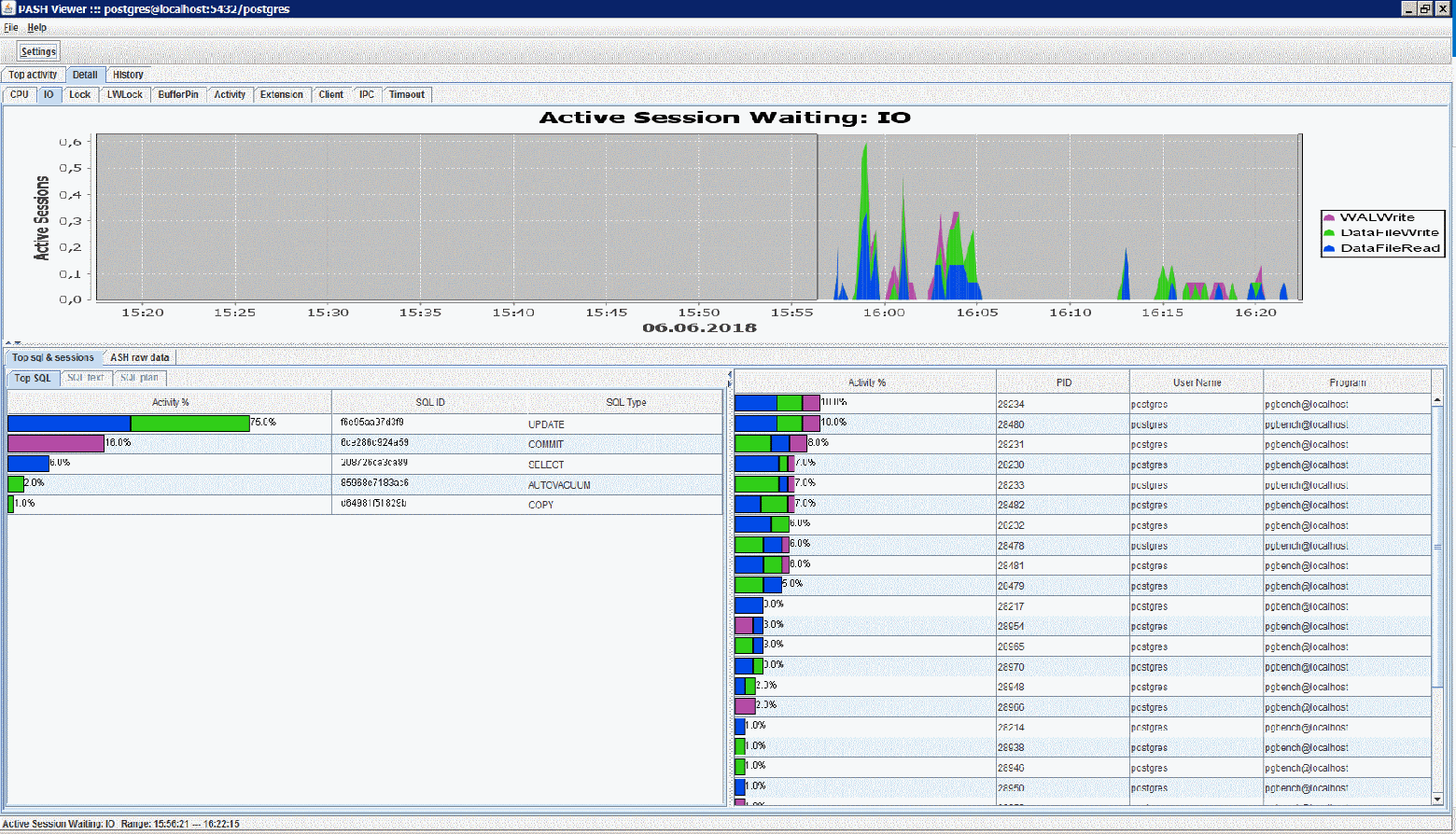
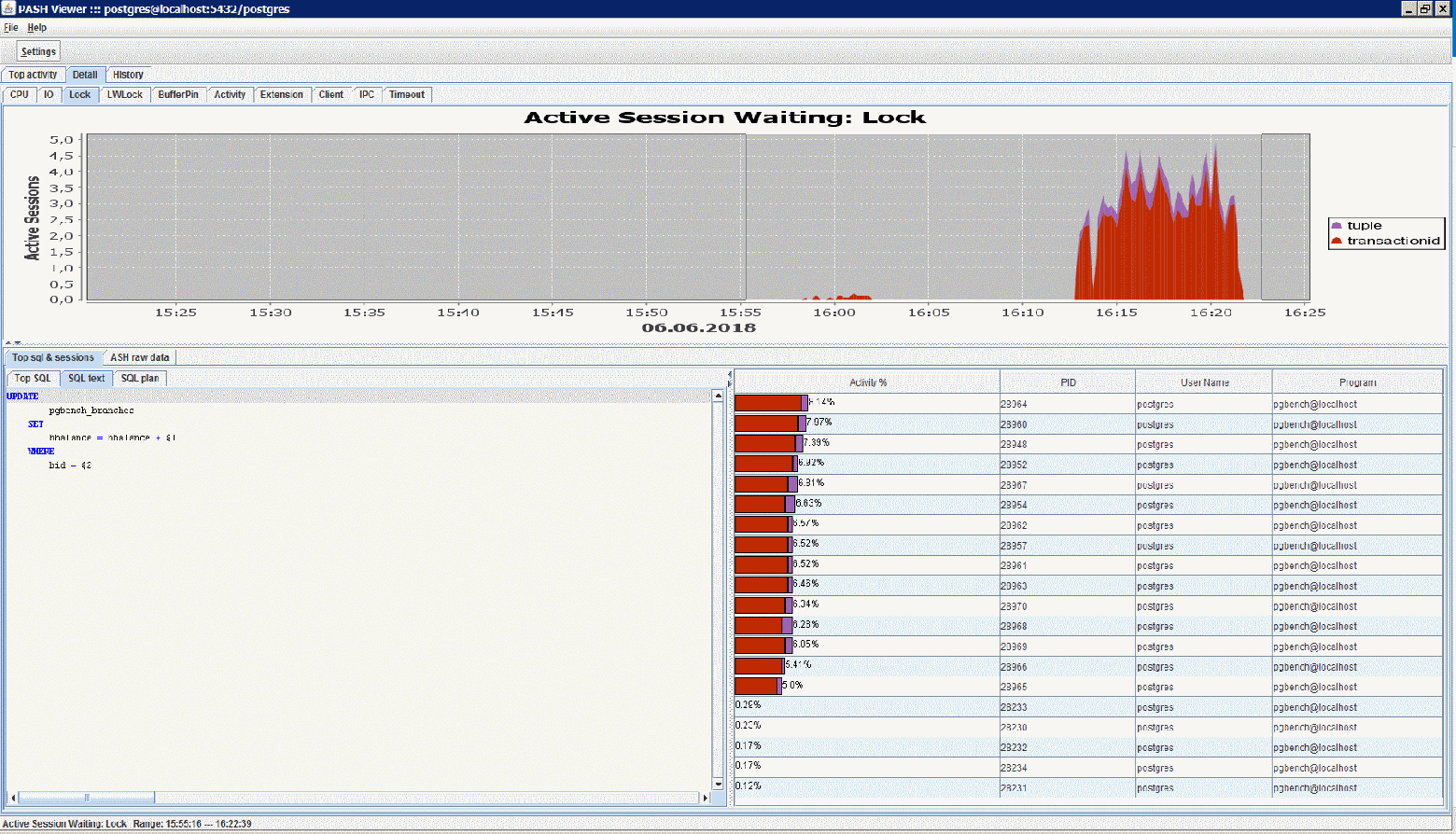
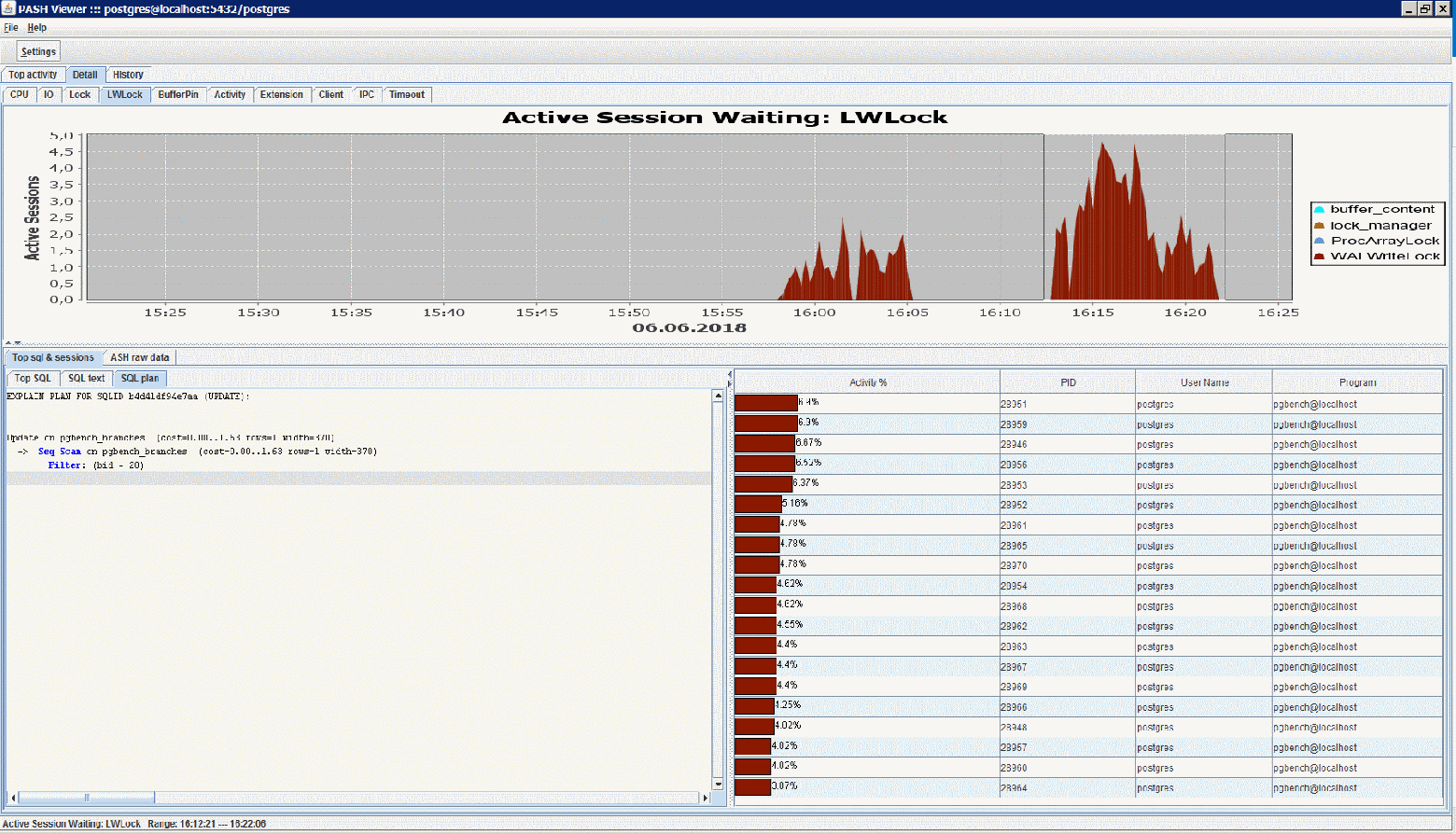
Данный инструмент написан из спортивного интереса, когда мною было обнаружено, что вьюха pg_stat_activity в PostgreSQL 10 имеет поля wait_event_type и wait_event, очень похожие по сути на оракловые wait_class и event из v$session.
Активно работая в данный момент с программой ASH-Viewer от akardapolov мне стало любопытно — насколько сложно переписать этот продукт под Postgres. Учитывая, что я не профессиональный разработчик, было не просто, но очень интересно. По ходу дела даже нашёл, как мне кажется, пару значительных багов, которые проявляются и в оригинальной программе для Oracle, по кр.мере для Standard Edition.
Принципы работы PASH-Viewer:
Не нужны никакие расширения. Берём данные исключительно из встроенной вьюхи pg_stat_activity.
Раз в секунду делается запрос активных сессий:
текст запроса к pg_stat_activity
SELECT current_timestamp, datname, pid, usesysid, usename, application_name, backend_type, coalesce(client_hostname, client_addr::text, 'localhost') as client_hostname, wait_event_type, wait_event, query, query_start, 1000 * EXTRACT(EPOCH FROM (clock_timestamp()-query_start)) as duration from pg_stat_activity where state='active' and pid != pg_backend_pid();
Раз в 15 секунд данные за последние 15 снимков усредняются и выводятся на график.
SQL id, который нужен для группировки запросов в разделе Top SQL, я генерирую сам, он не имеет никакого отношения к queryid из pg_stat_statements. Я думал, как использовать queryid, но к сожалению не нашёл способа сопоставить запросы из этих двух представлений. Было бы здорово, если бы разработчики добавили поле queryid в pg_stat_activity.
SQL id = первые 13 символов от md5 (нормализованный текст запроса).
Нормализованный текст запроса — это запрос, в котором удалены символы новых строк и лишние пробелы, а литералы заменены на $1, $2 и т.д… Написать хорошую функцию нормализации запроса для меня было сложно. Я написал плохую. Текст привожу, но вы его пожалуйста не смотрите, а то мне стыдно. Лучше пришлите хорошую.
NormalizeSQL
public static String NormalizeSQL(String sql) { sql = sql.replaceAll("\\n", " "); sql = sql.replaceAll("\\(", " ( "); sql = sql.replaceAll("\\)", " ) "); sql = sql.replaceAll(",", " , "); sql = sql.replaceAll("'", " ' "); sql = sql.replaceAll("=", " = "); sql = sql.replaceAll("<", " < "); sql = sql.replaceAll(">", " > "); sql = sql.replaceAll(";", ""); sql = sql.replaceAll("[ ]+", " "); sql = sql.replaceAll("> =", ">="); sql = sql.replaceAll("< =", "<="); sql = sql.toLowerCase().trim(); String[] array = sql.split(" ", -1); int var_number = 0; String normalized_sql = ""; Boolean quote_flag = false; for (int i = 0; i < array.length; i++) { if (array[i].equals("'")) { if (!quote_flag) { quote_flag = true; var_number++; normalized_sql += "$" + var_number + " "; } else { quote_flag = false; } } else if (quote_flag) { continue; } else if (array[i].matches("-?\\d+(\\.\\d+)?")) { var_number++; normalized_sql += "$" + var_number + " "; } else if (array[i].equals("order")) { for (int j = i; j < array.length; j++) { normalized_sql += array[j] + " "; } return normalized_sql.trim(); } else { normalized_sql += array[i] + " "; } } return normalized_sql.trim(); }
С планом выполнения запроса было сложно. Это к Oracle ты приходишь и говоришь «Дай мне план для sqlid=...», и он тебе отвечает — «Тебе самый последний, или за вчера, или показать все за последний месяц со статистикой выполнения по каждому?». А PostgreSQL тебе отвечает — «А что такое sqlid?».
Поэтому для запросов вида SELEСT/UPDATE/INSERT/DELETE посылаем в БД команду EXPLAIN и сохраняем результат локально. Делаем это не чаще 1 раза в час. В процессе отладки обнаружилось, что EXPLAIN висит на блокировке так же, как висел бы сам запрос, для которого мы хотим узнать план. Поэтому пришлось добавить setQueryTimeout(1).
И работает это только в том случае, если запрос выполнялся в той же БД, к который вы подключились (указывается при настройке соединения). И только если вы подключились к БД под суперюзером (postgres), чего некоторые, возможно, побоятся. Поэтому можно создать специального пользователя для мониторинга. Будет работать всё, кроме отображения планов.
CREATE USER pgmonuser WITH password 'pgmonuser'; GRANT pg_monitor TO pgmonuser;
Скачать с GitHub: https://github.com/dbacvetkov/PASH-Viewer/releases
UPD:
В версии 0.3 добавил поддержку PostgreSQL 9.6 (там всего два класса ожиданий — Lock и LWLock, всё остальное идёт как «CPU») и PostgreSQL 9.4 — 9.5 (там вообще либо CPU либо ожидание Lock).
В версии 0.3.1 добавил поле Backend Type в Top Sessions и избавился от белых полос на графике.
В версии 0.3.2 улучшил работу с планами, добавил некоторую статистику по запросам (AVG Duration, Calls Count) и возможность просматривать исторические данные:
How-to-create-pg_stat_activity-historical-table.
Спасибы и приветы:
Александру Кардаполову за ASH-Viewer.
Антону Глушакову за консультацию и тестирование.
Дмитрию Рудопысову за то, что объяснил, как компилировать и запускать скачанный с github проект.
Ещё слайды: