Под реверс-инжинирингом, в данном контексте, я понимаю восстановление исходной схемы сообщений наиболее близкие к оригиналу, используемому разработчиками. Существует несколько способов получить желаемое. Во-первых, если у нас есть доступ к клиентскому приложению, разработчики не позаботились о том чтобы скрыть отладочные символы и линковаться к LITE версии библиотеки protobuf, то получить оригинальные .proto-файлы не составит труда. Во-вторых, если же разработчики используют LITE сборку библиотеки, то это конечно усложняет жизнь реверсеру, но отнюдь не делает реверсинг бесполезным занятием: при определённой сноровке, даже в этом случае, можно восстановить .proto-файлы достаточно близкие к оригиналу.
В данной статье я хотел бы описать некоторые техники реверса ptobobuf сообщений, благодаря которым появился мой проект protodec. Отмечу, что все сказанное относиться к формату кодирования protobuf сообщений версии 2 (3 версия пока не поддерживается, packed поля тоже).
Для начала я создам объекты для исследования. Нам понадобятся 2 файла:
Сохраняем их и собираем все вместе. Если вы не знаете, что такое protoc, то Вам нужно прочесть введение в библиотеку Protobuf для вашего языка программирования.
Удаляем или закомментируем вторую строку файла addressbook.proto и выполняем команду:
После выполнения вышеупомянутых команд мы имеем два исполняемых файла tut.lite.exe и tut.exe, с LITE и полной сборкой библиотеки libprotobuf соответственно. Обе программы делают одно и тоже: создаётся protobuf сообщение, которое выводится в std::cout. Так же у нас появилось два бинарных файла с именами A и B. Первый сгенерирован lite версией, второй — полной версией программы. Содержимое их идентично. На скриншоте ниже можно увидеть бинарное представление этого сообщения и его текстовый вид:
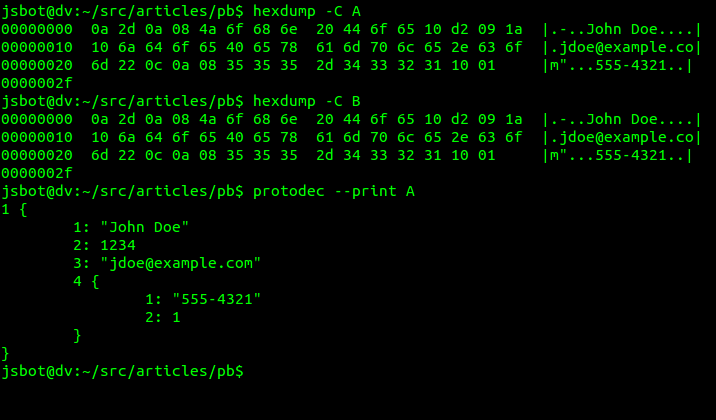
Удаляем addressbook.proto и попытаемся его восстановить.
Глянем содержимое файла adressbook.pb.cc, сгенерированного ранее утилитой protoc. Нас должна заинтересовать функция protobuf_AddDesc_addressbook_2eproto. Одним из первых действий в ней — вызов функции ::google::protobuf::DescriptorPool::InternalAddGeneratedFile, первый аргумент которой и есть Descriptor protobuf сообщение с информацией о структуре оригинальных сообщений.
В ней сохранена информацией о перечислениях, списке импорта, сообщениях, имена и типы данных их полей и т.д. Формат не является секретом и поставляется вместе с исходным кодом; его можно глянуть в google/protobuf/descriptor.proto. Эти данные используется при рефлексии, для отладочного вывода содержимого сообщений и т.д.
Утилита protodec выполняет поиск Descriptor данных в бинарном файле и умеет сохранять восстановленные из них .proto-файлы. Для этого нужно запустить команду:
В ответ увидим что-то такое:
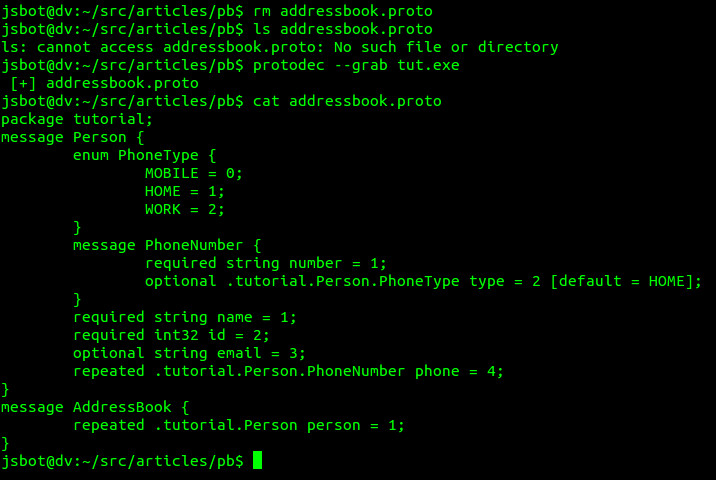
То есть, в итоге мы получили почти оригинал исходного .proto-файла.
Если к приложению нет доступа (допустим, оно работает где-то на сервере), то и к Descriptor данным добраться будет проблематично. То же самое относится, если приложение собрано с LITE оптимизацией: рефлексия не используется, поэтому и Descriptor описание .proto-файлов не генерируется на этапе компиляции, а следовательно восстановить оригинальные .proto-файлы методом упомянутым ранее у нас не получится. В этом случае можно попробовать анализировать содержимое protobuf сообщений. Отмечу, что они должны быть 100% иметь одинаковую структуру (корневое сообщение должно у них совпадать). Таких сообщений нам понадобятся как можно больше; чем больше в них данных, тем лучше результат получим в итоге.
Программа protodec может восстановить схему указанного protobuf сообщения с их типами, загруженного из файла. Для этого запустим команду:
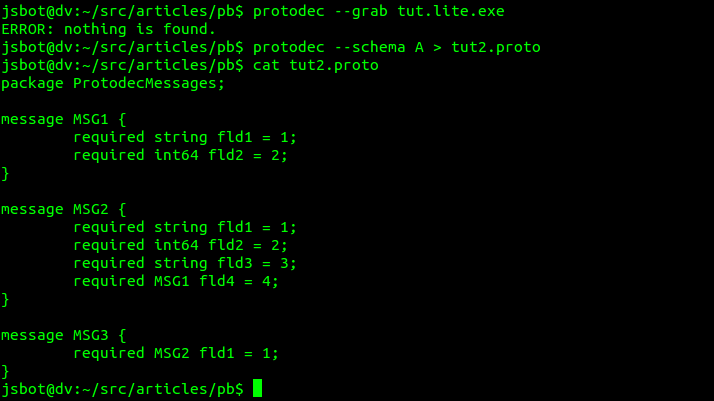
Этот вывод означает, что в данном protobuf сообщении (загруженном из файла A), было обнаружено 3 сообщения. Если мы взглянем на оригинальный addressbook.proto, то несомненно угадывается общее: MSG1 это Person::PhoneNumber, MSG2 это Person, ну а MSG3 это AddressBook. Опишу бросающиеся в глаза несоответствия:
Имена, как полей так и сообщений, генерируются автоматически, эти метаданные из тела самого protobuf сообщения «достать» невозможно, т.к. их там попросту нет. В таком случае можно постепенно переименовывать сообщения и поля, когда назначение их становится более-менее понятно из контекста исследуемых сообщений. Так же, в самом приложении, в списке экспорта иногда можно обнаружить данную информацию. Для этого нам понадобится любая утилита умеющая это делать, например, IDA. Вот, здесь мы выудили имена и порядок полей для сообщения tutorial::Person, которое имеет 4 поля:

Делаем то же самое для остальных сообщений и в итоге получаем практически оригинальный .proto-файл.
В итоге у нас получился приблизительно такой .proto-файл:
Напишем небольшую программу, чтобы проверить, что наша восстановленная схема может редактировать оригинальные сообщения.
Компилируем и запускаем:

В данной статье я хотел бы описать некоторые техники реверса ptobobuf сообщений, благодаря которым появился мой проект protodec. Отмечу, что все сказанное относиться к формату кодирования protobuf сообщений версии 2 (3 версия пока не поддерживается, packed поля тоже).
Подготовка
Для начала я создам объекты для исследования. Нам понадобятся 2 файла:
addressbook.proto
package tutorial; option optimize_for = LITE_RUNTIME; message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; } message AddressBook { repeated Person person = 1; }
tut.cpp
#include <iostream> #include <cassert> #include <string> #include "addressbook.pb.h" int main() { GOOGLE_PROTOBUF_VERIFY_VERSION; tutorial::AddressBook book; tutorial::Person * person = book.add_person(); person->set_id(1234); person->set_name("John Doe"); person->set_email("jdoe@example.com"); tutorial::Person_PhoneNumber * phone = person->add_phone(); phone->set_number("555-4321"); phone->set_type(tutorial::Person_PhoneType_HOME); std::string data = book.SerializeAsString(); assert(!data.empty()); std::cout.write(&data[0], data.size()); google::protobuf::ShutdownProtobufLibrary(); }
Сохраняем их и собираем все вместе. Если вы не знаете, что такое protoc, то Вам нужно прочесть введение в библиотеку Protobuf для вашего языка программирования.
protoc --cpp_out=. addressbook.proto && g++ addressbook.pb.cc tut.cpp `pkg-config --cflags --libs protobuf` -s -o tut.lite.exe && ./tut.lite.exe > A
Удаляем или закомментируем вторую строку файла addressbook.proto и выполняем команду:
protoc --cpp_out=. addressbook.proto && g++ addressbook.pb.cc tut.cpp `pkg-config --cflags --libs protobuf` -o tut.exe && ./tut.exe > B
После выполнения вышеупомянутых команд мы имеем два исполняемых файла tut.lite.exe и tut.exe, с LITE и полной сборкой библиотеки libprotobuf соответственно. Обе программы делают одно и тоже: создаётся protobuf сообщение, которое выводится в std::cout. Так же у нас появилось два бинарных файла с именами A и B. Первый сгенерирован lite версией, второй — полной версией программы. Содержимое их идентично. На скриншоте ниже можно увидеть бинарное представление этого сообщения и его текстовый вид:
Удаляем addressbook.proto и попытаемся его восстановить.
Восстановление схемы сообщений из Descriptor данных исполнимого файла
Глянем содержимое файла adressbook.pb.cc, сгенерированного ранее утилитой protoc. Нас должна заинтересовать функция protobuf_AddDesc_addressbook_2eproto. Одним из первых действий в ней — вызов функции ::google::protobuf::DescriptorPool::InternalAddGeneratedFile, первый аргумент которой и есть Descriptor protobuf сообщение с информацией о структуре оригинальных сообщений.
// ... void protobuf_AddDesc_addressbook_2eproto() { static bool already_here = false; if (already_here) return; already_here = true; GOOGLE_PROTOBUF_VERIFY_VERSION; ::google::protobuf::DescriptorPool::InternalAddGeneratedFile( "\n\021addressbook.proto\022\010tutorial\"\332\001\n\006Person" "\022\014\n\004name\030\001 \002(\t\022\n\n\002id\030\002 \002(\005\022\r\n\005email\030\003 \001(" "\t\022+\n\005phone\030\004 \003(\0132\034.tutorial.Person.Phone" "Number\032M\n\013PhoneNumber\022\016\n\006number\030\001 \002(\t\022.\n" "\004type\030\002 \001(\0162\032.tutorial.Person.PhoneType:" "\004HOME\"+\n\tPhoneType\022\n\n\006MOBILE\020\000\022\010\n\004HOME\020\001" "\022\010\n\004WORK\020\002\"/\n\013AddressBook\022 \n\006person\030\001 \003(" "\0132\020.tutorial.Person", 299); ::google::protobuf::MessageFactory::InternalRegisterGeneratedFile( "addressbook.proto", &protobuf_RegisterTypes); Person::default_instance_ = new Person(); Person_PhoneNumber::default_instance_ = new Person_PhoneNumber(); AddressBook::default_instance_ = new AddressBook(); Person::default_instance_->InitAsDefaultInstance(); Person_PhoneNumber::default_instance_->InitAsDefaultInstance(); AddressBook::default_instance_->InitAsDefaultInstance(); ::google::protobuf::internal::OnShutdown(&protobuf_ShutdownFile_addressbook_2eproto); } // ...
В ней сохранена информацией о перечислениях, списке импорта, сообщениях, имена и типы данных их полей и т.д. Формат не является секретом и поставляется вместе с исходным кодом; его можно глянуть в google/protobuf/descriptor.proto. Эти данные используется при рефлексии, для отладочного вывода содержимого сообщений и т.д.
Утилита protodec выполняет поиск Descriptor данных в бинарном файле и умеет сохранять восстановленные из них .proto-файлы. Для этого нужно запустить команду:
protodec --grab tut.exe
В ответ увидим что-то такое:
То есть, в итоге мы получили почти оригинал исходного .proto-файла.
Восстановление схемы из байт сообщения
Если к приложению нет доступа (допустим, оно работает где-то на сервере), то и к Descriptor данным добраться будет проблематично. То же самое относится, если приложение собрано с LITE оптимизацией: рефлексия не используется, поэтому и Descriptor описание .proto-файлов не генерируется на этапе компиляции, а следовательно восстановить оригинальные .proto-файлы методом упомянутым ранее у нас не получится. В этом случае можно попробовать анализировать содержимое protobuf сообщений. Отмечу, что они должны быть 100% иметь одинаковую структуру (корневое сообщение должно у них совпадать). Таких сообщений нам понадобятся как можно больше; чем больше в них данных, тем лучше результат получим в итоге.
Программа protodec может восстановить схему указанного protobuf сообщения с их типами, загруженного из файла. Для этого запустим команду:
protodec --schema A
Этот вывод означает, что в данном protobuf сообщении (загруженном из файла A), было обнаружено 3 сообщения. Если мы взглянем на оригинальный addressbook.proto, то несомненно угадывается общее: MSG1 это Person::PhoneNumber, MSG2 это Person, ну а MSG3 это AddressBook. Опишу бросающиеся в глаза несоответствия:
- Поле MSG3.fld1 должно быть repeated. Проблема тут в том, что в оригинальном сообщении, в AddressBook.person всего лишь один элемент, а на бинарном уровне нельзя различить repeated поле в таком случае. Если бы в AddressBook.person, данных было хотя бы 2 элемента, то он бы определился верно. Именно поэтому нам нужно несколько сообщений данной схемы, с максимальной заполненностью;
- Некоторые required поля должны быть optional. Данная проблема так же решается анализом большого количества сообщений, благодаря которому можно понять где должно быть required поле, а где optional;
- Поле MSG2.fld2 должно быть int32, а оно int64. На низком уровне, в protobuf все целочисленные типы (int32, int64, uint32, uint64, sint32, sint64, bool, enum) хранятся как Varint. Затем можно понять из контекста, числа в этом поле будут ли они знаковыми или беззнаковыми, int64 выбран для того чтобы в него можно было сохранить максимально возможное целочисленное значение для используемого языка программирования.
Имена, как полей так и сообщений, генерируются автоматически, эти метаданные из тела самого protobuf сообщения «достать» невозможно, т.к. их там попросту нет. В таком случае можно постепенно переименовывать сообщения и поля, когда назначение их становится более-менее понятно из контекста исследуемых сообщений. Так же, в самом приложении, в списке экспорта иногда можно обнаружить данную информацию. Для этого нам понадобится любая утилита умеющая это делать, например, IDA. Вот, здесь мы выудили имена и порядок полей для сообщения tutorial::Person, которое имеет 4 поля:
Делаем то же самое для остальных сообщений и в итоге получаем практически оригинальный .proto-файл.
Проверка
В итоге у нас получился приблизительно такой .proto-файл:
tut2.proto
package ProtodecMessages; message PHONE { required string Number = 1; required int64 Type = 2; } message PERSON { required string Name = 1; required int64 Id = 2; required string Email = 3; required PHONE Phone = 4; } message ADDRESSBOOK { repeated PERSON Person = 1; }
Напишем небольшую программу, чтобы проверить, что наша восстановленная схема может редактировать оригинальные сообщения.
tut2.cpp
#include <iostream> #include <fstream> #include <string> #include <cassert> #include "tut2.pb.h" int main() { GOOGLE_PROTOBUF_VERIFY_VERSION; // читаем содержимое protobuf сообщения из std::cin std::string data; ProtodecMessages::ADDRESSBOOK book; while (std::cin.peek() != EOF) data.push_back((char)std::cin.get()); // все ли удачно распарсили? assert(book.ParseFromString(data)); assert(book.person_size() > 0); // изменяем сообщение ProtodecMessages::PERSON * person = book.mutable_person(0); person->set_email("fake@name.com"); person->set_id(4321); // выводим измененное сообщение в std::cout data = book.SerializeAsString(); assert(!data.empty()); std::cout.write(&data[0], data.size()); // Optional: Delete all global objects allocated by libprotobuf. google::protobuf::ShutdownProtobufLibrary(); }
Компилируем и запускаем:
protoc --cpp_out=. tut2.proto && g++ tut2.pb.cc tut2.cpp `pkg-config --cflags --libs protobuf` -o tut2.exe

