
Многие программисты пытались и пытаются сделать какую-нибудь диалоговую программу для общения с машиной на ЕЯ. Не счесть всяких ботов и тому подобных самоделок.
Кроме того, существует огромное количество коммерческих программ, которые как-то, приблизительно, решают проблемы машинного понимания ЕЯ. Примеры всем известны – поисковые системы, так называемые системы машинного перевода, системы анализа тональности, справочные системы, да и тот же FAQ – все они далеки от удовлетворительного решения проблемы общения с машиной на ЕЯ.
Причина видна невооруженным глазом – используются приблизительные, поверхностные, упрощенные способы обработки естественно-языковых предложений – поиск ключевых слов, использование статистических данных о встречаемости тех или иных синтаксических структур в языке. Тем самым как бы подразумевается, что ЕЯ слишком сложен для реализации полного машинного понимания, поэтому надо применять упрощающие задачу подходы.
Каким должно быть полное, бескомпромиссное решение проблемы? Очевидно, для этого машина должна обеспечивать такую же работу с естественным языком, какую выполняем мы, люди, когда читаем, слушаем, говорим, пишем и думаем. В чем наше отличие в этом деле от нынешних компьютерных программ? Человек работает со смысловым содержанием предложений, понимая, что одну и ту же мысль можно выразить множеством способов, хотя и не полностью эквивалентных. Значит, надо научить машину так обрабатывать предложения на естественном языке, чтобы извлекать мысль, смысловое содержание содержащуюся в этих предложениях. Машина должна работать с мыслью, а не с буквой.
Тут возникают два взаимосвязанных вопроса:
— как построить механизм извлечения смыслового содержания из текста?
— как формально представить это смысловое содержание текста?
Конечно, главной проблемой здесь является вторая, поскольку обеспечивает необходимую начальную формализацию задачи. Решения этой проблем известны достаточно давно. Кратко рассмотрим некоторые из них.
Еще в далеком 1980г. в переводе на русский язык вышла книга Р. Шенка «Концептуальная обработка информации», в которой он описал выполненную им со своими аспирантами работу по моделированию машинного понимания естественного языка. Он разработал метод формального представления смыслового содержания ЕЯ-предложения, а его аспиранты реализовали в виде программ на языке ЛИСП три основные необходимые функции:
— семантическая трансляция – преобразование предложения нам естественном языке в соответствующую концептуальную модель;
— концептуальная память – манипулирование концептуальными структурами, соответствующее «человеческим» мыслительным операциям;
— концептуальная генерация – преобразование концептуальной структуры в текст на естественном языке.
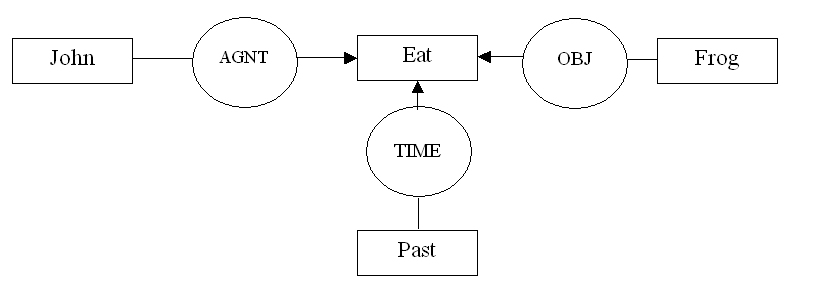
Пример концептуального представления предложения «Джон съел лягушку».

Подход Шенка основан на применение специального, разработанного им языка для описания мыслительных (концептуальных) операций и объектов. Он назвал свой подход теорией концептуальной зависимости (ТКЗ).
Для того чтобы дать начальное представление о ТКЗ приведем некоторые минимальные сведения о нем. Концептуализация – базовая единица концептуального уровня, из которой конструируются мысли. Концептуализация строится из следующих элементов:
— ДЕЯТЕЛЬ – понятие исполнителя АКТа;
— АКТ – действие, производимое по отношению к объекту;
— ОБЪЕКТ – нечто над которым производится действие;
— РЕЦИПИЕНТ – получатель ОБЪЕКТА в результате АКТа;
— НАПРАВЛЕНИЕ – местоположение, к которому направлен АКТ;
— СОСТОЯНИЕ – состояние ОБЪЕКТА.
Действия, объекты, отношения, состояния – вот основные элементы созданного им языка (для которого он не придумал имени).
Основные типы концептуальных действий в ТКЗ следующие:
— PROPEL, MOVE, INGEST, EXPEL, GRASP (физические действия, выполняемые человеком);
— PTRANS – «переместить физический объект»;
— ATRANS – «изменить абстрактное отношение для объекта
— SPEAK – «произвести звук»;
— ATTEND – «направить орган чувств к определенному стимулу»;
— MTRANS – «передавать информацию (между людьми или внутри одного человека)»;
— MBUILD – «создавать иди сочетать мысли».
Здесь мы не будем давать описание или хотя бы введение в язык ТКЗ, поскольку это не является целью данного текста. В книге Р. Шенка есть подробное описание этого языка.
Теория Шенка направлена на описание поведения и мышления человеческих субъектов, что очень интересно и актуально для моделирования личности. На основе ТКЗ можно создавать программы, обеспечивающие диалог мыслящих индивидуумов, когда диалог с машиной будет неотличим от диалога с человеком.
В то же время, для машинного понимания ЕЯ-текста не всегда нужно точное моделирование мыслительных процессов индивидуума. В качестве одного из более утилитарных подходов к моделированию семантики текста можно рассматривать теорию концептуальных графов. Первым автором, который подробно описал КГ и рассмотрел вопросы их применения является R. Sowa, книга которого «Conceptual Structures: Information Processing in Mind and Machine» на русский язык не переводилась.
Концептуальный граф представляет собой связную сеть бинарных отношений, описывающих смысловые связи соответствующего предложения. Этот подход превратился в целое научное направление, в котором есть различные ветви, имеется множество экспериментальных разработок, проводятся научные конференции.
В КГ тоже есть абстрактные концепты и отношения, но при описании концептуализации приводятся только непосредственно высказанные смысловые утверждения и концептуальные объекты, поэтому конкретная концептуализация выглядит намного проще.
В качестве одной из практических реализаций теории КГ можно рассматривать UNL – универсальный сетевой язык, созданный и развиваемый в институте развития ООН. UNL предназначен для решения проблемы машинного перевода в Интернет — планируется, что для каждого из существующих естественных языков будет создан транслятор в UNL и генератор из текста UNL в каждый ЕЯ, что позволит людям свободно общаться в Интернет, не зависимо от используемого языка. Несмотря на понятную и четкую концепцию, изложенную в соответствующих стандартах, язык UNL все еще развит не в такой мере, чтобы обеспечить решение проблемы машинного перевода.
Работа по созданию семантического процессора CONST, которая ведется в НПФ «Семантикс Рисеч» (г. Казань) позволит снять проблему машинного понимания естественного языка, предоставив программистам удобные инструменты для создания интеллектуальных приложений на основе механизмов решения всех основных типов задач, требующих машинного понимания ЕЯ — машинный перевод, базы знаний, естественно-языковый диалог с машиной, общение с роботом и т.п.
Язык CONST является одним из вариантов реализации теории КГ и предназначен для построения всех типов интеллектуальных систем, связанных с пониманием ЕЯ-текстов и ЕЯ-диалогом. Структура семантического процессора аналогична системе MARGIE, но предназначена для коммерческого использования.

Литература
1. Шенк Р. Обработка концептуальной информации, М.: Энергия, 1980, — 360с.
2. Sowa John F. Conceptual Structures: Information Processing in Mind and Machine, Addison-Wesley, Reading, Ma.
3. www.undlfoundation.org
4. Н. Ихсанов. CONST – инструмент создания прикладных интеллектуальных систем, Эвристические алгоритмы и распределённые вычисления, Самара, 2015, т.2. №2, с.69–78

