
Заинтересовавшись вопросом скорости работы операций упаковки и распаковки в .NET решил опубликовать свои небольшие и крайне субъективные наблюдения и измерения по этой теме.
Код примера доступен на github, поэтому приглашаю всех желающих сообщить о своих результатах измерений в комментариях.
Теория
Операция упаковки boxing характеризуется выделением памяти в управляемой куче (managed heap) под объект value type и дальнейшее присваивание указателя на этот участок памяти переменной в стеке.
Распаковка unboxing, напротив, выделяет память в стеке выполнения под объект, полученный из управляемой кучи с помощью указателя.
Казалось бы, в обоих случаях выделяется память и особой разницы быть не должно, если бы не одно но- крайне важной деталью является область памяти.
Вспоминая про то, что за выделение памяти в .NET в управляемой куче отвечает сборщик мусора (Garbage Collector) важно отметить, что делает он это нелинейно, ввиду возможной её фрагментации (наличия свободных участков памяти) и поиска необходимого свободного участка требуемого размера.
Update:
Как заметил blanabrother в комментариях, при выделении памяти/копировании значения в managed heap отсутствует процесс поиска свободного участка памяти и её возможная фрагментация ввиду инкриминирующегося указателя и дальнейшей её компактификации с использованием GC. Однако, опираясь на следующие измерения скорости выделения памяти в C++ посмею предположить, что область (тип) памяти является основной причиной такой разницы в производительности.
В случае же с распаковкой, память выделяется в стеке выполнения, который содержит указатель на свой конец, по совместительству являющийся началом участка памяти под новый объект.
Вывод из этого я делаю такой, что процесс упаковки должен занимать значительно больше времени, чем распаковки, ввиду возможных side effects связанных с GC и медленной скоростью выделения памяти/копирования значения в managed heap.
Практика
Для проверки этого утверждения я набросал 4 небольшие функции: 2 для boxing и 2 для unboxing типов int и struct.
public class BoxingUnboxingBenchmark { private long LoopCount = 1000000; private object BoxedInt = 1; private object BoxedStruct = new ExampleStruct { Amount = 1000, Currency = "RUB" }; [Benchmark] public object BoxingInt() { int unboxed = 1000; for (var i = 0; i < LoopCount; i++) { BoxedInt = (object) unboxed; } return BoxedInt; } [Benchmark] public int UnboxingInt() { int unboxed = 1000; for (var i = 0; i < LoopCount; i++) { unboxed = (int)BoxedInt; } return unboxed; } [Benchmark] public object BoxingStruct() { ExampleStruct unboxed = new ExampleStruct() { Amount = 1000, Currency = "RUB" }; for (var i = 0; i < LoopCount; i++) { BoxedStruct = (object) unboxed; } return BoxedStruct; } [Benchmark] public ExampleStruct UnBoxingStruct() { ExampleStruct unboxed = new ExampleStruct(); for (var i = 0; i < LoopCount; i++) { unboxed = (ExampleStruct) BoxedStruct; } return unboxed; } }
Для замера производительности была использована библиотека BenchmarkDotNet в режиме Release (буду рад если DreamWalker подскажет, каким образом сделать данные замеры более объективными). Далее представлен результат измерений:
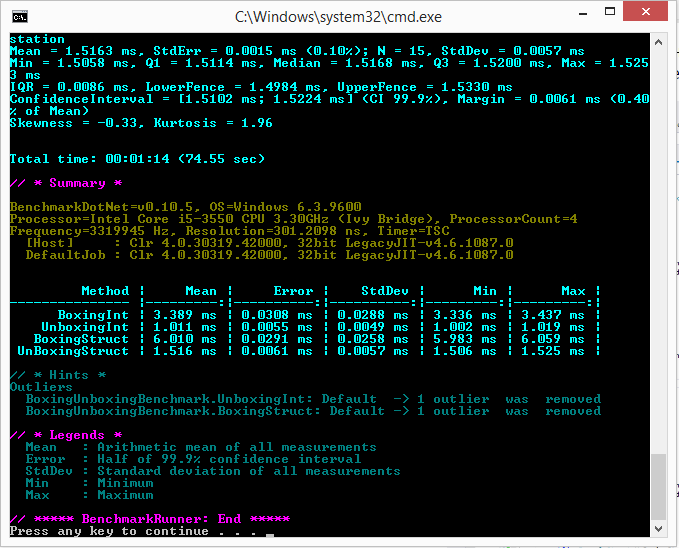
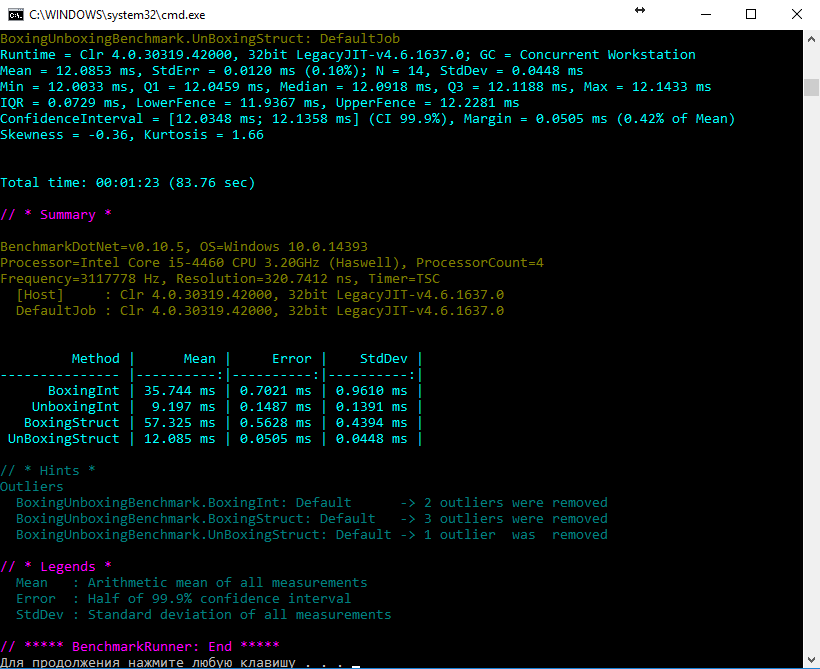
Сразу оговорюсь, что не могу быть твёрдо уверен в отсутствии оптимизаций компилятором итогового кода, однако, судя по IL коду, каждая из функций содержит проверяемую операцию в единственном числе.
Измерения проводились на нескольких машинах с разным кол-вом LoopCount, однако, скорость распаковки из раза в раз превосходила упаковку в 3-8 раз.
.method public hidebysig instance object
BoxingInt() cil managed
{
.custom instance void [BenchmarkDotNet.Core]BenchmarkDotNet.Attributes.BenchmarkAttribute::.ctor() = ( 01 00 00 00 )
// Code size 43 (0x2b)
.maxstack 2
.locals init ([0] int32 unboxed,
[1] int32 i)
IL_0000: ldc.i4 0x3e8
IL_0005: stloc.0
IL_0006: ldc.i4.0
IL_0007: stloc.1
IL_0008: br.s IL_001a
IL_000a: ldarg.0
IL_000b: ldloc.0
IL_000c: box [mscorlib]System.Int32
IL_0011: stfld object ConsoleApp1.BoxingUnboxingBenchmark::BoxedInt
IL_0016: ldloc.1
IL_0017: ldc.i4.1
IL_0018: add
IL_0019: stloc.1
IL_001a: ldloc.1
IL_001b: conv.i8
IL_001c: ldarg.0
IL_001d: ldfld int64 ConsoleApp1.BoxingUnboxingBenchmark::LoopCount
IL_0022: blt.s IL_000a
IL_0024: ldarg.0
IL_0025: ldfld object ConsoleApp1.BoxingUnboxingBenchmark::BoxedInt
IL_002a: ret
} // end of method BoxingUnboxingBenchmark::BoxingInt
.method public hidebysig instance valuetype ConsoleApp1.ExampleStruct
UnBoxingStruct() cil managed
{
.custom instance void [BenchmarkDotNet.Core]BenchmarkDotNet.Attributes.BenchmarkAttribute::.ctor() = ( 01 00 00 00 )
// Code size 40 (0x28)
.maxstack 2
.locals init ([0] valuetype ConsoleApp1.ExampleStruct unboxed,
[1] int32 i)
IL_0000: ldloca.s unboxed
IL_0002: initobj ConsoleApp1.ExampleStruct
IL_0008: ldc.i4.0
IL_0009: stloc.1
IL_000a: br.s IL_001c
IL_000c: ldarg.0
IL_000d: ldfld object ConsoleApp1.BoxingUnboxingBenchmark::BoxedStruct
IL_0012: unbox.any ConsoleApp1.ExampleStruct
IL_0017: stloc.0
IL_0018: ldloc.1
IL_0019: ldc.i4.1
IL_001a: add
IL_001b: stloc.1
IL_001c: ldloc.1
IL_001d: conv.i8
IL_001e: ldarg.0
IL_001f: ldfld int64 ConsoleApp1.BoxingUnboxingBenchmark::LoopCount
IL_0024: blt.s IL_000c
IL_0026: ldloc.0
IL_0027: ret
} // end of method BoxingUnboxingBenchmark::UnBoxingStruct
