В сети уже есть довольно немало сравнений Entity Framework и NHibernate, но все они по большей части фокусируются на технической стороне вопроса. В этой статье я бы хотел сравнить эти две технологии с точки зрения Domain Driven Design (DDD). Мы рассмотрим несколько примеров кода и увидим как эти две ORM позволяют нам справляться со сложностями.

Сегодня довольно распространенной практикой является использование Onion (слоёной) архитектуры для проектирования сложных систем. Она позволяет изолировать доменную логику от остальных частей системы так, что мы можем сфокусироваться на наиболее важных частях приложения.
Изоляция доменной логики означает, что доменные классы могут взаимодействовать только с другими доменными классами. Это один из наиболее важных принципов, которому необходимо следовать для того, чтобы сделать код чистым и связанным (coherent).
На картинке ниже изображена onion архитектура с использованием классической n-уровневой схемы.
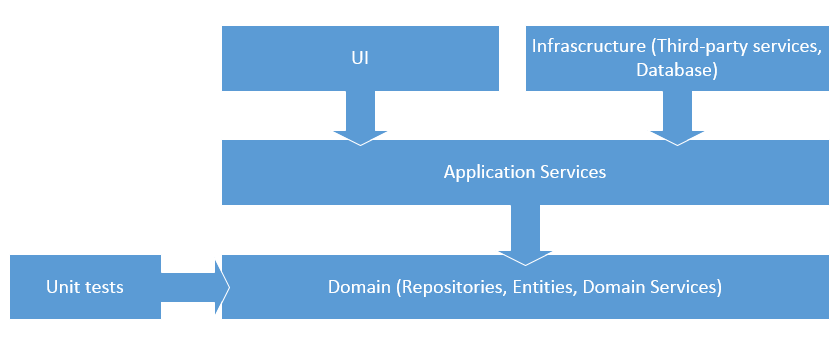
При использовании ORM важно поддерживать хорошую степерь изоляции между доменной логикой и логикой сохранения данных в БД (Persistence Ignorance). Это означает, что код следует структурировать таким образом, чтобы вся логика, относящаяся к сохранению данных в БД, была вынесена из доменных классов. В идеале, доменные сущности не должны содержать никакой информации о том, как они сохраняются в БД. Следование этому правилу позволяет придерживаться принципу единственной обязанности и, таким образом, сохранять код простым и поддерживаемым.
Если вы пишете код, похожий на пример ниже, вы на неверном пути:
Если доменная логика отделена от логики сохранения данных, можно сказать что доменные классы являются persistence ignorant. Это означает, что вы можете менять то, каким образом вы сохраняете данные в БД не затрагивая доменную логику. Persistence ignorance — необходимое условие при изолировании доменной логики.
Давайте рассмотрим примеры кода из реальных проектов.

На рисунке выше изображен агрегат, содержащий два класса. Класс Order является корнем агрегата. Это означает, что Order контролирует время жизни объектов в коллекции Lines. Если Order будет удален, то объекты из этой коллекции будут удалены вместе с ним; OrderLine не может существовать без объекта Order.
Предположим, нам нужно реализовать метод, который удаляет одну из позиций в заказе. Вот как мы можем имплементировать это в случае если наш код не связан с какой-либо ORM:
Вы просто удаляете позицию из коллекции, и на этом все. До тех пор, пока заказ является корнем агрегата, клиенты этого класса могут получить доступ к его позициям только через ссылку на объект Order. Если в нем не будет этой позиции, можно считать что она удалена, т.к. другие объекты не могут сохранять ссылки на дочерние объекты агрегата.
Если вы попробуете выполнить этот код с использованием Entity Framework, вы получите исключение:
The operation failed: The relationship could not be changed because one or more of the foreign-key properties is non-nullable.
В Entity Framework не существует способа задать маппинг таким образом, чтобы удаленные из коллекции (orphaned) позиции автоматически удалялись из базы. Вам необходимо делать это самому:
Передача OrdersContext в метод доменного объекта нарушает принцип разделения ответственности, т.к. класс Order в этом случае содержит информацию о том, как он сохраняется в базе.
Вот как это может быть сделано в NHibernate:
Заметьте, что этот код практически инедтичен коду, который мы бы писали, если бы нам не нужно было сохранять данные в БД. Вы можете указать NHibernate необходимость удалять позиции из БД автоматически после того как они удалены из коллекции:

Предположим, что в один из классов нам необходимо добавить ссылку на связанный класс. Вот пример кода, не завязанный ни на одну ORM:
Вот как это делается в Entity Framework по умолчанию:
Способ по умолчанию в NHibernate:
Как можно видеть, по умолчанию, в Entity Framework нужно добавить дополнительное свойство с идентификатором для того, чтобы связать две сущности. Этот подход нарушает принцип единственной ответственности: идентификаторы являются деталью имплементации того, как данные хранятся в БД; доменные объекты не должны содержать в себе подобную информацию. Entity Framework побуждает вас работать напрямую с терминами баз данных, в том время как в данном случае наилучшим выходом было бы создать единственное свойство Order и отдать остальную работу самой ORM.
Более того, этот код нарушает принцип Don’t repeat yourself. Объявление и OrderId, и Order позволяет классу OrderLine очень легко перейти в неконсистентное состояние:
Необходимо отметить, что EF все же позволяет объявлять ссылки на связанные сущности без указания отдельного свойства-идентификатора, но у этого подхода есть два недостатка:
— Доступ к идентификатору связанного объекта (т.е. orderLine.Order.Id) приводит к загрузке всего объекта из БД, не смотря на то, что этот идентификатор уже содержится в памяти. NHibernate, в свою очередь, достаточно умен и не загружает связанный объект из базы в случае если клиент обращается к его Id.
— Entity Framework побуждает разработчиков использовать идентификаторы. Частично из-за того, что это дефолтный способ для того, чтобы ссылаться на связанные сущности, частично из-за того, что все примеры в документации используют именно этот подход. В NHibernate, напротив, дефолтный способ объявления ссылки на связанную сущность — это ссылка на объект этой сущности.
Если вы хотите коллекцию позиций в заказе коллекцией только для чтения (read-only) для клиентов этого класса, вы можете написать следующий код (версия, не привязанная ни к одной ORM):
Официальных способ сделать это в EF:
Очевидно, это не тот способ, которые вы хотите применять при проектировании доменной модели, т.к. он напрямую смешивает инфраструктурную логику с доменной. Неофициальный способ немногим лучше:
Опять же, класс Order содержит инфраструктурный код. В Entity Framework нет способа, который позволил бы отделить инфраструктурный код от доменного в подобных случаях.
Вот как это можно сделать с NHibernate:
Опять же, код выше практически идентичен коду, который не завязан ни на одну ORM. Класс Order здесь чист и не содержит никакой информации о том, как он хранится в БД, что позволяет нам сфокусироваться на предметной области.
Код, использующий NHibernate, имеет один недостаток. Он подвержен ошибкам при рефакторинге, т.к. название свойства указано в виде строки. Тем не менее, это разумный компромисс, т.к. этот подход позволяет четко отделить логику предметной области от логики сохранения данных в БД. Кроме того, подобные ошибки довольно легко отлавливаются интеграционными тестами.
Ниже код из задачи, над которой я работал пару лет назад. Я опустил детали для кракости, но основная идея должна быть понятна:
Метод принимает некоторые данные, конвертирует их в доменные объекты и сохраняет после этого. Он возвращает список идентификаторов заказчиков. Внешний код может отметить процесс миграции используя CancellationToken, переданный в качестве параметра.
Если вы используете для этой задачи Entity Framework, то он будет вставлять записи в БД по мере сохранения их в сессии для того, чтобы получить Id, т.к. единственная доступная стратегия генерации целочисленных идентификаторов в EF — database identity. Этот подход работает довольно хорошо в большинстве случаев, но он имеет существенный недостаток: он нарушает принцип Unit of Work. Если вызывающий код отменит выполнение метода, EF придется удалить все записи, вставленные в БД к моменту отмены, что приводит к значительныму проседанию производительности.
С NHibernate вы можете выбрать стратегию Hi/Lo, так что записи просто не будут сохраняться в БД до момента закрытия сессии. Идентификаторы в этом случае генерируются на клиенте, так что нет необходимости сохранять записи в БД для того, чтобы получить их. NHibernate может помочь сохранить существенное количество времени в задачах подобного типа.
Предположим, что список ваших клиентов не меняется часто и вы решаете его закешировать, чтобы не обращаться каждый раз к базе для его получения. Допустим также, что класс заказа имеет предусловие, согласно которому каждый заказ должен принадлежать одному из клиентов. Вы можете имплементировать это предусловие используя конструктор:
Таким образом, мы можем быть уверены, что ни один заказ не будет создан без указания его заказчика.
С Entity Framework вы не можете присвоить новому объекту ссылку на detached объект. Если вы напишете код как на примере выше, EF попытается вставить клиента в БД, т.к. он не был приаттачен к текущему контексту. Чтобы исправить это, вам необходимо явно указать, что заказчик уже существует в базе:
Опять же, такой подход нарушает принцип единственной ответственности и устанавливает зависимость между доменной и инфраструктурной логикой. В отличие от EF, NHibernate может определять, является ли объект заказчика новым по его идентификатору и не пытается вставить его в БД если он уже присутствует там. Версия кода, использующего NHibernate, аналогична версии без ORM.
Существует простой способ измерить насколько хорошо ORM позволяет изолировать доменную логику от логики сохранения данных в БД. Чем ближе код, который использует ORM к коду, который не привязан ни к одной ORM, тем лучше эта ORM позвояет разделять ответственности в коде.
EF слишком тесно завязан на базу данных. Когда вы пишете код с Entity Framework, вам постоянно приходится думать в терминах foreign-key constraint-ов и взаимосвязей между таблицами. Без чистой и изолированной доменной модели, ваше внимание постоянно отвлекается, вы не можете сосредоточиться на логике предметной области.
Особенность тут в том, что вы можете не замечать этих отвлечений до тех пор пока ваша система не вырастет до достаточно больших размеров. И когда это случается, становится действительно сложно поддерживать прежний тепм разработки новой функциональности из-за возросших затрат на поддержку текущего кода.
Суммируя все вышесказанное, NHibernate все еще впереди Entity Framework-а. Кроме лучшей степени изоляции доменного кода от инфраструктурной логики, NHibernate имеет довольно много полезных фич, которых нет в Entity Framework: кеш 2-го уровня, стратегии одновременного доступа к данным в БД (concurrency strategies), более гибкие способы маппинга данных и т.д. Пожалуй, единственное чем EF может похвастаться — это неброкирующий I/O при работе с БД (async database operations).
В чем же дело? Entity Framework разрабатывается уже в течение многих лет, не так ли? К сожалению, судя по всему, никто в команде EF не рассматривает ORM с точки зрения DDD. Команда Entity Framework все еще думаю об ORM в терминах данных, а не в терминах модели. Это значит, что, несмотря на то, что Entity Framework — хороший инструмент во многих простых ситуациях, если вы работаете над более сложными проектами, NHibernate будет для вас лучшим выбором.
Как по мне, эта ситуация весьма разочаровывающая. Со всей той поддержкой, которую EF получает от Microsoft и со всем доверием, которое разработчики вкладывают в него из-за того, что это рекомендованная (и дефолтная для многих) ORM, Entity Framework мог быть лучше. Судя по всему, в очередной раз в Microsoft не приняли во внимание опыт сообщества и пошли своим путем.
Program manager команды Entity Framework в Microsoft Rowan Miller ответил, что часть описанных выше проблем будет исправлена в EF7. Несмотря на то, что это только часть, будем надеяться что EF изменится к лучшему в будущем.
Ссылка на оригинал статьи: NHibernate vs Entity Framework
Слоёная архитектура (Onion architecture)
Сегодня довольно распространенной практикой является использование Onion (слоёной) архитектуры для проектирования сложных систем. Она позволяет изолировать доменную логику от остальных частей системы так, что мы можем сфокусироваться на наиболее важных частях приложения.
Изоляция доменной логики означает, что доменные классы могут взаимодействовать только с другими доменными классами. Это один из наиболее важных принципов, которому необходимо следовать для того, чтобы сделать код чистым и связанным (coherent).
На картинке ниже изображена onion архитектура с использованием классической n-уровневой схемы.
Persistence Ignorance
При использовании ORM важно поддерживать хорошую степерь изоляции между доменной логикой и логикой сохранения данных в БД (Persistence Ignorance). Это означает, что код следует структурировать таким образом, чтобы вся логика, относящаяся к сохранению данных в БД, была вынесена из доменных классов. В идеале, доменные сущности не должны содержать никакой информации о том, как они сохраняются в БД. Следование этому правилу позволяет придерживаться принципу единственной обязанности и, таким образом, сохранять код простым и поддерживаемым.
Если вы пишете код, похожий на пример ниже, вы на неверном пути:
public class MyEntity { // Perstisted in the DB public int Id { get; set; } public string Name { get; set; } // Not persisted public bool Flag { get; set; } }
Если доменная логика отделена от логики сохранения данных, можно сказать что доменные классы являются persistence ignorant. Это означает, что вы можете менять то, каким образом вы сохраняете данные в БД не затрагивая доменную логику. Persistence ignorance — необходимое условие при изолировании доменной логики.
Пример 1: Удаление дочерней сущности из корня агрегата
Давайте рассмотрим примеры кода из реальных проектов.
На рисунке выше изображен агрегат, содержащий два класса. Класс Order является корнем агрегата. Это означает, что Order контролирует время жизни объектов в коллекции Lines. Если Order будет удален, то объекты из этой коллекции будут удалены вместе с ним; OrderLine не может существовать без объекта Order.
Предположим, нам нужно реализовать метод, который удаляет одну из позиций в заказе. Вот как мы можем имплементировать это в случае если наш код не связан с какой-либо ORM:
public ICollection<OrderLine> Lines { get; private set; } public void RemoveLine(OrderLine line) { Lines.Remove(line); }
Вы просто удаляете позицию из коллекции, и на этом все. До тех пор, пока заказ является корнем агрегата, клиенты этого класса могут получить доступ к его позициям только через ссылку на объект Order. Если в нем не будет этой позиции, можно считать что она удалена, т.к. другие объекты не могут сохранять ссылки на дочерние объекты агрегата.
Если вы попробуете выполнить этот код с использованием Entity Framework, вы получите исключение:
The operation failed: The relationship could not be changed because one or more of the foreign-key properties is non-nullable.
В Entity Framework не существует способа задать маппинг таким образом, чтобы удаленные из коллекции (orphaned) позиции автоматически удалялись из базы. Вам необходимо делать это самому:
public virtual ICollection<OrderLine> Lines { get; set; } public virtual void RemoveLine(OrderLine line, OrdersContext db) { Lines.Remove(line); db.OrderLines.Remove(line); }
Передача OrdersContext в метод доменного объекта нарушает принцип разделения ответственности, т.к. класс Order в этом случае содержит информацию о том, как он сохраняется в базе.
Вот как это может быть сделано в NHibernate:
public virtual IList<OrderLine> Lines { get; protected set; } public virtual void RemoveLine(OrderLine line) { Lines.Remove(line); }
Заметьте, что этот код практически инедтичен коду, который мы бы писали, если бы нам не нужно было сохранять данные в БД. Вы можете указать NHibernate необходимость удалять позиции из БД автоматически после того как они удалены из коллекции:
public class OrderMap : ClassMap<Order> { public OrderMap() { Id(x => x.Id); HasMany(x => x.Lines).Cascade.AllDeleteOrphan().Inverse(); } }
Пример 2: Ссылка на связанную сущность
Предположим, что в один из классов нам необходимо добавить ссылку на связанный класс. Вот пример кода, не завязанный ни на одну ORM:
public class OrderLine { public Order Order { get; private set; } // Other members }
Вот как это делается в Entity Framework по умолчанию:
public class OrderLine { public virtual Order Order { get; set; } public int OrderId { get; set; } // Other members }
Способ по умолчанию в NHibernate:
public class OrderLine { public virtual Order Order { get; set; } // Other members }
Как можно видеть, по умолчанию, в Entity Framework нужно добавить дополнительное свойство с идентификатором для того, чтобы связать две сущности. Этот подход нарушает принцип единственной ответственности: идентификаторы являются деталью имплементации того, как данные хранятся в БД; доменные объекты не должны содержать в себе подобную информацию. Entity Framework побуждает вас работать напрямую с терминами баз данных, в том время как в данном случае наилучшим выходом было бы создать единственное свойство Order и отдать остальную работу самой ORM.
Более того, этот код нарушает принцип Don’t repeat yourself. Объявление и OrderId, и Order позволяет классу OrderLine очень легко перейти в неконсистентное состояние:
Order = order; // An order with Id == 1 OrderId = 2;
Необходимо отметить, что EF все же позволяет объявлять ссылки на связанные сущности без указания отдельного свойства-идентификатора, но у этого подхода есть два недостатка:
— Доступ к идентификатору связанного объекта (т.е. orderLine.Order.Id) приводит к загрузке всего объекта из БД, не смотря на то, что этот идентификатор уже содержится в памяти. NHibernate, в свою очередь, достаточно умен и не загружает связанный объект из базы в случае если клиент обращается к его Id.
— Entity Framework побуждает разработчиков использовать идентификаторы. Частично из-за того, что это дефолтный способ для того, чтобы ссылаться на связанные сущности, частично из-за того, что все примеры в документации используют именно этот подход. В NHibernate, напротив, дефолтный способ объявления ссылки на связанную сущность — это ссылка на объект этой сущности.
Пример 3: Read-only коллекция связанных сущностей
Если вы хотите коллекцию позиций в заказе коллекцией только для чтения (read-only) для клиентов этого класса, вы можете написать следующий код (версия, не привязанная ни к одной ORM):
private List<OrderLine> _lines; public IReadOnlyList<OrderLine> Lines { get { return _lines.ToList(); } }
Официальных способ сделать это в EF:
public class Order { protected virtual ICollection<OrderLine> LinesInternal { get; set; } public virtual IReadOnlyList<OrderLine> Lines { get { return LinesInternal.ToList(); } } public class OrderConfiguration : EntityTypeConfiguration<Order> { public OrderConfiguration() { HasMany(p => p.LinesInternal).WithRequired(x => x.Order); } } } public class OrdersContext : DbContext { protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Configurations.Add(new Order.OrderConfiguration()); } }
Очевидно, это не тот способ, которые вы хотите применять при проектировании доменной модели, т.к. он напрямую смешивает инфраструктурную логику с доменной. Неофициальный способ немногим лучше:
public class Order { public static Expression<Func<Order, ICollection<OrderLine>>> LinesExpression = f => f.LinesInternal; protected virtual ICollection<OrderLine> LinesInternal { get; set; } public virtual IReadOnlyList<OrderLine> Lines { get { return LinesInternal.ToList(); } } } public class OrdersContext : DbContext { protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<Order>() .HasMany(Order.LinesExpression); } }
Опять же, класс Order содержит инфраструктурный код. В Entity Framework нет способа, который позволил бы отделить инфраструктурный код от доменного в подобных случаях.
Вот как это можно сделать с NHibernate:
public class Order { private IList<OrderLine> _lines; public virtual IReadOnlyList<OrderLine> Lines { get { return _lines.ToList(); } } } public class OrderMap : ClassMap<Order> { public OrderMap() { HasMany<OrderLine>(Reveal.Member<Order>(“Lines”)) .Access.CamelCaseField(Prefix.Underscore); } }
Опять же, код выше практически идентичен коду, который не завязан ни на одну ORM. Класс Order здесь чист и не содержит никакой информации о том, как он хранится в БД, что позволяет нам сфокусироваться на предметной области.
Код, использующий NHibernate, имеет один недостаток. Он подвержен ошибкам при рефакторинге, т.к. название свойства указано в виде строки. Тем не менее, это разумный компромисс, т.к. этот подход позволяет четко отделить логику предметной области от логики сохранения данных в БД. Кроме того, подобные ошибки довольно легко отлавливаются интеграционными тестами.
Пример 4: Паттерн Unit of Work
Ниже код из задачи, над которой я работал пару лет назад. Я опустил детали для кракости, но основная идея должна быть понятна:
public IList<int> MigrateCustomers(IEnumerable<CustomerDto> customerDtos, CancellationToken token) { List<int> ids = new List<int>(); using (ISession session = CreateSession()) using (ITransaction transaction = session.BeginTransaction()) { foreach (CustomerDto dto in customerDtos) { token.ThrowIfCancellationRequested(); Customer customer = CreateCustomer(dto); session.Save(customer); ids.Add(customer.Id); } transaction.Commit(); } return ids; }
Метод принимает некоторые данные, конвертирует их в доменные объекты и сохраняет после этого. Он возвращает список идентификаторов заказчиков. Внешний код может отметить процесс миграции используя CancellationToken, переданный в качестве параметра.
Если вы используете для этой задачи Entity Framework, то он будет вставлять записи в БД по мере сохранения их в сессии для того, чтобы получить Id, т.к. единственная доступная стратегия генерации целочисленных идентификаторов в EF — database identity. Этот подход работает довольно хорошо в большинстве случаев, но он имеет существенный недостаток: он нарушает принцип Unit of Work. Если вызывающий код отменит выполнение метода, EF придется удалить все записи, вставленные в БД к моменту отмены, что приводит к значительныму проседанию производительности.
С NHibernate вы можете выбрать стратегию Hi/Lo, так что записи просто не будут сохраняться в БД до момента закрытия сессии. Идентификаторы в этом случае генерируются на клиенте, так что нет необходимости сохранять записи в БД для того, чтобы получить их. NHibernate может помочь сохранить существенное количество времени в задачах подобного типа.
Пример 5: Работа с закешированными объектами
Предположим, что список ваших клиентов не меняется часто и вы решаете его закешировать, чтобы не обращаться каждый раз к базе для его получения. Допустим также, что класс заказа имеет предусловие, согласно которому каждый заказ должен принадлежать одному из клиентов. Вы можете имплементировать это предусловие используя конструктор:
public Order(Customer customer) { Customer = customer; }
Таким образом, мы можем быть уверены, что ни один заказ не будет создан без указания его заказчика.
С Entity Framework вы не можете присвоить новому объекту ссылку на detached объект. Если вы напишете код как на примере выше, EF попытается вставить клиента в БД, т.к. он не был приаттачен к текущему контексту. Чтобы исправить это, вам необходимо явно указать, что заказчик уже существует в базе:
public Order(Customer customer, OrdersContext context) { context.Entry(customer).State = EntityState.Unchanged; Customer = customer; }
Опять же, такой подход нарушает принцип единственной ответственности и устанавливает зависимость между доменной и инфраструктурной логикой. В отличие от EF, NHibernate может определять, является ли объект заказчика новым по его идентификатору и не пытается вставить его в БД если он уже присутствует там. Версия кода, использующего NHibernate, аналогична версии без ORM.
Результаты
Существует простой способ измерить насколько хорошо ORM позволяет изолировать доменную логику от логики сохранения данных в БД. Чем ближе код, который использует ORM к коду, который не привязан ни к одной ORM, тем лучше эта ORM позвояет разделять ответственности в коде.
EF слишком тесно завязан на базу данных. Когда вы пишете код с Entity Framework, вам постоянно приходится думать в терминах foreign-key constraint-ов и взаимосвязей между таблицами. Без чистой и изолированной доменной модели, ваше внимание постоянно отвлекается, вы не можете сосредоточиться на логике предметной области.
Особенность тут в том, что вы можете не замечать этих отвлечений до тех пор пока ваша система не вырастет до достаточно больших размеров. И когда это случается, становится действительно сложно поддерживать прежний тепм разработки новой функциональности из-за возросших затрат на поддержку текущего кода.
Суммируя все вышесказанное, NHibernate все еще впереди Entity Framework-а. Кроме лучшей степени изоляции доменного кода от инфраструктурной логики, NHibernate имеет довольно много полезных фич, которых нет в Entity Framework: кеш 2-го уровня, стратегии одновременного доступа к данным в БД (concurrency strategies), более гибкие способы маппинга данных и т.д. Пожалуй, единственное чем EF может похвастаться — это неброкирующий I/O при работе с БД (async database operations).
В чем же дело? Entity Framework разрабатывается уже в течение многих лет, не так ли? К сожалению, судя по всему, никто в команде EF не рассматривает ORM с точки зрения DDD. Команда Entity Framework все еще думаю об ORM в терминах данных, а не в терминах модели. Это значит, что, несмотря на то, что Entity Framework — хороший инструмент во многих простых ситуациях, если вы работаете над более сложными проектами, NHibernate будет для вас лучшим выбором.
Как по мне, эта ситуация весьма разочаровывающая. Со всей той поддержкой, которую EF получает от Microsoft и со всем доверием, которое разработчики вкладывают в него из-за того, что это рекомендованная (и дефолтная для многих) ORM, Entity Framework мог быть лучше. Судя по всему, в очередной раз в Microsoft не приняли во внимание опыт сообщества и пошли своим путем.
Апдейт
Program manager команды Entity Framework в Microsoft Rowan Miller ответил, что часть описанных выше проблем будет исправлена в EF7. Несмотря на то, что это только часть, будем надеяться что EF изменится к лучшему в будущем.
Ссылка на оригинал статьи: NHibernate vs Entity Framework

