Целью статьи является дать основные представления о DevOps и практиках, используемых при этой методологии. Тут не будет сложных терминов, конкретных продуктов и road map внедрения DevOps, но, надеюсь, будет интересно ознакомиться.
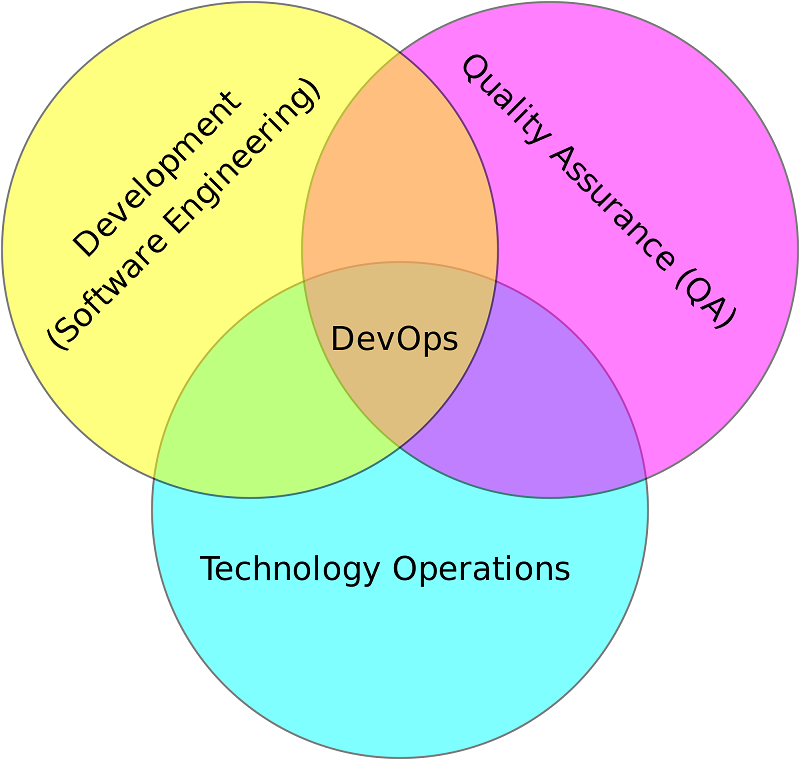
Как такового, определения DevOps нет, и все понимают эту методологию по-разному. Декларируемая цель – убрать барьеры между DEVelopment и OPerations. Поэтому часто DevOps понимают как то, что operations, QA и development находятся в одной команде, сидят в одном помещении, проводят общие митинги, общаются. Само по себе сближение и неформальное общение членов команды всегда полезно и уже это может привести к улучшению результатов. Но есть и формальные практики, следование которым позволяет улучшить поставку релизов, а значит и удовлетворение бизнеса.
Здесь описаны следующие:
Приведенные ниже практики взяты из серии роликов от Microsoft DevOps-Fundamentals. Очень интересные и полезные вебинары, правда, с акцентом на технологии Microsoft.
Структура статьи построена следующим образом: перечислены практики, дано их описание, приведено Бизнес-Значение практики (то, как внедрение этого подхода улучшит жизнь бизнеса) и Измеримость (как можно измерить улучшение). И Бизнес-значение, и Измеримость также взяты из презентаций «DevOps-Fundamentals».
Ну что же, приступим. Процесс разработки и поставки ПО состоит из следующих шагов:
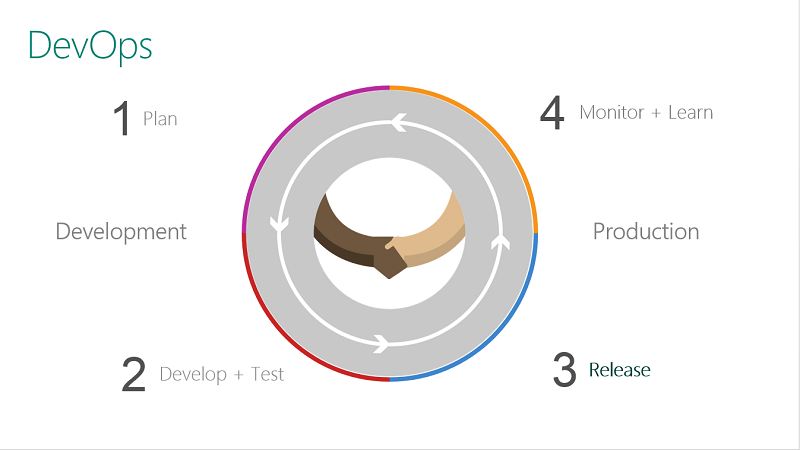
Начинается все с планирования. Планирование релиза, разработки, тестирования, развертывания. Пропустим этот шаг, так как development и operations в этом шаге не задействованы. После того, как разработчик закончил реализацию некоторого участка кода, он сохраняет (commit'ит) его в систему контроля версий. После этого вступает в дело первая практика:
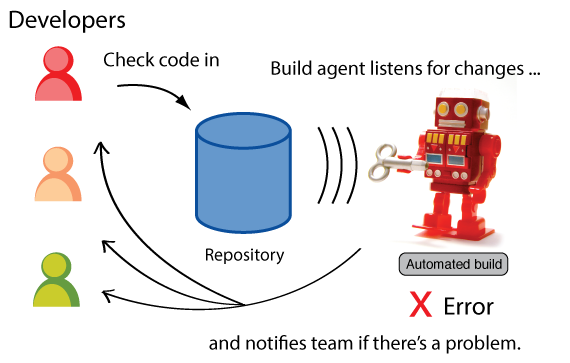
Непрерывная интеграция (Continuous Integration) — это практика разработки программного обеспечения, которая заключается в слиянии рабочих копий в общую основную ветвь разработки несколько раз в день и выполнении частых автоматизированных сборок проекта для скорейшего выявления и решения интеграционных проблем. Wiki
Собственно, что такое Continuous Integration? Процесс происходит примерно так: разработчик, после того, как завершил свою задачу и отладился, сохраняет свои изменения в рабочюю копию (TFS, SVN, Git). Дальше в действие вступает некий робот (TFS, TeamCity, что-либо еще), отслеживающий изменение рабочей версии. Он видит, что рабочая копия изменилась и запускает сборку проекта. По результатам сборки, оповещается разработчик (и другие заинтересованные лица) о том, прошло все успешно или нет. Оповещение может быть через письмо, сообщение в трее, или отобразиться на web-странице. Таким образом, если сборка прошла с ошибкой, то разработчик сразу же узнает об этом.

Автоматизированное тестирование – это процесс верификации программного обеспечения, при котором основные функции и шаги теста, такие как запуск, инициализация, выполнение, анализ и выдача результата, выполняются автоматически при помощи инструментов для автоматизированного тестирования ©.
После того, как сборка собрана, её нужно проверить. Наиболее быстро это можно сделать с помощью автоматических тестов. Для этого используются различные инструменты: это могут быть Unit тесты, UX тесты, интеграционные тесты. Главное условие – они не должны требовать участия человека. С помощью авто-тестов мы сразу получаем информацию о том, есть ли ошибки в нашей сборке. И сразу же можем начать их исправлять, не дожидаясь результатов ручного тестирования.
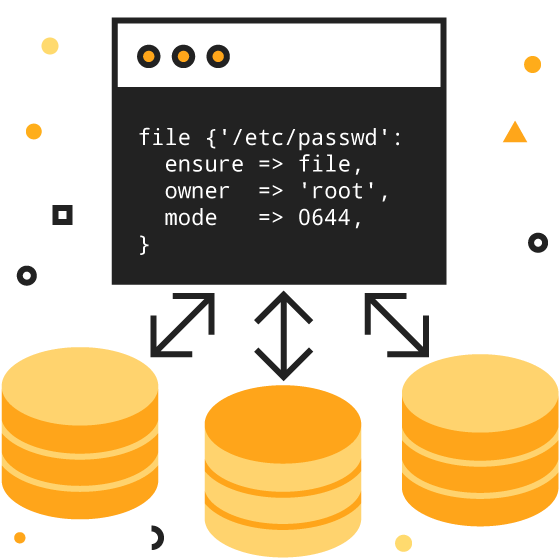
Инфраструктура как код — это процесс управления и подготовки вычислительной инфраструктуры (процессы, физические сервера, виртуальные сервера и т.п.) и их конфигурации через машиннообрабатываемые файлы определений, а не физическую конфигурацию оборудования или использование конфигурационных инструментов Wiki.
Подход к конфигурированию приложений должен быть таким же, как и к коду. То есть конфигурационные файлы, переменные окружения, что-то еще должны храниться в централизованном хранилище или системе контроля версий, возможно, в той же самой, что и хранится код. И при конфигурировании приложения браться они должны именно оттуда. Соответственно, в случае необходимости изменить конфигурацию на сервере, ответственный сотрудник не заходит на него и меняет, например, соединение к БД, а меняет нужную переменную в хранилище, и оттуда она уже автоматически появляется на сервере.
Для переменных, специфичных для различных сред (Dev, Stage, Production) используются синонимы, подменяемые при развертывании на реальные значения. Примером такой подмены может служить технология transform, используемая для изменения конфигурационных файлов .NET приложений.
Непрерывная развертывание – объединение Continuous Integration (непрерывной интеграции) и Continuous Delivery (непрерывной поставки). Это следующий шаг после успешной сборки и успешного прохождения автоматических тестов (и, возможно, установки галочки «сборка готова к развертыванию» ответственным человеком). Если вы уверены в ваших тестах, их наборе и покрытии, при их успешном выполнении запускается автоматическая установка на соответствующую среду, тестовую или продуктовую. Разница между Continuous Integration, Delivery, Deployment хорошо описана тут: http://blogs.atlassian.com/2014/04/practical-continuous-deployment/

Управление релизом заключается в том, что мы определяем формальные критерии, готова ли сборка к установке на соответствующую среду. Примером критериев, по которым сборка готова, и, если они выполняются, автоматически запускается поставка (Continuous Deployment) могут быть:
Полезная ссылка: Управление релизами в Visual Studio 2013.

Управление конфигурациями (Configuration Management) — это детальная запись и обновление информации, описывающей ПО и оборудование предприятия. Такая информация обычно включает версии и апдейты, которые были применены к установленному ПО, а также местоположение и сетевые адреса оборудования. ©
Здесь к формальному определению добавить особо и нечего. Все должно быть записано и подсчитано.

Нагрузочное тестирование (load testing) — подвид тестирования производительности, сбор показателей и определение производительности и времени отклика программно-технической системы или устройства в ответ на внешний запрос с целью установления соответствия требованиям, предъявляемым к данной системе (устройству) Wiki
Часто происходит так, что, например, для web приложений, когда пользователь один (разработчик или тестировщик) страница быстро открывается у и хорошо реагирует на работу с ней. Но как только изменения попадают на продуктовый сервер, и эту же страницу начинают смотреть сотни, тысячи человек одновременно, страница долго грузится и перестаёт реагировать.
Проводя нагрузочное тестирование мы и определяем наличие проблем на раннем этапе, еще до попадания проблемной сборки на продуктовый сервер. Нагрузочное тестирование реализуется генерацией большого потока запросов к серверу и анализа поведения сервера.

Мониторинг быстродействия приложения (application performance management) – это мониторинг и управление быстродействием и доступностью ПО. APM стремится выявлять и диагностировать проблемы быстродействия комплексно, для поддержания ожидаемого уровня обслуживания Wiki
Нагрузочное тестирование выявляет многие проблемы еще до того, как сборка попала на продуктовые сервера и с ней начали работать клиенты. Но, к сожалению, не всегда удается предугадать как действия пользователей, так и влияние разницы в ресурсах серверов на тестовой и продуктовой средах. Поэтому необходимо мониторить состояние и работу приложения на продуктовой среде. Этому и служит мониторинг быстродействия приложения.
Надеюсь, данная статья дала вам представление, что такое DevOps и что нужно сделать для улучшения жизни developers, operations и business.
Как такового, определения DevOps нет, и все понимают эту методологию по-разному. Декларируемая цель – убрать барьеры между DEVelopment и OPerations. Поэтому часто DevOps понимают как то, что operations, QA и development находятся в одной команде, сидят в одном помещении, проводят общие митинги, общаются. Само по себе сближение и неформальное общение членов команды всегда полезно и уже это может привести к улучшению результатов. Но есть и формальные практики, следование которым позволяет улучшить поставку релизов, а значит и удовлетворение бизнеса.
Здесь описаны следующие:
- Continuous Integration
- Automated Testing
- Infrastructure as Code
- Continuous Deployment
- Configuration Management
- Load Testing
- Application Performance Monitoring
Приведенные ниже практики взяты из серии роликов от Microsoft DevOps-Fundamentals. Очень интересные и полезные вебинары, правда, с акцентом на технологии Microsoft.
Структура статьи построена следующим образом: перечислены практики, дано их описание, приведено Бизнес-Значение практики (то, как внедрение этого подхода улучшит жизнь бизнеса) и Измеримость (как можно измерить улучшение). И Бизнес-значение, и Измеримость также взяты из презентаций «DevOps-Fundamentals».
Ну что же, приступим. Процесс разработки и поставки ПО состоит из следующих шагов:
Начинается все с планирования. Планирование релиза, разработки, тестирования, развертывания. Пропустим этот шаг, так как development и operations в этом шаге не задействованы. После того, как разработчик закончил реализацию некоторого участка кода, он сохраняет (commit'ит) его в систему контроля версий. После этого вступает в дело первая практика:
Непрерывная интеграция (Continuous Integration)
Непрерывная интеграция (Continuous Integration) — это практика разработки программного обеспечения, которая заключается в слиянии рабочих копий в общую основную ветвь разработки несколько раз в день и выполнении частых автоматизированных сборок проекта для скорейшего выявления и решения интеграционных проблем. Wiki
Собственно, что такое Continuous Integration? Процесс происходит примерно так: разработчик, после того, как завершил свою задачу и отладился, сохраняет свои изменения в рабочюю копию (TFS, SVN, Git). Дальше в действие вступает некий робот (TFS, TeamCity, что-либо еще), отслеживающий изменение рабочей версии. Он видит, что рабочая копия изменилась и запускает сборку проекта. По результатам сборки, оповещается разработчик (и другие заинтересованные лица) о том, прошло все успешно или нет. Оповещение может быть через письмо, сообщение в трее, или отобразиться на web-странице. Таким образом, если сборка прошла с ошибкой, то разработчик сразу же узнает об этом.
Бизнес значение
- Ускорение поставки (Accelerate Delivery) – достигается тем, что мы сразу же узнаем об ошибке сборки и, соответственно, можем быстрее начать её исправлять.
- Повторяемость (Repeatability) — весь процесс повторяем, то есть если никаких изменений не произошло, то и сборка будет так же успешна (или не успешна). Нет такой проблемы как то, что у одного разработчика все собирается, а у другого – нет.
- Оптимизация ресурсов (Optimized Resources) — нет необходимости вручную запускать сборку, на компьютере человека или билд сервере, нет необходимости готовить сборку – выкачивать исходники из source control и т.п.
Измеримость
- Время развертывания (Deployment Lead Time) – время, необходимое на сборку проекта.
- MTTR (Mean Time To Repair — среднее время восстановления работоспособности). Можно измерить время, прошедшее от сообщения об ошибочной сборке, до исправления, убирающего ошибку.
- MTTD (Mean Time To Detect – среднее время обнаружения неисправности). измеряется время, которое прошло от внесения ошибки, до определения, что возникла проблема и в чем она заключается.
Автоматическое тестирование (Automated Testing)
Автоматизированное тестирование – это процесс верификации программного обеспечения, при котором основные функции и шаги теста, такие как запуск, инициализация, выполнение, анализ и выдача результата, выполняются автоматически при помощи инструментов для автоматизированного тестирования ©.
После того, как сборка собрана, её нужно проверить. Наиболее быстро это можно сделать с помощью автоматических тестов. Для этого используются различные инструменты: это могут быть Unit тесты, UX тесты, интеграционные тесты. Главное условие – они не должны требовать участия человека. С помощью авто-тестов мы сразу получаем информацию о том, есть ли ошибки в нашей сборке. И сразу же можем начать их исправлять, не дожидаясь результатов ручного тестирования.
Бизнес значение
- Ускорение поставки (Accelerate Delivery). Мы быстрее получаем информацию о том, валидна ли сборка и можно ли её выпускать.
- Повторяемость (Repeatability) – тест всегда запускается в одной и той же последовательности, по одному и тому же сценарию, поэтому и результат будет одинаков.
- Оптимизация ресурсов (Optimized Resources). Автоматические тесты дешевле ручного за счет того, что их выполнение гораздо дешевле, чем проверка с помощью ручного тестирования.
Измеримость
- Время развертывания (Deployment Lead Time) – время, необходимое на развертывание (сборку, проверку).
- MTTR – В данном случае, измеряется время от диагностирования ошибки до её исправления (успешного прохождения теста).
- MTTD – так как тесты автоматические, то можно измерить время от сборки проекта до получения отчета об ошибке по результатам тестирования.
Инфраструктура как код (Infrastructure as Code)
Инфраструктура как код — это процесс управления и подготовки вычислительной инфраструктуры (процессы, физические сервера, виртуальные сервера и т.п.) и их конфигурации через машиннообрабатываемые файлы определений, а не физическую конфигурацию оборудования или использование конфигурационных инструментов Wiki.
Подход к конфигурированию приложений должен быть таким же, как и к коду. То есть конфигурационные файлы, переменные окружения, что-то еще должны храниться в централизованном хранилище или системе контроля версий, возможно, в той же самой, что и хранится код. И при конфигурировании приложения браться они должны именно оттуда. Соответственно, в случае необходимости изменить конфигурацию на сервере, ответственный сотрудник не заходит на него и меняет, например, соединение к БД, а меняет нужную переменную в хранилище, и оттуда она уже автоматически появляется на сервере.
Для переменных, специфичных для различных сред (Dev, Stage, Production) используются синонимы, подменяемые при развертывании на реальные значения. Примером такой подмены может служить технология transform, используемая для изменения конфигурационных файлов .NET приложений.
Привычки (Habits)
- Production first mindset — в первую очередь — производство (производственное мышление). Производство является сердцем любой организации, поставщика программного обеспечения, и лучшие из них признают, что производство должно быть главным приоритетом каждого члена команды, каждой роли, а не только IT. Промежуточные артефакты, такие как документация и pre-Prod окружение недостаточно. Высоко мотивированные исполнители всегда отслеживают жизненный статус, устраняют жизненные проблемы и первопричины, а также активно выявляют проблемы в производительности и работе ПО.
- Инфраструктура как гибкий ресурс — Infrastructure as flexible resource.
Бизнес значение
- Оптимизация ресурсов (Optimized Resources) — оптимизация ресурсов за счет более быстрого развертывания: нет необходимости вручную править конфигурации, особенно если серверов много.
- Ускорение поставки (Accelerate Delivery). Компьютер быстрее изменит и настроит конфигурацию.
Измеримость
- Скорость развертывания (Deployment Rate). Измеряется время развертывания приложения.
- MTTR – (Mean Time To Repair). Время на восстановление.
Непрерывное развертывание (Continuous Deployment)
Непрерывная развертывание – объединение Continuous Integration (непрерывной интеграции) и Continuous Delivery (непрерывной поставки). Это следующий шаг после успешной сборки и успешного прохождения автоматических тестов (и, возможно, установки галочки «сборка готова к развертыванию» ответственным человеком). Если вы уверены в ваших тестах, их наборе и покрытии, при их успешном выполнении запускается автоматическая установка на соответствующую среду, тестовую или продуктовую. Разница между Continuous Integration, Delivery, Deployment хорошо описана тут: http://blogs.atlassian.com/2014/04/practical-continuous-deployment/
Бизнес значение
- Оптимизация ресурсов (Optimized Resources ). Участие человека сведено к минимуму.
- Ускорение поставки (Accelerate Delivery). Машина быстрее все установит, чем человек.
Измеримость
- Частота поставки (Deployment Frequency). Измеряется количество установок в единицу времени (день, неделя, месяц, год).
- MTTR
- Доступность (Availability).
Управление релизами (Release Management)
Управление релизом заключается в том, что мы определяем формальные критерии, готова ли сборка к установке на соответствующую среду. Примером критериев, по которым сборка готова, и, если они выполняются, автоматически запускается поставка (Continuous Deployment) могут быть:
- DEV среда – сборка прошла без ошибок.
- STAGE среда – сборка была установлена на DEV среде и unit тесты прошли успешно.
- PROD среда – сборка прошла тестирование на STAGE среде, есть не более 5% minor багов, major багов нет, QA Lead и Dev Lead поставили Confirm билду о готовности к PROD среде.
Полезная ссылка: Управление релизами в Visual Studio 2013.
Бизнес значение
- Оптимизация ресурсов (Optimized Resources). Ресурсы, требуемые для определения готовности сборки (и её установки) всегда известны и их можно оптимизировать.
- Ускорение поставки (Accelerate Delivery). Мы быстрее и штатно (по строго определенным правилам) можем определить, готова ли сборка к поставке.
Измеримость
- Частота поставки (Deployment Frequency).
- MTTR
- Доступность (Avaibility).
Управление конфигурациями (Configuration Management)
Управление конфигурациями (Configuration Management) — это детальная запись и обновление информации, описывающей ПО и оборудование предприятия. Такая информация обычно включает версии и апдейты, которые были применены к установленному ПО, а также местоположение и сетевые адреса оборудования. ©
Здесь к формальному определению добавить особо и нечего. Все должно быть записано и подсчитано.
Бизнес значение
- Faster Detection & Remediation – более быстрое определение проблемы и восстановление.
- Оптимизация ресурсов (Optimized Resources).
- Большая гибкость.
Измеримость
- MTTD
- MTTR
- Доступность
Нагрузочное тестирование (Load Testing)
Нагрузочное тестирование (load testing) — подвид тестирования производительности, сбор показателей и определение производительности и времени отклика программно-технической системы или устройства в ответ на внешний запрос с целью установления соответствия требованиям, предъявляемым к данной системе (устройству) Wiki
Часто происходит так, что, например, для web приложений, когда пользователь один (разработчик или тестировщик) страница быстро открывается у и хорошо реагирует на работу с ней. Но как только изменения попадают на продуктовый сервер, и эту же страницу начинают смотреть сотни, тысячи человек одновременно, страница долго грузится и перестаёт реагировать.
Проводя нагрузочное тестирование мы и определяем наличие проблем на раннем этапе, еще до попадания проблемной сборки на продуктовый сервер. Нагрузочное тестирование реализуется генерацией большого потока запросов к серверу и анализа поведения сервера.
Бизнес значение
- Увеличение качества поставки (Improve deployment quality). Мы всегда можем быть уверены, что устанавливаемая сборка отвечает критериям производительности и не ухудшает их.
- Поиск «бутылочного горлышка» производительности (Find performance bottlenecks). Диагностирование, какое место является проблемным с точки зрения производительности и как её можно решить на ранней стадии, до жалоб клиентов.
- Cater for demand – удовлетворение заказчика от постоянного качества продукта.
- Поддержание качества приложения (Maintain application quality).
Измеримость
- Availability – доступность приложения.
- MTTD
- MTTR
Мониторинг быстродействия приложения Application Performance Monitoring
Мониторинг быстродействия приложения (application performance management) – это мониторинг и управление быстродействием и доступностью ПО. APM стремится выявлять и диагностировать проблемы быстродействия комплексно, для поддержания ожидаемого уровня обслуживания Wiki
Нагрузочное тестирование выявляет многие проблемы еще до того, как сборка попала на продуктовые сервера и с ней начали работать клиенты. Но, к сожалению, не всегда удается предугадать как действия пользователей, так и влияние разницы в ресурсах серверов на тестовой и продуктовой средах. Поэтому необходимо мониторить состояние и работу приложения на продуктовой среде. Этому и служит мониторинг быстродействия приложения.
Бизнес значение
- Faster Detection & Remediation- более быстрое определение проблемы и восстановление. Мы быстрее узнаем об узких местах, возникший в продуктовой системе.
- Optimized Resources – оптимизация ресурсов. Можем перераспределить вычислительные ресурсы со служб, где они мало задействованы, на загруженные службы.
- More Resilience – большая гибкость. То же самое, что и в предыдущем пункте: балансировка нагрузки.
Измеримость
- MTTD
- MTTR
- Availability
Надеюсь, данная статья дала вам представление, что такое DevOps и что нужно сделать для улучшения жизни developers, operations и business.

