наиболее подходящее значение MTU. Так как есть некотарая путаница в том, что такое MTU, есть трудности с пониманием какое значение MTU нужно настроить. Так к примеру для нормальной работы СХД NetApp с установленным значением MTU 9000 на Ethernet интерфейсе будет «нормально» работать со свичами у которы значение MTU установлено в одно из значений: 9000 (Catalyst 2970/2960/3750/3560 Series), 9198 (Catalyst 3850), 9216 (Cisco Nexus 3000/5000/7000/9000, Catalyst 6000/6500 / Cisco 7600 OSR Series), на других это значение вообще должно быть 9252. Как правило, установив MTU на свиче в максимально допустимое значение (выше или равно 9000), всё будет работать. Для разъяснения, рекомендую прочесть соответствующую статью Maximum Transmission Unit (MTU). Мифы и рифы.
Jumbo Frames в Cisco UCS
Выполняем инастройку из командной строки на каждом Fabric Interconnect:
system jumbomtu 9216 policy-map type network-qos jumbo class type network-qos class-default mtu 9216 multi-cast-optimize exit system qos service-policy type network-qos jumbo exit copy run start
Либо из GUI интерфейса UCS Manager
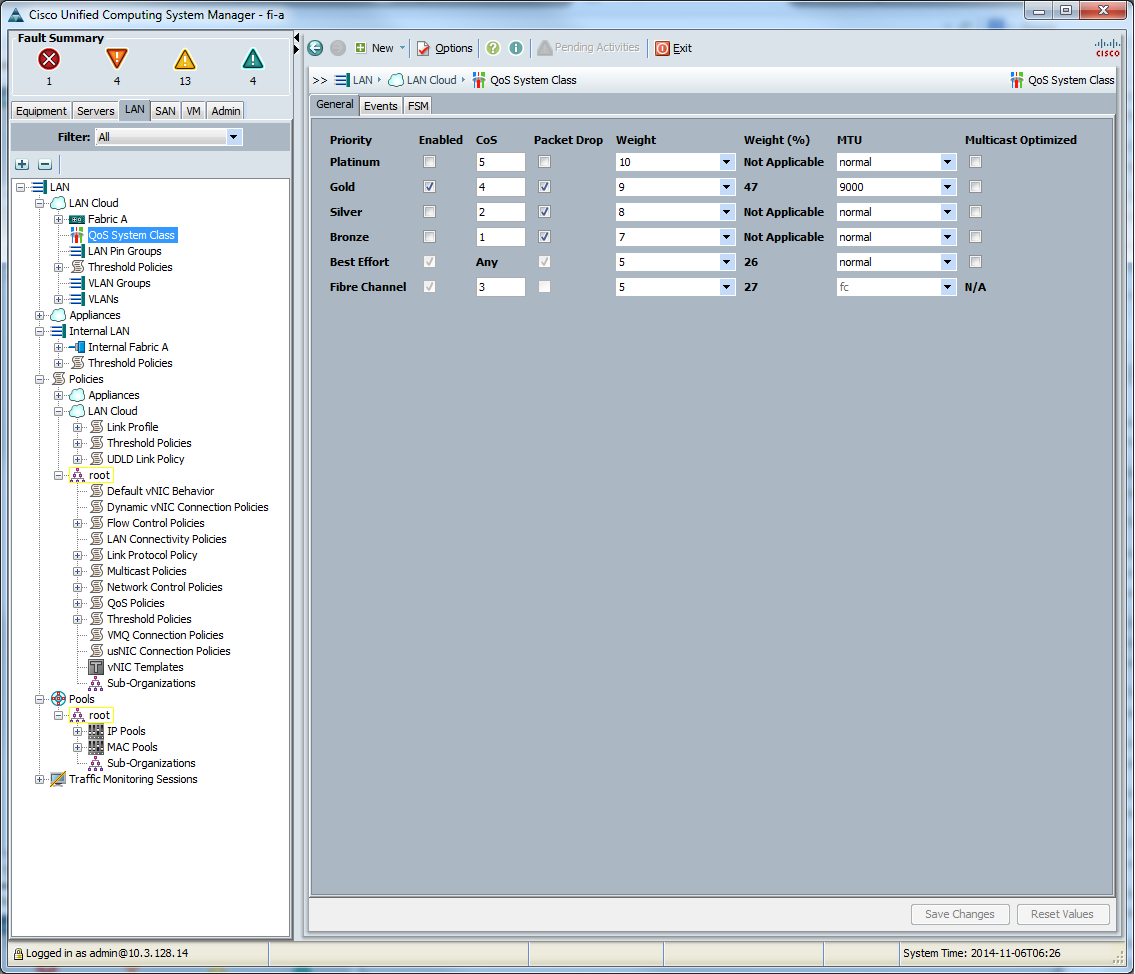
В настройках UCS Manager при работе с Ethernet настраиваем MTU во вкладке «Lan > Lan Cloud > QoS System Class», прописываем MTU одному выбранному классу.
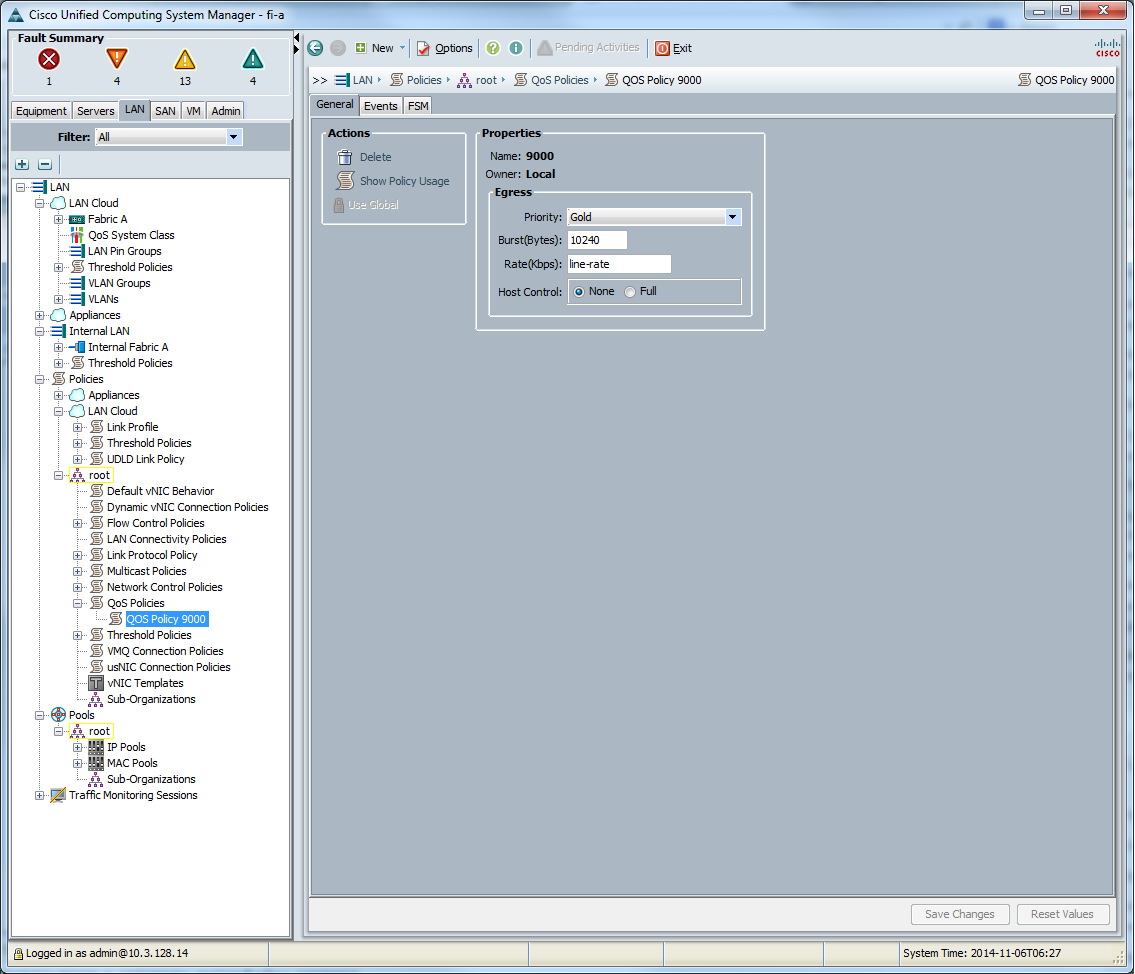
Потом создаём «QoS политику»
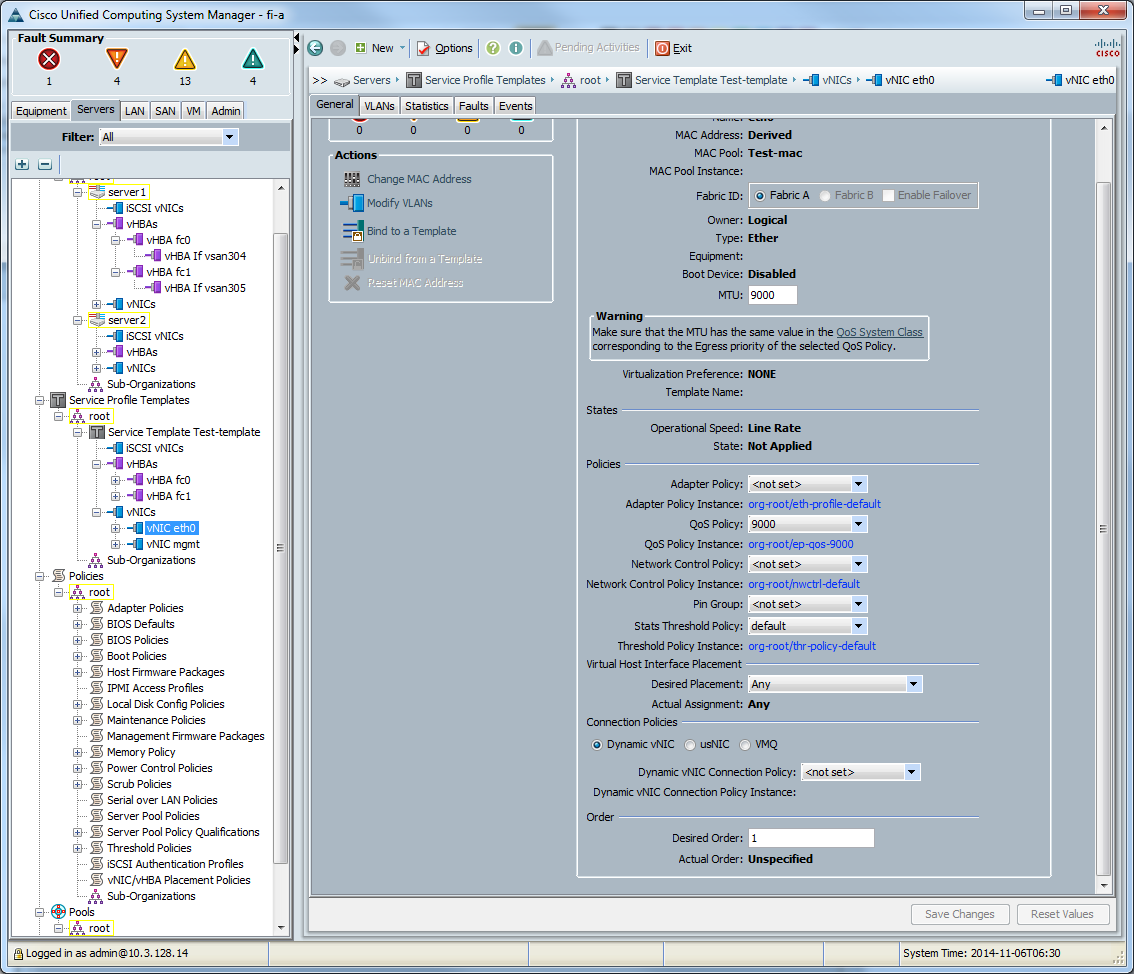
Создаём vNIC template

Привязываем к сетевому интерфейсу сервера.
Потом создаём «QoS политику»
Создаём vNIC template
Привязываем к сетевому интерфейсу сервера.
FlowControl
Настройки flowcontrol должны соответствовать для обоих: портов СХД и подключённых к ним портов свича. Другими словами если flowcontrol на портах СХД установлен в none, то и на свиче flowcontrol должен быть установлен в off и наоборот. Другой пример: если СХД отправляет flowcontrol send, то свитч должен обязательно быть настроен для их приёма (flowcontrol receive on). Не соответствие настроек flowcontrol приводит к разрыву установленных сессий протоколов, к примеру CIFS или iSCSI, связь будет присутствовать, но из-за постоянных разрывов сессий будет работать очень медленно во время увеличения нагрузки на линк, а во время небольших нагрузок проблема проявляться не будет вовсе.
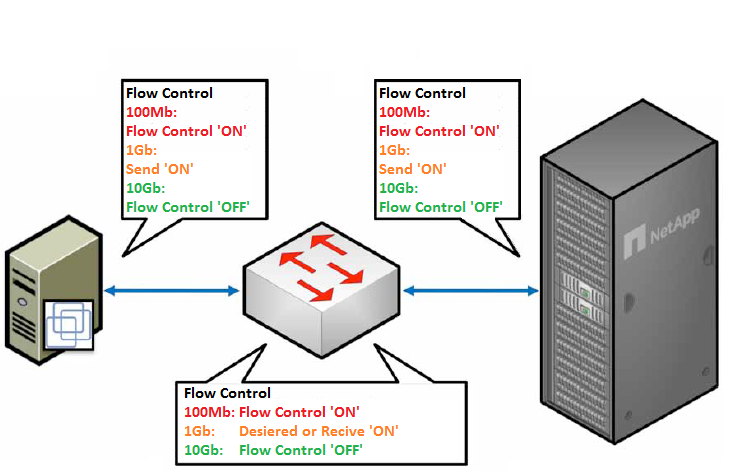
- Общее правило гласит по возможности не включать flowcontrol, TR-3428.
- Для 10GB сетей крайне не рекомендуется включать flowcontrol.
- Для сетей 1GB можно включать flowcontrol (в качестве исключения из правила): хранилище отсылает управление потоком, а свитч принимает — на СХД устанавливать flowcontrol в значение send, а на свитче в значение Desired (или send/tx off & receive/rx on).
- Для 100 MB сетей (в качестве исключения из правила) можно включать flowcontrol на приём и передачу на обоих: хранилище и свитч отсылают и принимают команды управления потоком.
- Тем, кому интересно почему такие рекомендации, вам сюда.
- Дополнительно смотри TR-3802
- Примеры настройки хранилища и свичий можно посмотреть в соответствующих статьях.
Не путать «Обычный» FlowControl с PFC (IEEE 802.1Qbb) для DCB (Lossless) Eternet.
Spanning Tree Protocol
В случае использования NetApp с «классическим Ethernet» (т.е. Ethernet который так сказать «не уровня „Datacenter“) крайне рекомендуется включить RSTP, а Ethernet порты, в которые подключены конечные узлы (СХД и хосты) настроить с включенным режимом portfast, TR-3749. Ethernet сети уровня „Datacenter“ вообще не нуждаются в Spanning Tree, примером такого оборудования могут служить коммутаторы Cisco серии Nexus с технологией vPC.
Converged Network
Учитывая „универсальность“ 10GBE, когда по одной физике могут ходить одновременно FCoE, NFS, CIFS, iSCSI, на ряду с применением таких технологий как vPC и LACP, а также простоту обслуживания Ethernet сетей выгодно отличает протокол и коммутаторы от FC таким образом предоставляя возможность „манёвра“ и сохранения инвестиций в случае изменения бизнес потребностей.
FC8 vs 10GBE: iSCSI, CIFS, NFS
Внутренние тестирования СХД NetApp (у других вендоров СХД эта ситуация может отличаться) FC8G и 10GBE iSCSI, CIFS и NFS показывают практически одинаковую производительность и латенси, характерным для OLTP и виртуализации серверов и десктопов, т.е. для нагрузок с мелкими блоками и случайным чтением записью.
Рекомендую ознакомится со стаьёй описывающей сходства, отличия и перспективы Ethernet & FC.
В случае когда инфраструктура заказчика подразумевает два коммутатора, то можно говорить об одинаковой сложности настройки как SAN так и Ethernet сети. Но у многих заказчиков SAN сеть не сводится к двум SAN коммутаторам где „все видят всех“, на этом как правило, настройка далеко не заканчивается, в этом плане обслуживание Ethernet намного проще. Как правило SAN сети заказчиков это множество коммутаторов с избыточными линками и связями с удалёнными сайтами, что отнюдь не тривиально в обслуживании. И если что-то пойдёт не так, Wireshark'ом трафик не „послушаешь“.
Современные конвергентные коммутаторы, такие как Cisco Nexus 5500 способны коммутировать как трафик Ethernet так и FC позволяя иметь большую гибкость в будущем благодаря решению „два-в-одном“.
LACP
Также не забываете о возможности агрегации портов при помощи EtherChannel LACP. Нужно также понимать, что агрегация не объединяет волшебным образом Ethernet порты, а всего лишь распределяет (балансирует) трафик между ними, другими словами два агрегированных 10GBE порта далеко не всегда „дотягивают“ до 20GBE. Здесь стоит отметить, что в зависимости от того, находится ли СХД в отдельной IP подсети от хостов, нужно выбирать правильный метод балансировки. В случае когда СХД находится в отдельной подсети от хостов нельзя выбирать балансировку по MAC (дестинейшина), так как он будет всегда один и тот-же — MAC адрес шлюза. В случае когда хостов меньше, чем количество агрегированных линков на СХД, балансировка работает не оптимальным образом в виду не совершенства и ограничений сетевых алгоритмов балансировки нагрузки. И наоборот: чем больше узлов сети используют агрегированный линк и чем „правильнее“ подобран алгоритм балансировки, тем больше максимальная пропускная способность агрегированного линка приближается к сумме пропускных способностей всех линков. Подробнее про белансировку LACP смотрите в статье „Агрегация каналов и балансирова трафика по IP“.
Документ TR-3749 описывает нюансы настройки VMWare ESXi с СХД NetApp и коммутаторами Cisco.
Пример настройки LACP
на NetApp 7-Mode
на NetApp Clustered ONTAP
Обратите внимание, portfast (spanning-tree port type edge) должен быть настроен ДО того, как будет подключён NetApp!
На коммутаторе Cisco Catalyst:
На коммутаторе Cisco Nexus 5000:
vif create lacp <vif name> -b ip {Port list}
на NetApp Clustered ONTAP
ifgrp create -node <node name> -ifgrp <vif name> -distr-func {mac | ip | sequential | port} -mode multimode_lacp ifgrp add-port -node <node name> -ifgrp <vif name> -port {Port 1} ifgrp add-port -node <node name> -ifgrp <vif name> -port {Port 2}
Обратите внимание, portfast (spanning-tree port type edge) должен быть настроен ДО того, как будет подключён NetApp!
На коммутаторе Cisco Catalyst:
cat(config)#interface gi0/23 cat(config)#description NetApp e0a Trunk cat(config)#switchport mode trunk cat(config)#switchport trunk allowed vlan 10,20,30 cat(config)#switchport trunk native vlan 123 cat(config)#flowcontrol receive on cat(config)#no cdp enable cat(config)#spanning-tree guard loop cat(config)#!portfast must be configured before netapp connection cat(config)#spanning-tree portfast cat(config)# cat(config)#int port-channel1 cat(config-if)#description LACP multimode VIF for netapp1 cat(config-if)#int gi0/23 cat(config-if)#channel-protocol lacp cat(config-if)#channel-group 1 mode active
На коммутаторе Cisco Nexus 5000:
n5k(config)#interface EthernetX/X/X n5k(config-if)#switchport mode trunk n5k(config-if)#switchport trunk allowed vlan XXX n5k(config-if)#spanning-tree port type edge n5k(config-if)#channel-group XX mode active n5k(config)# n5k(config)#interface port-channelXX n5k(config-if)#switchport mode trunk n5k(config-if)#switchport trunk allowed vlan XX n5k(config-if)#!portfast must be configured before netapp connection n5k(config-if)#spanning-tree port type edge
Уверен, что со временем мне будет что добавить в эту статью по оптимизации сети, спустя время, так что заглядывайте сюда время от времени.
Замечания по ошибкам в тексте и предложения прошу направлять в ЛС.

