При разработке отчетов (программ) SAP на языке ABAP для обращения к базе данных используются Open SQL-запросы. Синтаксис очень похож на SQL, но имеются некоторые отличия. Одно из таких отличий – возможность использования конструкции FOR ALL ENTRIES IN. Эта конструкция применяется в SELECT запросах до оператора WHERE. После неё указывается внутренняя таблица с данными, поля которой можно использовать в операторе WHERE в качестве условий выборки.
В этой статье я хочу рассказать о тонкостях работы этой конструкции: что происходит на уровне БД, об оптимизации запросов и о database-hints.
Очень часто программисты при написании кода на ABAP используют эту конструкцию. Она удобна, экономит время при разработке, но не все задумываются над тем, как она работает. И вот однажды, из-за возросшего объемы данных, наступает такой момент, когда написанная программа начинает «тормозить». Чаще всего проблема бывает в запросах к базе данных, и разработчик начинает оптимизировать их: добавляет индексы, убирает запросы из циклов и т.д. Но он практически никогда не обращает внимания на конструкцию FOR ALL ENTRIES IN, так как считает, что оптимизировать в ней нечего.
Давайте на простом примере проанализируем работу этой конструкции. Из таблицы BKPF выберем 1000 строк во внутреннюю таблицу LT_BKPF, а потом из таблицы BSIS выберем данные, используя конструкцию FOR ALL ENTRIES IN LT_BKPF. Аналогичный пример приведен в официальной справке SAP.
Для анализа работы конструкции будем использовать транзакцию ST05 – трассировка SQL-запросов.
В одном режиме запускаем ST05 и включаем трассировку (рис. 1):
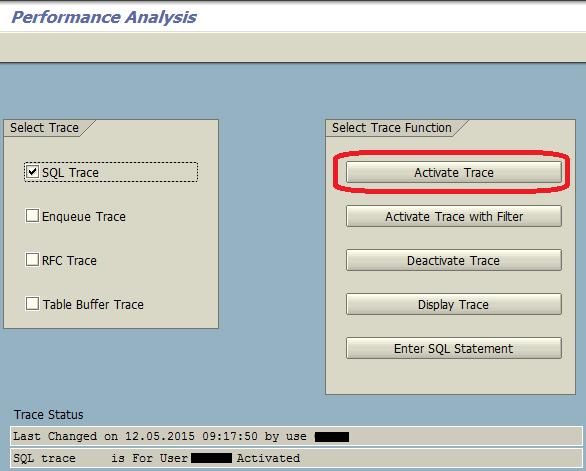
Рис. 1 Запуск трассировки
В другом режиме выполняем нашу программу. После чего в ST05 выключаем трассировку и выводим результат (рис. 2, рис. 3, рис. 4), установив фильтр на таблицы BKPF и BSIS, чтобы отсеять ненужный нам мусор:

Рис. 2 Отключение трассировки
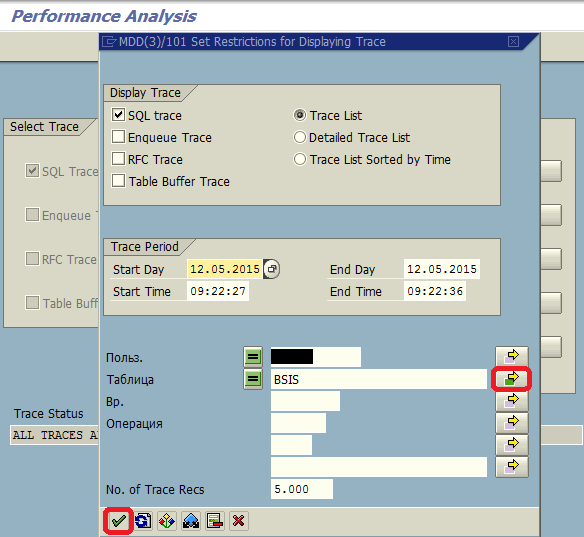
Рис. 3 Вывод результата трассировки
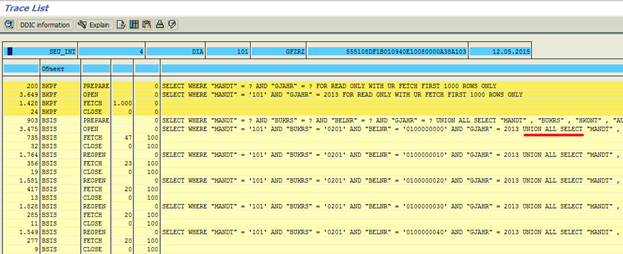
Рис. 4 Результат трассировки
Мы видим, что к таблице BKPF у нас отработал один запрос и вернул 1000 строк – здесь все нормально. А вот к таблице BSIS у нас выполнилось 100 запросов, да еще и каждый из них содержит 10 запросов, объединенных через конструкцию UNION ALL SELECT. Это, по сути, означает, что один Open SQL-запрос с FOR ALL ENTRIES IN превратился во время выполнения в 1000 отдельных запросов к базе данных. Если обобщенно – сколько записей во внутренней таблице FOR ALL ENTRIES IN, столько будет отдельных запросов к базе данных. Понятно, что при большом объеме данных это всё будет очень медленно работать.
Чтобы увеличить быстродействие, нам придется немного усложнить код нашей программы:
Распишу по шагам, что мы сделали:
Посмотрим результат трассировки после такой модификации кода (рис. 5, рис. 6):
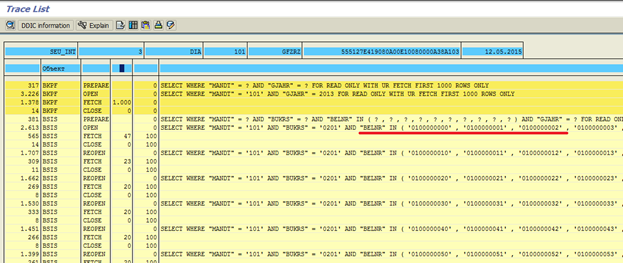
Рис. 5 Результат трассировки после оптимизации кода

Рис. 6 Результат трассировки после оптимизации кода (подробно)
Мы видим, что нам удалось избавиться от UNION ALL SELECT и теперь к таблице BSIS у нас 100 запросов с оператором IN (по 10 значений в запросе) вместо 1000 запросов, объединенных через UNION ALL SELECT.
Когда я оптимизировал подобный запрос, мне достигнутого результата было недостаточно, и я решил разобраться, почему именно по 10 значений передается в оператор IN. Оказалось, что это регулируется глобальным настроечным параметром SAP max_in_blocking_factor и влияет на все запросы, но, используя так называемые database-hints, можно эту настройку поменять для конкретного запроса непосредственно перед выполнением этого запроса. Для этого нужно в самом запросе дописать %_hints db2 '&max_in_blocking_factor 500&' или %_hints oracle '&max_in_blocking_factor 500&' в зависимости от СУБД:
После добавления database-hints имеем следующий результат (рис. 7):
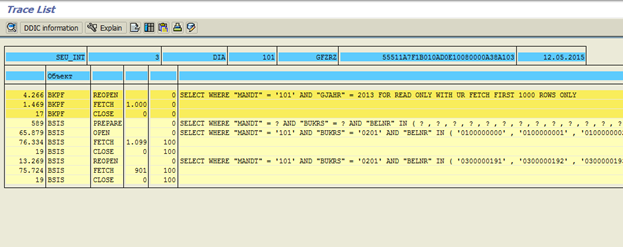
Рис. 7 Результат трассировки после добавления database-hints
Видно, что теперь к таблице BSIS у нас всего 2 запроса с оператором IN (по 500 значений в запросе) вместо 1000 запросов.
Внимание! Настройку max_in_blocking_factor нужно изменять аккуратно: чем выше значение, тем больше требуется оперативной памяти для хранения результата. В каждом частном случае нужен индивидуальный подход, чтобы выбрать золотую середину между производительностью и потреблением ресурсов.
В большинстве случаев много маленьких запросов будут выполняться дольше, чем один большой запрос. Даже на нашем искусственном примере, где выборка осуществляется по индексируемым полям, мы получили почти четырехкратный выигрыш в скорости выполнения. Особый выигрыш в производительности получится, если в выборке (в блоке WHERE) участвуют не входящие в индекс поля. На моей практике встречались отчеты, время работы которых удалось уменьшить с 50 минут до 30 секунд без существенной корректировки кода и добавления новых индексов.
В этой статье я хочу рассказать о тонкостях работы этой конструкции: что происходит на уровне БД, об оптимизации запросов и о database-hints.
Очень часто программисты при написании кода на ABAP используют эту конструкцию. Она удобна, экономит время при разработке, но не все задумываются над тем, как она работает. И вот однажды, из-за возросшего объемы данных, наступает такой момент, когда написанная программа начинает «тормозить». Чаще всего проблема бывает в запросах к базе данных, и разработчик начинает оптимизировать их: добавляет индексы, убирает запросы из циклов и т.д. Но он практически никогда не обращает внимания на конструкцию FOR ALL ENTRIES IN, так как считает, что оптимизировать в ней нечего.
Что происходит на уровне БД
Давайте на простом примере проанализируем работу этой конструкции. Из таблицы BKPF выберем 1000 строк во внутреннюю таблицу LT_BKPF, а потом из таблицы BSIS выберем данные, используя конструкцию FOR ALL ENTRIES IN LT_BKPF. Аналогичный пример приведен в официальной справке SAP.
report z_test. " объявляем переменные " data: begin of ls_bkpf, bukrs type bkpf-bukrs, belnr type bkpf-belnr, end of ls_bkpf. data: lt_bkpf like table of ls_bkpf. data: lt_bsis like table of bsis. " выбираем данные из таблицы bkpf и помещаем их во внутреннюю таблицу lt_bkpf " select bukrs belnr up to 1000 rows from bkpf into corresponding fields of table lt_bkpf where gjahr = '2013'. check lines( lt_bkpf ) > 0. " выбираем данные из таблицы BSIS. В FOR ALL ENTRIES IN передаем внутреннюю таблицу LT_BKPF " select * from bsis into corresponding fields of table lt_bsis for all entries in lt_bkpf where bsis~bukrs = lt_bkpf-bukrs and bsis~belnr = lt_bkpf-belnr and bsis~gjahr = '2013'.
Для анализа работы конструкции будем использовать транзакцию ST05 – трассировка SQL-запросов.
В одном режиме запускаем ST05 и включаем трассировку (рис. 1):
Рис. 1 Запуск трассировки
В другом режиме выполняем нашу программу. После чего в ST05 выключаем трассировку и выводим результат (рис. 2, рис. 3, рис. 4), установив фильтр на таблицы BKPF и BSIS, чтобы отсеять ненужный нам мусор:
Рис. 2 Отключение трассировки
Рис. 3 Вывод результата трассировки
Рис. 4 Результат трассировки
Мы видим, что к таблице BKPF у нас отработал один запрос и вернул 1000 строк – здесь все нормально. А вот к таблице BSIS у нас выполнилось 100 запросов, да еще и каждый из них содержит 10 запросов, объединенных через конструкцию UNION ALL SELECT. Это, по сути, означает, что один Open SQL-запрос с FOR ALL ENTRIES IN превратился во время выполнения в 1000 отдельных запросов к базе данных. Если обобщенно – сколько записей во внутренней таблице FOR ALL ENTRIES IN, столько будет отдельных запросов к базе данных. Понятно, что при большом объеме данных это всё будет очень медленно работать.
Оптимизируем
Чтобы увеличить быстродействие, нам придется немного усложнить код нашей программы:
report z_test. " объявляем переменные " data: begin of ls_bkpf, bukrs type bkpf-bukrs, belnr type bkpf-belnr, end of ls_bkpf. data: lt_bkpf like table of ls_bkpf. data: lt_bkpf_tmp like lt_bkpf. field-symbols: <wa_bkpf> like ls_bkpf. data: lt_bsis like table of bsis. data: begin of ls_bukrs, bukrs type bukrs, end of ls_bukrs. data: lt_bukrs like table of ls_bukrs. " выбираем данные из таблицы BKPF и помещаем их во внутреннюю таблицу LT_BKPF " select bukrs belnr up to 1000 rows from bkpf into corresponding fields of table lt_bkpf where gjahr = '2013'. check lines( lt_bkpf ) > 0. " получаем список уникальных БЕ во внутреннюю таблицу LT_BUKRS " loop at lt_bkpf assigning <wa_bkpf>. ls_bukrs-bukrs = <wa_bkpf>-bukrs. collect ls_bukrs into lt_bukrs. endloop. " для каждой БЕ выполняем запрос " loop at lt_bukrs into ls_bukrs. " выбираем из LT_BKPF документы, относящиеся к определенной БЕ и помещаем в таблицу LT_BKPF_TMP " clear lt_bkpf_tmp. loop at lt_bkpf assigning <wa_bkpf> where bukrs = ls_bukrs-bukrs. append <wa_bkpf> to lt_bkpf_tmp. endloop. " выбираем данные из таблицы BSIS. В FOR ALL ENTRIES IN передаем внутреннюю таблицу LT_BKPF_TMP " select * from bsis appending corresponding fields of table lt_bsis for all entries in lt_bkpf_tmp where bsis~bukrs = ls_bukrs-bukrs and bsis~belnr = lt_bkpf_tmp-belnr and bsis~gjahr = '2013'. endloop.
Распишу по шагам, что мы сделали:
- Проанализировали внутреннюю таблицу LT_BKPF и поняли, что значения в колонке BUKRS, в основном, повторяются.
- Сохранили все уникальные значения колонки BUKRS во внутреннюю таблицу LT_BUKRS.
- Переделали запрос к таблице BSIS:
- для каждого уникального значения BUKRS выполняем отдельный запрос в цикле, предварительно подготовив внутреннюю таблицу LT_BKPF_TMP с номерами документов для конкретной БЕ (BUKRS). Эту таблицу передаем в FOR ALL ENTRIES IN вместо LT_BKPF;
- INTO CORRESPONDING FIELDS заменили на APPENDING CORRESPONDING FIELDS, чтобы на каждом шаге не затирать внутреннюю таблицу LT_BSIS, а добавлять в нее данные;
- в блоке WHERE оставили только одно поле из таблицы LT_BKPF_TMP.
Посмотрим результат трассировки после такой модификации кода (рис. 5, рис. 6):
Рис. 5 Результат трассировки после оптимизации кода
Рис. 6 Результат трассировки после оптимизации кода (подробно)
Мы видим, что нам удалось избавиться от UNION ALL SELECT и теперь к таблице BSIS у нас 100 запросов с оператором IN (по 10 значений в запросе) вместо 1000 запросов, объединенных через UNION ALL SELECT.
Когда я оптимизировал подобный запрос, мне достигнутого результата было недостаточно, и я решил разобраться, почему именно по 10 значений передается в оператор IN. Оказалось, что это регулируется глобальным настроечным параметром SAP max_in_blocking_factor и влияет на все запросы, но, используя так называемые database-hints, можно эту настройку поменять для конкретного запроса непосредственно перед выполнением этого запроса. Для этого нужно в самом запросе дописать %_hints db2 '&max_in_blocking_factor 500&' или %_hints oracle '&max_in_blocking_factor 500&' в зависимости от СУБД:
select * from bsis appending corresponding fields of table lt_bsis for all entries in lt_bkpf_tmp where bsis~bukrs = ls_bukrs-bukrs and bsis~belnr = lt_bkpf_tmp-belnr and bsis~gjahr = '2013' %_hints db2 '&max_in_blocking_factor 500&'.
После добавления database-hints имеем следующий результат (рис. 7):
Рис. 7 Результат трассировки после добавления database-hints
Видно, что теперь к таблице BSIS у нас всего 2 запроса с оператором IN (по 500 значений в запросе) вместо 1000 запросов.
Внимание! Настройку max_in_blocking_factor нужно изменять аккуратно: чем выше значение, тем больше требуется оперативной памяти для хранения результата. В каждом частном случае нужен индивидуальный подход, чтобы выбрать золотую середину между производительностью и потреблением ресурсов.
А стоит ли овчина выделки?
В большинстве случаев много маленьких запросов будут выполняться дольше, чем один большой запрос. Даже на нашем искусственном примере, где выборка осуществляется по индексируемым полям, мы получили почти четырехкратный выигрыш в скорости выполнения. Особый выигрыш в производительности получится, если в выборке (в блоке WHERE) участвуют не входящие в индекс поля. На моей практике встречались отчеты, время работы которых удалось уменьшить с 50 минут до 30 секунд без существенной корректировки кода и добавления новых индексов.
Резюмируем
- При использовании конструкции FOR ALL ENTRIES IN LOCAL_TABLE стремитесь сделать так, чтобы в блоке WHERE использовалось только одно поле из внутренней таблицы LOCAL_TABLE.
- Всегда проверяйте, чтобы таблица LOCAL_TABLE была не пустая, иначе условия с полями этой таблицы будут игнорироваться.
- Используйте database-hints очень аккуратно.
- Оптимизировать запросы таким образом есть смысл, только если какая-либо колонка внутренней таблицы LOCAL_TABLE содержит много повторяющихся значений, иначе нет никакого смысла.
- Преждевременная оптимизация – корень всех зол (с) Дональд Кнут. Оптимизировать нужно только тогда, когда это действительно потребуется, но способы лучше знать заранее.

