ETL и 1С. Извлечение данных
Первый взгляд
Если вы, как ETL-специалист столкнулись с необходимостью получать данные из 1С, то это первое, что вы можете увидеть, попытавшись разобраться со структурой БД (это из случае MSSQL, для других СУБД картинка аналогичная):
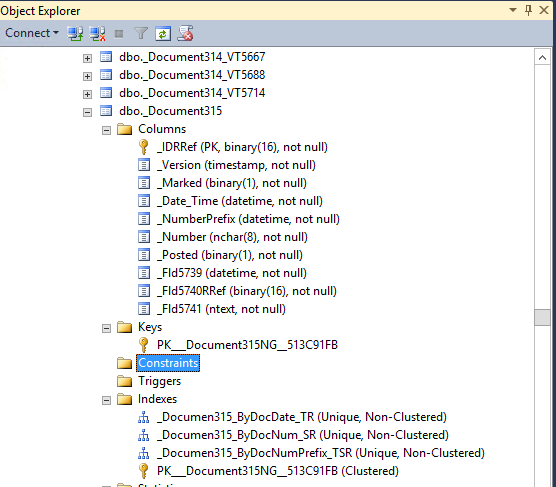
Бизнес-смысл в наименованиях таблиц и полей отсутствует, внешних ключей нет.
Пару ласковых о самой 1С. Реальные таблицы СУБД в ней скрыты за объектами, которые видит разработчик, который часто не догадывается о реальной структуре базы. Да… И весь код на русском языке. Кроме того, есть перечисления, строковые представления которых с помощью SQL получить практически невозможно. Об этом подробнее здесь.
Есть случаи, когда БД нет (и 1С в файловой версии), но это, разумеется ориентирует вас на интеграцию без использования средств СУБД.
Однако, не стоит впадать в отчаяние, поскольку все не так плохо, как кажется.
Внимательный взгляд
Для захвата данных из 1С у вас есть 2 пути:
Реализация «высокоуровневого» интерфейса
Вы можете воспользоваться файловыми выгрузками, web/json сервисами и прочими возможностями 1С, которые окажутся совместимы с вашим ETL.
+
- Вам не придется лезть в 1С. Все, что на стороне 1С должны сделать 1Сники
- Вы никак не нарушаете лицензионную политику 1С
—
- Появляется еще один источник для ошибок в виде дополнительных выгрузок-загрузок,
расписаний, роботизации - Это будет работать существенно медленнее из-за особенностей интерфейсов 1С
- При любых изменениях в захватываемых данных, вам придется вносить изменения в выгрузки (но это можно обойти настроечной системой)
- Это вызовет больше ошибок в целостности данных, чем работа напрямую с СУБД
Реализация на СУБД
+
- Работает быстрее
- Позволяет гарантировать полноту данных в хранилище при правильном подходе
—
- Нарушает лицензионное соглашение с 1С
Итак, взвесив за и против, вы решаете строить интеграцию через СУБД, ну или хотя бы
подумать, как вы будете это делать дальше.
Data mapping
Для того, чтобы связать бизнес-данные, как их понимают на стороне 1С с реальными таблицами БД, вам потребуется выполнить немного магии в самой 1С, а именно получить описание метаданных 1С в пригодном для использования виде (в связи бизнес-объектов и таблиц).
Опять же есть, как минимум, целых 3 подхода:
- Используя com-соединение, web/json сервис получить таблицу соответствия из 1С
- Сделать то же самое на стороне 1С, сформировав таблицу метаданных
- Разобрать бинарный файл, который хранится в той же БД
3-й путь мне кажется несколько рискованным в силу того, что 1С имеет привычку вносить изменения в свои внутренности без предупреждения. И, при этом, довольно сложным.
Выбор между 1 и 2 не столь очевиден, но на мой вкус использовать заранее сформированную таблицу гораздо удобнее, и надежнее в ежедневном использовании и нет нужды задействовать что-то, кроме чистого SQL.
Хранить и поддерживать актуальность таблицы удобнее при помощи 1С, обновляя после каждого обновления конфигурации. При этом, ETL может пользоваться View, который покажет данные уже в более удобоваримой форме.
Подготовка таблицы метаданных
Создать в 1С объект, который содержит метаданные конфигурации (к сожалению, скриптом это не сделать, но можно отдать инструкцию 1С-нику)
РегистрСведений.СтруктураКонфигурации
Поля:
ИмяТаблицыХранения
ИмяТаблицы
СинонимТаблицы
Назначение
ИмяПоляХранения
СинонимПоля
Все строки 150 символов
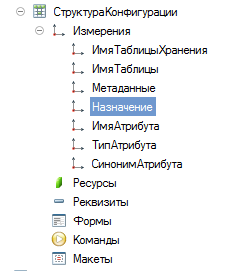
Получается денормализованно, но довольно удобно и просто.
Код 1С для заполнения структуры:
СтруктураБД = ПолучитьСтруктуруХраненияБазыДанных(,истина); ЗаписиСтруктура = РегистрыСведений.СтруктураКонфигурации.СоздатьНаборЗаписей(); Для каждого СтрокаСтруктуры Из СтруктураБД Цикл Для каждого СтрокаПолей Из СтрокаСтруктуры.Поля Цикл Запись = ЗаписиСтруктура.Добавить(); Запись.ИмяТаблицыХранения = СтрокаСтруктуры.ИмяТаблицыХранения; Запись.ИмяТаблицы = СтрокаСтруктуры.ИмяТаблицы; Запись.СинонимТаблицы = Метаданные.НайтиПоПолномуИмени(СтрокаСтруктуры.Метаданные); Запись.Назначение = СтрокаСтруктуры.Назначение; Запись.ИмяПоляХранения = СтрокаПолей.ИмяПоляХранения; Запись.СинонимПоля = Метаданные.НайтиПоПолномуИмени(СтрокаПолей.Метаданные); КонецЦикла; Конеццикла; ЗаписиСтруктура.Записать(истина);
Опять же все довольно просто и очевидно, несмотря на русский язык. Нужно выполнять этот код при каждом обновлении конфигурации. Делать это можно руками в обработке или при помощи регламентного задания.
Таблицу можно просматривать как в режиме клиента, так и со стороны SQL, зная их имена.
SELECT * FROM _InfoReg27083 ORDER BY _Fld27085
(_InfoReg27083 — имя, которое 1С дала таблице регистра со структурой, _Fld27085 — имя поля с именем таблицы хранения)
Можно сделать View, чтобы было удобнее.
Если нет возможности вносить изменения в конфигурацию, можно сделать таблицу, соединившись через com, или дописав в обработке выгрузку в таблицу базы, которая задействована в ETL.
А здесь про то, какие есть типы таблиц, и зачем они нужны (нужен доступ к ИТС 1C).
Следующий шаг — составить карту данных и описание трансформации.
| Field | Field1C | Transformation | ... |
|---|---|---|---|
| _Fld15704 | Документ.РеализацияТоваровУслуг.Вес | Check >=0, round(10,2),… | ... |
Вот мы получили таблицу маппинга, которую можно использовать в дальнейшей работе.
Захват изменений данных
Теперь с точки зрения стратегии захвата изменений данных. Здесь опять есть несколько вариантов. Проще забирать таблицы целиком, что, разумеется может стоить серверу существенных дополнительных расходов.
Однако, есть и другие способы:
- Использовать версии объектов
- Использовать план обмена
Использовать версии объектов
Для объектов «ссылочного» типа 1С поддерживает версии. Номер версии объекта записывается в бинарное поле _version, аккуратно обновляющееся при каждом обновлении записи. На MSSQL, например, это поле типа timestamp. Версии поддерживаются для объектов типа «Документ»,«Справочник»,«Бизнес-процесс»,«Задача»,«План счетов»,«План видов характеристик», «Константы». Использовать версию довольно просто, сохранив у себя в staging area значение последней версии для объекта, и при следующем обновлении выбрав объекты, большие по значению поля версии. Вместе с «основным» объектом нужно не забыть забрать его табличные части (см. Назначение — «Табличная часть») в структуре (поле вида _DocumentXXX_IDRRef или _ReferenceXXX_IDRRef — ссылка на основную таблицу).
Использовать план обмена
Для не ссылочных типов такой подход не годится, но можно воспользоваться объектом «план обмена». В таблице структуры их назначение = 'РегистрацияИзменений'. Для каждого объекта конфигурации создается отдельная таблица плана обмена.
На уровне БД это таблица, вот такой структуры:
_NodeTRef, — идентификатор типа «узла» плана обмена. Он нам не очень интересен
_NodeRRef, — идентификатор узла плана обмена
_MessageNo, — номер сообщения
Дальше идут поля ключа «основной» таблицы. Они различаются в зависимости от типа таблицы, с которой связана таблица плана обмена:
_IDRRef — в данном случае ID справочника или документа
может быть вот так вот:
_RecorderTRef
_RecorderRRef
Это будет таблица изменений регистра накопления, регистра сведений, подчиненного регистратору, или регистра бухгалтерии. Так же может быть ключ таблицы регистра сведений, если он не подчинен регистратору.
Для того, чтобы такая таблица регистрации изменений существовала, нужно включить в конфигураторе 1С нужный нам объект в план обмена. Кроме того, нужен быть создан узел плана обмена, идентификатор (_IDRRef) которого наим нужно будет использовать.
Таблицу плана обмена можно найти в структуре (см. выше). Т.к. в плане обмена регистрируются изменения для всех узлов, а не только для хранилища, нам нужно ограничить выборку нужным нам _NodeRRef. План обмена можно использовать и для ссылочных объектов, но на мой взгляд это бессмысленный расход ресурсов.
Как забирать данные через план обмена:
Для начала мы пишем update к плану обмена, где ставим произвольный _MessageNO (лучше всегда 1).
Например
UPDATE _DocumentChangeRec18901 set _MessageNO = 1 WHERE _NodeRRef = @_NodeRRefДалее выбираем данные из таблицы данных, связав ее по ключу с таблицей плана обмена
SELECT [fieldslist] FROM _Document18891 inner join _DocumentChangeRec18901 ON _Document18891._IDRRef = _DocumentChangeRec18901._IDRRef and _MessageNO = 1 AND _NodeRRef = @_NodeRRefИ подтверждаем забор изменений, удалив записи таблицы изменений
DELETE FROM _DocumentChangeRec18901 WHERE _MessageNO = 1 AND _NodeRRef = @_NodeRRefИтого: Мы научились читать на стороне ETL метаданные 1С, научились выполнять захват данных. Остальные шаги процесса ETL достаточно хорошо известны. Например, можно почитать здесь.

