
Наверняка вы уже читали не один обзор механизмов сборки мусора в Java и настройка таких опций, как Xmx и Xms, превратилась для вас в обычную рутину. Но действительно ли вы в деталях понимаете, что происходит под капотом вашей виртуальной машины в тот момент, когда приходит время избавиться от ненужных объектов в памяти и ваш идеально оптимизированный метод начинает выполняться в несколько раз дольше положенного? И знаете ли вы, какие возможности предоставляют вам последние версии Java для оптимизации ответственной работы по сборке мусора, зачастую сильно влияющей на производительность вашего приложения?
Попробуем в нескольких статьях пройти путь от описания базовых идей, лежащих в основе всех сборщиков мусора, до разбора алгоритмов работы и возможностей тонкой настройки различных сборщиков Java HotSpot VM (вы ведь знаете, что таких сборщиков четыре?). И самое главное, рассмотрим, каким образом эти знания можно использовать на практике.
Следует сразу оговориться, что все сказанное ниже относится к виртуальной машине HotSpot. Так что если вы встречаете в тексте упоминание JVM, то речь идет именно об этой реализации. Но базовые принципы распространяются и на виртуальные машины других поставщиков, хотя в некоторых деталях они могут отличаться.
А оно мне надо?
Резонный вопрос. Далеко не любой программе для беспроблемной работы требуется тонкая настройка сборщика мусора. Очень часто выделения ей необходимого объема памяти оказывается достаточным. В конце концов, редкий пользователь заметит, что отклик программы время от времени занимает на сотню-другую миллисекунд дольше обычного.
Но возможно, объемы используемой вашей программой памяти таковы, что ее очистка занимает секунды, а то и десятки секунд. Или ваш сервис связан жестким SLA, и вы не можете позволить себе раскидываться десятками миллисекунд направо и налево. Или же любознательность не позволяет вам просто так закрывать глаза на то, что ваша программа что-то делает в своих недрах, а вы не знаете что. В этих случаях давайте разбираться.
Разделяй и властвуй
Прежде чем приступить непосредственно к решению вопросов очистки наших Авгиевых конюшен, давайте разберемся с их общим устройством и определимся, на чем конкретно нам хотелось бы сосредоточиться.
JVM разделяет используемую ею память на две области: куча (heap), в которой хранятся данные приложения, и не-куча (non-heap), в которой хранится код программы и другие вспомогательные данные.
Если ваше приложение при работе самостоятельно не генерирует новые классы и не занимается постоянной подгрузкой / выгрузкой классов, то состояние non-heap в долгосрочной перспективе будет близким к статичному и мало поддающимся оптимизации. В связи с этим, механизмы функционирования области non-heap мы здесь рассматривать не будем, а сосредоточимся на той области, где наши усилия принесут наибольшую выгоду.
Все объекты, которые явно или неявно создаются Java-приложением, размещаются в куче. Над оптимизацией размещения объектов и алгоритмами их обработки разработчики языков с автоматической сборкой мусора бьются с первого дня их создания. И как минимум в ближайшем будущем эта битва будет продолжаться, ведь объемы обрабатываемых данных растут, а требования к сборке мусора у различных приложений сильно отличаются, что делает создание единого идеального сборщика не самым тривиальным делом. Наше же дело — следить за развитием ситуации и стараться извлекать из имеющихся инструментов как можно больше пользы.
Из поколения в поколение
Преследуя свои цели (которые могут варьироваться и которые мы обязательно рассмотрим ниже), различные сборщики мусора используют разные подходы к организации памяти и ее очистке, но их объединяет общая черта — все они опираются на слабую гипотезу о поколениях. В общем виде, гипотеза о поколениях гласит, что вероятность смерти как функция от возраста снижается очень быстро. Ее приложение к сборке мусора в частности означает, что подавляющее большинство объектов живут крайне недолго. По людским меркам, большинство даже в детский сад не пойдут. Также это означает, что чем дольше прожил объект, тем выше вероятность того, что он будет жить и дальше.
Большинство приложений имеют распределение времен жизни объектов, схематично описываемое примерно такой кривой:
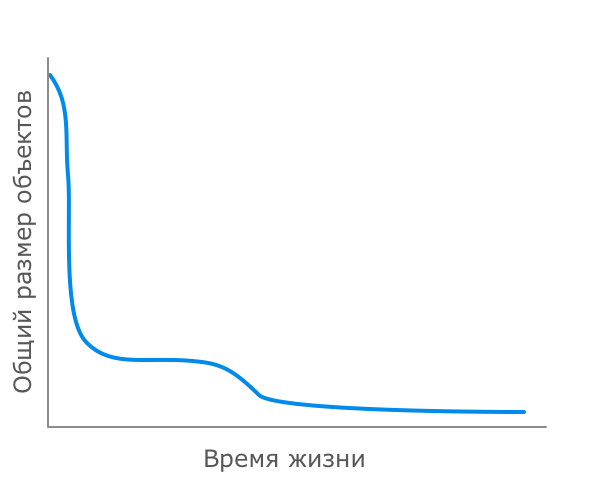
Подавляющее большинство объектов создаются на очень короткое время, они становятся ненужными практически сразу после их первого использования. Итераторы, локальные переменные методов, результаты боксинга и прочие временные объекты, которые зачастую создаются неявно, попадают именно в эту категорию, образуя пик в самом начале графика.
Далее идут объекты, создаваемые для выполнения более-менее долгих вычислений. Их жизнь чуть разнообразнее — они обычно гуляют по различным методам, трансформируясь и обогащаясь в процессе, но после этого становятся ненужными и превращаются в мусор. Благодаря таким объектам возникает небольшой бугорок на графике следом за пиком временных объектов.
И, наконец, объекты-старожилы, переживающие почти всех — это постоянные данные программы, загружаемые часто в самом начале и проживающие долгую и счастливую жизнь до остановки приложения.
Конечно, каждое приложение по-своему уникально, поэтому в каждом конкретном случае этот график будет варьироваться, изменять пропорции, на нем будут появляться аномалии, но чаще всего форма именно такая. Запомните этот график, он нам еще пригодится при выполнении оптимизаций.
Все это навело разработчиков на мысль, что в первую очередь необходимо сосредотачиваться на очистке тех объектов, которые были созданы совсем недавно. Именно среди них чаще всего находится

Вот тут и возникает идея разделения объектов на младшее поколение (young generation) и старшее поколение (old generation). В соответствии с этим разделением и процессы сборки мусора разделяются на малую сборку (minor GC), затрагивающую только младшее поколение, и полную сборку (full GC), которая может затрагивать оба поколения. Малые сборки выполняются достаточно часто и удаляют основную часть мертвых объектов. Полные сборки выполняются тогда, когда текущий объем выделенной программе памяти близок к исчерпанию и малой сборкой уже не обойтись.
При этом разделение объектов по поколениям не просто условное, они физически размещаются в разных регионах памяти. Объекты из младшего поколения по мере выживания в сборках мусора переходят в старшее поколение. В старшем поколении объект может прожить до окончания работы приложения, либо будет удален в процессе одной из полных сборок мусора.
Вам быстро, дешево или качественно?
Интуитивно понятно, что желательно иметь сборщик мусора, который как можно быстрее избавлялся бы от ненужных объектов, расчищая дорогу молодым и обеспечивая тихое и спокойное существование долгожителям. Но работа сборщика мусора не бесплатная, она оплачивается ресурсами компьютера и задержками в выполнении программы. Поэтому прежде чем двигаться дальше, давайте разберемся с критериями, используемыми при оценке сборщиков.
Традиционно, при определении эффективности работы сборщика мусора учитываются следующие факторы:
- Максимальная задержка — максимальное время, на которое сборщик приостанавливает выполнение программы для выполнения одной сборки. Такие остановки называются stop-the-world (или STW).
- Пропускная способность — отношение общего времени работы программы к общему времени простоя, вызванного сборкой мусора, на длительном промежутке времени.
- Потребляемые ресурсы — объем ресурсов процессора и/или дополнительной памяти, потребляемых сборщиком.
Понятно, что добиться улучшения всех трех параметров одновременно практически невозможно. Уменьшение максимального времени задержки приводит к учащению сборки мусора, уменьшая пропускную способность. Либо приходится использовать более ухищренные алгоритмы для сохранения пропускной способности, что чаще всего увеличивает потребление ресурсов. И так далее.
Поэтому при настройке сборщиков мусора разработчики обычно фокусируются на оптимизации одного или двух параметров, стараясь сильно не ухудшать остальные, но жертвуя ими в случае необходимости.
Memento Mori
Господи, дай мне места для размещения того, что пока еще нужно,
Дай мне смелости удалить то, что больше не пригодится,
И дай мне мудрости, чтобы отличить одно от другого.
— Молитва сборщиков мусора
Еще один важный вопрос, который хотелось бы разобрать прежде, чем двигаться дальше, это определение самого понятия мусора, то есть мертвых объектов.
Как мы уже выяснили выше, путь большинства объектов от момента создания и исполнения своего предназначения до момента превращения в мусор, достаточно короток. Но существуют факторы, которые могут задержать его в мире живых чуть дольше, чем нам того хотелось бы.
Все мы знаем, что считать объект живым просто по факту наличия на него ссылок из других объектов нельзя. В противном случае рецепт бессмертия в JVM был бы до безобразия прост и заключался бы в наличии взаимных ссылок хотя бы у двух объектов друг на друга, а в общем случае — в наличии цикла в графе связанности объектов. При таком подходе и ограниченном объеме памяти более-менее серьезная программа долго не проработала бы, поэтому с отслеживанием циклов в графах объектов JVM справляется хорошо.
Но и просто сказать, что объект мертв и может быть удален только на основании того, что в программе не осталось ссылающихся на него (напрямую или опосредованно) еще используемых объектов, нельзя, так как разделение объектов на поколения вносит свои коррективы.
Рассмотрим такую ситуацию: У нас есть молодой объект A и ссылающийся на него объект B, уже заслуживший место в старшем поколении. В какой-то момент времени оба этих объекта стали нам не нужны и мы обнулили все имеющиеся у нас ссылки на них. Очевидно, объект A можно было бы удалить в ближайшую малую сборку мусора, но для того, чтобы получить это знание, сборщику пришлось бы просмотреть всё старшее поколение и понять, что объект B ссылающийся на A, тоже является мусором, а следовательно их оба можно утилизировать. Но анализ старшего поколения не входит в план малой сборки, так как является относительно дорогой процедурой, поэтому объект А во время малой сборки будет считаться живым.

Таким образом, чаще всего для целей малой сборки мусора объект считается мертвым и подлежащим утилизации, если до него невозможно добраться по ссылкам ни из объектов старшего поколения, ни из так называемых корней (roots), к каковым относятся ссылки из стеков потоков, статические члены классов
Кстати, время от момента, когда объект стал нам не нужен, до момента его фактического удаления из памяти называется проворством (promptness) и иногда рассматривается как дополнительный фактор оценки эффективности сборщика.
Под микроскопом
Итак, мы уже получили базовые представления о том, чем занимаются сборщики мусора и по каким критериям их можно оценивать. Теперь хотелось бы разобраться, каким образом можно заглянуть внутрь виртуальной машины, чтобы у нас была возможность наблюдать за работой ее скрытых механизмов.
Инструменты мониторинга памяти и процессов сборки мусора целесообразно разделить на две группы:
- внутренние, являющиеся частью той программы, которую мы мониторим,
- внешние, подключаемые к процессу исследуемой программы извне.
Проблема с инструментами мониторинга памяти в том, что они самим фактом наблюдения за памятью и сборками мусора, как в квантовой механике или в психологии, влияют на поведение подопытного. Ниже я приведу пример такого изменения поведения, а пока просто нужно запомнить, что какой бы инструмент вы ни использовали, следует проверить его калибровку хотя бы на простом примере: запустите программу, которая ничего не делает, и помониторьте ее.
Внутренние инструменты
Что касается внутренних инструментов мониторинга, то здесь мы можем либо попросить JVM выводить информацию о производимых сборках с различным уровнем детализации (в stdout или в лог-файл), либо самостоятельно обращаться к MXBean’ам, возвращающим информацию о состоянии памяти и о выполняемых сборках мусора, и обрабатывать ее как нам вздумается.
В JVM HotSpot доступны следующие опции, управляющие выводом информации о сборках мусора (это основные опции, работающие для всех сборщиков):
| Включает режим логирования сборок мусора в stdout. | |
| Указывает имя файла, в который должна логироваться информация о сборках мусора. Имеет приоритет над -verbose:gc. | |
| Добавляет к информации о сборках временные метки (в виде количества секунд, прошедших с начала работы программы). | |
| Включает расширенный вывод информации о сборках мусора. | |
| При старте приложения выводит в stdout значения всех опций, заданных явно или установленных самой JVM. Сюда же попадают опции, относящиеся к сборке мусора. Часто бывает полезно посмотреть на присвоенные им значения. |
Если вы хотите собирать данные из своего приложения самостоятельно, то для этого можно использовать соответствующие MXBean’ы. Вот пример простого класса, который позволяет выводить текущее состояние различных регионов памяти, а также информацию о сборках мусора, его можно взять за основу, если хотите разработать свой собственный мониторинг:
MemoryUtil.java
public class MemoryUtil { private static final int NORM_NAME_LENGTH = 25; private static final long SIZE_KB = 1024; private static final long SIZE_MB = SIZE_KB * 1024; private static final long SIZE_GB = SIZE_MB * 1024; private static final String SPACES = " "; private static Map<String, MemRegion> memRegions; // Вспомогательный класс для хранения информации о регионах памяти private static class MemRegion { private boolean heap; // Признак того, что это регион кучи private String normName; // Имя, доведенное пробелами до универсальной длины public MemRegion(String name, boolean heap) { this.heap = heap; normName = name.length() < NORM_NAME_LENGTH ? name.concat(SPACES.substring(0, NORM_NAME_LENGTH - name.length())) : name; } public boolean isHeap() { return heap; } public String getNormName() { return normName; } } static { // Запоминаем информацию обо всех регионах памяти memRegions = new HashMap<String, MemRegion>(ManagementFactory.getMemoryPoolMXBeans().size()); for(MemoryPoolMXBean mBean: ManagementFactory.getMemoryPoolMXBeans()) { memRegions.put(mBean.getName(), new MemRegion(mBean.getName(), mBean.getType() == MemoryType.HEAP)); } } // Обработчик сообщений о сборке мусора private static NotificationListener gcHandler = new NotificationListener() { @Override public void handleNotification(Notification notification, Object handback) { if (notification.getType().equals(GarbageCollectionNotificationInfo.GARBAGE_COLLECTION_NOTIFICATION)) { GarbageCollectionNotificationInfo gcInfo = GarbageCollectionNotificationInfo.from((CompositeData) notification.getUserData()); Map<String, MemoryUsage> memBefore = gcInfo.getGcInfo().getMemoryUsageBeforeGc(); Map<String, MemoryUsage> memAfter = gcInfo.getGcInfo().getMemoryUsageAfterGc(); StringBuilder sb = new StringBuilder(); sb.append("[").append(gcInfo.getGcAction()).append(" / ").append(gcInfo.getGcCause()) .append(" / ").append(gcInfo.getGcName()).append(" / ("); appendMemUsage(sb, memBefore); sb.append(") -> ("); appendMemUsage(sb, memAfter); sb.append("), ").append(gcInfo.getGcInfo().getDuration()).append(" ms]"); System.out.println(sb.toString()); } } }; /** * Выводит в stdout информацию о текущем состоянии различных разделов памяти. */ public static void printUsage(boolean heapOnly) { for(MemoryPoolMXBean mBean: ManagementFactory.getMemoryPoolMXBeans()) { if (!heapOnly || mBean.getType() == MemoryType.HEAP) { printMemUsage(mBean.getName(), mBean.getUsage()); } } } /** * Запускает процесс мониторинга сборок мусора. */ public static void startGCMonitor() { for(GarbageCollectorMXBean mBean: ManagementFactory.getGarbageCollectorMXBeans()) { ((NotificationEmitter) mBean).addNotificationListener(gcHandler, null, null); } } /** * Останавливает процесс мониторинга сборок мусора. */ public static void stopGCMonitor() { for(GarbageCollectorMXBean mBean: ManagementFactory.getGarbageCollectorMXBeans()) { try { ((NotificationEmitter) mBean).removeNotificationListener(gcHandler); } catch(ListenerNotFoundException e) { } } } private static void printMemUsage(String title, MemoryUsage usage) { System.out.println(String.format("%s%s\t%.1f%%\t[%s]", memRegions.get(title).getNormName(), formatMemory(usage.getUsed()), usage.getMax() < 0 ? 0.0 : (double)usage.getUsed() / (double)usage.getMax() * 100, formatMemory(usage.getMax()))); } private static String formatMemory(long bytes) { if (bytes > SIZE_GB) { return String.format("%.2fG", bytes / (double)SIZE_GB); } else if (bytes > SIZE_MB) { return String.format("%.2fM", bytes / (double)SIZE_MB); } else if (bytes > SIZE_KB) { return String.format("%.2fK", bytes / (double)SIZE_KB); } return Long.toString(bytes); } private static void appendMemUsage(StringBuilder sb, Map<String, MemoryUsage> memUsage) { for(Entry<String, MemoryUsage> entry: memUsage.entrySet()) { if (memRegions.get(entry.getKey()).isHeap()) { sb.append(entry.getKey()).append(" used=") .append(entry.getValue().getUsed() >> 10) .append("K; "); } } } }
Внешние инструменты
В природе существует огромное количество инструментов, позволяющих подключиться к процессу Java и в удобном виде получить информацию о состоянии памяти и процессах сборки мусора. Это и входящие в поставку JVM HotSpot утилиты VisualVM (с плагином VisualGC) и Java Mission Control и различные инструменты/плагины для IDE и отдельные программы вроде JProfiler или YourKit и еще много чего.
Вы можете выбрать то, чем вам удобнее пользоваться, но как уже было сказано выше, обязательно проверьте, какое влияние оказывает ваш инструмент и его настройки на подопытное приложение. Вот пример того, как VisualVM влияет на поведение программы, весь исполняемый код которой состоит из приостановки выполнения основного потока:

Видите этот растущий график в верхней части? Это почти 8 МБ мусорных данных в минуту, привносимых мониторингом. Если вам нужно общее представление о том, как работает сборщик, либо если десяток мегабайт данных в минуту для вашей программы меньше допустимой погрешности измерений, то такое поведение инструменту можно простить. Но если вы проводите тонкую настройку и у вас каждый мегабайт на счету, то лучше выбрать что-нибудь менее прожорливое.
В идеале, ваш инструмент должен отображать график использования памяти коматозной программой как-нибудь так:
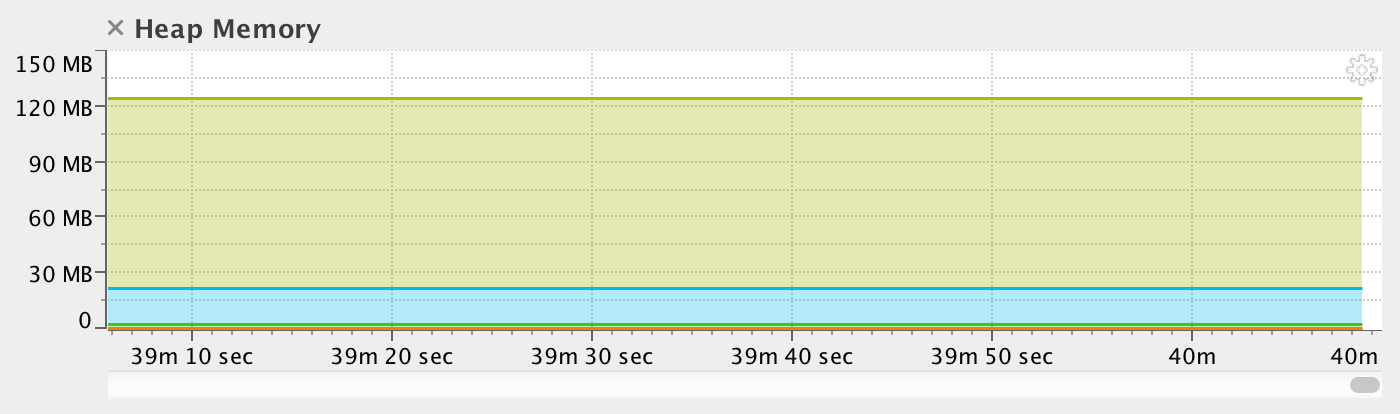
Как вариант, обратите внимание на описанные выше внутренние инструменты мониторинга, они изначально легковесные, а при необходимости добавления расширенных функций вы можете сами влиять на их прожорливость.
А можно всех посмотреть?
Ну что ж, раз вы добрались до этого места и вас не остановило даже долгое перечисление очевидных вещей в предыдущих параграфах, то вам и впрямь должно быть интересно. Давайте тогда уже взглянем на то, что же нам предоставляет HotSpot из коробки.
Как уже было сказано, описанные выше принципы сборки мусора являются общими для всех сборщиков. Но при этом между сборщиками существуют и заметные различия, проявляющиеся в ответах на следующие вопросы:
- Какое количество регионов кучи используется, каково их назначение и размеры? Как эти размеры изменяются динамически?
- Как устроен перевод объектов из младшего поколения в старшее?
- Какие из работ по сборке мусора выполняются параллельно с работой основной программы, а какие приводят к ее остановке?
- Каким образом сборщик мусора автоматически подстраивается под требуемые параметры производительности? Каким из них отдает приоритет?
- Какие существуют возможности по настройке сборщика?

Java HotSpot VM предоставляет разработчикам на выбор семь различных сборщика мусора:
Serial (последовательный) — самый простой вариант для приложений с небольшим объемом данных и не требовательных к задержкам. Редко когда используется, но на слабых компьютерах может быть выбран виртуальной машиной в качестве сборщика по умолчанию.
Parallel (параллельный) — наследует подходы к сборке от последовательного сборщика, но добавляет параллелизм в некоторые операции, а также возможности по автоматической подстройке под требуемые параметры производительности.
Concurrent Mark Sweep (CMS) — нацелен на снижение максимальных задержек путем выполнения части работ по сборке мусора параллельно с основными потоками приложения. Подходит для работы с относительно большими объемами данных в памяти.
Garbage-First (G1) — создан для постепенной замены CMS, особенно в серверных приложениях, работающих на многопроцессорных серверах и оперирующих большими объемами данных.
Epsilon GC — разработан для случаев, когда сборка мусора вообще не нужна.
ZGC — пытается удерживать паузы на субмиллисекундном уровне, даже при работе с очень большими кучами.
Shenandoah GC — еще один сборщик, нацеленный на ультракороткие паузы независимо от размера кучи.
В следующих статьях мы детально рассмотрим каждый из этих сборщиков, стараясь придерживаться общего плана: краткое описание, принципы работы, ситуации STW (это stop the world, если успели забыть), способы настройки, достоинства и недостатки. Получив эти знания, мы посмотрим, что с ними делать в реальной жизни.
Часть 2 — Сборщики Serial GC и Parallel GC →
Часть 3 — Сборщики CMS GC и G1 GC →
Часть 4 — Сборщик ZGC →
Часть 5 — Сборщик Epsilon GC →
Часть 6 — Сборщик Shenandoah GC →

