Наверно, в мире данных нет подобного феномена настолько неоднозначного понимания того, что же такое Hadoop. Ни один подобный продукт не окутан таким большим количеством мифов, легенд, а главное непонимания со стороны пользователей. Не менее загадочным и противоречивым является термин "Big Data", который иногда хочется писать желтым шрифтом(спасибо маркетологам), а произносить с особым пафосом. Об этих двух понятиях — Hadoop и Big Data я бы хотел поделиться с сообществом, а возможно и развести небольшой холивар.
Возможно статья кого-то обидит, кого-то улыбнет, но я надеюсь, что не оставит никого равнодушным.

Демонстрация Hadoop пользователям
Начнем с истоков.
Первая половина 2000х, Google: мы сделали отличный инструмент — молоток, он хорошо забивает гвозди. Этот молоток состоит из ручки и бойка, но только мы с вами им не поделимся.
2006 год, Дуг Кайтинг: привет, народ, я тут сделал такой же молоток, как у Google и он действительно хорошо забивает гвозди, к слову сказать, я тут попробовал забивать им небольшие шурупы и вы не поверите, он более-менее справился с этим.
2010 год, Пол 30 лет: Парни, молоток работает, даже больше, он отлично забивает болты. Конечно, отверстие надо немного подготовить, но инструмент очень перспективный.
2012 год, Пол 32 года: Оказывается молотком можно рубить деревья, конечно, это немного дольше, чем топором, но он, мать его, работает! И за все за это мы не заплатили ни копейки Так же мы хотим построить с помощью молотка небольшой дом. Пожелайте нам удачи.
2013 год, Дуг: Мы оснастили молоток лазерным прицелом — теперь можно его метать, встроенный нож позволит вам более эффективно рубить деревья. Все бесплатно, все ради людей.
2015 год, Дэн, 25 лет: я кошу траву молотком… каждый день. Это немного сложно, но мне, черт возьми, нравится, мне нравится работать руками!
Если действительно разобраться и копнуть немного глубже, то Google, а потом и Дуг сделали инструмент(и далеко не идеальный, как призналось Google, спустя несколько лет), для решения конкретного класса задач — построение поискового индекса.
Инструмент получился неплохим, но есть одна проблема, в прочем, обо всем по порядку.
В начале 2012 года начался агрессивный тренд — "эпоха big data".
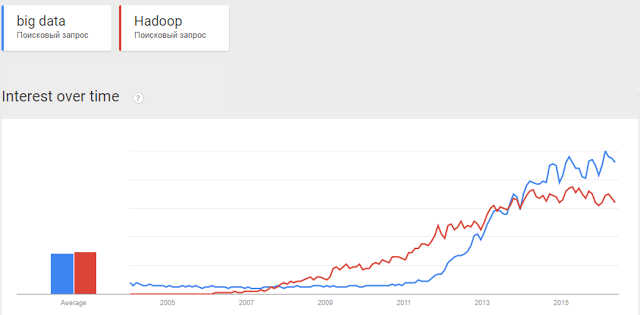
Именно с этого момента начали появляться бесполезные статьи и даже книги в стиле "Как стать big data company" или "Большие данные решают все". Ни одна из конференций больше не обходилась без рассуждений о том, "с какого терабайта начиналась big data" и повторяющихся историй о том, как "одна компания была почти на грани дефолта, но таки перешла на большие данные и она просто порвала рынок". Вся это пустая болтовня подкармливалась грамотным маркетингом от компаний, которые продавали поддержку на все это — спонсировались хакатоны, семинары и много-много всего.
В конечном итоге у большого количества людей сложилась конкретная картина мира, в которой традиционные решения — это медленно, это дорого, да и как минимум, это больше не модно.
Прошло уже много лет, но до сих пор я вижу обсуждения и статьи с заголовками "Map Reduce: first steps" или "Big Data: What Does it Really Mean?" на профессиональных ресурсах.
Hadoop как средство для индексирования
И так, что же все-таки такое Hadoop? В общих словах это файловая система HDFS и набор инструментов для обработки данных.
Все же этот блог технический, позволю себе вот такую вот картинку:
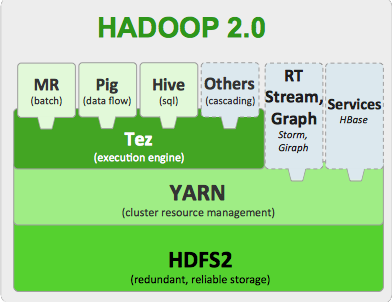
Компоненты Hadoop 2
Все это размазано по кластеру из "дешевого железа" и по мнению маркетологов должно в мановение ока завалить вас деньгами, которые будут приносить "большие данные".
Крупные интернет-компании, например Yahoo, в свое время, оценили Hadoop, как средство обработки больших объемов информации. Используя MapReduce, они могли строить поисковые индексы на кластерах из тысяч машин.
Надо сказать, тогда это было действительно прорывом — Open Source продукт умеет решать задачи такого класса и все это бесплатно. Yahoo сделало ставку на то, что возможно в будущем им бы не пришлось выращивать специалистов, а набирать со стороны уже готовых.
Но я не знаю когда первая обезьяна спустилась с дерева, взяла палку и начала использовать MapReduce для аналитики данных, но факт остается фактом, MapReduce начал реально появляться там, где это совершенно не нужно.
Hadoop MapReduce как средство для аналитики
Если у вас одна большая таблица, например, логи пользователей, то MR с натяжкой мог бы сгодиться для подсчета количества строк или уникальных записей. Но у этого фреймворка были фундаментальные недостатки:
Каждый шаг MapReduce порождает большую нагрузку на диски, что замедляет общую работу. Результаты работы каждого этапа сбрасываются на диск.
Инициализация "воркеров" занимает относительно большое время, что приводит к большим задержкам, даже для простых запросов.
Число "маперов" и "редьюсеров" постоянно во время выполнения, ресурсы делятся между этими группами процессов и если, например, маперы уже прекратили свою работу, то ресурсы редьюсерам уже не освободятся.
Все это более-менее эффективно работает на простых запросах. Операции JOIN больших таблиц будут работать крайне не эффективно — нагрузка на сеть.
Не смотря на весь этот комплекс проблем, MapReduce заслужил большую популярность в области анализа данных. Когда новички начинают свое знакомство с Hadoop, первое что они видят — MapReduce, "ну ок" — говорят они, — "надо изучать". По факту инструмент для аналитики бесполезен, но маркетинг сыграл злую шутку с MR. Интерес пользователей не только не угасает, но и подпитывается новичками(я пишу эту статью в июне 2016).
Для анализа заинтересованности в технологии со стороны бизнеса я решил использовать HeadHunter.ru как основную площадку поиска предложений по работе.
И еще можно встретить такие интересные вакансии на HH.ru по ключевым словам MapReduce:

На момент написания статьи было 30 вакансий только в Москве, и это от уважаемых и успешных фирм. Сразу скажу, что я не анализировал глубоко эти предложения, но позитивная динамика все же имеется, около года назад подобных предложений было больше.
Конечно, люди размещавшие вакансию могли просто написать, что попало и, возможно, HeadHunter это не лучшее средство для подобной аналитки, но более подходящих инструментов измерения заинтересованности бизнеса я найти не смог.
Spark как средство для аналитики
Конечно, умные люди сразу поняли, что c MR ловить нечего и придумали Spark, который кстати так же живет под крылом ASF. Spark — это MR на стероидах и как говорят разработчики быстрее MapReduce в более чем 100 раз.
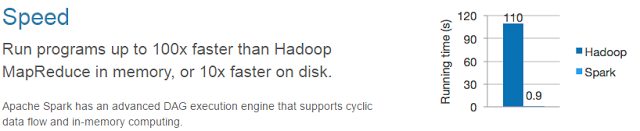
Сферический Spark в вакууме быстрее MapReduce
Spark хорош тем, что лишен перечисленных недостатков MR.
Но мы уже выходим на другой уровень и недостатки снова появляются:
Хардкод и усердный код на Java превращает простые запросы в месиво, которое невозможно будет читать в будущем. Поддержка SQL пока слабая.
Нет стоимостной оптимизации. С этой проблемой можно столкнуться при соединении таблиц.
Spark не понимает, как данные лежат в HDFS. Это хоть и MPP-система, но при соединении больших таблиц возникает ситуация, когда соединяемые данные находятся на разных узлах, что приводит к нагрузке на сеть.
Хотя в целом Spark штука годная, но возможно его убьет рынок труда, так как искать дорогих специалистов на Java или Scala, которые будут хардкодить вам аналитику очень и очень тяжело, особенно если вы no-name-company(произносить с особым пафосом, если работаете в такой).
Так же вместе со Spark зародилось интересное решение — Spark Streaming и, возможно, это будет действительно таким "долгоиграющим" решением.
Spark штука простая, надежная и его можно развернуть без Hadoop.
Поживем увидим.
Предложение по вакансиями немного лучше чем по MapReduce, они более зрелые и похоже их писали плюс-минус понимающие люди

Количество подобных предложений — 56 штук.

А теперь несколько мифов о Hadoop и BigData
Миф 1. Hadoop — это бесплатно
В наши дни мы использует очень много OpenSource продуктов и даже не задумываемся о том, почему мы за них не платим. Конечно, бесплатный сыр бывает только в мышеловке и платить, в конце концов, приходится, особенно за Hadoop.
Hadoop и все что с ним связано, активно позиционируется маркетологами под флагами бесплатности, мира и братства. Но в действительности, использовать собственную сборку Hadoop рискнут не многие — продукт достаточно сырой и до сих пор многими непонятный.
Компании придется нанимать дорогих специалистов, при этом задачи они будут решать дольше и усерднее. В конце концов вместо того, что бы решать задачи обработки данных, сотрудники будут решать проблемы латания дыр в сыром софте и построению костылей.
Конечно, речь не касается других зрелых OpenSource продуктов, типа MySQL, Postgres и т.п., которые активно используются в боевых системах, но даже тут, множество компаний пользуется платной профессиональной поддержкой.
Прежде чем решать, нужен ли вам бесплатный продукт, посчитайте, так ли он бесплатен. Возможно, с вашими задачами по сбору зерна с полей, с одинаковым успехом справится и вчерашний студент на современном комбайне и группа дорогих Java-кодеров, с бесплатными молотками-серпами.
Ок, Hadoop, это не бесплатно, допустим, но Hadoop работает на дешевом железе! И снова мимо. Hadoop хоть и работает на дешевом железе, для быстрого и надежного решения задач вам все равно потребуются нормальные сервера — на "десктопах" это работать не будет. Для годной работы Hadoop потребуется железо такого же класса, как и для работы любых других аналитических MPP-систем. По рекомендации Cloudera в
зависимости от задач необходимо:
- 2 CPU c 4-8-16 Ядрами
- 12-24 JBOD дисков
- 64-512GB of RAM
- 10 Gbit Net
Прошу заметить, что RAID отсутствует, но избыточность Hadoop на уровне софта требует примерно такого же количества дисков.
Миф 2. Hadoop для обработки неструктурированной информации.
Другой не менее примечательный миф говорит нам о том, что "Hadoop необходим для обработки неструктурированной информации", а такой неструктурированной информацией как раз и является Big Data :-). Но давайте разберемся сначала, что же такое неструктурированная информация.
Таблицы — это точно структурированная информация, это бесспорно.
А вот JSON, XML, YAM — называют полу-структурированной информацией.
Но и такие форматы имеют структуру, только не такую явную как структура таблиц.
Другая актуальная тема — логи, по мнению популяризаторов BigData — не имеют структуры.

На самом деле структура есть, логи вполне себе нормально записываются в таблицы и обрабатываются без MapReduce
Твиттер:

На самом деле, структура есть почти у всех данных, которые нам могут пригодиться. Она может быть разрозненная, не удобная для обработки, но она есть.
Даже такие данные, например, видео или аудио информация могут быть представлены в виде виде структуры которую можно распределить на большое количество серверов и обрабатывать.
Видео-файлы:

Скорее всего, там, где вы работаете, нет неструктурированной информации. И ваша информация может быть разрозненной и "грязной", но какая-то структура у нее все равно имеется. В таком случае, у вас действительно проблемы и нужно решать в первую очередь их.
Конечно, есть информация, которую нельзя эффективно "размазать" по большому кластеру, например генетическая информация или огромный файловый архив, но таких кейсов чрезвычайно мало и для "бизнес-аналитики" они не интересны, такие задачи решаются другими средствами совершенно на другом уровне(если знаете, расскажите).
Если вы знаете какие-то действительно неструктурированные источники информации, которые нельзя просто так обработать в распределенном кластере, пожалуйста, пишите в комментариях.
Миф 3. Любая проблема решается через технологии Big Data
Еще один интересный термин навязанный обществу — "технологии Big Data". Конечно, никакого логического определения того, что такое Big Data конечно нет, тем более нет определения "технологий Big Data".
Принято считать, что все, что связано с Hadoop — это "технологии Big Data"

Но Hadoop и все что с ним связано, очень хорошо замаскированный, аккуратный суперфункциональный швейцарский нож-молоток. Им можно рубить деревья, косить траву, забивать болты. Он справляется со всеми задачами, но вот только когда дело доходит до решения конкретной задачи, особенно когда нужно сделать это качественно, такой швейцарский нож-молоток только усложнит вам жизнь.
Impala, Dill, Kudu — новые игроки
Конечно, еще более умные люди, чем все остальные, посмотрели на весь этот бардак и решили создать свой лунапарк.
Три зверька Impala, Drill и Kudu появились примерно одновременно и не совсем давно.
Это такие же МРР-движки поверх HDFS как Spark и MR, но разница между ними такая же, как между едой и закуской — огромная. Продукты так же находятся под крылом, многоуважаемого ASF. В принципе, всеми тремя проектами можно пользоваться уже сейчас, не смотря что они на стадии так называемой "инкубации".
Кстати, Impala и Kudu находятся под крылом Cloudera, а Drill вышел из компании Dremio.
Из всего зверинца я бы выделил Apache Kudu как самый интересный инструмент из представленных с четким и зрелым roadmap.
Преимущества Kudu следующие:
Kudu понимает, как лежат данные в HDFS и понимает как их правильно класть в HDFS, чтобы оптимизировать будущие запросы. Директива distributed by.
Только SQL и никакого хардкода.
Из явных недостатков можно выделить отсутствие Cost-based оптимизатора, но это лечится и возможно в будущих релизах мы Kudu предстанет во всей красе. Все эти 3 продукта плюс-минус примерно одинаковые, по этому, рассмотрим архитектуру на примере Apache Impala:

Как мы видим, имеются экземпляры СУБД — Impala, которые уже работает с данными на своей конкретной ноде. При подключении клиента к одному из узлов он становится управляющим. Архитектура достаточно похожа на Vertica, Teradata(верхнеуровнево и очень приближенно). Основная задача при работе с такими системами сводится к тому, чтобы правильно "размазать" данные по кластеру, чтобы в дальнейшем эффективно с ними работать.
При всех своих достоинствах, разработчики пиарят свои системы как "федеравтивные", то есть: берем таблицу Kuda, связываем ее с плоским файлом, все это смешиваем с Postgres и приправляем MySQL. То есть у нас появляется возможность работать с гетерогенными источниками как с обычными таблицами или нереляционными структурами(JSON) как с таблицами. Но у такого подхода есть своя цена — оптимизатор не понимает статистику внешних источников, так же такие внешние таблицы становятся узким горлышком при выполнении запросов, так как, по сути, работают в "один поток".
Другой важный момент — необходимость HDFS. HDFS в такой архитектуре превращается в бесполезный аппендикс, который только усложняет работу системы — лишний слой абстракции, который имеет свои накладные расходы. Так же, HDFS может быть развернута поверх не совсем эффективных или не правильно настроенных файловых систем, что может привести к фрагментации файлов данных и потери производительности.
Конечно, HDFS можно использовать как помойку всего и вся, скидывая в нее все нужное и ненужное. Такой подход последнее время называется "Data Lake", но не стоит забывать, что анализировать неподготовленные данные будет сложнее в будущем. Последователи такого подхода аргументируют преимущества тем, что данные, возможно, и не придется анализировать, следовательно, нет необходимости тратить времени на их подготовку. В общем, решать, по какому пути идти, все же, вам.
Никаких предложений по работе и интересов компаний в сторону Kudu-подобных продуктов нет, а зря.
Немного маркетинга
Вы, наверно, заметили явный тренд в сторону того, что весь этот цирк в области аналитики данных движется в сторону традиционных аналитических MPP-систем (Teradata, Vertica, GPDB и т.п.).
Все аналитические MPP-системы развиваются в одном направлении, только при этом две разные группы идут к этому с разных сторон.
Первая группа — идет по пути "шардирования" традиционных SQL СУБД.
Вторая группа — идет по родословной от MR и HDFS.
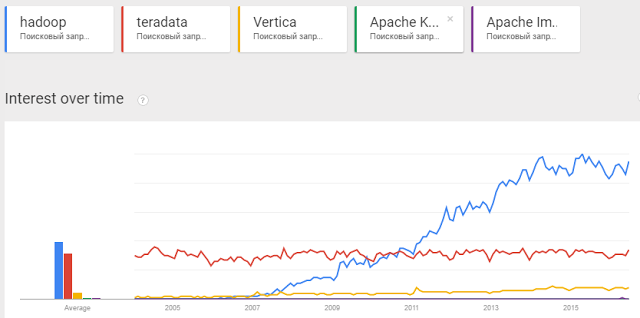
Пользователи проявляют интерес к слову Hadoop
Лавинообразный рост Hadoop конечно обусловлен очень грамотным маркетингом со стороны компаний, продающих эти решения.
Компании смогли вырастить в умах людей идею того, что Hadoop бесплатен, он прост и быстр и легок, а еще… нет бога кроме Hadoop.
Напор был таким сильным, что даже Teradata не смогла совладать с собой и вместо того, что бы самой формировать рынок, начала продавать решения на базе Hadoop и нанимать специалистов. Не говоря уже о других игроках рынка, которые дружно родили поделия под названием "AnyDumbSoft Big Data Edition", в большинстве случаев использующие стандартные коннекторы к HDFS.
Тренду поддался даже Oracle, выпустивший "Big data appliance" или "Golden Gate for Big data". Первый продукт — это просто готовая железка с "золотым" CDH от Cloudera, а в продукт номер два просто добавлены Java-коннекторы для Kafka(брокер сообщений), HBase и остального зоопарка. Сделать это мог любой пользователь самостоятельно.
Big Data больного человека
К сожалению, это тренд, это мейнстрим, который сметет любую стабильную компанию, если она рискнет пойти против течения. Кстати, я отчасти тоже рискую быть закиданным помидорами, освещая данную тему.
Apache HAWQ (Pivotal HDB).
Pivotal пошел дальше всех. Они взяли традиционный Greenplum и натянули его на HDFS. Весь движок обработки данных остался за Postgres, но сами файлы данных хранятся в HDFS. Какой-то практической целесообразности в этом мало.
Вы получаете в распоряжение такой же Greenplum, с более сложным администрированием, но продают вам его и рекламируют как Hadoop.
Apache HAWQ очень похож на Apache Kudu.
Cloudera Distributed Hadoop
Cloudera одна из первых компаний начавших монетизировать Hadoop и именно там работает Дуг, который изобрел Hadoop.
Cloudera в отличие от других игроков, не подстраивается под рынок, а сама делает его. Грамотный пиар и маркетинг позволили ей завоевать достаточно лакомый кусочек рынка — сейчас в списке клиентов более 100 крупных и известных компаний.
В отличие от других подобных компаний, Cloudera не просто продает зоопарк из уже готовых компонентов, но и сама активно участвует в их разработке.
По цене CDH выходит немного дешевле Vertica/Greenplum.
Но несмотря на большое количество историй успеха на сайте Cloudera, есть одна маленькая проблема — Kuda, Impala — немного сырые, продукты на стадии инкубации. Даже когда они созреют, этим системам нужно будет пройти долгий путь, чтобы обрасти всем необходимым функционалом Vertica или хотя бы Greenplum, а это не год и не два, пока же CDH можно оставить для хипстеров.
Так же надо отдать должное маркетологам Cloudera, сумевшим встряхнуть рынок.
Будущее Hadoop
Позволю себе пованговать и представить, что будет со стеком Hadoop через 5 лет.
MapReduce будет использоваться только в очень ограниченном количестве задач, проект скорее всего выпилят из общего стека, либо о нем забудут.
Появятся первые дистрибутивы CDH уже с частичным отказом от использования HDFS. В таком случае, файлы таблиц будут храниться на обычной файловой системе, но у нас будет небольшая помойка для хранения сырых данных.
Можно провести аналогию с Flex Zone в Vertica — свалка, в которую можно кидать все что угодно и обрабатывать далее по мере необходимости или забывать.
На самом деле иметь такую помойку не только удобно, но мы будем просто вынуждены иметь ее. Объемы дискового пространства растут непропорционально быстро по сравнению с производительностью процессоров. Когда количество узлов в кластере увеличивают в целях производительности мы увеличиваем и объем дискового пространства(больше необходимого). В следствие чего, всегда будет большое количество незанятого дискового пространства, в котором удобно хранить данные к которым обращение будет либо очень редкое, либо мы к ним не обратимся никогда.
Зоопарк имени Hadoop вряд ли оправдает кредит доверия, который предоставили ему пользователи, но надеюсь, что не уйдет с рынка.
Хотя бы, из интересов конкуренции.

Будут ли у Hadoop проблемы через 5 лет?
Что будет со Spark? Возможно, многие будут использовать его как движок для распределенной предобработки и подготовки данных в реальном времени — Spark Streaming, но и эта ниша тоже активно занимается другими игроками (Storm, производители ETL)
Будущее Vertica, Greenplum.
Vertica будет полировать свою интеграцию с HDFS, наращивать функционал и Vertica скорее всего не пойдет в OpenSource — сейчас продукт и так хорошо продается.
Greenpum сделает свой аналог Flex Zone, путем слияния кода с HAWQ, либо сам станет non-HDFS частью HAWQ, в конце концов, кого-то мы потеряем.
Каких то новых игроков на рынке аналитических MPP-систем, скорее всего, ожидать не придется. Открытие исходников Greenplum ставит целесообразность использования таких СУБД как Postgres-XL, как минимум, под сомнение.
Принципиальных изменений архитектуры в этих продуктах мы вряд ли увидим, изменения будут в улучшении имеющегося функционала.
Будущее Postgres-XL и подобных
Postgres-XL могла бы быть прекрасным MPP инструментом для аналитики больших объемов данных, если бы немного бы отошла от всего того, что дал ей Postgres. К сожалению СУБД не умеет работать с Column Store-таблицами, в ней нет нормального синтаксиса для управления партициями, а так же она имеет стандартный оптимизатор Postgres со всеми вытекающими.
Например, в Greenplum есть cost-based оптимизатор, заточенный для аналитических запросов. Это та штука, без которой жизнь аналитика и разработчика очень сильно усложнится.
Но ставить крест на таком замечательном продукте тоже не стоит, Postgres развивается, в 9.6 уже появилась многопоточность и, возможно, умельцы прикрутят Column Store и GPORCA в Postgres-XL.
Будущее Teradata, Netezza, SAP и подобных
В любом случае рынок аналитических систем будет расти и в любом случае клиенты на эти продукты будут. Будут эти решения продавать на полях для гольфа или на конференциях "Big Data — технология будущего" я не знаю.
Но скорее всего, этим игрокам придется уйти от текущей бизнес-модели программно-аппаратных средств и взглянуть в сторону Only-Software-продуктов.
Запрыгнуть в призрачный поезд "Big Data" у них не получится, но это и не нужно, ибо поезд мнимый и они отчасти сами его и придумали.
Будущее Redshift, BigQuery и облачных сервисов для аналитики
На первый взгляд, облачные сервисы выглядят очень и очень привлекательно: не нужно заморачиваться покупкой оборудования и лицензиями. Подразумевается, что при желании можно будет с легкостью отказаться от сервиса или перейти в другой.
С другой стороны, аналитика — проект долгосрочный, а разрабатывать аналитическое хранилище, абстрагируясь от конкретной технологии очень и очень сложно. Поэтому в будущем перейти безболезненно из одного облачного хранилища в другое будет сложно.
Клиенты у таких игроков точно будут, но очень специфичные — стартапы и небольшие компании.
Резюме: Я не коснулся большого количества продуктов из зверинца ASF, которые продают под соусом Big Data (Storm, Sqoop и т.п.), так как пока к ним мало интереса как с моей стороны, так и рынка в целом. Поэтому, буду рад любым комментариям, касаемым этих продуктов.
Также я не коснулся темы кликстрим-аналитики, которая набирает обороты. Надеюсь, опишу это в следующих статьях.
Второе резюме: Сложно не пойти на поводу у "творцов" рынка при выборе решений в области обработки и анализа данных. До сих пор пыль не осела и мы еще будем сталкиваться с компаниями, продающими "счастье" и мы будем сталкиваться с продуктами, позиционируемыми как "универсальное лекарство" от Big Data головного мозга.
Я постарался показать, куда развивается Hadoop, да и вся индустрия обработки данных. Попытался развеять несколько мифов прод Big Data и постарался представить в каком направлении будет развиваться вся область. Надеюсь, получилось — узнаем об этом уже через несколько лет.
В конце концов, рынок развивается и становится более доступным для потребителя, появляются новые продукты, появляются новые либо перерождаются старые технологии.

