Многим компаниям требуются сервера с высокопроизводительной дисковой подсистемой большой емкости, которая достигается за счет использования большого количества высокопроизводительных дисков. Имеем случай, когда компания использовала решение из 10 HDD с интерфейсом SAS емкостью 600 GB, организованных в массив RAID 50 (полезная емкость массива 600*8=4800 GB). Данный RAID 50 представляет из себя комбинированный массив, который рассматриваем как два массива RAID 5, объединенных в массив RAID 0. Данное решение позволяет получить более высокую скорость записи на массив в сравнении с обычным RAID 5 с таким же количеством дисков-участников, потому что для формирования блока четности требуется меньшее число операций чтения с дисков участников (скоростью расчета самого блока четности можно пренебречь в силу того, что он представляет весьма малую нагрузку для современных RAID контроллеров). Также в RAID 50 в некоторых случаях отказоустойчивость будет выше, так как допустима потеря до двух дисков (при условии, что диски из разных массивов RAID 5, входящих в данный RAID). В рассматриваемом нами случае со слов системного администратора произошел отказ 2 дисков, которые привели к остановке RAID массива. Затем последовали действия системного администратора и сервисного отдела компании продавца сервера, которые не могут быть описаны в силу сбивчивых и противоречащих друг другу показаний.
В нашем случае диски пронумерованы представителем заказчика от 0 до 9 со словами: «именно в таком порядке они были использованы в массиве, и никто их местами не менял». Данное утверждение подлежит обязательной проверке. Также мы были поставлены в известность, что данный массив использовался в качестве хранилища для ESXi сервера, и на нем должно содержаться несколько десятков виртуальных машин.
Перед тем, как начать любые операции над дисками из массива, необходимо проверить их физическую целостность и исправность, а также создать копии и далее работать исключительно с копиями для безопасного проведения работ. При наличии серьезно поврежденных накопителей рассмотреть необходимость проведения работ по извлечению данных, то есть если серьезно поврежден только один накопитель, то необходимо выяснить посредством анализа массива, собранного из оставшихся дисков, содержал ли проблемный HDD актуальные данные, или им нужно пренебречь и получить недостающие данные за счет XOR операции над остальными участниками одного из RAID 5, в который входил данный диск.
Было выполнено создание копий, в результате которого выяснилось, что 4 накопителя имеют дефекты между LBA 424 000 000 и LBA 425 000 000, выражается это в виде нечитаемых нескольких десятков секторов на каждом из проблемных дисков. Непрочитанные сектора в копиях заполняем паттерном 0xDE 0xAD для того, чтобы потом была возможность идентификации пострадавших данных.
Первичный анализ подразумевает идентификацию RAID контроллера, к которому были подключены диски, точнее идентификацию расположения метаданных RAID контроллера, чтобы эти области не включать при сборке в массив.
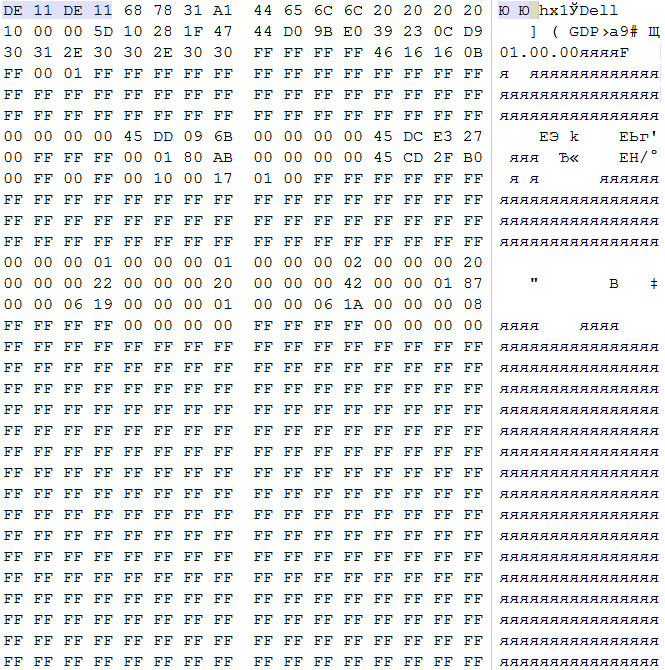
В данном случае в последнем секторе каждого из дисков обнаруживаем характерные 0xDE 0x11 0xDE 0x11 c дальнейшей пометкой бренда RAID контроллера. Метаданные данного контроллера располагаются исключительно в конце LBA диапазона, какие-либо буферные зоны в середине диапазона данным контроллером не используются. На основании этого и предыдущих данных следует вывод, что сбор массива должен начинаться с LBA 0 каждого из дисков.
Зная, что суммарная емкость массива более 2 TB, проводим поиск в LBA 0 каждого из дисков таблицы разделов (защитной MBR)

и GPT заголовка в LBA 1.
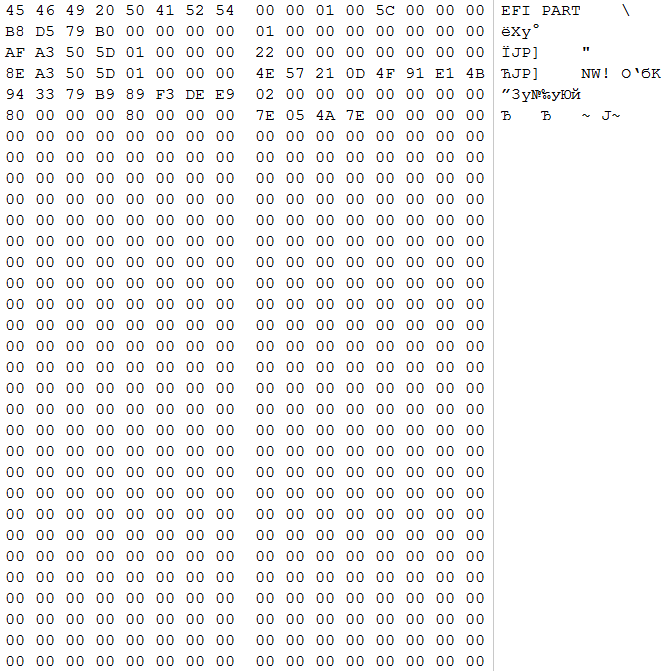
В этом случае данных структур не обнаружено. Данные структуры обычно становятся жертвами необдуманных действий обслуживающего сервер персонала, который не отрабатывал ситуации отказа системы хранения данных и не изучал особенностей работы конкретного RAID контроллера.
Для дальнейшего анализа особенностей массива необходимо произвести на одном из дисков поиск регулярных выражений монотонно возрастающих последовательностей. Это могут быть как таблицы FAT или достаточно большой фрагмент MFT, так и иные удобные для анализа структуры. Зная, что на данном массиве содержались виртуальные машины с ОС Windows, мы можем предположить, что внутри данных машин использовалась файловая система NTFS. На основании этого проводим поиск записей MFT по характерному регулярному выражению 0x46 0x49 0x4C 0x45 с нулевым смещением относительно 512-байтного блока (сектора). В нашем случае после LBA 2 400 000 (1,2GB) обнаруживается достаточно протяженный (более 5000 записей) фрагмент MFT. В нашем случае размер записи MFT стандартный и составляет 1024 байт (2 сектора).

Локализуем границы найденного фрагмента с записями MFT и проверим наличие фрагмента с записями MFT в этих границах на остальных дисках-участниках массива (границы могут чуть-чуть отличаться, но не более чем на размер блока, используемого в RAID массиве). В нашем случае наличие записей MFT подтверждается. Листаем записи с анализом номеров (номер DWORD располагается по смещению 0x2C). Анализируем количество блоков, где возрастание номера записи MFT происходит с изменением на единицу, на основании этого рассчитываем размер блока, используемого в данном RAID массиве. В нашем случае размер составляет 0x10000 байт (128 секторов или 64KiB). Далее выберем среди записей MFT какое-либо из мест, где записи MFT или результат их XOR операции симметрично располагаются на всех дисках-участниках и составим матрицу с номерами записей, с которых начинаются блоки массива с удвоенным количеством строк.
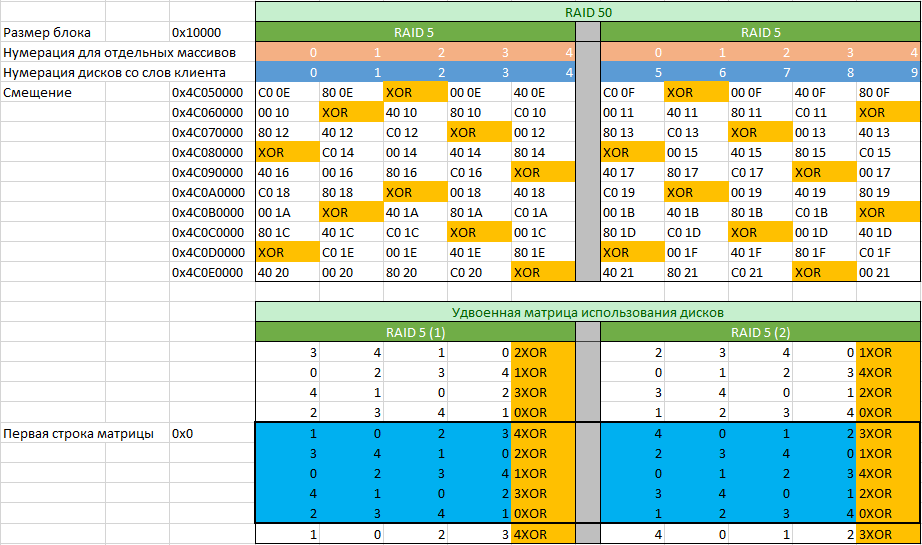
По номерам записей определим какие из дисков входят в первый RAID 5, а какие во второй. Проверку корректности выполняем посредством XOR операции. В нашем случае согласно таблицы мы видим, что нумерация дисков представителем заказчика была сделана неверно, так как матрицы обоих массивов отличаются по расположению блока четности (обозначенного как “XOR”). Также видим, что в данном массиве нет задержки четности, так как с каждой строкой меняется положение блока четности.
Заполнив таблицу номерами записей MFT по указанным смещениями с каждого из дисков, можно перейти к заполнению удвоенной матрицы использования дисков. Удвоена она из-за того, что формировать матрицу мы начали в произвольном месте. Следующей задачей ставится определить с какой строки начинается правильная матрица. Задача легко выполнима, если взять первые пять смещений, указанные на рисунке выше и умножить на 8. Далее решить простой пример в виде а=a+b где стартовые значения a=0x0 b=0x280000 (0x280000=0x10000*0x28, где 0x28 является количеством блоков с данными, которые содержатся в матрице использования дисков) и решать его в цикле, пока он не достигнет одного из значений смещений умноженного на 8.
После построения матрицы использования дисков мы можем произвести сбор массива любыми доступными для этого средствами, умеющими работать с матрицей произвольного размера. Но такой вариант сбора массива не будет учитывать актуальности данных на всех дисках, в связи с чем необходимы дополнительные анализы для исключения диска содержащего неактуальные данные (он был первым исключен из массива).
Для определения неактуального диска обычно не требуется полный сбор массива. Достаточно собрать первые 10-100GB и проанализировать найденные структуры. В нашем случае оперируем началом массива из 20GB. Как уже писалось, защитная MBR и GPT на дисках отсутствуют, и, естественно, их нет в собранном массиве, но при поиске достаточно быстро можно найти magic блок VMFS, отняв от его позиции 0x100000 (2048 секторов), получим точку начала VMFS раздела. Определив положение fdc.sf (file descriptor system file), проведем анализ его содержимого. Во многих случаях анализ этой структуры позволит найти место, где присутствуют ошибочные записи. Сопоставив его с матрицей использования дисков, получим номер диска, содержащего неактуальные данные. В нашем случае этого оказалось достаточно и дополнительные аналитические мероприятия не потребовались.
Выполнив сбор массива целиком с компенсацией недостающих данных за счет XOR операции, получили полный образ массива. Зная локализацию дефектов и локализацию файлов виртуальных машин в образе, возможно установить, на какие именно файлы виртуальных машин приходятся дефекты. Выполнив копирование файлов виртуальных машин из VMFS хранилища, можем смонтировать их в ОС как отдельные диски и выполнить проверку целостности файлов, содержащихся в виртуальных машинах посредством поиска файлов, содержащих сектора с паттерном 0xDE 0xAD. Сформировав список поврежденных файлов работу по восстановлению информации из поврежденного RAID 50 можно считать завершенной.
Обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить работу специалиста.
Следующая публикация: Восстановление базы 1С Предприятие (DBF) после форматирования
В нашем случае диски пронумерованы представителем заказчика от 0 до 9 со словами: «именно в таком порядке они были использованы в массиве, и никто их местами не менял». Данное утверждение подлежит обязательной проверке. Также мы были поставлены в известность, что данный массив использовался в качестве хранилища для ESXi сервера, и на нем должно содержаться несколько десятков виртуальных машин.
Перед тем, как начать любые операции над дисками из массива, необходимо проверить их физическую целостность и исправность, а также создать копии и далее работать исключительно с копиями для безопасного проведения работ. При наличии серьезно поврежденных накопителей рассмотреть необходимость проведения работ по извлечению данных, то есть если серьезно поврежден только один накопитель, то необходимо выяснить посредством анализа массива, собранного из оставшихся дисков, содержал ли проблемный HDD актуальные данные, или им нужно пренебречь и получить недостающие данные за счет XOR операции над остальными участниками одного из RAID 5, в который входил данный диск.
Было выполнено создание копий, в результате которого выяснилось, что 4 накопителя имеют дефекты между LBA 424 000 000 и LBA 425 000 000, выражается это в виде нечитаемых нескольких десятков секторов на каждом из проблемных дисков. Непрочитанные сектора в копиях заполняем паттерном 0xDE 0xAD для того, чтобы потом была возможность идентификации пострадавших данных.
Первичный анализ подразумевает идентификацию RAID контроллера, к которому были подключены диски, точнее идентификацию расположения метаданных RAID контроллера, чтобы эти области не включать при сборке в массив.
В данном случае в последнем секторе каждого из дисков обнаруживаем характерные 0xDE 0x11 0xDE 0x11 c дальнейшей пометкой бренда RAID контроллера. Метаданные данного контроллера располагаются исключительно в конце LBA диапазона, какие-либо буферные зоны в середине диапазона данным контроллером не используются. На основании этого и предыдущих данных следует вывод, что сбор массива должен начинаться с LBA 0 каждого из дисков.
Зная, что суммарная емкость массива более 2 TB, проводим поиск в LBA 0 каждого из дисков таблицы разделов (защитной MBR)
и GPT заголовка в LBA 1.
В этом случае данных структур не обнаружено. Данные структуры обычно становятся жертвами необдуманных действий обслуживающего сервер персонала, который не отрабатывал ситуации отказа системы хранения данных и не изучал особенностей работы конкретного RAID контроллера.
Для дальнейшего анализа особенностей массива необходимо произвести на одном из дисков поиск регулярных выражений монотонно возрастающих последовательностей. Это могут быть как таблицы FAT или достаточно большой фрагмент MFT, так и иные удобные для анализа структуры. Зная, что на данном массиве содержались виртуальные машины с ОС Windows, мы можем предположить, что внутри данных машин использовалась файловая система NTFS. На основании этого проводим поиск записей MFT по характерному регулярному выражению 0x46 0x49 0x4C 0x45 с нулевым смещением относительно 512-байтного блока (сектора). В нашем случае после LBA 2 400 000 (1,2GB) обнаруживается достаточно протяженный (более 5000 записей) фрагмент MFT. В нашем случае размер записи MFT стандартный и составляет 1024 байт (2 сектора).
Локализуем границы найденного фрагмента с записями MFT и проверим наличие фрагмента с записями MFT в этих границах на остальных дисках-участниках массива (границы могут чуть-чуть отличаться, но не более чем на размер блока, используемого в RAID массиве). В нашем случае наличие записей MFT подтверждается. Листаем записи с анализом номеров (номер DWORD располагается по смещению 0x2C). Анализируем количество блоков, где возрастание номера записи MFT происходит с изменением на единицу, на основании этого рассчитываем размер блока, используемого в данном RAID массиве. В нашем случае размер составляет 0x10000 байт (128 секторов или 64KiB). Далее выберем среди записей MFT какое-либо из мест, где записи MFT или результат их XOR операции симметрично располагаются на всех дисках-участниках и составим матрицу с номерами записей, с которых начинаются блоки массива с удвоенным количеством строк.
По номерам записей определим какие из дисков входят в первый RAID 5, а какие во второй. Проверку корректности выполняем посредством XOR операции. В нашем случае согласно таблицы мы видим, что нумерация дисков представителем заказчика была сделана неверно, так как матрицы обоих массивов отличаются по расположению блока четности (обозначенного как “XOR”). Также видим, что в данном массиве нет задержки четности, так как с каждой строкой меняется положение блока четности.
Заполнив таблицу номерами записей MFT по указанным смещениями с каждого из дисков, можно перейти к заполнению удвоенной матрицы использования дисков. Удвоена она из-за того, что формировать матрицу мы начали в произвольном месте. Следующей задачей ставится определить с какой строки начинается правильная матрица. Задача легко выполнима, если взять первые пять смещений, указанные на рисунке выше и умножить на 8. Далее решить простой пример в виде а=a+b где стартовые значения a=0x0 b=0x280000 (0x280000=0x10000*0x28, где 0x28 является количеством блоков с данными, которые содержатся в матрице использования дисков) и решать его в цикле, пока он не достигнет одного из значений смещений умноженного на 8.
После построения матрицы использования дисков мы можем произвести сбор массива любыми доступными для этого средствами, умеющими работать с матрицей произвольного размера. Но такой вариант сбора массива не будет учитывать актуальности данных на всех дисках, в связи с чем необходимы дополнительные анализы для исключения диска содержащего неактуальные данные (он был первым исключен из массива).
Для определения неактуального диска обычно не требуется полный сбор массива. Достаточно собрать первые 10-100GB и проанализировать найденные структуры. В нашем случае оперируем началом массива из 20GB. Как уже писалось, защитная MBR и GPT на дисках отсутствуют, и, естественно, их нет в собранном массиве, но при поиске достаточно быстро можно найти magic блок VMFS, отняв от его позиции 0x100000 (2048 секторов), получим точку начала VMFS раздела. Определив положение fdc.sf (file descriptor system file), проведем анализ его содержимого. Во многих случаях анализ этой структуры позволит найти место, где присутствуют ошибочные записи. Сопоставив его с матрицей использования дисков, получим номер диска, содержащего неактуальные данные. В нашем случае этого оказалось достаточно и дополнительные аналитические мероприятия не потребовались.
Выполнив сбор массива целиком с компенсацией недостающих данных за счет XOR операции, получили полный образ массива. Зная локализацию дефектов и локализацию файлов виртуальных машин в образе, возможно установить, на какие именно файлы виртуальных машин приходятся дефекты. Выполнив копирование файлов виртуальных машин из VMFS хранилища, можем смонтировать их в ОС как отдельные диски и выполнить проверку целостности файлов, содержащихся в виртуальных машинах посредством поиска файлов, содержащих сектора с паттерном 0xDE 0xAD. Сформировав список поврежденных файлов работу по восстановлению информации из поврежденного RAID 50 можно считать завершенной.
Обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить работу специалиста.
Следующая публикация: Восстановление базы 1С Предприятие (DBF) после форматирования

