Недавно, обсуждая нюансы работы USB flash на данном ресурсе, столкнулся с тем, что основная масса технически грамотных людей в силу отсутствия литературы не имеет представления об основных принципах работы NAND контроллеров, в связи с чем появляется масса далеких от реальности заявлений об особенностях оптимизации микропрограмм устройств, либо делаются неверные выводы о причинах выхода из строя самих устройств.
Дабы немного развеять иллюзии, попробуем методами реверс-инжиниринга проанализировать алгоритмы работы NAND контроллера производства SKYMEDI SK6211 на примере готового изделия в виде USB flash 8Gb, выпущенной компанией Kingston.

рис. 1
Для полноценного анализа сначала создадим имитацию использования накопителя посредством записи большого числа файлов с последующим частичным случайным удалением и повторными записями. Следом пропишем половину LBA диапазона нулями, но кроме нулей в каждый «сектор» поместим по смещению 0x0 DWORD с его номером. Вторую половину логического диапазона пропишем паттерном 0x77 (данный паттерн относительно удобен для анализа алгоритмов зашумливания данных).
Выпаиваем обе микросхемы памяти NAND flash. В этом экземпляре они производства Samsung, маркировка K9HBG08U1M в исполнении TSOP-48. Эксплуатационные характеристики: размер страницы — 2112 байт, размер блока – 128 страниц, количество блоков в плоскости – 2048, количество плоскостей в банке – 4, количество физических банков – 2. Суммарная емкость двух микросхем 2112*128*2048*4*2*2=8 858 370 048 байт.

рис. 2
На рис. 2 показан принцип нумерации блоков (блок состоит из 128 страниц). Стоит отметить, что данная микросхема может одновременно выполнять операции программирования/стирания сразу в двух плоскостях (вариации 0,1 и 2,3). Те, кто желает более подробно изучить особенности микросхем и нюансы работы с ними могут поискать техническую документацию (datasheet), которая в данное время уже доступна широкой публике K9HBG08U1M.pdf.
Для чтения микросхем используем NAND reader входящий в состав комплекса Flash Extractor. В те времена, когда контроллер SK6211 был популярен, этот комплекс, предназначенный для восстановления данных, был практически единственным аналитическим инструментом, который был в свободной продаже.

рис. 3
Приступая к анализу алгоритмов распределения данных контроллером SK6211, узнаем о его возможностях параллельной работы с микросхемами из рекламных источников, а также о несколько отличающихся двух видах кодов коррекции ошибок (ЕСС). В данной публикации, в силу обширности темы, опустим описание особенностей работы кодов коррекции ошибок, и всю математическую составляющую, связанную с ними.
Первая задача в анализе данных установить признаки зашумливания записываемых в память данных. Для этого выполним поиск записанного нами паттерна 0x77 и попробуем обнаружить множество страниц, сплошь заполненных оным. Но результаты поиска к успеху не приводят, что позволяет сделать вывод, что данные записаны в измененном виде. При пролистывании дампов обнаруживаем большое количество страниц, заполненных значением 0x88 кроме последних 64 байт, а также большое количество страниц, заполненных сплошь 0xFF кроме 4 байт в начале каждого 512 байтного блока и последних 64 байт (в границах страницы 2112 байт). Исходя из того, какие паттерны мы записывали на USB flash, вынесем предположение, что имеет место инверсия данных. Прежде, чем выполнять инвертирование данных, проведем анализ содержимого NAND страниц для установления расположения служебных данных. В местах заполнения паттерном весьма просто отличить наше инвертированное однородное значение от служебных данных, которые не состоят сплошь из одинаковых последовательностей байт.

Рис 4.
SK6211 в используемых страницах размещает 2048 байт данных (DA) и 64 байта отводит для хранения служебных данных (SA). Хорошо прослеживаются 4 группы данных по 16 байт, что намекает на применимость их к четырем блокам по 512 содержащихся в странице.
Выведем содержимое первой 16- байтной группы из нескольких тысяч страниц.
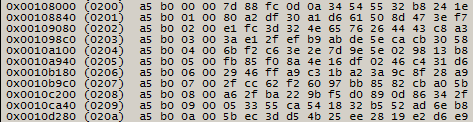
рис. 5
На рис. 5 видно, что упорядоченными остаются первые 4 байта, и хаотичное содержимое располагается в остальных 12. Исходя из этого, можно предположить, что последние 12 байт в каждой строке содержат код коррекции ошибок. Зная, что блок, которым оперирует NAND микросхема, равен 128 страницам, произведем расчет размера блока 2112*128=270 336 (0x42000) байт. От 0x00108000 шагнем на один блок вперед, то есть к странице по адресу 0x0014a000.
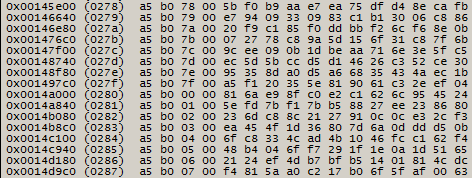
рис. 6
из содержимого рис. 5 и рис. 6 очевидно, что 3-й байт играет роль номера страницы для блока NAND памяти. Это предположение не опровергается при просмотре всех непустых блоков NAND памяти.
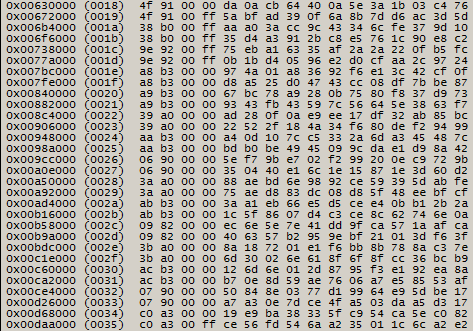
рис. 7
В 0 и 1 байтах служебных данных в каждой странице на протяжении двух блоков неизменные значения. Можно предположить, что эта пара байт отведена для номера блока. Выведем все значения для всех блоков и обнаружим, что в младшем полубайте первого байта используются значения от 0x0 до 0x3, а в нулевом байте пробегают значения от 0x00 до 0xFF. Значения старшего полубайта в первом байте имеют более разнообразные значения. Предположим, что для нумерации используется 10 бит, которые формируются из двух младших битов первого байта служебной зоны в качестве старшей части и 8 бит из нулевого байта в качестве младшей части. Проверим достоверность предположений посредством вывода номеров для первых 0x400 блоков. Отсортировав их в порядке возрастания, заметим, что последовательно выстраивается цепочка из номеров от 0x000 до 0x3C3, что подтверждает корректность предположения. Выполнив аналогичные проверки для остальных групп по 0x400 блоков окончательно исключим вероятность ошибочной интерпретации.
Выполним инвертирование данных, за исключением служебных, и проанализируем механизм распараллеливания данных. Проверим предположение о симметричности записи в разные банки посредством анализа логических номеров в блоках в каждом дампе. В случае SK6211 предположение о симметричной записи подтверждено. Найдем блок с логическим номером 0x000, в котором каждый 512 блок данных содержит порядковый номер и нули в качестве содержимого. Опираясь на фактическое расположение записанных нами данных, построим таблицу положения данных.
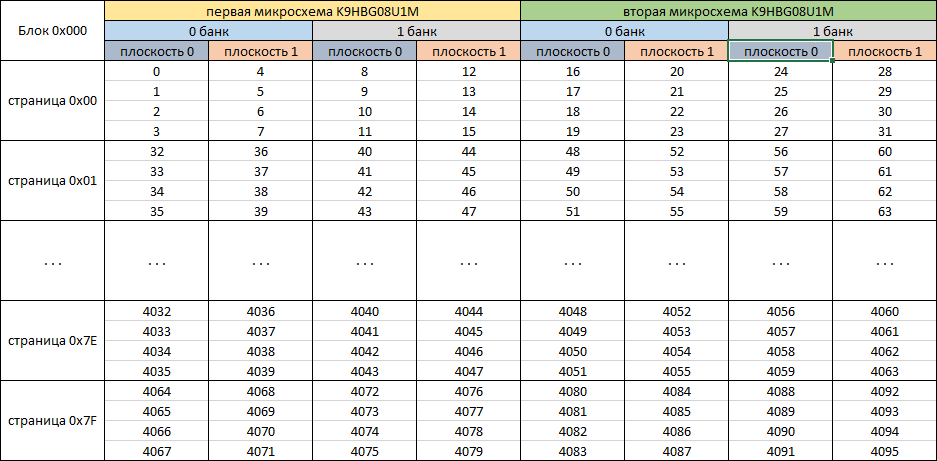
Рис. 8
Согласно размещения данных можем заметить, что контроллер для данного набора микросхем реализует максимально эффективное распараллеливание для получения высокой производительности. С учетом механизма распараллеливания данных рассчитаем размер блока, которым оперирует система трансляции в микрокоде накопителя 0x42000*8=0x210000 байт. Если отбросить служебные данные, то размер блока 0x40000*8=0x200000 (2 097 152) байт.
Для дальнейшего анализа нам необходимо устранить разброс данных и собрать их в цельные блоки по 2 МБ.

рис. 9
Первый шаг – устранение распараллеливания между плоскостями посредством постраничного объединения четных блоков с нечетными.
Второй шаг – объединение с удвоенным размером страницы 0 и 1 банков каждой из микросхем NAND памяти.
Третий шаг – объединение с учетверенным размером страницы обеих микросхем NAND памяти.
При анализе содержимого блоков по 2МБ в результирующем дампе наблюдается монотонно возрастающая последовательность пронумерованных нами «секторов», что подтверждает корректность анализа алгоритма распараллеливания данных.
Далее на сборном дампе выясним порядок расположения блоков и организацию в логические банки.

Рис. 10
Произведем поиск нескольких десятков блоков и сбор по порядковому номеру. По результатам сбора удостоверяемся, что наша нумерация секторов в блоках стыкуется. И сделанное ранее предположение о том, что 10 бит из первых двух служебных байт являются номером блока, верно.
Полный размер микросхем 8 858 370 048 (0x210000000) байт размер блока в трансляторе 2 162 688 (0x210000). Всего блоков 0x210000000/0x210000=0x1000 (4096). Исходя из разрядности используемых чисел и фактической нумерации, номера блоков не могут превышать 0x400 (1024) из этого можно сделать вывод о существовании 4 логических банков в трансляции. Условно разделим результирующий дамп на 4 равные части (по 0x400 блоков), оценим в каждой части номера блоков и на основании этого предположим количество блоков, включенных в трансляцию в каждом логическом банке.
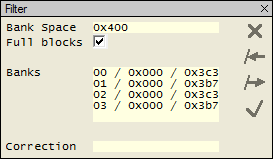
рис. 11
Обратим внимание, что размер каждого логического банка заметно меньше 0x400. Эта необходимость диктуется тем, что «лишние» блоки в некотором количестве нужны для служебных структур и, самое главное, для эффективной работы механизма выравнивания износа. Механизм реализуется по принципу, что каждый блок, в котором изменяется содержимое, будет исключен из трансляции и попадет в резервные, а его место займет блок, который до записи в него измененных данных не был включен в трансляцию и числился резервным. С учетом счетчиков записи в каждый блок механизм работает достаточно эффективно. Ахиллесовой пятой данного алгоритма будет обилие неизменяемых данных, тогда при записях в ротации будет участвовать относительно небольшое число блоков.
Данный принцип весьма наглядно подтверждается расположением блоков в дампе. Согласно рис. 10 можно заметить, насколько нелинеен разброс блоков, из которых реализуется логическое пространство. Припаяв микросхемы NAND памяти обратно и подключив USB flash к компьютеру, выполним некоторое число записей в первые 4096 «секторов», снова выпаяем и прочитаем микросхемы NAND памяти, проведем сбор и оценим порядок блоков в результирующем дампе.

рис. 12
Как можем заметить при неизменном порядке остальных блоков, блок с логическим номером 0x000 «перекочевал» в другое место. По старому адресу все страницы блока, как в области пользовательских данных, так и в области служебных сплошь заполнены 0xFF, что свидетельствует об очистке данного блока и исключении из трансляции.
Сравнивая оба результирующих дампа, кроме измененных данных в нулевом блоке будут изменения и в служебных данных, проанализировав которые мы можем установить, каким образом сформирована структура транслятора.
Подобный метод анализа позволяет получить достаточно данных об алгоритме работы USB NAND контроллера, чтобы применять их для восстановления информации из поврежденных накопителей, основанных на исследуемом контроллере, а также позволяет увидеть в действии механизмы распараллеливания данных и выравнивания износа. Также, основываясь на устройстве транслятора и анализе USB flash (дополнительные мероприятия по анализу проводим на накопителе, отформатированном в FAT32 и заполненном несколькими тысячами файлов), можно заметить, что для блоков со структурами файловой системы нет какого-либо привилегированного выделения блоков.
Следующая публикация: Восстановление данных с внешнего жесткого диска Seagate FreeAgent Go
Предыдущая публикация: Восстановление данных из поврежденного массива RAID 5 в NAS под управлением Linux
Дабы немного развеять иллюзии, попробуем методами реверс-инжиниринга проанализировать алгоритмы работы NAND контроллера производства SKYMEDI SK6211 на примере готового изделия в виде USB flash 8Gb, выпущенной компанией Kingston.
рис. 1
Для полноценного анализа сначала создадим имитацию использования накопителя посредством записи большого числа файлов с последующим частичным случайным удалением и повторными записями. Следом пропишем половину LBA диапазона нулями, но кроме нулей в каждый «сектор» поместим по смещению 0x0 DWORD с его номером. Вторую половину логического диапазона пропишем паттерном 0x77 (данный паттерн относительно удобен для анализа алгоритмов зашумливания данных).
Выпаиваем обе микросхемы памяти NAND flash. В этом экземпляре они производства Samsung, маркировка K9HBG08U1M в исполнении TSOP-48. Эксплуатационные характеристики: размер страницы — 2112 байт, размер блока – 128 страниц, количество блоков в плоскости – 2048, количество плоскостей в банке – 4, количество физических банков – 2. Суммарная емкость двух микросхем 2112*128*2048*4*2*2=8 858 370 048 байт.
рис. 2
На рис. 2 показан принцип нумерации блоков (блок состоит из 128 страниц). Стоит отметить, что данная микросхема может одновременно выполнять операции программирования/стирания сразу в двух плоскостях (вариации 0,1 и 2,3). Те, кто желает более подробно изучить особенности микросхем и нюансы работы с ними могут поискать техническую документацию (datasheet), которая в данное время уже доступна широкой публике K9HBG08U1M.pdf.
Для чтения микросхем используем NAND reader входящий в состав комплекса Flash Extractor. В те времена, когда контроллер SK6211 был популярен, этот комплекс, предназначенный для восстановления данных, был практически единственным аналитическим инструментом, который был в свободной продаже.
рис. 3
Приступая к анализу алгоритмов распределения данных контроллером SK6211, узнаем о его возможностях параллельной работы с микросхемами из рекламных источников, а также о несколько отличающихся двух видах кодов коррекции ошибок (ЕСС). В данной публикации, в силу обширности темы, опустим описание особенностей работы кодов коррекции ошибок, и всю математическую составляющую, связанную с ними.
Первая задача в анализе данных установить признаки зашумливания записываемых в память данных. Для этого выполним поиск записанного нами паттерна 0x77 и попробуем обнаружить множество страниц, сплошь заполненных оным. Но результаты поиска к успеху не приводят, что позволяет сделать вывод, что данные записаны в измененном виде. При пролистывании дампов обнаруживаем большое количество страниц, заполненных значением 0x88 кроме последних 64 байт, а также большое количество страниц, заполненных сплошь 0xFF кроме 4 байт в начале каждого 512 байтного блока и последних 64 байт (в границах страницы 2112 байт). Исходя из того, какие паттерны мы записывали на USB flash, вынесем предположение, что имеет место инверсия данных. Прежде, чем выполнять инвертирование данных, проведем анализ содержимого NAND страниц для установления расположения служебных данных. В местах заполнения паттерном весьма просто отличить наше инвертированное однородное значение от служебных данных, которые не состоят сплошь из одинаковых последовательностей байт.
Рис 4.
SK6211 в используемых страницах размещает 2048 байт данных (DA) и 64 байта отводит для хранения служебных данных (SA). Хорошо прослеживаются 4 группы данных по 16 байт, что намекает на применимость их к четырем блокам по 512 содержащихся в странице.
Выведем содержимое первой 16- байтной группы из нескольких тысяч страниц.
рис. 5
На рис. 5 видно, что упорядоченными остаются первые 4 байта, и хаотичное содержимое располагается в остальных 12. Исходя из этого, можно предположить, что последние 12 байт в каждой строке содержат код коррекции ошибок. Зная, что блок, которым оперирует NAND микросхема, равен 128 страницам, произведем расчет размера блока 2112*128=270 336 (0x42000) байт. От 0x00108000 шагнем на один блок вперед, то есть к странице по адресу 0x0014a000.
рис. 6
из содержимого рис. 5 и рис. 6 очевидно, что 3-й байт играет роль номера страницы для блока NAND памяти. Это предположение не опровергается при просмотре всех непустых блоков NAND памяти.
рис. 7
В 0 и 1 байтах служебных данных в каждой странице на протяжении двух блоков неизменные значения. Можно предположить, что эта пара байт отведена для номера блока. Выведем все значения для всех блоков и обнаружим, что в младшем полубайте первого байта используются значения от 0x0 до 0x3, а в нулевом байте пробегают значения от 0x00 до 0xFF. Значения старшего полубайта в первом байте имеют более разнообразные значения. Предположим, что для нумерации используется 10 бит, которые формируются из двух младших битов первого байта служебной зоны в качестве старшей части и 8 бит из нулевого байта в качестве младшей части. Проверим достоверность предположений посредством вывода номеров для первых 0x400 блоков. Отсортировав их в порядке возрастания, заметим, что последовательно выстраивается цепочка из номеров от 0x000 до 0x3C3, что подтверждает корректность предположения. Выполнив аналогичные проверки для остальных групп по 0x400 блоков окончательно исключим вероятность ошибочной интерпретации.
Выполним инвертирование данных, за исключением служебных, и проанализируем механизм распараллеливания данных. Проверим предположение о симметричности записи в разные банки посредством анализа логических номеров в блоках в каждом дампе. В случае SK6211 предположение о симметричной записи подтверждено. Найдем блок с логическим номером 0x000, в котором каждый 512 блок данных содержит порядковый номер и нули в качестве содержимого. Опираясь на фактическое расположение записанных нами данных, построим таблицу положения данных.
Рис. 8
Согласно размещения данных можем заметить, что контроллер для данного набора микросхем реализует максимально эффективное распараллеливание для получения высокой производительности. С учетом механизма распараллеливания данных рассчитаем размер блока, которым оперирует система трансляции в микрокоде накопителя 0x42000*8=0x210000 байт. Если отбросить служебные данные, то размер блока 0x40000*8=0x200000 (2 097 152) байт.
Для дальнейшего анализа нам необходимо устранить разброс данных и собрать их в цельные блоки по 2 МБ.
рис. 9
Первый шаг – устранение распараллеливания между плоскостями посредством постраничного объединения четных блоков с нечетными.
Второй шаг – объединение с удвоенным размером страницы 0 и 1 банков каждой из микросхем NAND памяти.
Третий шаг – объединение с учетверенным размером страницы обеих микросхем NAND памяти.
При анализе содержимого блоков по 2МБ в результирующем дампе наблюдается монотонно возрастающая последовательность пронумерованных нами «секторов», что подтверждает корректность анализа алгоритма распараллеливания данных.
Далее на сборном дампе выясним порядок расположения блоков и организацию в логические банки.
Рис. 10
Произведем поиск нескольких десятков блоков и сбор по порядковому номеру. По результатам сбора удостоверяемся, что наша нумерация секторов в блоках стыкуется. И сделанное ранее предположение о том, что 10 бит из первых двух служебных байт являются номером блока, верно.
Полный размер микросхем 8 858 370 048 (0x210000000) байт размер блока в трансляторе 2 162 688 (0x210000). Всего блоков 0x210000000/0x210000=0x1000 (4096). Исходя из разрядности используемых чисел и фактической нумерации, номера блоков не могут превышать 0x400 (1024) из этого можно сделать вывод о существовании 4 логических банков в трансляции. Условно разделим результирующий дамп на 4 равные части (по 0x400 блоков), оценим в каждой части номера блоков и на основании этого предположим количество блоков, включенных в трансляцию в каждом логическом банке.
рис. 11
Обратим внимание, что размер каждого логического банка заметно меньше 0x400. Эта необходимость диктуется тем, что «лишние» блоки в некотором количестве нужны для служебных структур и, самое главное, для эффективной работы механизма выравнивания износа. Механизм реализуется по принципу, что каждый блок, в котором изменяется содержимое, будет исключен из трансляции и попадет в резервные, а его место займет блок, который до записи в него измененных данных не был включен в трансляцию и числился резервным. С учетом счетчиков записи в каждый блок механизм работает достаточно эффективно. Ахиллесовой пятой данного алгоритма будет обилие неизменяемых данных, тогда при записях в ротации будет участвовать относительно небольшое число блоков.
Данный принцип весьма наглядно подтверждается расположением блоков в дампе. Согласно рис. 10 можно заметить, насколько нелинеен разброс блоков, из которых реализуется логическое пространство. Припаяв микросхемы NAND памяти обратно и подключив USB flash к компьютеру, выполним некоторое число записей в первые 4096 «секторов», снова выпаяем и прочитаем микросхемы NAND памяти, проведем сбор и оценим порядок блоков в результирующем дампе.
рис. 12
Как можем заметить при неизменном порядке остальных блоков, блок с логическим номером 0x000 «перекочевал» в другое место. По старому адресу все страницы блока, как в области пользовательских данных, так и в области служебных сплошь заполнены 0xFF, что свидетельствует об очистке данного блока и исключении из трансляции.
Сравнивая оба результирующих дампа, кроме измененных данных в нулевом блоке будут изменения и в служебных данных, проанализировав которые мы можем установить, каким образом сформирована структура транслятора.
Подобный метод анализа позволяет получить достаточно данных об алгоритме работы USB NAND контроллера, чтобы применять их для восстановления информации из поврежденных накопителей, основанных на исследуемом контроллере, а также позволяет увидеть в действии механизмы распараллеливания данных и выравнивания износа. Также, основываясь на устройстве транслятора и анализе USB flash (дополнительные мероприятия по анализу проводим на накопителе, отформатированном в FAT32 и заполненном несколькими тысячами файлов), можно заметить, что для блоков со структурами файловой системы нет какого-либо привилегированного выделения блоков.
Следующая публикация: Восстановление данных с внешнего жесткого диска Seagate FreeAgent Go
Предыдущая публикация: Восстановление данных из поврежденного массива RAID 5 в NAS под управлением Linux

