Я бы хотел обсудить принцип разделения ответственности (Separation of Concerns, SoC) в контексте ORM, а также посмотреть почему этот принцип так важен. Также мы рассмотрим примеры нарушения границ ответственности между доменной логикой и логикой сохранения данных.
В каждом приложении мы имеем дело с несколькими понятиями (concerns). Как минимум три из них как правило четко определены: UI, бизнес логика и база данных. Принцип разделения ответственности тесно связан с принципом единственной обязанности (Single Responsibility Principle, SRP). Вы можете думать о SoC как о SRP примененном не к единственному классу, а к всему приложению. В большистве случаев эти два принципа могут использоваться взаимозаменяемо.
В случае с ORM принцип SoC относится к разделению логики предметной (доменной) области и логики сохранения данных в БД. Мы можем утверждать, что код приложения имеет хорошую степень разделения ответственностей если доменные классы в нем не знают о том, как они сохраняются в базе данных. Конечно, не всегда возможно достичь полного разделения этих двух областей приложения. Иногда требования производительности таковы, что приходится нарушать эти границы. Но в любом случае, всегда стоит стремиться к настолько полному разграничению ответственностей, насколько возможно.
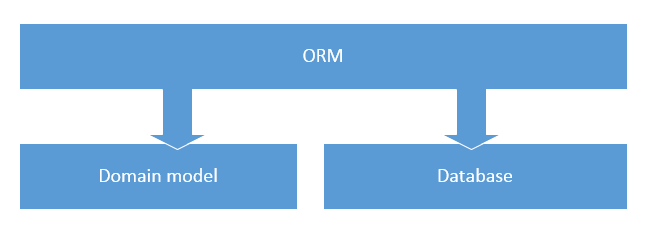
И конечно, мы не можем просто так отделить доменную логику приложения от логики сохранения данных в БД, нам требуется что-то, что соединит их вместе. Именно в этом нам помогают ORM. ORM выступает медиатором между кодом доменной модели и базой данных. В большинстве случаев, ORM способна сделать это таким образом, что ни код предметной области, ни БД не знают о существовании друг друга.
Существует немало информации о том, как поддерживать хорошую степерь разделения ответственностей. Но почему это важно?
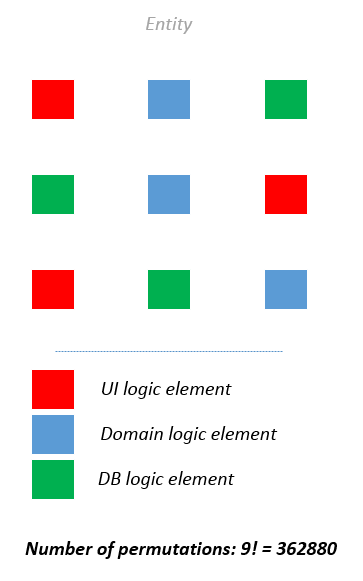
При сохранении различных ответственностей в едином классе, нам приходится коддерживать их консистентность одновременно с каждой операцией в рамках этого класса. Это очень быстро приводит к комбинаторному взрыву. Более того, сложность приложения нарастает гораздо быстрее, чем думают большинство разработчиков. Каждая дополнительная ответственность увеличивает сложность класса на порядок.
Чтобы справиться со всей этой сложностью, нам необходимо разделить эти ответственности:

SoC — это не просто вопрос хорошего или красивого кода. Принцип SoC жизненно важен для поддержания приемлемой скорости разработки. Более того, он важен для успеха вашего проекта.
Человек может удерживать в кратковременной памяти не более девяти объектов одновременно. Приложение без четкого разделения ответственностей очень быстро переполняет кратковременную память разработчика из-за огромного количества комбинаций, в которых различные неразделенные понятия могут взаимодействовать друг с другом.
Разделение этих понятий на высоко связанные части позволяет вам «разделить и властвовать» над разрабатываемым вами приложением. Гораздо проще управлять сложностью небольшого, изолированного компонента, который слабо связан с остальными компонентами приложения.
Давайте рассмотрим примеры, в которых логика сохранения данных проникает в локику предметной области.
Пример 1: Работа с персистентным статусом объекта в классе доменной модели.
Текущее персистентное состояние объекта (т.е. существует ли он уже в БД или нет) не имеет никакого отношения к логике доменной модели. В идеале, доменные объекты должны оперировать только теми данными, которые напрямую относятся к бизнес-логике приложения.
Пример 2: Работа с идентификаторами
Работа с идентификаторами в классах предметной области — пожалуй, наиболее распространенный тип смешения разных видов ответственностей приложения. Идентификаторы — деталь имплементации того, как ваши объекты сохраняются в БД. Как правило они используются для сравнения объектов между собой. Если вы также используете их для этой цели, гораздо лучшим решением будет переопределить операторы сравнения (equality members) в базовом классе доменного объекта и писать ‘customer1 == customer2′ вместо ‘customer1.Id == customer2.Id’.
Пример 3: Разделение свойств доменного класса по персистентному признаку
Если вы имеете тенденцию писать такой код, то вам следует остановиться и обдумать доменную модель. Подобный подход может говорить о том, что вы включили в доменную модель элементы, которые не имеют к ней отношения.
Пример 1: Каскадное удаление
Настройка БД для каскадного удаления — один из примеров проникновения логики предметной области в логику сохранения данных. В идеале, БД сама по себе не должна содержать информации о том, когда должно срабатывать удаление данных. Подобное знание — это забота домена. Ваш C#/Java/etc код должен быть единственным местом для хранения подобной логики.
Пример 2: Хранимые процедуры
Использование хранимых процедур, которые изменяют данные в БД — еще один пример. Не позволяйте доменной логике проникать в базу данных, храните код, изменяющий состояние данных, в вашей доменной модели.
Тут необходимо сделать два замечания. Во-первых, в большинстве случаев, нет ничего плохого в том, чтобы иметь хранимые процедуры, которые не изменяют данные в БД (read-only stored procedures). Помещение кода, приводящего к побочным эффектам (side effects), в доменную модель и кода без побочных эффектов в хранимые процедуры прекрасно соотносится с принципом CQRS.
Во-вторых, существуют случаи, когда избежать использования SQL не получится. К примеру, если вам необходимо удалить группу объектов по какому-то признаку, SQL оператор DELETE сделает эту работу намного быстрее. В таких случаях, использование SQL, изменяющего данные в БД, оправданно, но необходимо держать все подобные исключения под строгим контролем и не давать им разрастаться.
Пример 3: Значения по умолчанию
Значения по умолчанию в таблицах БД — другой пример доменной логики, проникнувшей в базу данных. Значения свойств, которые доменная сущность имеет по умолчанию, должны быть определены в коде, а не отданы на откуп БД.
Подумайте, насколько сложно собирать подобные знания по кусочкам из разных мест приложения. Намного проще хранить их в едином месте.
Большинство подобных «протечек» возникает из-за того, что люди думают о своем приложении не в терминах предметной области, а в терминах данных. Многие разработчики рассматривают разрабатываемую ими систему именно так. Для них, классы — это всего лишь хранилище для данных, которые они переносят от БД к UI, а ORM — всего лишь утилита, помогающая не копировать вручную данные из результатов выполнения SQL запросов в эти объекты. Очень часто бывает сложно сделать сдвиг в парадигме мышления. Но после того как он сделан, люди как правило открывают целый мир выразительных доменных моделей, которые позволяют разрабатывать приложения намного быстрее, особенно на больших проектах.
Конечно, не всегда возможно достичь желаемого уровня разделения ответственностей в коде приложения. Но в большинстве случаев ничто не мешает сделать это. Большинство проектов проваливаются не из-за того, что они оказываются не способны выполнить какое-либо из технических требований. Большинство терпят неудачу из-за того, что оказываются погребены под массой беспорядочного кода, который мешает разработчикам менять что-либо в нем. Каждое изменение в подобном коде приводит к каскаду багов и неожиданных побочных эффектов по всему приложению.
SoC — принцип, который позволяет избежать подобного исхода.
Ссылка на оригинал статьи: Separation of Concerns in ORM
Принцип разделения ответственности
В каждом приложении мы имеем дело с несколькими понятиями (concerns). Как минимум три из них как правило четко определены: UI, бизнес логика и база данных. Принцип разделения ответственности тесно связан с принципом единственной обязанности (Single Responsibility Principle, SRP). Вы можете думать о SoC как о SRP примененном не к единственному классу, а к всему приложению. В большистве случаев эти два принципа могут использоваться взаимозаменяемо.
В случае с ORM принцип SoC относится к разделению логики предметной (доменной) области и логики сохранения данных в БД. Мы можем утверждать, что код приложения имеет хорошую степень разделения ответственностей если доменные классы в нем не знают о том, как они сохраняются в базе данных. Конечно, не всегда возможно достичь полного разделения этих двух областей приложения. Иногда требования производительности таковы, что приходится нарушать эти границы. Но в любом случае, всегда стоит стремиться к настолько полному разграничению ответственностей, насколько возможно.
И конечно, мы не можем просто так отделить доменную логику приложения от логики сохранения данных в БД, нам требуется что-то, что соединит их вместе. Именно в этом нам помогают ORM. ORM выступает медиатором между кодом доменной модели и базой данных. В большинстве случаев, ORM способна сделать это таким образом, что ни код предметной области, ни БД не знают о существовании друг друга.
Почему SoC важен?
Существует немало информации о том, как поддерживать хорошую степерь разделения ответственностей. Но почему это важно?
При сохранении различных ответственностей в едином классе, нам приходится коддерживать их консистентность одновременно с каждой операцией в рамках этого класса. Это очень быстро приводит к комбинаторному взрыву. Более того, сложность приложения нарастает гораздо быстрее, чем думают большинство разработчиков. Каждая дополнительная ответственность увеличивает сложность класса на порядок.
Чтобы справиться со всей этой сложностью, нам необходимо разделить эти ответственности:
SoC — это не просто вопрос хорошего или красивого кода. Принцип SoC жизненно важен для поддержания приемлемой скорости разработки. Более того, он важен для успеха вашего проекта.
Человек может удерживать в кратковременной памяти не более девяти объектов одновременно. Приложение без четкого разделения ответственностей очень быстро переполняет кратковременную память разработчика из-за огромного количества комбинаций, в которых различные неразделенные понятия могут взаимодействовать друг с другом.
Разделение этих понятий на высоко связанные части позволяет вам «разделить и властвовать» над разрабатываемым вами приложением. Гораздо проще управлять сложностью небольшого, изолированного компонента, который слабо связан с остальными компонентами приложения.
Когда логика сохранения данных в БД проникает в доменную логику
Давайте рассмотрим примеры, в которых логика сохранения данных проникает в локику предметной области.
Пример 1: Работа с персистентным статусом объекта в классе доменной модели.
public void DoWork(Customer customer, MyContext context) { if (context.Entry(customer).State == EntityState.Modified) { // Do something } }
Текущее персистентное состояние объекта (т.е. существует ли он уже в БД или нет) не имеет никакого отношения к логике доменной модели. В идеале, доменные объекты должны оперировать только теми данными, которые напрямую относятся к бизнес-логике приложения.
Пример 2: Работа с идентификаторами
public void DoWork(Customer customer1, Customer customer2) { if (customer1.Id > 0) { // Do something } if (customer1.Id == customer2.Id) { // Do something } }
Работа с идентификаторами в классах предметной области — пожалуй, наиболее распространенный тип смешения разных видов ответственностей приложения. Идентификаторы — деталь имплементации того, как ваши объекты сохраняются в БД. Как правило они используются для сравнения объектов между собой. Если вы также используете их для этой цели, гораздо лучшим решением будет переопределить операторы сравнения (equality members) в базовом классе доменного объекта и писать ‘customer1 == customer2′ вместо ‘customer1.Id == customer2.Id’.
Пример 3: Разделение свойств доменного класса по персистентному признаку
public class Customer { public int Number { get; set; } public string Name { get; set; } // Не сохраняется в БД, можем хранить здесь все что угодно public string Message { get; set; } }
Если вы имеете тенденцию писать такой код, то вам следует остановиться и обдумать доменную модель. Подобный подход может говорить о том, что вы включили в доменную модель элементы, которые не имеют к ней отношения.
Когда доменная логика проникает в базу данных
Пример 1: Каскадное удаление
Настройка БД для каскадного удаления — один из примеров проникновения логики предметной области в логику сохранения данных. В идеале, БД сама по себе не должна содержать информации о том, когда должно срабатывать удаление данных. Подобное знание — это забота домена. Ваш C#/Java/etc код должен быть единственным местом для хранения подобной логики.
Пример 2: Хранимые процедуры
Использование хранимых процедур, которые изменяют данные в БД — еще один пример. Не позволяйте доменной логике проникать в базу данных, храните код, изменяющий состояние данных, в вашей доменной модели.
Тут необходимо сделать два замечания. Во-первых, в большинстве случаев, нет ничего плохого в том, чтобы иметь хранимые процедуры, которые не изменяют данные в БД (read-only stored procedures). Помещение кода, приводящего к побочным эффектам (side effects), в доменную модель и кода без побочных эффектов в хранимые процедуры прекрасно соотносится с принципом CQRS.
Во-вторых, существуют случаи, когда избежать использования SQL не получится. К примеру, если вам необходимо удалить группу объектов по какому-то признаку, SQL оператор DELETE сделает эту работу намного быстрее. В таких случаях, использование SQL, изменяющего данные в БД, оправданно, но необходимо держать все подобные исключения под строгим контролем и не давать им разрастаться.
Пример 3: Значения по умолчанию
Значения по умолчанию в таблицах БД — другой пример доменной логики, проникнувшей в базу данных. Значения свойств, которые доменная сущность имеет по умолчанию, должны быть определены в коде, а не отданы на откуп БД.
Подумайте, насколько сложно собирать подобные знания по кусочкам из разных мест приложения. Намного проще хранить их в едином месте.
Заключение
Большинство подобных «протечек» возникает из-за того, что люди думают о своем приложении не в терминах предметной области, а в терминах данных. Многие разработчики рассматривают разрабатываемую ими систему именно так. Для них, классы — это всего лишь хранилище для данных, которые они переносят от БД к UI, а ORM — всего лишь утилита, помогающая не копировать вручную данные из результатов выполнения SQL запросов в эти объекты. Очень часто бывает сложно сделать сдвиг в парадигме мышления. Но после того как он сделан, люди как правило открывают целый мир выразительных доменных моделей, которые позволяют разрабатывать приложения намного быстрее, особенно на больших проектах.
Конечно, не всегда возможно достичь желаемого уровня разделения ответственностей в коде приложения. Но в большинстве случаев ничто не мешает сделать это. Большинство проектов проваливаются не из-за того, что они оказываются не способны выполнить какое-либо из технических требований. Большинство терпят неудачу из-за того, что оказываются погребены под массой беспорядочного кода, который мешает разработчикам менять что-либо в нем. Каждое изменение в подобном коде приводит к каскаду багов и неожиданных побочных эффектов по всему приложению.
SoC — принцип, который позволяет избежать подобного исхода.
Ссылка на оригинал статьи: Separation of Concerns in ORM

