В продолжении темы по оптимизации хоста. В предыдущей статье я писал об оптимизации Windows и SAN сети, в этой статье я хотел бы рассмотреть тему оптимизации RedHat/Oracle Linux (с виртуализацией и без) с использованием СХД NetApp FAS в среде SAN.
Для поиска и устранения узких мест в такой инфраструктуре, нужно опредилиться с компонентами инфраструктуры, среди которых их стоит искать. Разделим инфраструктуру на следующие компоненты:

Для поиска узкого места обычно выполняют методику последовательного исключения. Предлагаю перво-наперво начать с СХД. А дальше двигаться СХД -> Сеть (Ethernet / FC) -> Хост ( Windows / Linux / VMware ESXi 5.Х и ESXi 6.X ) -> Приложение. Сейчас остановимся на Хосте.
В случае подключения LUN на прямую к ОС без виртуализации желательно установить NetApp Host Utility. В случае же использования виртуализации с RDM или VMFS, необходимо настроить Multipathing на гипервизоре.
Multipathing должен по-умолчанию использовать предпочтительные пути — пути к LUN через порты контроллера на котором он расположен. Сообщения в консоли СХД FCP Partner Path Misconfigured будут говорить о неправильно настроенном ALUA или MPIO. Это важный параметр, не стоит его игнорировать, так как был один реальный случай, когда взбесившийся драйвер мультипасинга хоста безостановочно переключался между путями создавая таким образом большие очереди в системе ввода-вывода. Подробнее про SAN Booting смотрите соответствующую статью: Red Hat Enterprise Linux / Oracle Enterprise Linux, Cent OS, SUSE Linux Enterprise
Подробнее о рекомендациях зонирования для NetApp в картинках.
В случае использования iSCSI крайне рекомендуется использовать Jumbo Frames в Ethernet со скоростью выше или равно 1Gb. Подробнее в статье про Ethernet с NetApp FAS. Не забудьте что ping нужно запускать на 28 байт меньше при использовании Jumbo Frames в Linux.
Flow Control желательно выключать на всём пути трафика от сервера до СХД с 10Гб линками. Подробнее.
ESXi & MTU9000
Для поиска и устранения узких мест в такой инфраструктуре, нужно опредилиться с компонентами инфраструктуры, среди которых их стоит искать. Разделим инфраструктуру на следующие компоненты:
- Настройки хоста c SAN (FC/FCoE)
- Настройки Ethernet сети на хосте для IP SAN ( iSCSI ).
- Собственно сам хост с ОС
- Приложениями на Хосте
- Проверка совместимости драйверов и версий ПО
Для поиска узкого места обычно выполняют методику последовательного исключения. Предлагаю перво-наперво начать с СХД. А дальше двигаться СХД -> Сеть (Ethernet / FC) -> Хост ( Windows / Linux / VMware ESXi 5.Х и ESXi 6.X ) -> Приложение. Сейчас остановимся на Хосте.
SAN Multipathing
В случае подключения LUN на прямую к ОС без виртуализации желательно установить NetApp Host Utility. В случае же использования виртуализации с RDM или VMFS, необходимо настроить Multipathing на гипервизоре.
Multipathing должен по-умолчанию использовать предпочтительные пути — пути к LUN через порты контроллера на котором он расположен. Сообщения в консоли СХД FCP Partner Path Misconfigured будут говорить о неправильно настроенном ALUA или MPIO. Это важный параметр, не стоит его игнорировать, так как был один реальный случай, когда взбесившийся драйвер мультипасинга хоста безостановочно переключался между путями создавая таким образом большие очереди в системе ввода-вывода. Подробнее про SAN Booting смотрите соответствующую статью: Red Hat Enterprise Linux / Oracle Enterprise Linux, Cent OS, SUSE Linux Enterprise
Подробнее о рекомендациях зонирования для NetApp в картинках.
Ethernet
Jumbo frames
В случае использования iSCSI крайне рекомендуется использовать Jumbo Frames в Ethernet со скоростью выше или равно 1Gb. Подробнее в статье про Ethernet с NetApp FAS. Не забудьте что ping нужно запускать на 28 байт меньше при использовании Jumbo Frames в Linux.
ifconfig eth0 mtu 9000 up echo MTU=9000 >> /etc/sysconfig/network-scripts/ifcfg-eth0 #ping for MTU 9000 ping -M do -s 8972 [destinationIP]
Flow Control
Flow Control желательно выключать на всём пути трафика от сервера до СХД с 10Гб линками. Подробнее.
ethtool -A eth0 autoneg off ethtool -A eth0 rx off ethtool -A eth0 tx off echo ethtool -A eth0 autoneg off >> /etc/sysconfig/network-scripts/ifcfg-eth0 echo ethtool -A eth0 rx off >> /etc/sysconfig/network-scripts/ifcfg-eth0 echo ethtool -A eth0 tx off >> /etc/sysconfig/network-scripts/ifcfg-eth0
ESXi & MTU9000
В случае использования окружения ESXi, не забудьте создать правильный сетевой адаптер — E1000 для 1GB сетей или VMXNET3 если у вас сеть выше чем 1Gb. E1000 и VMXNET3 поддерживают MTU 9000, а стандартный виртуальный сетевой адаптер типа «Flexible» не поддерживает.
Подробнее про оптимизацию VMware с NetApp FAS.
Converged Network
Учитывая «универсальность» 10GBE, когда по одной физике могут ходить одновременно FCoE, NFS, CIFS, iSCSI, на ряду с применением таких технологий как vPC и LACP, а также простоту обслуживания Ethernet сетей выгодно отличает протокол и коммутаторы от FC таким образом предоставляя возможность «манёвра» и сохранения инвестиций в случае изменения бизнес потребностей.
FC8 vs 10GBE: iSCSI, CIFS, NFS
Внутренние тестирования СХД NetApp (у других вендоров СХД эта ситуация может отличаться) FC8G и 10GBE iSCSI, CIFS и NFS показывают практически одинаковую производительность и латенси, характерным для OLTP и виртуализации серверов и десктопов, т.е. для нагрузок с мелкими блоками и случайным чтением записью.
Предлагаю ознакомится со стаьёй описывающей сходства, отличия и перспективы Ethernet & FC.
В случае когда инфраструктура заказчика подразумевает два коммутатора, то можно говорить об одинаковой сложности настройки как SAN так и Ethernet сети. Но у многих заказчиков SAN сеть не сводится к двум SAN коммутаторам где «все видят всех», на этом как правило, настройка далеко не заканчивается, в этом плане обслуживание Ethernet намного проще. Как правило SAN сети заказчиков это множество коммутаторов с избыточными линками и связями с удалёнными сайтами, что отнюдь не тривиально в обслуживании. И если что-то пойдёт не так, Wireshark'ом трафик не «послушаешь».
Современные конвергентные коммутаторы, такие как Cisco Nexus 5500 способны коммутировать как трафик Ethernet так и FC позволяя иметь большую гибкость в будущем благодаря решению «два-в-одном».
Thin Provitioning
В случае использования «файловых» протоколов NFS и CIFS очень просто получать преимущество от использования технологии Thin Provitioning, возвращая высвобожденное пространство внутрь файловой шары. А вот в случае с SAN использование ThinProvitioning приводит к необходимости постоянного контроля над свободным пространством плюс высвобождение свободного пространства (механизм доступен для современных ОС) происходит не «внутрь» того же LUN, а как бы внутрь Volume содержащий этот LUN. Рекомендую ознакомиться с документом NetApp Thin-Provisioned LUNs on RHEL 6.2 Deployment Guide.
Хост ESXi
Отдавать гостевой ОС все ресурсы сервера не стоит, во первых гипервизору нужно оставить минимум 4ГБ ОЗУ, во вторых иногда наблюдается обратный эффект при добавлении ресурсов гостевой ОС, это нужно подбирать эмпирическим путём.
Подробнее о настройках ESXi хоста для NetApp FAS.
Гостевая ОС так и хост BareMetal Linux
Хочу обратить ваше внимание на то, что в большинстве дистрибутивов Linux как в качестве виртуальной машины так и BareMetal параметр I/O scheduling установлен в значение не подходящее для FAS систем, это может приводить к высокой утилизации CPU.
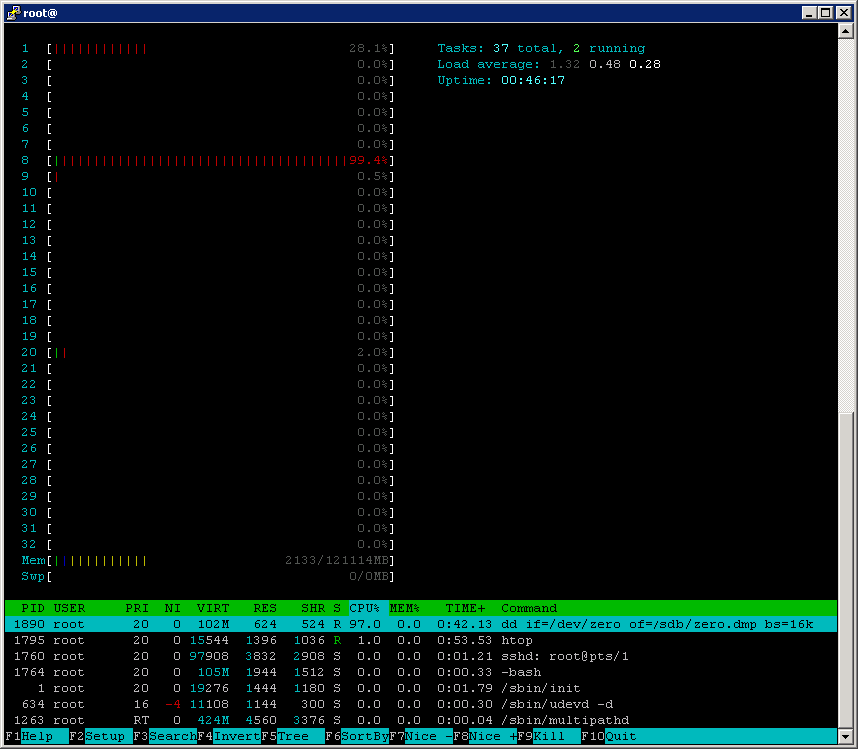
Обратите внимание на вывод команды top, на высокую утилизацию CPU вызванную процессом dd, который в общем-то должен генерировать нагрузку только на систему хранения.
Сбор статистики на хосте
Linux и другие Unix-like:
Теперь посмотрим на состояние дисковой подсистемы на стороне хоста
iostat -dx 2
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sdb 0.00 0.00 0.00 454.00 0.00 464896.00 1024.00 67.42 150.26 2.20 100.00
Обратите внимание на высокое значение await = 150.26 мс. Эти два косвенных признака, высокая утилизация CPU и высокие задержки, могут нам подсказывать, что необходимо более оптимально настроить ОС и СХД для взаимодействия. Проверить стоит, к примеру: адекватность работы мультипасинга, ALUA, предпочтительных путей и очередей на HBA.
Интерпретация iostatПодробнее здесь.
Iostat
Windows, аналог
rrqm/s (The,number of merged read requests queued per second.) read I/O per second
LogicalDisk(*)\Disk Transfers/sec = rrqm/s+wrqm/s., Для,Linux машин добавить колонку rrqm/s, а LogicalDisk(*)\Disk Transfers/sec пропускать
wrqm/s (The number of merged write requests,queued per second.) write I/O per second
LogicalDisk(*)\Disk Transfers/sec = rrqm/s+wrqm/s., Для,Linux машин добавить колонку wrqm/s, а LogicalDisk(*)\Disk Transfers/sec пропускать
r/s (The number of read requests sent to the device per,second.)
Disk,reads/sec
w/s (The number of write requests sent to the device per,second.)
Disk,writes/sec
rsec/s (The number of sectors read per second.) нужно знать размер сектора, обычно,512 байт.
rsec/s*512=,"\LogicalDisk(*)\Disk,Read Bytes/sec",
wsec/s (The number of sectors written per second.) нужно знать размер сектора, обычно,512 байт.
wsec/s*512=,"\LogicalDisk(*)\Disk Write Bytes/sec",
avgrq-sz (The request size in sectors.) нужно знать размер сектора, обычно 512 байт.
avgrq-sz — средний размер оперируемого блока — нужен. Добавить колонку, в Windows он высчитывается из других параметров.
avgqu-sz (The number of,requests waiting in the device’s queue.)
"\LogicalDisk(*)\Avg.,Disk Queue Length". Отдельно по Read и Write получается нет, но этого, достаточно. Соотношение чтение записи будет высчитываться по «rrqm/s» с «wrqm/s» или «r/s» с «w/s»., Т.е., для Linux пропускать:,LogicalDisk(*)\Avg.,Disk Read Queue Length,LogicalDisk(_Total)\Avg.,Disk Write Queue Length.
await (The number of milliseconds required to respond to,requests)
Среднее,Latency, в Windows это значение не выдаёт, высчитывается из других, пареметров, добавить колонку, параметр нужен.
svctm (The number of milliseconds spent servicing,requests, from beginning to end)
Время, выполнения запроса. Добавить отдельную колонку для Linux машин, пригодится
%util (The percentage of CPU time during which requests were,issued)
"\Processor(_total)\%,Processor Time", нагрузка на CPU пускай будет (добавить колонку), из неё косвенно понятно перегруз дисковой подсистемы.
Linux elevator
Теперь про значения для elevator/scheduler:
По-умолчанию оно установлено в значение cfq или deadline:
cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq]
Рекомендуется устанавливать его в значение noop:
echo noop > /sys/block/sda/queue/scheduler
cd /sys/block/sda/queue
grep .* *
scheduler:[noop] deadline cfq
Для того, чтобы настройки были постоянными, добавьте “elevator=noop” в параметры загрузки ядра в файле /etc/grub.conf, они будут применены ко всем блочным устройствам. Или добавьте соответствующий скрипт в /etc/rc.local, для того, чтобы гибко устанавливать настрйки для каждого отдельного блочного устройства.
Пример скрипта установки scheduler в noop для sdbНе забудьте поменять sdb на имя вашего блочного устройства
cat /etc/rc.local | grep -iv "^exit" > /tmp/temp
echo -e "echo noop > /sys/block/sdb/queue/scheduler\nexit 0" >> /tmp/temp
cat /tmp/temp > /etc/rc.local; rm /tmp/temp
Настройки Sysctl с работой Virtual Memory
Стоит опытным путём подобрать наиболее оптимальные значения работы виртуальной памяти ОС — параметры sysctl: vm.dirty_background_ratio, vm.dirty_ratio и vm.swappiness.
Проверяем значения sysctlsysctl -a | grep dirty
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 500
sysctl -a | grep swappiness
vm.swappiness = 60
Так у одного заказчика наиболее оптимальными значениями для RedHat Enterprice Linux 6 с СХД NetApp с SSD кешем и подключением по FC8G были: vm.dirty_ratio = 2 и vm.dirty_background_ratio = 1, которые существенно снизили нагрузку CPU хоста. Для проверки оптимальных настроек Linux хоста воспользуйтесь утилитой Linux Host Validator and Configurator. Во время тестирования утилиты SnapDrive под Linux (или другими Unix-like) ОС воспользуйтесь SnapDrive Configuration Checker for Unix. Подробнее про подбор оптимальных параметров vm.dirty* смотите здесь. В случае использования БД Oracle или виртуализации, внутри такой Linux машины рекомендуется устанавливать значение vm.swappiness=0. Это значение даст использовать swap только когда физическая память действительно закончиться, что является наиболее оптимальным для таких задач.
Устанавливаем значения sysctlsysctl -w vm.dirty_background_ratio=1
sysctl -w vm.dirty_ratio=2
echo vm.dirty_background_ratio=1 >> /etc/sysctl.conf
echo vm.dirty_ratio=2 >> /etc/sysctl.conf
#for Guest VMs or Oracle DB
sysctl -w vm.swappiness=0
echo vm.swappiness=0 >> /etc/sysctl.conf
#Reload data from /etc/sysctl.conf
sudo sysctl –p
I/O queue size или длинна очереди ввода-вывода на HBA
Значение по-умолчанию обычно 128, его нужно подбирать вручную. Увеличение длинны очереди имеет смысл при случайных операциях ввода-вывода, генерирующих множество операций disk seek на дисковой подсистеме. Изменяем так:
echo 100000 > /sys/block/[DEVICE]/queue/nr_requests
Иногда изменение этого параметра может не давать результатов, к примеру в случае с InnoDB (из-за особенностей работы этого приложения, которое само оптимизирует данные перед их записью) или в случае увеличения параметра выше дефолтного при работе с SSD дисками (так как в них нет операций disk seek).
Гостевая ОС
В некоторых случаях VMFS показывает лучшую производительность по сравнению с RDM. Так в некоторых тестах c FC4G можно получить 300 MByte/sec при использовании VMFS и около 200 MByte/sec с RDM.
Файловая система
ФС может вносить существенные коррективы при тестировании производительности.
Размер блока ФС должен быть кратным 4КБ. К примеру, если мы запускаем синтетическую нагрузку подобную генерируемой OLTP, где размер оперируемого блока в среднем равен 8КБ, то ставим 8КБ. Хочу также обратить внимание что как сама ФС, её реализация для конкретной ОС и версия может очень сильно влиять на общую картину производительности. Так для при записи 10 МБ блоками в 100 потоков командой dd файлов от БД на ФС UFS расположенной на LUN отданный по FC4G с СХД FAS 2240 и 21+2 дисками SAS 600 10k в одном агрегате показывал скорость 150 МБ/сек, тогда как та же конфигурация но с ФС ZFS показывала в два раза больше (приближаясь к теоретическому максимуму сетевого канала), а параметр Noatime вообще никак не влиял на ситуацию.
Noatime на Хосте
На уровне файловой системы можно настроить параметр при монтрировании noatime и nodiratime, который не даст обновлять время доступа к файлам, что часто очень положительно сказывается на производительности. Для таких ФС как UFS, EXT3 и др. У одного из заказчиков установка noatime при монтировании файловой системы ext3 на Red Hat Enterprise Linux 6 сильно уменьшило нагрузку на CPU хоста.
Таблица загрузки
Для Linux машин нужно при создании LUN'а выбрать геометрию диска: "linux" (для машин без xen) или "xen" в случае если на этот лун будет установлен Linux LVM с Dom0.
Misalignment
Для любой ОС нужно при создании LUN'а, в настройках СХД, выбрать правильную геометрию. В случае неправильно указанного размера блока ФС, неправильно указанной геометрии LUN, не правильно выбранного на хосте параметра MBR/GPT мы будем наблюдать в пиковые нагрузки сообщения в консоли NetApp FAS, о неком событии "LUN misalignment". Иногда эти сообщения могут появляться ошибочно, в случае редкого их появления просто игнорируйте их. Проверить это можно выполнив на системе хранения команду lun stats.
NetApp Host Utilities
Не игнорируйте этот пункт. Набор утилит устанавливает правильные задержки, размер очереди на HBA и другие настройки на хосте. Устанавливайте Host Utilities после установки драйверов. Отображает подключённые LUN и их детальную информацию со стороны СХД. Набор утилит бесплатный и может быть скачан с сайта техподдержки нетапа. После установки запустите утилиту
host_config <-setup> <-protocol fcp|iscsi|mixed> <-multipath mpxio|dmp|non> [-noalua]
Она находиться
/opt/netapp/santools/
После чего, скорее всего, понадобится перезапустить хост.
NetApp Linux Forum
Не забудьте поискать больше информации и задать свои вопросы на https://linux.netapp.com/forum.
Приложения
В зависимости от конфигурации, протоколов, нагрузок и инфраструктуры ваши приложения могут иметь различные рекомендации настройки и тонкого тюнинга. Для этого обращайтесь за Best Practice Guide для соответствующих приложений для вашей конфигурации. Самыми распространёнными могут быть
- NetApp SnapManager for Oracle & SAN сеть
- Oracle DB on Clustered ONTAP, NetApp for Oracle Database, Best Practices for Oracle Databases on NetApp Storage, SnapManager for Oracle
- Oracle VM
- DB2, DB2 and FlexClone, Deploying an IBM DB2 Multipartition Database
- MySQL
- Infrastructure for Web 2.0/LAMP Applications powered by NetApp and MySQL
- Red Hat Enterprise Linux 6, KVM
- Lotus Domino 8.5 for Linux
- Citrix XenServer
- Deploying Red Hat Enterprise Linux OpenStack Platform 4 on NetApp Clustered Data ONTAP
- и др.
Драйвера
Не забудьте установить драйвера для вашего HBA адаптера (собрав их под ваше ядро), до того, как установите NetApp Host Utility. Следуйте рекомендациям настройки HBA адаптера. Часто необходимо изменить длинну очереди и время таймаута для наиболее оптимального взаимодействия с NetApp. В случае использования виртуализации VMware ESXi или другой, не забудьте включить NPIV в случае необходимости проброса виртуальных HBA адапторов внутрь виртуальных машн. В некоторых адаптерах на базе технологии NPIV может быть настроен QoS, таких как Qlogic HBA серии 8100.
Совместимость
Широко применяйте матрицу совместимости в вашей практике для уменьшения потенциальных проблем в инфрастурктуре ЦОД.
Уверен, что со временем мне будет что добавить в эту статью по оптимизации Linux хоста, так что заглядывайте сюда время от времени.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания и дополнения напротив прошу в комментарии
В случае использования окружения ESXi, не забудьте создать правильный сетевой адаптер — E1000 для 1GB сетей или VMXNET3 если у вас сеть выше чем 1Gb. E1000 и VMXNET3 поддерживают MTU 9000, а стандартный виртуальный сетевой адаптер типа «Flexible» не поддерживает.
Подробнее про оптимизацию VMware с NetApp FAS.
Converged Network
Учитывая «универсальность» 10GBE, когда по одной физике могут ходить одновременно FCoE, NFS, CIFS, iSCSI, на ряду с применением таких технологий как vPC и LACP, а также простоту обслуживания Ethernet сетей выгодно отличает протокол и коммутаторы от FC таким образом предоставляя возможность «манёвра» и сохранения инвестиций в случае изменения бизнес потребностей.
FC8 vs 10GBE: iSCSI, CIFS, NFS
Внутренние тестирования СХД NetApp (у других вендоров СХД эта ситуация может отличаться) FC8G и 10GBE iSCSI, CIFS и NFS показывают практически одинаковую производительность и латенси, характерным для OLTP и виртуализации серверов и десктопов, т.е. для нагрузок с мелкими блоками и случайным чтением записью.
Предлагаю ознакомится со стаьёй описывающей сходства, отличия и перспективы Ethernet & FC.
В случае когда инфраструктура заказчика подразумевает два коммутатора, то можно говорить об одинаковой сложности настройки как SAN так и Ethernet сети. Но у многих заказчиков SAN сеть не сводится к двум SAN коммутаторам где «все видят всех», на этом как правило, настройка далеко не заканчивается, в этом плане обслуживание Ethernet намного проще. Как правило SAN сети заказчиков это множество коммутаторов с избыточными линками и связями с удалёнными сайтами, что отнюдь не тривиально в обслуживании. И если что-то пойдёт не так, Wireshark'ом трафик не «послушаешь».
Современные конвергентные коммутаторы, такие как Cisco Nexus 5500 способны коммутировать как трафик Ethernet так и FC позволяя иметь большую гибкость в будущем благодаря решению «два-в-одном».
Thin Provitioning
В случае использования «файловых» протоколов NFS и CIFS очень просто получать преимущество от использования технологии Thin Provitioning, возвращая высвобожденное пространство внутрь файловой шары. А вот в случае с SAN использование ThinProvitioning приводит к необходимости постоянного контроля над свободным пространством плюс высвобождение свободного пространства (механизм доступен для современных ОС) происходит не «внутрь» того же LUN, а как бы внутрь Volume содержащий этот LUN. Рекомендую ознакомиться с документом NetApp Thin-Provisioned LUNs on RHEL 6.2 Deployment Guide.
Хост ESXi
Отдавать гостевой ОС все ресурсы сервера не стоит, во первых гипервизору нужно оставить минимум 4ГБ ОЗУ, во вторых иногда наблюдается обратный эффект при добавлении ресурсов гостевой ОС, это нужно подбирать эмпирическим путём.
Подробнее о настройках ESXi хоста для NetApp FAS.
Гостевая ОС так и хост BareMetal Linux
Хочу обратить ваше внимание на то, что в большинстве дистрибутивов Linux как в качестве виртуальной машины так и BareMetal параметр I/O scheduling установлен в значение не подходящее для FAS систем, это может приводить к высокой утилизации CPU.
Обратите внимание на вывод команды top, на высокую утилизацию CPU вызванную процессом dd, который в общем-то должен генерировать нагрузку только на систему хранения.
Сбор статистики на хосте
Linux и другие Unix-like:
Теперь посмотрим на состояние дисковой подсистемы на стороне хоста
iostat -dx 2 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sdb 0.00 0.00 0.00 454.00 0.00 464896.00 1024.00 67.42 150.26 2.20 100.00
Обратите внимание на высокое значение await = 150.26 мс. Эти два косвенных признака, высокая утилизация CPU и высокие задержки, могут нам подсказывать, что необходимо более оптимально настроить ОС и СХД для взаимодействия. Проверить стоит, к примеру: адекватность работы мультипасинга, ALUA, предпочтительных путей и очередей на HBA.
Интерпретация iostat
Подробнее здесь.
| Iostat | Windows, аналог |
|---|---|
| rrqm/s (The,number of merged read requests queued per second.) read I/O per second | LogicalDisk(*)\Disk Transfers/sec = rrqm/s+wrqm/s., Для,Linux машин добавить колонку rrqm/s, а LogicalDisk(*)\Disk Transfers/sec пропускать |
| wrqm/s (The number of merged write requests,queued per second.) write I/O per second | LogicalDisk(*)\Disk Transfers/sec = rrqm/s+wrqm/s., Для,Linux машин добавить колонку wrqm/s, а LogicalDisk(*)\Disk Transfers/sec пропускать |
| r/s (The number of read requests sent to the device per,second.) | Disk,reads/sec |
| w/s (The number of write requests sent to the device per,second.) | Disk,writes/sec |
| rsec/s (The number of sectors read per second.) нужно знать размер сектора, обычно,512 байт. | rsec/s*512=,"\LogicalDisk(*)\Disk,Read Bytes/sec", |
| wsec/s (The number of sectors written per second.) нужно знать размер сектора, обычно,512 байт. | wsec/s*512=,"\LogicalDisk(*)\Disk Write Bytes/sec", |
| avgrq-sz (The request size in sectors.) нужно знать размер сектора, обычно 512 байт. | avgrq-sz — средний размер оперируемого блока — нужен. Добавить колонку, в Windows он высчитывается из других параметров. |
| avgqu-sz (The number of,requests waiting in the device’s queue.) | "\LogicalDisk(*)\Avg.,Disk Queue Length". Отдельно по Read и Write получается нет, но этого, достаточно. Соотношение чтение записи будет высчитываться по «rrqm/s» с «wrqm/s» или «r/s» с «w/s»., Т.е., для Linux пропускать:,LogicalDisk(*)\Avg.,Disk Read Queue Length,LogicalDisk(_Total)\Avg.,Disk Write Queue Length. |
| await (The number of milliseconds required to respond to,requests) | Среднее,Latency, в Windows это значение не выдаёт, высчитывается из других, пареметров, добавить колонку, параметр нужен. |
| svctm (The number of milliseconds spent servicing,requests, from beginning to end) | Время, выполнения запроса. Добавить отдельную колонку для Linux машин, пригодится |
| %util (The percentage of CPU time during which requests were,issued) | "\Processor(_total)\%,Processor Time", нагрузка на CPU пускай будет (добавить колонку), из неё косвенно понятно перегруз дисковой подсистемы. |
Linux elevator
Теперь про значения для elevator/scheduler:
По-умолчанию оно установлено в значение cfq или deadline:
cat /sys/block/sda/queue/scheduler noop anticipatory deadline [cfq]
Рекомендуется устанавливать его в значение noop:
echo noop > /sys/block/sda/queue/scheduler cd /sys/block/sda/queue grep .* * scheduler:[noop] deadline cfq
Для того, чтобы настройки были постоянными, добавьте “elevator=noop” в параметры загрузки ядра в файле /etc/grub.conf, они будут применены ко всем блочным устройствам. Или добавьте соответствующий скрипт в /etc/rc.local, для того, чтобы гибко устанавливать настрйки для каждого отдельного блочного устройства.
Пример скрипта установки scheduler в noop для sdb
Не забудьте поменять sdb на имя вашего блочного устройства
cat /etc/rc.local | grep -iv "^exit" > /tmp/temp echo -e "echo noop > /sys/block/sdb/queue/scheduler\nexit 0" >> /tmp/temp cat /tmp/temp > /etc/rc.local; rm /tmp/temp
Настройки Sysctl с работой Virtual Memory
Стоит опытным путём подобрать наиболее оптимальные значения работы виртуальной памяти ОС — параметры sysctl: vm.dirty_background_ratio, vm.dirty_ratio и vm.swappiness.
Проверяем значения sysctl
sysctl -a | grep dirty vm.dirty_background_bytes = 0 vm.dirty_background_ratio = 10 vm.dirty_bytes = 0 vm.dirty_expire_centisecs = 3000 vm.dirty_ratio = 20 vm.dirty_writeback_centisecs = 500 sysctl -a | grep swappiness vm.swappiness = 60
Так у одного заказчика наиболее оптимальными значениями для RedHat Enterprice Linux 6 с СХД NetApp с SSD кешем и подключением по FC8G были: vm.dirty_ratio = 2 и vm.dirty_background_ratio = 1, которые существенно снизили нагрузку CPU хоста. Для проверки оптимальных настроек Linux хоста воспользуйтесь утилитой Linux Host Validator and Configurator. Во время тестирования утилиты SnapDrive под Linux (или другими Unix-like) ОС воспользуйтесь SnapDrive Configuration Checker for Unix. Подробнее про подбор оптимальных параметров vm.dirty* смотите здесь. В случае использования БД Oracle или виртуализации, внутри такой Linux машины рекомендуется устанавливать значение vm.swappiness=0. Это значение даст использовать swap только когда физическая память действительно закончиться, что является наиболее оптимальным для таких задач.
Устанавливаем значения sysctl
sysctl -w vm.dirty_background_ratio=1 sysctl -w vm.dirty_ratio=2 echo vm.dirty_background_ratio=1 >> /etc/sysctl.conf echo vm.dirty_ratio=2 >> /etc/sysctl.conf #for Guest VMs or Oracle DB sysctl -w vm.swappiness=0 echo vm.swappiness=0 >> /etc/sysctl.conf #Reload data from /etc/sysctl.conf sudo sysctl –p
I/O queue size или длинна очереди ввода-вывода на HBA
Значение по-умолчанию обычно 128, его нужно подбирать вручную. Увеличение длинны очереди имеет смысл при случайных операциях ввода-вывода, генерирующих множество операций disk seek на дисковой подсистеме. Изменяем так:
Иногда изменение этого параметра может не давать результатов, к примеру в случае с InnoDB (из-за особенностей работы этого приложения, которое само оптимизирует данные перед их записью) или в случае увеличения параметра выше дефолтного при работе с SSD дисками (так как в них нет операций disk seek).echo 100000 > /sys/block/[DEVICE]/queue/nr_requests
Гостевая ОС
В некоторых случаях VMFS показывает лучшую производительность по сравнению с RDM. Так в некоторых тестах c FC4G можно получить 300 MByte/sec при использовании VMFS и около 200 MByte/sec с RDM.
Файловая система
ФС может вносить существенные коррективы при тестировании производительности.
Размер блока ФС должен быть кратным 4КБ. К примеру, если мы запускаем синтетическую нагрузку подобную генерируемой OLTP, где размер оперируемого блока в среднем равен 8КБ, то ставим 8КБ. Хочу также обратить внимание что как сама ФС, её реализация для конкретной ОС и версия может очень сильно влиять на общую картину производительности. Так для при записи 10 МБ блоками в 100 потоков командой dd файлов от БД на ФС UFS расположенной на LUN отданный по FC4G с СХД FAS 2240 и 21+2 дисками SAS 600 10k в одном агрегате показывал скорость 150 МБ/сек, тогда как та же конфигурация но с ФС ZFS показывала в два раза больше (приближаясь к теоретическому максимуму сетевого канала), а параметр Noatime вообще никак не влиял на ситуацию.
Noatime на Хосте
На уровне файловой системы можно настроить параметр при монтрировании noatime и nodiratime, который не даст обновлять время доступа к файлам, что часто очень положительно сказывается на производительности. Для таких ФС как UFS, EXT3 и др. У одного из заказчиков установка noatime при монтировании файловой системы ext3 на Red Hat Enterprise Linux 6 сильно уменьшило нагрузку на CPU хоста.
Таблица загрузки
Для Linux машин нужно при создании LUN'а выбрать геометрию диска: "linux" (для машин без xen) или "xen" в случае если на этот лун будет установлен Linux LVM с Dom0.
Misalignment
Для любой ОС нужно при создании LUN'а, в настройках СХД, выбрать правильную геометрию. В случае неправильно указанного размера блока ФС, неправильно указанной геометрии LUN, не правильно выбранного на хосте параметра MBR/GPT мы будем наблюдать в пиковые нагрузки сообщения в консоли NetApp FAS, о неком событии "LUN misalignment". Иногда эти сообщения могут появляться ошибочно, в случае редкого их появления просто игнорируйте их. Проверить это можно выполнив на системе хранения команду lun stats.
NetApp Host Utilities
Не игнорируйте этот пункт. Набор утилит устанавливает правильные задержки, размер очереди на HBA и другие настройки на хосте. Устанавливайте Host Utilities после установки драйверов. Отображает подключённые LUN и их детальную информацию со стороны СХД. Набор утилит бесплатный и может быть скачан с сайта техподдержки нетапа. После установки запустите утилиту
host_config <-setup> <-protocol fcp|iscsi|mixed> <-multipath mpxio|dmp|non> [-noalua]
Она находиться
/opt/netapp/santools/
После чего, скорее всего, понадобится перезапустить хост.
NetApp Linux Forum
Не забудьте поискать больше информации и задать свои вопросы на https://linux.netapp.com/forum.
Приложения
В зависимости от конфигурации, протоколов, нагрузок и инфраструктуры ваши приложения могут иметь различные рекомендации настройки и тонкого тюнинга. Для этого обращайтесь за Best Practice Guide для соответствующих приложений для вашей конфигурации. Самыми распространёнными могут быть
- NetApp SnapManager for Oracle & SAN сеть
- Oracle DB on Clustered ONTAP, NetApp for Oracle Database, Best Practices for Oracle Databases on NetApp Storage, SnapManager for Oracle
- Oracle VM
- DB2, DB2 and FlexClone, Deploying an IBM DB2 Multipartition Database
- MySQL
- Infrastructure for Web 2.0/LAMP Applications powered by NetApp and MySQL
- Red Hat Enterprise Linux 6, KVM
- Lotus Domino 8.5 for Linux
- Citrix XenServer
- Deploying Red Hat Enterprise Linux OpenStack Platform 4 on NetApp Clustered Data ONTAP
- и др.
Драйвера
Не забудьте установить драйвера для вашего HBA адаптера (собрав их под ваше ядро), до того, как установите NetApp Host Utility. Следуйте рекомендациям настройки HBA адаптера. Часто необходимо изменить длинну очереди и время таймаута для наиболее оптимального взаимодействия с NetApp. В случае использования виртуализации VMware ESXi или другой, не забудьте включить NPIV в случае необходимости проброса виртуальных HBA адапторов внутрь виртуальных машн. В некоторых адаптерах на базе технологии NPIV может быть настроен QoS, таких как Qlogic HBA серии 8100.
Совместимость
Широко применяйте матрицу совместимости в вашей практике для уменьшения потенциальных проблем в инфрастурктуре ЦОД.
Уверен, что со временем мне будет что добавить в эту статью по оптимизации Linux хоста, так что заглядывайте сюда время от времени.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания и дополнения напротив прошу в комментарии

