Вчера после публикации статьи zarytskiy «Какой язык программирования выбрать для работы с данными?» я понял, что .net в целом и C# в частности не рассматривается, как инструмент для машинного обучения и анализа данных. Не то, чтобы для этого совсем не было объективных причин, но все же надо восстановить справедливость и потратить пару минут на рассказ о фреймворке Accord.NET.
Итак, в прошлой статье цикла, посвящённого обучению Data Science с нуля, мы с вами разбирали вопрос создания своего собственного набора данных и обучение моделей из библиотеки scikit-learn (Python) на примере задачи классификации спектров излучения ламп и дневного света.
В этот раз, чтобы набор данных не пропадал мы рассмотрим и сопоставим нашей прошлой статье маленький кусочек задачи машинного обучения, но в этот раз реализованный на C#
Милости прошу всех под кат.

Для начала надо отметить, что машинное обучение, Python и C# я знаю одинаково плохо, ну то есть почти никак, поэтому данная статья вряд ли подарит читателю, какой-то виртуозный код или особо ценную информацию. В прочем мы такую цель и не ставим, ведь правда?
Фрагменты кода и данные, как и прежде можно взять на GitHub
Вкратце напомню о чем шла речь в прошлой статье:
С помощью открытого проекта Spectralworkbench (Public Lab), я собрал для вас небольшую коллекцию спектров дневного света, люминесцентных ламп и светодиодных ламп предположительно различных оттенков белого света и с различным качеством цветопередачи. В наборе содержалось по 30 обучающих образцов каждого класса и по 11 контрольных соответственно.
Дальше после долгих моих разглагольствований мы наконец приступили к непосредственно машинному обучению и в итоге обучили: классификаторы RandomForestClassifier и LogisticRegression, в том числе с подбором параметров, также побаловались с отображением признаков в двухмерном виде с помощью T-SNE и PCA, под конец попробовали сделать кластеризацию данных с помощью DBSCAN, ну а завершила статью моя эпичная битва с компьютером, которую я к сожалению проиграл с результатом в пару % точности предсказания.
Итак, беглый поиск в Интернете говорит, о том, что Accord.NET один из самых популярных в экосистеме .Net, видимо по тому, что в первую очередь заточен под C#, хотя есть и другие, например, Angara (заточена под F#). Безусловно платформа позволяет запускать фреймворки на всех языках .Net (ну или точно подавляющем большинстве языков).
Первое, что бросается в глаза, это все же на порядок меньшая популярность фреймворка по сравнению с решениями на Python или R, как следствие полагаться придется на примеры и документацию, документация, для новичка могла бы быть и побольше разжёвана, а примеры в основном встречаются в виде уже собранных проектов, которые хорошо бы открывать в Visual Studio. После целого моря информации по машинному обучению c Питоном, это немного отталкивает, видимо именно поэтому в данном случае я ограничился только классификацией (SVM) и отображением признаков с помощью PCA.
Итак, нам понадобится MS Visual Studio (у меня была 2015) или MonoDevelop (например, для Linux).
В принципе можно воспользоваться инструкцией для быстрого старта, а можно поверить мне на слово. Пример буду приводить для Visual Studio:
Открываем Program.cs и добавляем пространства имен:
Дальше для простоты все запихнем в базовый класс
Итак:
Читаем данные, к сожалению удобной библиотеки, Pandas у нас нет, но есть аналоги (хоть и менее удобные на мой взгляд).
Один из минусов, это опять-таки не очевидность, я собрал пару «велосипедов» прежде чем понял, что Accord предлагает свое решение для обработки csv или xsls при желании.
Собственно, обучаем модель классификатора, если вам уже впиталась в душу терминология scikit-learn, то по началу будет не привычно. Но в принципе все должно быть понятно в teacher запихиваем класс модели, потом обучаем ее на данных, потом вызываем предсказание меток (напомню: 0 – светодиод, 1 – лампа, — 2 дневной свет)
Дальше распечатаем данные (результат будет, чуть позже на картинке)
Ну и финальный аккорд — трансформируем данные с помощью PCA и выведем диаграмму рассеяния
Ну вот, что получилось в итоге:
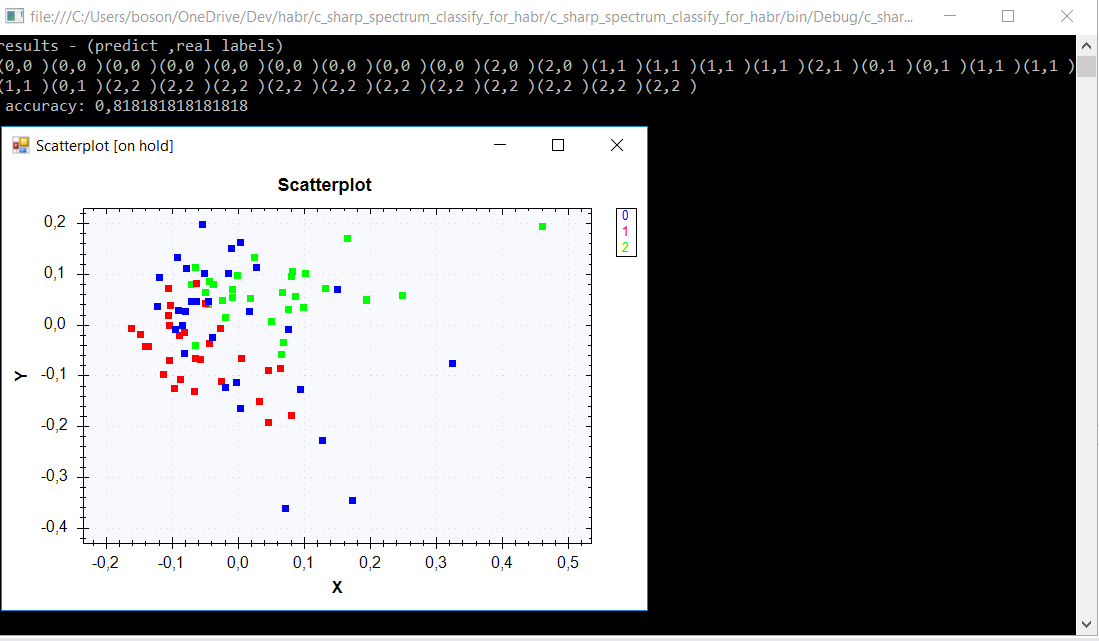
Давайте сравним с тем что поучилось в прошлой статье для
Логистической регрессии с подобранными параметрами
(предсказание, факт):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2), (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
accuracy on test data: 0.81818
как видите результат сопоставим.
Посмотрим на график PCA.
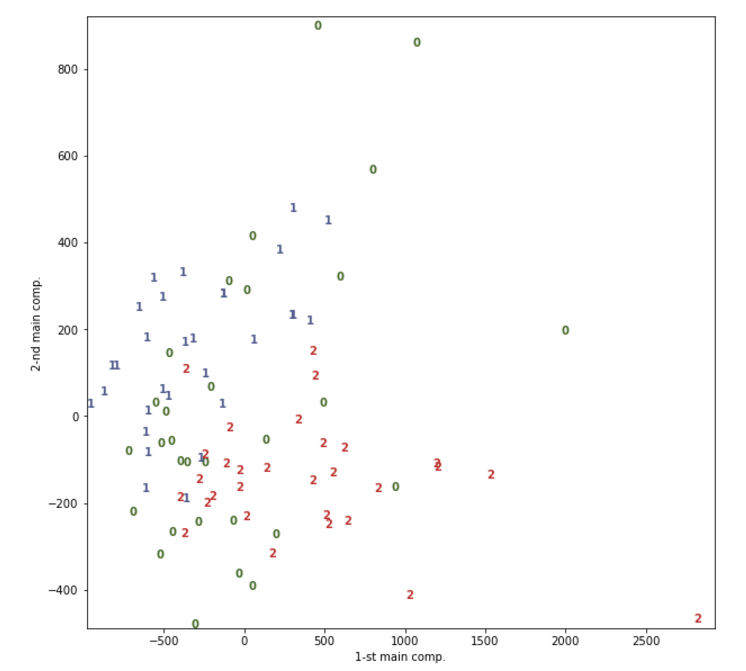
Ну в принципе похоже, но немного отличается, разработчики на своем сайте утверждают, что «все в порядке так и должно быть, все равно все скорей всего правильно, просто таковы особенности алгоритмов» (ну близко к тексту).
UPD: Спасибо AirLight
Как выяснилось, графики если их правильно наложить и вовсе совпадают практически полностью думаю, как раз остальное особенности работы и реализации алгоритма, а может все дело в масштабе, не возьмусь точно утверждать
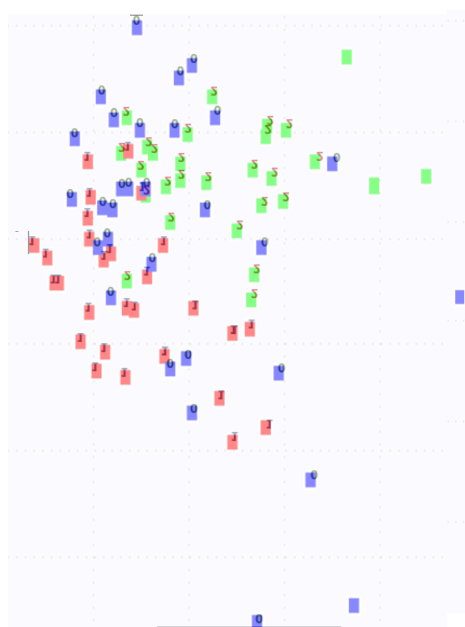
Давайте подведем итоги. Понятно, что опыта у меня мало, чтобы судить объективно, так что буду субъективен.
1. По началу после Python, возврат к .Net и этому фреймворку «вымораживал» жутко. К динамической типизации и удобным манипуляциям с данными быстро привыкаешь. Также раздражали другие названия моделей и то, что их чертовски много и для всего реализован свой класс (ну что поделать такова парадигма C#)
2. Качать проекты целиком не хотелось, а примеры к описанию классов «куцые» в итоге разбор даже того, что я вам сюда выложил, отнял у меня больше времени, чем бы хотелось, с мульти-классовой классификацией я так толком и не разобрался, в scikit-learn, оно как-то намного лучше из коробки выходит.
3. С другой стороны — модель показала такую же точность и даже не пришлось перебирать параметры, думаю и cлучайный лес тоже бы сошелся, если бы я не поленился разобраться с его реализациями.
4. Где это применять? Ну по всей видимости, во-первых, в приложениях, базирующихся на Windows Forms – технологии безусловно почетной и заслуживающей уважения, но уже давно устаревшей и MS не развиваемой, с другой стороны я не пробовал, но вполне возможно, что Аккорд подцепится к универсальным приложениям Windows и тогда с его помощью можно будет решать задачи машинного обучения и анализа данных в малых устройствах под управлением Windows IoT.
5. Если кого интересует кроссплатформенность, то да — она есть! Не поленился поставил себе на вторую систему (Mint) MonoDevelop и проверил, проект собирается и запускается, а значит и под MacOS должно тоже пойти.
Учитывая большое количество фанатов C# и их оптимистичные комментарии на сайте проекта, думаю у данного фреймворка, как и в целом у применения C# в области науки о данных есть право на жизнь, пусть и какую-то слегка маргинальную.
Ну всё, на этом все обещания, которые я дал в статье «Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science» — выполнены, так что могу ненадолго уйти на покой с чистой совестью.
Всем успехов и хороших выходных!
Итак, в прошлой статье цикла, посвящённого обучению Data Science с нуля, мы с вами разбирали вопрос создания своего собственного набора данных и обучение моделей из библиотеки scikit-learn (Python) на примере задачи классификации спектров излучения ламп и дневного света.
В этот раз, чтобы набор данных не пропадал мы рассмотрим и сопоставим нашей прошлой статье маленький кусочек задачи машинного обучения, но в этот раз реализованный на C#
Милости прошу всех под кат.
Для начала надо отметить, что машинное обучение, Python и C# я знаю одинаково плохо, ну то есть почти никак, поэтому данная статья вряд ли подарит читателю, какой-то виртуозный код или особо ценную информацию. В прочем мы такую цель и не ставим, ведь правда?
Фрагменты кода и данные, как и прежде можно взять на GitHub
Часть 1. Прелюдия
Вкратце напомню о чем шла речь в прошлой статье:
С помощью открытого проекта Spectralworkbench (Public Lab), я собрал для вас небольшую коллекцию спектров дневного света, люминесцентных ламп и светодиодных ламп предположительно различных оттенков белого света и с различным качеством цветопередачи. В наборе содержалось по 30 обучающих образцов каждого класса и по 11 контрольных соответственно.
Дальше после долгих моих разглагольствований мы наконец приступили к непосредственно машинному обучению и в итоге обучили: классификаторы RandomForestClassifier и LogisticRegression, в том числе с подбором параметров, также побаловались с отображением признаков в двухмерном виде с помощью T-SNE и PCA, под конец попробовали сделать кластеризацию данных с помощью DBSCAN, ну а завершила статью моя эпичная битва с компьютером, которую я к сожалению проиграл с результатом в пару % точности предсказания.
Часть 2. Ария
Итак, беглый поиск в Интернете говорит, о том, что Accord.NET один из самых популярных в экосистеме .Net, видимо по тому, что в первую очередь заточен под C#, хотя есть и другие, например, Angara (заточена под F#). Безусловно платформа позволяет запускать фреймворки на всех языках .Net (ну или точно подавляющем большинстве языков).
Первое, что бросается в глаза, это все же на порядок меньшая популярность фреймворка по сравнению с решениями на Python или R, как следствие полагаться придется на примеры и документацию, документация, для новичка могла бы быть и побольше разжёвана, а примеры в основном встречаются в виде уже собранных проектов, которые хорошо бы открывать в Visual Studio. После целого моря информации по машинному обучению c Питоном, это немного отталкивает, видимо именно поэтому в данном случае я ограничился только классификацией (SVM) и отображением признаков с помощью PCA.
Итак, нам понадобится MS Visual Studio (у меня была 2015) или MonoDevelop (например, для Linux).
В принципе можно воспользоваться инструкцией для быстрого старта, а можно поверить мне на слово. Пример буду приводить для Visual Studio:
- Создаём новое консольное приложение.
- Добавляем ссылку на сборку System.Windows.Forms.dll, она нам пригодится для отображения графиков.
- Добавляем пакеты NuGet: Accord, Accord.Controls, Accord.IO, Accord.MachineLearning, Accord.Statistics (часть из них итак добавиться сама, когда один потянет другие)
- Начинаем «кодить»
Открываем Program.cs и добавляем пространства имен:
using System;
using System.Linq;
using Accord.Statistics.Models.Regression.Linear;
using Accord.Statistics.Analysis;
using Accord.IO;
using Accord.Math;
using System.Data;
using Accord.MachineLearning.VectorMachines.Learning;
using Accord.Math.Optimization.Losses;
using Accord.Statistics.Kernels;
using Accord.Controls;
Дальше для простоты все запихнем в базовый класс
class Program
{
static void Main(string[] args)
{
Итак:
Читаем данные, к сожалению удобной библиотеки, Pandas у нас нет, но есть аналоги (хоть и менее удобные на мой взгляд).
Один из минусов, это опять-таки не очевидность, я собрал пару «велосипедов» прежде чем понял, что Accord предлагает свое решение для обработки csv или xsls при желании.
//This is a program for demonstrating machine
//learning and classifying the spectrum of light sources using .net
//read data (If you use linux do not forget to correct the path to the files)
string trainCsvFilePath = @"data\train.csv";
string testCsvFilePath = @"data\test.csv";
DataTable trainTable = new CsvReader(trainCsvFilePath, true).ToTable();
DataTable testTable = new CsvReader(testCsvFilePath, true).ToTable();
// Convert the DataTable to input and output vectors (train and test)
int[] trainOutputs = trainTable.Columns["label"].ToArray<int>();
trainTable.Columns.Remove("label");
double[][] trainInputs = trainTable.ToJagged<double>();
int[] testOutputs = testTable.Columns["label"].ToArray<int>();
testTable.Columns.Remove("label");
double[][] testInputs = testTable.ToJagged<double>();
Собственно, обучаем модель классификатора, если вам уже впиталась в душу терминология scikit-learn, то по началу будет не привычно. Но в принципе все должно быть понятно в teacher запихиваем класс модели, потом обучаем ее на данных, потом вызываем предсказание меток (напомню: 0 – светодиод, 1 – лампа, — 2 дневной свет)
// training model SVM classifier
var teacher = new MulticlassSupportVectorLearning<Gaussian>()
{
// Configure the learning algorithm to use SMO to train the
// underlying SVMs in each of the binary class subproblems.
Learner = (param) => new SequentialMinimalOptimization<Gaussian>()
{
// Estimate a suitable guess for the Gaussian kernel's parameters.
// This estimate can serve as a starting point for a grid search.
UseKernelEstimation = true
}
};
// Learn a machine
var machine = teacher.Learn(trainInputs, trainOutputs);
// Obtain class predictions for each sample
int[] predicted = machine.Decide(testInputs);
Дальше распечатаем данные (результат будет, чуть позже на картинке)
// print result
int i = 0;
Console.WriteLine("results - (predict ,real labels)");
foreach (int pred in predicted)
{
Console.Write("({0},{1} )", pred, testOutputs[i]);
i++;
}
//calculate the accuracy
double error = new ZeroOneLoss(testOutputs).Loss(predicted);
Console.WriteLine("\n accuracy: {0}", 1 - error);
Ну и финальный аккорд — трансформируем данные с помощью PCA и выведем диаграмму рассеяния
// consider the decrease in the dimension of features using PCA
var pca = new PrincipalComponentAnalysis()
{
Method = PrincipalComponentMethod.Center,
Whiten = true
};
pca.NumberOfOutputs = 2;
MultivariateLinearRegression transform = pca.Learn(trainInputs);
double[][] outputPCA = pca.Transform(trainInputs);
// print it on the scatter plot
ScatterplotBox.Show(outputPCA, trainOutputs).Hold();
Console.ReadLine();
Ну вот, что получилось в итоге:
Давайте сравним с тем что поучилось в прошлой статье для
Логистической регрессии с подобранными параметрами
(предсказание, факт):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2), (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
accuracy on test data: 0.81818
как видите результат сопоставим.
Посмотрим на график PCA.
Ну в принципе похоже, но немного отличается, разработчики на своем сайте утверждают, что «все в порядке так и должно быть, все равно все скорей всего правильно, просто таковы особенности алгоритмов» (ну близко к тексту).
UPD: Спасибо AirLight
Как выяснилось, графики если их правильно наложить и вовсе совпадают практически полностью думаю, как раз остальное особенности работы и реализации алгоритма, а может все дело в масштабе, не возьмусь точно утверждать
Часть 3. Финал.
Давайте подведем итоги. Понятно, что опыта у меня мало, чтобы судить объективно, так что буду субъективен.
1. По началу после Python, возврат к .Net и этому фреймворку «вымораживал» жутко. К динамической типизации и удобным манипуляциям с данными быстро привыкаешь. Также раздражали другие названия моделей и то, что их чертовски много и для всего реализован свой класс (ну что поделать такова парадигма C#)
2. Качать проекты целиком не хотелось, а примеры к описанию классов «куцые» в итоге разбор даже того, что я вам сюда выложил, отнял у меня больше времени, чем бы хотелось, с мульти-классовой классификацией я так толком и не разобрался, в scikit-learn, оно как-то намного лучше из коробки выходит.
3. С другой стороны — модель показала такую же точность и даже не пришлось перебирать параметры, думаю и cлучайный лес тоже бы сошелся, если бы я не поленился разобраться с его реализациями.
4. Где это применять? Ну по всей видимости, во-первых, в приложениях, базирующихся на Windows Forms – технологии безусловно почетной и заслуживающей уважения, но уже давно устаревшей и MS не развиваемой, с другой стороны я не пробовал, но вполне возможно, что Аккорд подцепится к универсальным приложениям Windows и тогда с его помощью можно будет решать задачи машинного обучения и анализа данных в малых устройствах под управлением Windows IoT.
5. Если кого интересует кроссплатформенность, то да — она есть! Не поленился поставил себе на вторую систему (Mint) MonoDevelop и проверил, проект собирается и запускается, а значит и под MacOS должно тоже пойти.
Учитывая большое количество фанатов C# и их оптимистичные комментарии на сайте проекта, думаю у данного фреймворка, как и в целом у применения C# в области науки о данных есть право на жизнь, пусть и какую-то слегка маргинальную.
Ну всё, на этом все обещания, которые я дал в статье «Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science» — выполнены, так что могу ненадолго уйти на покой с чистой совестью.
Всем успехов и хороших выходных!

