
После ответов на 14 вопросов об индексах, которые вы стеснялись задать, у меня возникло гораздо больше комментариев, уточнений и исправлений. Скомпилировать из всего этого статью выглядело затеей с минимумом пользы. И это заставило меня призадумался, а почему вообще мы должны «стесняться задавать» подобные вопросы? Стыдно не знать? А есть ли способ разобраться, не вгоняя себя в краску? Есть. Причем он избавит от многочисленных неточностей, которыми изобилуют многие «ответы». Вы будете чувствовать буквально каждый байт вашей базы кончиками своих пальцев.
Для этого, я предлагаю «поднять капот» у SQL Server и окунуться в сладостный мир шестнадцатеричных дампов. Может статься, что внутри все гораздо проще, чем вам казалось.
Готовим рабочее место
В своих экспериментах я буду использовать бесплатный SQL Server 2014 Express Edition вместе с привычной многим Management Studio. Но почти все полученные знания корнями уходят в SQL Server 7.0, родом из девяностых, и не составит особого труда использовать обретенные навыки на старых инсталляциях.
Для большинства примеров нам понадобится включенный флаг трассировки 3604. Я не буду его тиражировать в каждом из них, но предполагаю, что он всегда включен. Просто помните — если не видно ни дампа, ни ошибок, то добавьте в начало вашего кода:
DBCC TRACEON(3604) GO
Некоторые команды требуют явного указания имени базы данных. В моём случае — это «Lab». Если вы выбрали другой идентификатор, то не забывайте вносить соответствующие изменения. Тоже самое касается и некоторых других значений. Например, физические адреса страниц вполне могут оказаться другими. Я буду стараться напоминать об этом, но старайтесь держать руку на пульсе своего кода.
Ответы сервера часто возвращают очень много полей или иных данных, из которых живой интерес будет представлять лишь малая их толика. Поскольку речь идет не о команде SELECT — регулировать вывод непросто. Поэтому я периодически буду отрезать лишнее, то там, то сям. Не удивляйтесь, если увидите намного больше данных, чем у меня.
Страничная организация
В SQL Server базовой структурой для организации данных является страница размером 8192 байта (8KB или 8KiB, кому как нравится). Её можно адресовать через указание кода файла (FID — File ID), частью которого она является (ниже подсмотрим его в sys.database_files), и кода самой страницы (PID — Page ID) в этом файле. Записывать такой адрес мы будем в виде «FID:PID». Например, 1:142 будет означать страницу с кодом 142 в файле с кодом 1.
SELECT FID = file_id, name, physical_name FROM sys.database_files
FID name physical_name ----------- --------------- ------------------- 1 Lab D:\Lab.mdf 2 Lab_log D:\Lab_log.ldf
Страницы как кластерных, так и обычных индексов, организованы в виде деревьев (B-Tree). Как у всякого дерева, у него есть корень (root node), листья (leaf nodes) и промежуточные узлы (intermediate nodes, но мы их можем назвать ветвями, продолжая растительную аналогию). Чтобы эти элементы было легко отличить друг от друга, не визуализируя, есть понятие уровня индекса (index level). Нулевое значение означает уровень листьев, максимальное — корень дерева. Все, что между ними — ветви.
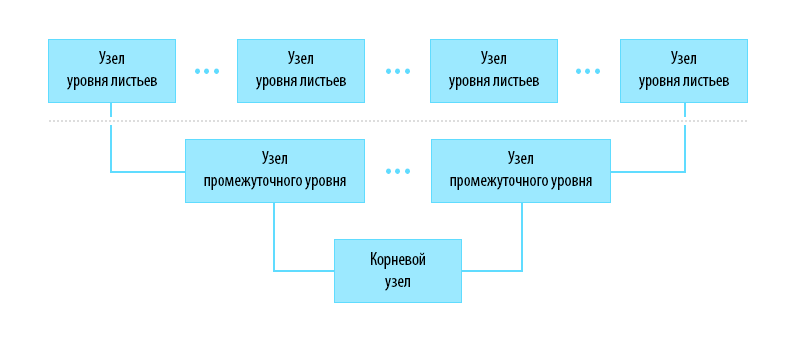
Давайте создадим простую таблицу на 1000 записей с кластерным индексом. Первая колонка будет простым автоинкрементным полем, вторая — такое же значение, но со знаком минус, третья — бинарным значением 0x112233445566778, которым удобно пользоваться как маркером в дампе.
CREATE TABLE [dbo].[ClusteredTable] ( [ID] [int] IDENTITY(1,1) PRIMARY KEY CLUSTERED, [A] AS (-[ID]) PERSISTED NOT NULL, [B] AS (CONVERT([binary](8), 0x1122334455667788)) PERSISTED NOT NULL ) GO INSERT INTO [dbo].[ClusteredTable] DEFAULT VALUES; GO 1000
Теперь воспользуемся недокументированной, но бессмертной командой DBCC IND для проведения страничной аутопсии. Первым аргументом необходимо указать имя или код базы, где находится исследуемая таблица. Вторым — имя этой таблицы (или код соответствующего объекта), третьим — код индекса. Есть еще четвертый опциональный параметр — код партиции. Но он нас в данном контексте не интересует, в отличие от кода индекса, на котором я остановлюсь подробней. Значение 0 говорит о том, что запрашивается уровень Heap. По сути, это уровень данных без каких-либо индексов. За номером 1зарезервирован кластерный индекс (выводится вместе с данными, как в Heap). Во всех остальных случаях вы просто указываете код соответствующего индекса. Давайте посмотрим на кластерный индекс нашей таблицы.
Начиная с версии 2012 появилась DMV-функция sys.dm_db_database_page_allocations. Она в чем-то удобней в использовании, дает более детальную информацию и имеет массу других преимуществ. Все наши примеры можно без труда воспроизвести с ее использованием.
DBCC IND('Lab', 'ClusteredTable', 1) GO
PageFID PagePID IndexID PageType IndexLevel ------- ----------- ----------- -------- ---------- 1 78 1 10 NULL 1 77 1 1 0 1 79 1 2 1 1 80 1 1 0 1 89 1 1 0 1 90 1 1 0
В качестве ответа сервера мы получаем список найденных страниц индекса. Первыми столбцами идут уже знакомые нам FID и PID, которые вместе дают адрес страницы. IndexID своей единицей в очередной раз подтверждает, что мы работаем с кластерным индексом. Тип страницы (PageType) со значением 1 — это данные, 2 — индексы, 10 — IAM (Index Allocation Map), который к индексам имеет опосредованное отношение и мы его проигнорируем. Еще один наш знакомый — уровень индекса (IndexLevel). По его максимальному значению мы видим корень кластерного индекса — страница 1:79. По нулевым значениям — листья 1:77, 1:80, 1:89, 1:90.
Структура страницы
Мысленно мы уже можем себе нарисовать дерево страниц. Но это легко сделать только когда у нас два уровня. А их могли бы быть намного больше. Поэтому без исследования самой страницы не обойтись. Начнем мы с корневой и воспользуемся еще одной недокументированной, но такой же бессмертной командой — DBCC PAGE.
Первым аргументом, также как и DBCC IND, она принимает имя или код базы. Дальше идет пара из FID и PID искомой страницы. Последним значением мы указуем формат вывода из следующих доступных значений:
- 0 — только заголовок;
- 1 — заголовок, дампы и индекс слотов;
- 2 — заголовок и полный дамп;
- 3 — заголовок и максимальная детализация для каждого слота.
Чтобы не объяснять смысл некоторых терминов абстрактно, сразу взглянем на дамп корневой страницы (не забывайте подставлять свои адреса страниц):
DBCC PAGE('Lab', 1, 79, 2) GO
PAGE: (1:79) ... 000000001431A000: 01020001 00800001 00000000 00000b00 00000000 .................... 000000001431A014: 00000400 78000000 6c1f8c00 4f000000 01000000 ....x...l.?.O....... 000000001431A028: 23000000 cc000000 0e000000 00000000 00000000 #...I............... 000000001431A03C: 9dcd3779 01000000 00000000 00000000 00000000 .I7y................ 000000001431A050: 00000000 00000000 00000000 00000000 06000000 .................... 000000001431A064: 074d0000 00010006 44010000 50000000 01000687 .M......D...P......? 000000001431A078: 02000059 00000001 0006ca03 00005a00 00000100 ...Y......E...Z..... 000000001431A08C: 00002121 21212121 21212121 21212121 21212121 ..!!!!!!!!!!!!!!!!!! ... 000000001431BFE0: 21212121 21212121 21212121 21212121 21212121 !!!!!!!!!!!!!!!!!!!! 000000001431BFF4: 21212121 81007600 6b006000 !!!!..v.k.`. OFFSET TABLE: Row - Offset 3 (0x3) - 129 (0x81) 2 (0x2) - 118 (0x76) 1 (0x1) - 107 (0x6b) 0 (0x0) - 96 (0x60)
На данном этапе я хочу показать структуру страницы в целом, поэтому большую часть дампа, которая на это не влияет, я вырезал.
Начинается всё с заголовка длиной в 96 байт, конец которого в выводе выше я отметил разрывом, чтобы удобней читалось. В быту его там нет. За заголовком идут записи с данными, которые называются «slots» (переводить этот термин я не стал). Точнее, они стараются идти после заголовка. Но данные в базе — величина непостоянная. Кортежи добавляются, удаляются, обновляются. Поэтому располагаться они могут не сразу после заголовка, а полностью в хаотичном порядке, с промежутком после заголовка, да и между слотами тоже.
Для того, чтобы контролировать их текущее местоположение, в самом конце страницы располагается индекс этих слотов. Каждый элемент занимает два байта, хранит смещение слота на странице в виде little-endian (то есть, самое последнее значение 0x6000 в нашем дампе мы читаем байт за байтом задом наперед — 0x0060) и нумеруются с конца. Самым последним идет слот 0, перед ним слот 1 и так далее. Индекс слотов и данные как бы движутся навстречу друг другу с разных сторон страницы. Расшифровка их индекса дана в самом дампе после заголовка OFFSET TABLE. Сравните ее с дампом индекса в конце страницы — 81007600 6b006000.

Структура записи
Теперь взглянем на сами слоты в деталях и для этого применим режим 1 вывода для инструкции DBCC PAGE.
DBCC PAGE('Lab', 1, 79, 1) GO
... Slot 0, Offset 0x60, Length 11, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = Record Size = 11 Memory Dump @0x0000000014B1A060 0000000000000000: 06000000 074d0000 000100 .....M..... Slot 1, Offset 0x6b, Length 11, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = Record Size = 11 Memory Dump @0x0000000014B1A06B 0000000000000000: 06440100 00500000 000100 .D...P..... Slot 2, Offset 0x76, Length 11, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = Record Size = 11 Memory Dump @0x0000000014B1A076 0000000000000000: 06870200 00590000 000100 .?...Y..... Slot 3, Offset 0x81, Length 11, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = Record Size = 11 Memory Dump @0x0000000014B1A081 0000000000000000: 06ca0300 005a0000 000100 .E...Z..... ...
Это те же самые четыре слота, которые мы видели раньше, только их двоичное представление вырезано из дампа страницы и подано на блюдечке, что очевидно облегчит нам их дальнейшее исследование.
Первый байт каждого из них (0x06) содержит информацию о типе записи. Точнее, за него отвечают только биты 1-3 (в нашем случае 011b = 3), которые могут принять одно из следующих значений:
- 0 — данные;
- 1/2 — forwarded/forwarding-записи;
- 3 — индекс;
- 4 — бинарные данные (блоб);
- 5/6/7 — ghost-записи для индекса/данных/версий.
Поскольку в наших тестах мы не увидим установленным нулевой бит, то можем смело говорить, что запись описывает индекс, если младшая часть байта равна 0x06.
За первым байтом в нашем случае идет значение ключа, по которому построен кластерный индекс, а за ним — адрес страницы в немного перевернутом формате PID:FID. То есть, для слота 3 значение ключа ID будет 0xca030000 (970 в десятичном виде после переворота little-endian), PID — 0x5a000000 (90), FID — 0x0100 (1). Что можно перевести как: «для поиска записей с ID от 970, отправляйтесь на страницу 1:90». Для слота 2 мы получим ID = 0x87020000 (647), PID = 59000000 (89), FID = 0x0100 (1). А читаем: «для записей с ID от 647 до 970 (которые уже обслуживает слот 3), следуйте на страницу 1:89». И так, все четыре слота отправляют нас на четыре страницы, каждый для своего диапазона значений. Эти четыре страницы мы уже видели в самом начале, когда умозрительно строили дерево по списку страниц. Посмотрите на самый первый вывод команды DBCC IND. Это те же адреса, что и у страниц с данными листового уровня (PageType = 1, IndexLevel = 0).
Будь наша таблица гораздо больше, эти записи ссылались бы на страницы индекса промежуточного уровня (Index Level корня минус один уровень). И ищи мы, скажем, значение ID = 743794, то в корневой странице получили бы слот, который отвечает за доcтаточно широкий диапазон 700000-750000. Он бы нас отправил на похожую страницу, за тем исключением, что там бы мы сузили диапазон поиска до слота 743000-744000. Который, в свою очередь, отправил бы уже на страницу с данными, где хранятся записи 743750-743800.
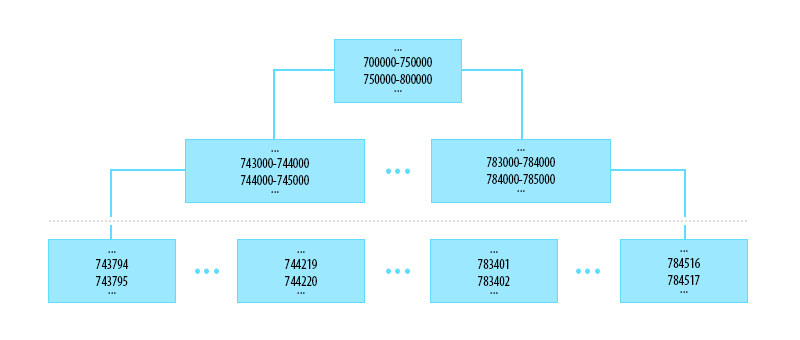
Коль скоро заговорили про данные, то давайте перейдем на страницу 1:89, обслуживающую значения от 657 до 970, которую мы только что обнаружили.
DBCC PAGE('Lab', 1, 89, 1) GO
... Slot 0, Offset 0x60, Length 23, DumpStyle BYTE Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 23 Memory Dump @0x0000000011F1A060 0000000000000000: 10001400 87020000 79fdffff 11223344 55667788 ....?...yyyy."3DUfw. 0000000000000014: 030000 ... Slot 1, Offset 0x77, Length 23, DumpStyle BYTE Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 23 Memory Dump @0x0000000011F1A077 0000000000000000: 10001400 88020000 78fdffff 11223344 55667788 ........xyyy."3DUfw. 0000000000000014: 030000 ... ...
Страница с данными принципиально не отличается от страниц с индексом. Это все тот же самый заголовок и те же самые слоты с их индексом в конце страницы. Для примера я ограничился только парой первых записей, по дампу которых мы последовательно и пройдемся.
- 0x10. Тип записи, с которым вы уже знакомы. Биты 1-3 дают нам значение 0, что говорит о странице с данными. Но еще всплывает установленный бит 4. Он сигнализирует, что у записи есть NULL BITMAP — битовая карта, где за каждым полем исследуемой таблицы закреплен один бит. Если этот бит установлен, то считается, что значение в соответствующем поле — NULL.
- 0x00. Второй байт отвечает за хитрые ghosted-forwarded записи, начиная с SQL Server 2012, и нас сейчас не интересует.
- 0x1400. Все типы можно классифицировать как типы с фиксированной длиной и переменной. Наиболее очевидный пример — binary(n) и varbinary(n). Сразу после этого значения пойдут непосредственно данные с типами фиксированной длины. А само оно указывает, с какого смещения в слоте начнется следующая порция информации. Приведенное значение (а именно, 20 в десятичном виде после разворота из little-endian) = 2 (первых байта с типами) + 2 (этих байта) + 4 (байта на тип int в поле ID) + 4 (байта на такой же тип в поле A) + 8 (байт на бинарное поле B).
- 0x87020000 / 88020000 — это значения 647 и 648, которые есть, ни что иное, как значения поля ID. Помните, раньше мы писали, что слот 2 обслуживает записи, начиная с ID = 647. Это они и есть.
- 0xFFFFFD79 / 0xFFFFFD78 — а это уже значения поля «A» (-647, -648), которое мы рассчитывали по формуле -ID.
- 0x11223344 55667788 — порцию данных логично завершает наш бинарный маркер, который мы определяли для поля B.
- 0x0300 — количество колонок. Как и ожидалось — их три (ID, A, B).
- 0x00 — а это та самая NULL BITMAP, которую я упоминал ранее. Её длина зависит от количества колонок (по биту на каждую) и округляется до ближайшего байта. В нашем случае для хранения трех бит (для трех полей ID, A, B) будет достаточно одного байта. Поскольку значений NULL у нас нет, все биты сброшены.
Обычные индексы
Теперь, давайте создадим в нашей таблице обычный, не кластерный индекс по полю A и посмотрим, чем он будет отличаться от кластерного.
CREATE INDEX [IX_ClusteredTable] ON [dbo].[ClusteredTable] ( [A] ASC ) GO
Посмотрим, какие страницы оказались задействованы и для этого указываем код нового индекса — 2.
DBCC IND('Lab', 'ClusteredTable', 2) GO
PageFID PagePID IndexID PageType IndexLevel ------- ----------- ----------- -------- ---------- 1 94 2 10 NULL 1 93 2 2 0 1 118 2 2 0 1 119 2 2 1
Очень знакомая картина. Есть страницы уровня листьев, которые мы узнаем по IndexLevel = 0. Только теперь у них тип PageType = 2, то есть это индексные страницы, а не страницы с данными. Есть и корневой узел с неизменными IndexLevel = 1, PageType = 2. По его адресу 1:119 мы и продолжим дальнейшее исследование.
DBCC PAGE('Lab', 1, 119, 1) GO
Slot 0, Offset 0x60, Length 15, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = Record Size = 15 Memory Dump @0x000000001095A060 0000000000000000: 0618fcff ffe80300 005d0000 000100 ..uyye...]..... Slot 1, Offset 0x6f, Length 15, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = Record Size = 15 Memory Dump @0x000000001095A06F 0000000000000000: 065afeff ffa60100 00760000 000100 .Z?yy¦...v.....
И опять ничего принципиально нового. Все тот же заголовок, те же слоты. Те ли это два слота, которые ссылаются на две страницы (1:93, 1:118) найденные выше? Разложим по полочкам. Первый байт с типом 0x06 говорит, что это индекс. Последние 6 байт — PID:FID, которые мы уже знаем как разбирать. После трансформации в привычный формат мы получаем точно 1:93 (0x5d000000 0100) и 1:118 (0x7600000000 0100). А вот между ними нас ждет интересный сюрприз. Например, для слота 1 значения 0x5AFEFFFF и 0xA6010000 — это ничто иное, как -422 и 422. То есть, помимо значения поля A, которое мы включили в индекс, он содержит еще и значение кластерного ключа ID.
В остальном схема аналогична наблюдаемой в кластерном индексе. Диапазон от -1000 до -422 обслуживает страница 1:93, от -422 — страница 1:118. За тем только исключением, что кластерный индекс у нас ссылался на страницы с данными, а куда ведет этот? Поехали, посмотрим.
DBCC PAGE('Lab', 1, 118, 1) GO
... m_pageId = (1:118) m_headerVersion = 1 m_type = 2 ... Slot 0, Offset 0x60, Length 12, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 12 Memory Dump @0x000000001331A060 0000000000000000: 165afeff ffa60100 00020000 .Z?yy¦...... Slot 1, Offset 0x6c, Length 12, DumpStyle BYTE Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 12 Memory Dump @0x000000001331A06C 0000000000000000: 165bfeff ffa50100 00020000 .[?yy?...... ...
Я намеренно оставил одну строчку из заголовка, чтобы мы лишний раз убедились, что судьба привела нас на индексную страницу (тип страницы m_type = 2). Все остальное вы наверняка читаете уже шутя. Не должен смутить даже новый тип записи — 0x16, поскольку это 0x10 + 0x06. Первое слагаемое — бит 4 наличия NULL_BITMAP, который мы видели на страницах с данными. Второе — тип индекса.
За ними уверенно следуют значения -422 (0x5AFEFFFF для слота 0) и -421 (0x5BFEFFFF для слота 1) из столбца A. Верим, предыдущий уровень индекса так и сказал, что страница 1:118 работает от -422. После этих значений следуют кластерные ключи (422, 421), которыми нас тоже не удивишь. А дальше — только количество колонок (0x0200) и NULL_BITMAP (0x00), как на страницах с данными. Заметьте, что ссылок на сами страницы с данными нет.
Знали ли вы до этого, что обычный индекс работает через кластерный (при его наличии, разумеется)? И если вы кластеризовали по большому (особенно, натуральному) ключу, то у вас есть риск получить раздутые вторичные индексы? Надеюсь, что нет. Также как и не знали еще многого из этой статьи, поскольку тогда в ней есть толк :)
Мне хочется думать, что теперь, вы отнесетесь с настороженностью к заявлениям с стиле: «Важной характеристикой кластеризованного индекса является то, что все значения отсортированы в определенном порядке либо возрастания, либо убывания» из упомянутой в начале статьи. Зная, что местоположение страниц неизвестно, что упорядоченность на странице определяется индексом слотов, можно с натяжкой говорить только о квази-упорядоченности. А лучше о том, что кластерный индекс… кластеризует. Да, это он делает отлично. Вы точно знаете, на каких страницах находится кластер данных от X до Y.
Хочется надеяться, что теперь вы сможете сами, с удовольствием от проделанной работы, исследовать работу индексов с Heap. Найти ответы на вопросы: «хорош ли GUID для кластерного индекса», «как проходит в таких случаях page split», «как выглядит UNIQUIFIER», «правда ли Heap быстрее для вставки»" и многие другие самостоятельно. Для нужной версии и в требуемых условиях. Возвращаясь, к заголовку статьи, «вам не надо будет их задавать».
До скорых встреч под капотом, надеюсь этот процесс вам пришелся по душе.

