Итак, после постановки требований описанной в части 1 можно перейти к проектированию системы.
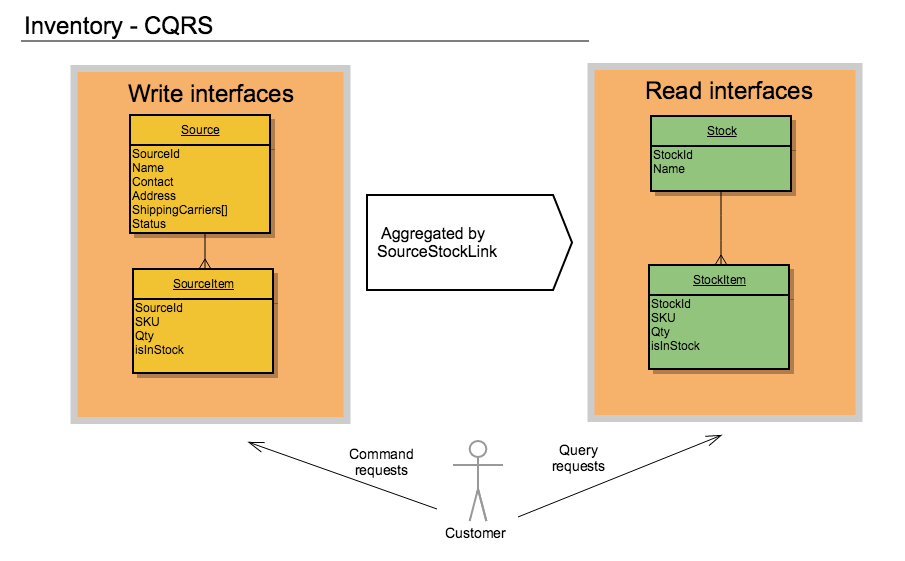
Основная наша задача в проектировании, как это понятно из названия статьи, добиться разделения интерфейсов на Query и Command, чтобы впоследствии разделить бизнес сценарии на те, которые будут читать данные (Query интерфейсы) и на те, которые будут изменять данные (Command интерфейсы). А также обеспечить минимальное время ожидание (latency) на обновление данных, доступных через Query, после того как мы изменили данные через Command.
Почему CQRS?
В последнее время разделение методов интерфейса (CQS), а впоследствии и самих интерфейсов на Query/Command стало популярным веянием в разработке архитектуры приложений. Но в Magento CQRS применяют не из-за популярности, а из-за того, что для нас иногда это единственный способ построить гибкое расширяемое (адаптирование к специфическим потребностям) решение с возможностью независимо масштабировать операции Чтения и Записи.
Фактически мы пришли к CQRS в результате осмысления и повсеместного применения SOLID в написании кода. CQRS это реализация принципа единой ответственности (The Single Responsibility Principle) и принципа разделения интерфейсов (The Interface Segregation Principle) и уход от классического CRUD.
Элементы CQRS у нас появились достаточно давно, когда мы задавались вопросом как масштабировать модель данных EAV (entity-attribute-value) для операций чтения и вводили индексные агрегационные таблицы для этого.
Более подробно про CQRS, и что он для нас значит можно послушать в презентации, которую я делал на MageCONF 2016 (видео, слайды).
Описание доменных сущностей
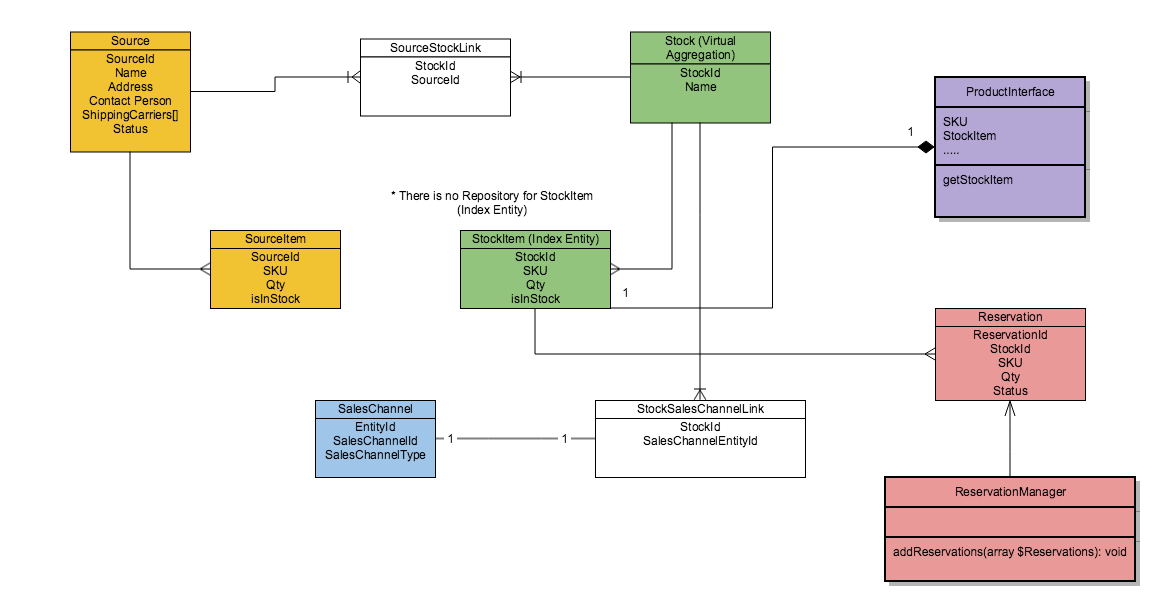
В предметной области Inventory у нас есть шесть основных доменных моделей:
- Source — сущность ответственная за представление любого физического склада где может находиться товар (магазин, склад).
- Source Item — сущность-связка, представляет собой количество определенного продукта (SKU) на конкретном физическом хранилище. А также хранит статус доступен ли продукт для продажи в данный момент.
- Stock — виртуальная сущность ответственная за представление запасов на нескольких физических складах (Source) одновременно. Представляет собой аргрегацию по физическим складам. Связь между складами и Stock (какие именно склады входят в агрегацию) задается администратором в админ панеле либо через вызов API.
- Stock Item — индексная сущность, строится на основании связей между Source и Stock, и представляет собой количество определенного продукта (SKU) доступное на конкретном Stock, т.е. виртуальной агрегации.
- Sales Channel — канал продаж через который осуществляется продажа конечному покупателю. В случае Magento это может быть (Website, Store, Store View), но канал продаж может определяться продавцом самостоятельно, поэтому для некоторых продавцов это может быть Страна (Country), или большой Оптовый клиент (Wholesale) может выступать самостоятельным каналом продаж. Фактически канал продаж это контекст (scope) в рамках которого происходит продажа, который помогает нам четко определить Stock который должен быть использован во время выполнения бизнес операции.
- Reservation — объект резервации, создается для того, чтобы иметь актуальный уровень товаров, которыми мы располагаем для продажи между событиями создания заказа и уменьшением количества товаров на конкретных физических складах. Фактически объект резервации помогает нам избавиться от надобности выполнения проверок, блокировок и списывания товаров из инвентаря физических складов (Source Item) во время операции размещения заказа, при этом значение товаров доступных для продажи в рамках определенного Stock меняется сразу же.
Данная диаграмма представляет собой взаимодействие описанных выше сущностей:
Таким образом мы получаем разделение интерфейсов на Query и Command:
Theory of operation
Одна из наших основных задач — это максимально разгрузить процесс размещения заказа. И идеально сделать эту операцию такой, которая не будет изменять состояние системы (State Modification). Это избавит от лишних блокировок и улучшит масштабирование чекаута.
По диаграммам выше видно, что такие операции как рендеринг страницы категории будет выполнен используя только Query API (StockItem), где нам нужно отобразить количество товаров, которые мы можем продать в определенном контексте (SalesChannel).
Операция синхронизации с внешней ERP или PIM системой будет использовать Command API (SourceItem) и обновлять количество товаров на конкретных складах, после чего реиндексация, которая пересоберет StockItem позволит этим обновлениям быть видимыми на фронте.
В случае операции размещения заказа все становится интересней.
Размещение Заказа по Шагам
Операция размещения заказа разделяется на две операции: непосредственно размещение заказа, в которой принимает участие покупатель и которая заканчивается оплатой и подтверждением принятия заказа на выполнение; и обработка заказа, которая происходит постфактум (с определенной задержкой от нескольких миллисекунд до минут и часов) основная задача которой определить из какого именно склада (или складов) мы должны выполнить доставку нашему покупателю и произвести калибровку количества товаров на этих складах после выполнения заказа.
Собственно, рассмотрим эти операции на примере подробней.
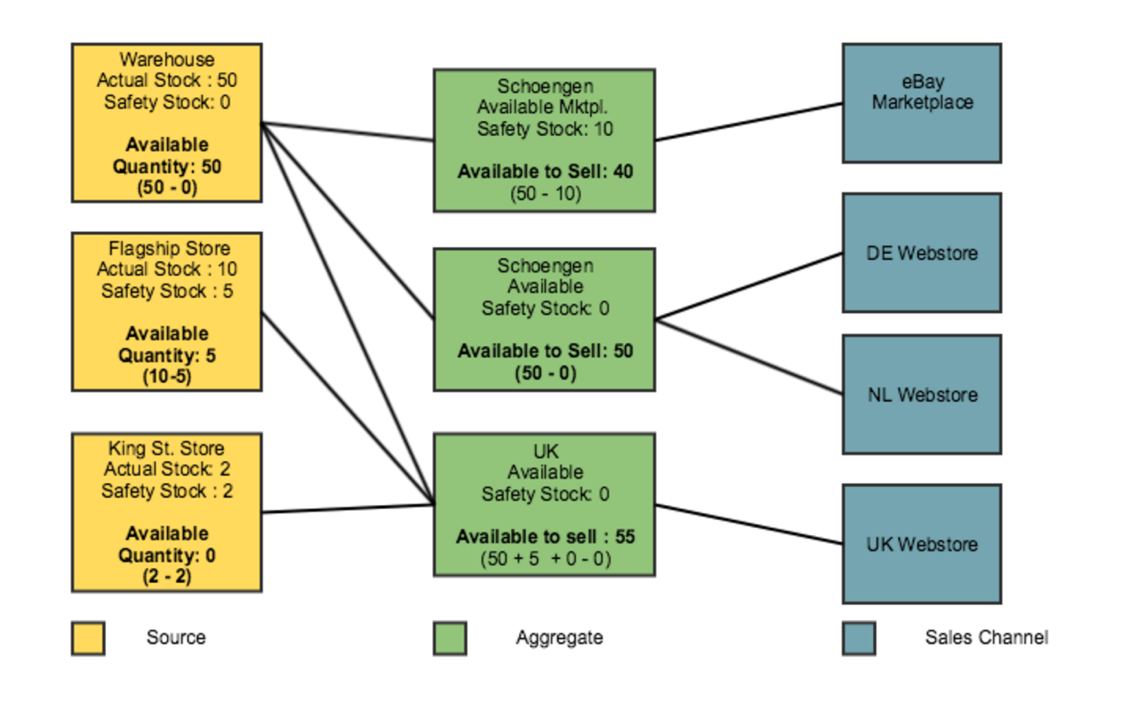
Пусть мы имеем 3 физических склада: Source A, Source B, Source C. На которых хранится товар SKU-1 в таком количестве:
- SourceItem A — 20
- SourceItem B — 25
- SourceItem C — 10
Для этого канала продаж у нас есть созданная виртуальная агрегация Stock A, с которой связаны все текущие физические склады (Source A, Source B, Source C). Получаем StockItem A для SKU-1 имеет количество 20+25+10 = 55
Соответственно, когда покупатель заходит на Website, система точно определяет Stock, который должен быть применен для определения количества товаров, и использует Stock Item-ы в рамках этого стока для всех продуктов (SKU) в категории, в нашем случае SKU-1.
Размещение заказа
Пусть покупатель решил купить 30 единиц товара SKU-1.
- Мы принимаем решение о том можем ли мы выполнить продажу (хватает ли у нас товара для продажи), количество StockItem A для SKU-1 = 55 минус количество всех резерваций для продукта SKU-1 на Stock A, в нашем случае 0 (так как пока ни одна резервация не создана), 55 — 0 > 30, то мы принимаем решение, что продать 30 единиц товара SKU-1 можем.
- Во время размещения заказа мы агностичны к тому с каких именно физических складов произойдет в итоге списание, поэтому мы не работаем с Source Item сущностями. *Данная тема будет рассмотрена в отдельной статье, которая будет полностью посвящена алгоритму выбора складов для доставки в рамках выполнения заказа.
- При этом мы не можем уменьшить кол-во SKU-1 на StockItem, так как это Read проекция, созданная только для чтения. Поэтому мы создаем резервацию (Reservation) для SKU-1 на Stock A в количестве 30 единиц. Создание резервации это Append Only операция, которая добавляется без каких либо проверок.
- Сама команда заказа может при этом класться в очередь на последующую обработку.
Состояние системы, которое мы имеем на текущий момент:
Количество товара SKU-1 на складах:
- SourceItem A — 20
- SourceItem B — 25
- SourceItem C — 10
Reservation для SKU-1 на Stock A в количестве (-30).
Пока мы не успели обработать данный заказ, например из-за большой latency, к нам на сайт приходит другой покупатель, который также хочет приобрести товар SKU-1 в количестве 10 единиц.
Система начинает выполнять те же шаги, что описаны выше.
Проверяем можем ли мы продать 10 единиц SKU-1. Проверка осуществляется таким образом: количество StockItem A для SKU-1 = 55 минус количество всех резерваций для продукта SKU-1 на Stock A, в нашем случае (-30), 55 — 30 = 25 > 10 принимаем решение, что продать 10 единиц товара SKU-1 можем.
По факту состояние в Event Sourcing определяется как проекция агрегированных данных (в нашем случае StockItem), с добавлением всех событий, которые были получены за дельту времени с момента формирования данной проекции (в нашем случае это Reservation).
Обработка заказа
На данном этапе мы должны определить какие именно физические склады будут принимать участие в доставке, и для этих складов уменьшить значение количества отгруженных товаров.
За эту часть ответсвенный алгоритм, который приймет решение о выборе складов (будет описан в следующей статье). Например, алгоритм принял решение, что дешевле всего для продавца будет отправить 30 товаров со складов Source С и Source B.
Соответсвенно количество товара SKU-1 на складах должно измениться:
- SourceItem A: 20
- SourceItem B: 25 — 20 = 5
- SourceItem C: 10 — 10 = 0
После чего мы создаем еще один объект Резервации на SKU-1 в рамках Stock A в количестве (+30) единиц, чтобы «обнулить» прошлый созданный объект резерва (-30 + 30 = 0). После этого должна создасться команда на обновление индекса StockItem (который строится как агрегация по наличию товаров на физических складах), которая также может быть асинхронной.
Magento MSI (Multi Source Inventory)
Данная статья является второй статьей в цикле «Система управления складом с использованием CQRS и Event Sourcing» в рамках которого будет рассмотрен сбор требований, проектирование и разработка системы управления складом на примере Magento 2.
Открытый проект, где ведется разработка, и куда привлекаются инженеры из сообщества, а также где можно ознакомиться с текущим состоянием проекта и документацией, доступен по ссылке.

