
В прошлый раз мы рассмотрели вариант генерации импульсов для шаговых двигателей, частично вынесенный с программного на микропрограммный уровень. В случае полного успеха, это сулит отсутствие необходимости обрабатывать прерывания, поступающие с частотой вплоть до 40 КГц. Но тот вариант обладает рядом явных недостатков. Во-первых, там не поддерживаются ускорения. Во-вторых, гранулярность допустимых частот шагов в том решении — сотни герц (например, возможна выработка частот 40000 Гц и 39966 Гц, но невозможна выработка частот с величиной между этими двумя значениями).
Реализация ускорений
Можно ли устранить указанные недостатки, пользуясь средствами всё тех же UDB, не усложняя систему? Давайте разбираться. Начнём с самого сложного — с ускорений. Ускорения добавляются в начале и конце пути. Во-первых, если на шаговый двигатель подать сразу импульсы высокой частоты, ему потребуется больший ток, чтобы начать работу. Высокий допустимый ток — это нагрев и шум, поэтому лучше его ограничивать. Но тогда двигатель может пропустить шаги на старте. Так что разгонять двигатель лучше плавно. Во-вторых, если тяжёлая головка останавливается резко, то у неё возникают переходные процессы, связанные с инерцией. На пластике видны волны. Поэтому плавно надо не только разгонять, но и останавливать головку. Классически график скорости двигателя представляют в виде трапеции. Вот фрагмент из исходного кода «прошивки» Marlin:
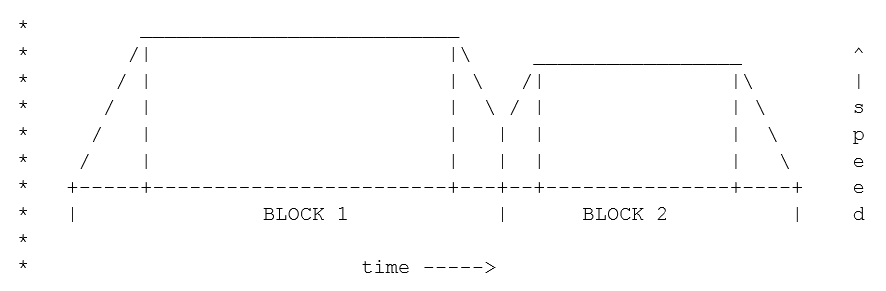
Я не буду даже пытаться прикидывать, можно ли реализовать такое средствами UDB. Виной тому тот факт, что сейчас в моду входит другой вид ускорения: не трапециевидные, а S-Curve. Их график выглядит так:

Такое — точно не для UDB. Сдаёмся? Вовсе нет! Я уже отмечал, что UDB у меня не реализует аппаратный интерфейс, а просто позволяет перенести часть кода с программного на микропрограммный уровень. Пусть профиль обсчитывает центральный процессор, а формирование шаговых импульсов по-прежнему выполняет UDB. У центрального процессора есть уйма времени на расчеты. Задача исключения частых прерываний по-прежнему будет решаться достаточно элегантно, а полного выноса процесса на микропрограммный уровень никто и не планировал.
Само собой, профиль потребуется готовить в памяти, а UDB будет забирать данные оттуда средствами DMA. Но сколько же требуется памяти? На один миллиметр нужно 200 шагов. Сейчас при 24-битном кодировании, это 600 байт на 1 мм перемещения головки! Вновь вспоминаем про не такие частые, но всё-таки постоянные прерывания, чтобы передавать всё фрагментами? Не совсем! Дело в том, что механизм DMA у PSoC основан на дескрипторах. Исполнив задание из одного дескриптора, контроллер DMA переходит к следующему. И так, по цепочке, можно использовать достаточно много дескрипторов. Проиллюстрируем это каким-нибудь рисунком из официальной документации:

Собственно, этим механизмом можно и воспользоваться, построив цепочку из трёх дескрипторов:
| № | Пояснение |
|---|---|
| 1 | Из памяти в FIFO с инкрементом адреса. Указывает на участок с профилем разгона. |
| 2 | Из памяти в FIFO без инкремента адреса. Посылает всё время на одно и то же слово в памяти для постоянной скорости. |
| 3 | Из памяти в FIFO с инкрементом адреса. Указывает на участок с профилем торможения. |
Получается, что основной путь описывается на шаге 2, а там физически используется одно и то же слово, задающее постоянную скорость. Расход памяти — не велик. В реальности, второй дескриптор физически может быть представлен двумя или тремя дескрипторами. Это связано с тем, что максимальная длина перекачки, согласно утверждениям TRM, может быть 64 килобайта (поправка будет ниже). То есть, 32767 слов. Что при 200 шагах на миллиметр будет соответствовать пути 163 миллиметра. Возможно, придётся делать отрезок из двух-трёх частей, в зависимости от максимальной дистанции, которую может пройти двигатель за один раз.
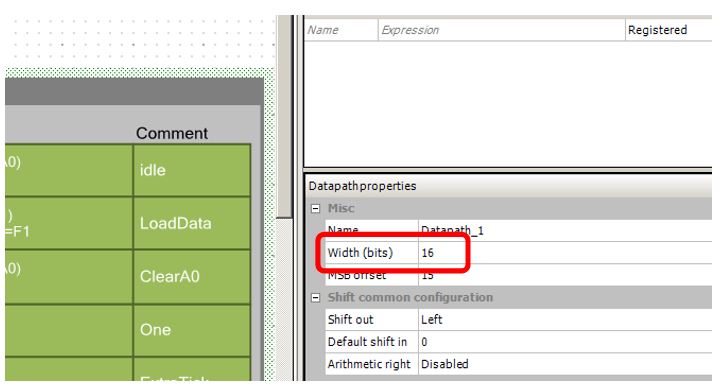
Тем не менее, для экономии памяти (да и расхода блоков UDB) предлагаю отказаться от 24-битных блоков DatapPath, перейдя на более экономичные 16-битные.
Итак. Первое предложение на доработку.
В памяти готовятся массивы, кодирующие длительности шагов. Далее, эти сведения уходят в UDB средствами DMA. Прямолинейный участок кодируется массивом из одного элемента, блок DMA не увеличивает адрес, выбирая всё время один и тот же элемент. Участки разгона, прямолинейного движения и торможения связываются средствами, имеющимися в контроллере DMA.
Точная подстройка средней частоты
Теперь рассмотрим, как можно победить проблему гранулярности частоты. Точно её задавать, разумеется, не удастся. Но, собственно, оригинальные «прошивки» тоже не могут этого сделать. Вместо этого они пользуются алгоритмом Брезенхема. К некоторым шагам добавляется задержка на один такт. В результате, средняя частота становится промежуточной, между меньшим и большим значением. Регулируя соотношение штатных и удлинённых периодов, можно плавно менять среднюю частоту. Если скорость у нас теперь задаётся не через регистр данных, а передаётся через FIFO, а число импульсов вообще задаётся через число переданных по DMA слов, оба регистра данных в UDB высвобождаются. Кроме того, высвобождается и один из аккумуляторов, который подсчитывал число импульсов. Вот на них и построим некий ШИМ.
Обычно в АЛУ сравниваются и присваиваются регистры с одним и тем же индексом. Когда у одного регистра индекс 0, а у другого — 1, не любой вариант операции может быть реализован. Но мне удалось сложить пасьянс из регистров, при котором ШИМ может быть сделан. Получилось так, как показано на рисунке.
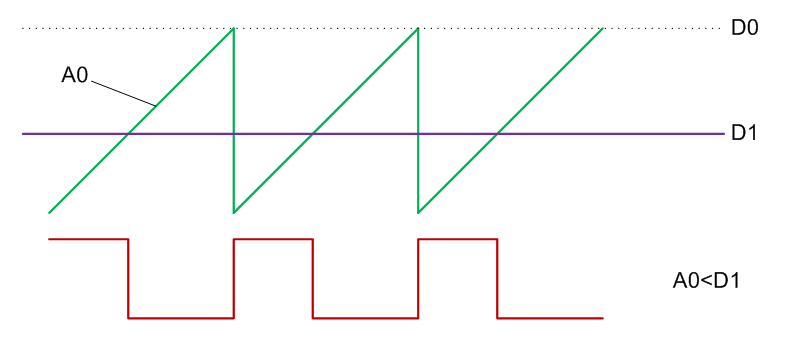
Когда выполняется условие A0<D1, к заданной длине импульса будем добавлять лишний такт. Когда условие не выполняется — не будем.
Сферический конь в обычных условиях
Итак, начинаем модифицировать разработанный блок для UDB с учётом новой архитектуры. Заменяем разрядность Datapath:
Нам понадобится намного больше выходов из Datapath, чем в прошлый раз.
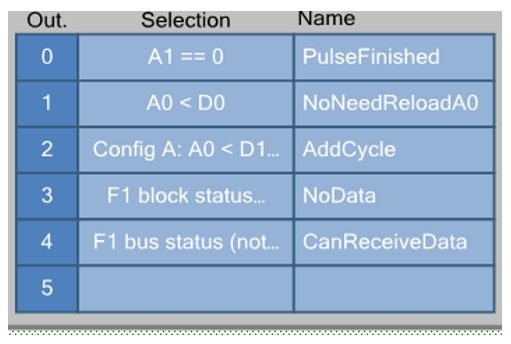
Дважды щёлкнув по ним, видим подробности:
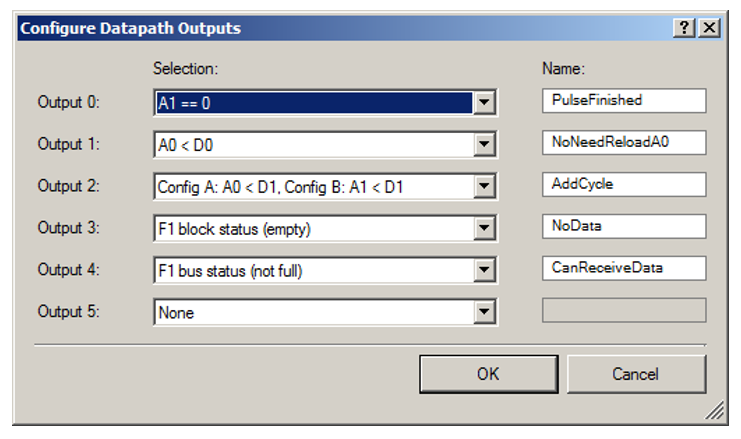
Разрядов у переменной State стало больше, не забудем подключить старший!!! В старом варианте там была константа 0.
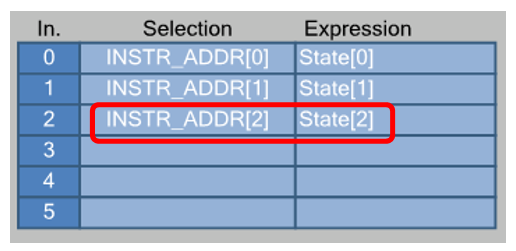
Граф переходов автомата у меня получился вот такой:

Мы находимся в состоянии Idle, пока пуст FIFO1. Кстати, работа именно с FIFO1, а не FIFO0 — результат того самого складывания пасьянса. Регистр A0 используется для реализации ШИМ, поэтому длительность импульса определяется регистром A1. А загружать его я могу только из FIFO1 (возможно, есть иные тайные методы, но мне они не известны). Поэтому DMA закачивает данные именно в FIFO1, и именно по состоянию «Не пуст» для FIFO1 произойдёт выход из состояния Idle.
АЛУ в состоянии IDLE зануляет регистр A0:

Это нужно, чтобы при начале работы ШИМ всегда начинал бы работу с начала.
Но вот в FIFO попали данные. Автомат переходит в состояние LoadData:

В этом состоянии АЛУ загружает очередное слово из FIFO в регистр A1. Попутно, чтобы не создавать лишние состояния, увеличивается значение счётчика A0, который используется для работы с ШИМ:

Если счётчик A0 ещё не достиг значения D0 (то есть, срабатывает условие A0<D0, взводящее флаг NoNeedReloadA0), мы идём в состояние One. Иначе — в состояние ClearA0.
В состоянии ClearA0 АЛУ просто зануляет значение A0, начиная новый цикл работы ШИМ:

после чего автомат также переходит в состояние One, просто на один такт позже.
Состояние One нам знакомо из старой версии автомата. АЛУ в нём не выполняет никаких функций.
А так — в этом состоянии на выходе Out_Step вырабатывается единица (здесь оптимизатор сработал лучше, когда единица вырабатывается по условию, это было выявлено опытным путём).
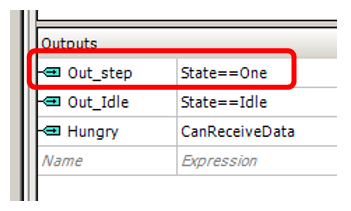
Мы находимся в этом состоянии, пока не обнулится уже известный нам семибитный счётчик. Но если раньше из этого состояния мы выходили по одному пути, то сейчас путей может быть два: прямой и с задержкой на такт.

В состояние ExtraTick мы попадём, если взведён флаг AddCycle, который назначен на выполнение условия A0<D1. В этом состоянии АЛУ не выполняет никаких полезных действий. Просто цикл выполняется на 1 такт дольше. Дальше все пути сойдутся в состоянии Delay.
Это состояние отмеряет длительность импульса. Регистр A1 (загруженный ещё в состоянии Load) уменьшается, пока не достигнет нуля.

Дальше, в зависимости от того, есть в FIFO дополнительные данные или их нет, автомат перейдёт на выборку очередной порции в состояние Load или в состояние Idle. Давайте посмотрим это не на рисунке (там длинные стрелки, всё будет мелко), а в виде таблицы, дважды щёлкнув по состоянию Delay:

Теперь выходы из UDB. Флаг нахождения в состоянии Idle я переделал на асинхронное сравнение (в прошлой версии был триггер, который взводился и сбрасывался в различных состояниях), так как для него оптимизатор показал лучший результат. Плюс добавился флаг Hungry, сигнализирующий блоку DMA готовность к приёму данных. Он заведён на флаг «FIFO1 не переполнено». Раз не переполнено, то DMA может загрузить туда очередное слово данных.

По автоматной части — всё.
На схему основного проекта добавляем блоки DMA. Прерывания я пока завёл на флаги окончания DMA, но не факт, что это правильно. Когда процесс прямого доступа к памяти завершён, можно начать новый процесс, относящийся к тому же отрезку, но нельзя начинать заполнение сведений о новом отрезке. В FIFO ещё находится от трёх до четырёх элементов. В это время ещё нельзя перепрограммировать регистры D0 и D1 блока на базе UDB, они ещё нужны для работы. Поэтому, возможно, потом будут добавлены прерывания на основании выходов Out_Idle. Но та кухня уже не будет относиться к программированию блоков UDB, поэтому мы упомянем её только вскользь.

Программные эксперименты
Так как сейчас всё не изведано, не будем писать никаких специальных функций. Все проверки будем проводить «В лоб». Потом, на основании удачных экспериментов, может быть будут написаны функции API. Итак. Функцию main() сделаем минималистичной. Она просто настраивает систему и вызывает выбранный тест.
int main(void) { CyGlobalIntEnable; /* Enable global interrupts. */ // isr_1_StartEx(StepperFinished); StepperController_X_Start(); StepperController_Y_Start(); StepperController_Z_Start(); StepperController_E0_Start(); StepperController_E1_Start(); // TestShortSteps(); TestWithPacking (); for(;;) { }
Попробуем послать пачку импульсов, вызвав функцию, проверив факт вставки дополнительного импульса. Вызов функции прост:
TestShortSteps();
А вот тело требует пояснений.
Сначала приведу всю функцию целиком
void TestShortSteps() { // Уменьшим длительность единицы, чтобы можно // было видеть всё на осциллографе // Если сделать меньше, то DMA не будет успевать заполнять!!! // Это надо бы разобраться, почему так медленно!!! StepperController_X_SingleVibrator_WritePeriod (6); // Теперь программируем алгоритм Брезенхема // На пять шагов — три коротких CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // В этом тесте просто шлём массив из двадцати шагов. // Хитрый алгоритм с упаковкой будем проверять чуть позже static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // Инициализировали DMA прямо здесь, так как массив живёт здесь uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // Так как мы всё делаем для опытов, выделили дескриптор для задачи тоже здесь uint8 td = CyDmaTdAllocate(); // Задали параметры дескриптора и длину в байтах. Также сказали, что следующего дескриптора нет. CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); // Теперь задали начальные адреса для дескриптора CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // Подключили этот дескриптор к каналу CyDmaChSetInitialTd(channel, td); // Запустили процесс с возвратом дескриптора к исходному виду CyDmaChEnable(channel, 1); }
Теперь рассмотрим важные её части.
Если длина положительной части импульса будет равна 92 тактам, то на осциллографе будет не разглядеть, есть там в отрицательной части какая-то однотактовая вставка или нет. Масштаб будет не тот. Надо сделать положительную часть как можно короче, чтобы полный импульс был бы сопоставим по масштабу со вставляемым тактом. Поэтому я принудительно изменяю период счётчика, задающего длительность положительной части импульса:
// Уменьшим длительность единицы, чтобы можно // было видеть всё на осциллографе // Если сделать меньше, то DMA не будет успевать заполнять!!! // Это надо бы разобраться, почему так медленно!!! StepperController_X_SingleVibrator_WritePeriod (6);
Но почему целых шесть тактов? Почему не три? Почему не два? Почему, в конце концов, не один? Это грустная история. Если положительный импульс короче, чем 6 тактов, то система не работает. Долгая отладка на осциллографе с выводом проверочных линий наружу, показала, что DMA — штука не быстрая. Если автомат работает меньше определённой длительности, то к моменту выхода из состояния Delay, FIFO чаще всего ещё пусто. В него может быть ещё не помещено ни одного нового слова данных! И только когда положительная часть импульса имеет длительность 6 тактов, FIFO гарантированно успеет загрузиться…
Лирическое отступление о латентности
Ещё одна идея фикс, которая сидит у меня в голове, — аппаратное ускорение тех или иных функций ядра нашей ОСРВ МАКС. Но увы, все мои лучшие идеи разбиваются о те самые латентности.
Было дело, я изучил разработку Bare Metal приложений под Cyclone V SoC. Но оказалось, что работа с одиночными регистрами FPGA (когда попеременно идёт то запись в них, то чтение из них) снижает работу ядра в сотни (!!!) раз. Вы не ослышались. Именно в сотни. Причём всё это слабо документировано, но я сначала нутром почуял, а затем доказал по обрывкам фраз из документации, что виноваты латентности при прохождении запросов через кучу мостов. Если надо прогнать большой массив, там латентность тоже будет, но в пересчёте на одно прокачанное слово, она будет не существенной. Когда запросы одиночные (а аппаратное ускорение ядра ОС подразумевает именно их), замедление идёт именно в сотни раз. Намного быстрее получится всё сделать чисто программным путём, когда программа работает с основной памятью через кэш на бешеной скорости.
На PSoC у меня тоже были определённые планы. С виду, можно замечательно искать данные в массиве, используя DMA и UDB. Да что уж там! За счёт дескрипторной структуры DMA у этих контроллеров можно было бы вести полностью аппаратный поиск в связных списках! Но получив описанный выше затык, я понял, что он тоже связан с латентностью. Здесь эта латентность прекрасно описана в документации. Как в TRM на семейство, так и в отдельном документе AN84810 — PSoC 3 and PSoC 5LP Advanced DMA Topics. Там этому посвящён раздел 3.2. Так что очередное аппаратное ускорение отменяется. А жалко. Но, как говорил Семён Семёнович Горбунков: «Будем искать».
Продолжаем программные эксперименты
Далее, я задаю параметры алгоритма Брезенхема:
// Теперь программируем алгоритм Брезенхема // На пять шагов — три коротких CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2);
Ну, и дальше идёт штатный код, передающий массив слов через DMA в FIFO1 блока управления двигателем X.
Результат требует некоторых пояснений. Вот он:
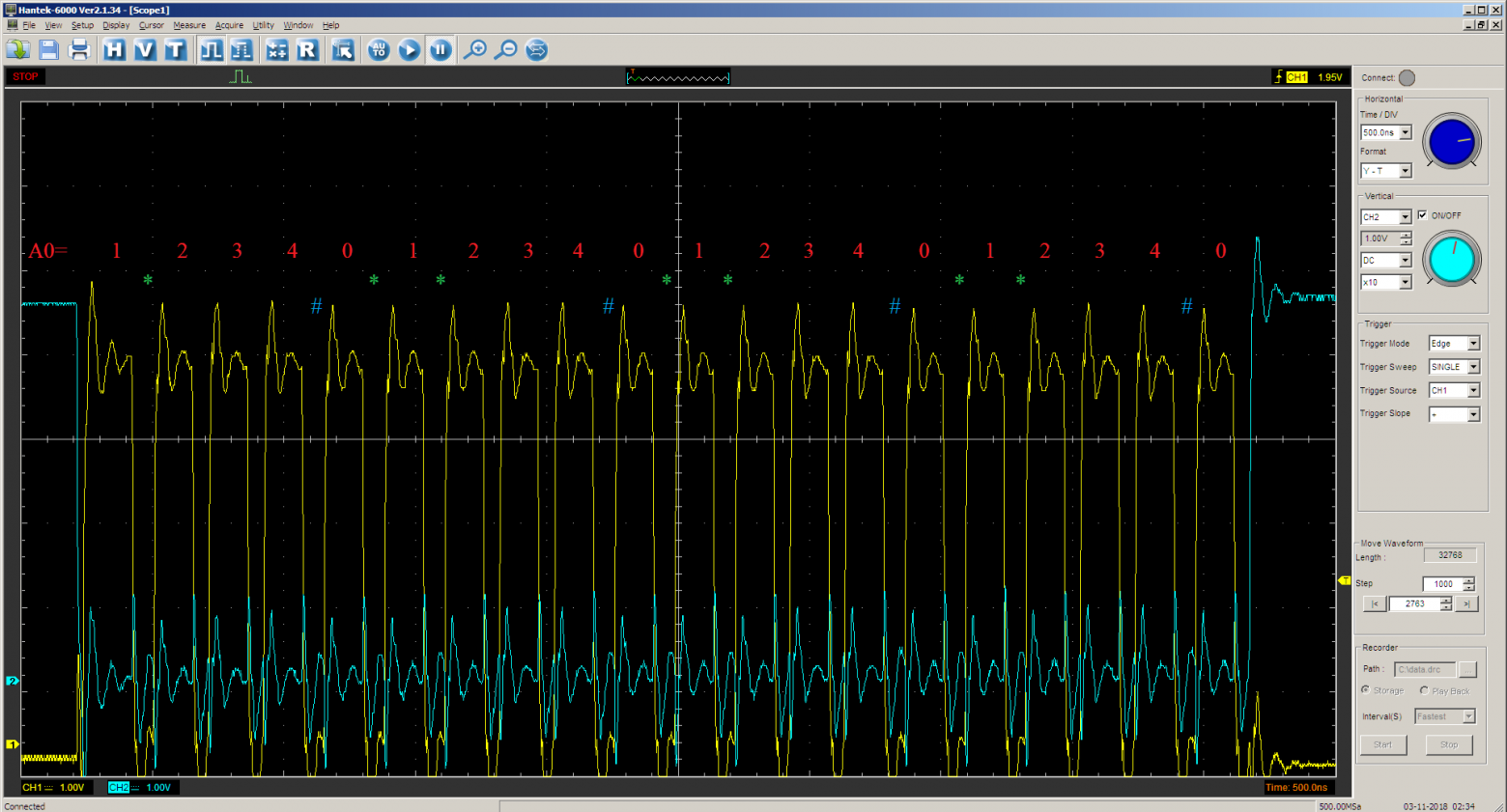
Красным показано значение счётчика A0, когда автомат находится в состоянии One. Зелёной звёздочкой показаны случаи, когда задержка вставлена за счёт нахождения автомата в состоянии ExtraTick. Есть ещё такты, где задержка обусловлена нахождением в состоянии ClearA0, они отмечены синей решёткой.
Как видно, при первом входе самая первая задержка теряется. Это связано с тем, что A0 сброшен при нахождении в Idle, но увеличивается при входе в LoadData. Поэтому к точке анализа (выходу из состояния One) он уже равен единице. Счёт начинается с неё. Но в целом, на среднюю частоту это не повлияет. Это просто надо иметь в виду. Как надо иметь в виду, что при сбросе A0 также будет вставляться такт. Его надо учитывать при расчетах средней частоты.
А в целом, число импульсов верное. Их длительность тоже правдоподобна.
Попробуем запрограммировать более реальную цепочку дескрипторов,
состоящую из участка разгона, линейного движения и торможения.
void TestWithPacking(int countOnLinearStage) { // Уменьшим длительность единицы, чтобы можно // было видеть всё на осциллографе. // Если сделать меньше, то DMA не будет успевать заполнять!!! // Это надо бы разобраться, почему так медленно!!! StepperController_X_SingleVibrator_WritePeriod (6); // Теперь программируем алгоритм Брезенхема // На пять шагов — три коротких CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // Профиль участка разгона static const uint16 accelerate[] = {0x0010,0x0008,0x0004}; // Профиль участка торможения static const uint16 deccelerate[] = {0x004,0x0008,0x0010}; // Число доп. тактов для линейного участка. static const uint16 steps[] = {0x0001}; // Инициализировали DMA прямо здесь, так как массив живёт здесь uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // Дескриптор торможения uint8 tdDeccelerate = CyDmaTdAllocate(); CyDmaTdSetConfiguration(tdDeccelerate, sizeof(deccelerate), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdDeccelerate, LO16((uint32)deccelerate), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // Тот самый хитрый дескриптор линейных шагов uint8 tdSteps = CyDmaTdAllocate(); // инкремент адреса закомментирован!!! // Имеется ссылка на следующий дескриптор!!! CyDmaTdSetConfiguration(tdSteps, countOnLinearStage, tdDeccelerate, /*TD_INC_SRC_ADR |*/ TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdSteps, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // Дескриптор разгона // Имеется ссылка на следующий дескриптор!!! uint8 tdAccelerate = CyDmaTdAllocate(); CyDmaTdSetConfiguration(tdAccelerate, sizeof(accelerate), tdSteps, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdAccelerate, LO16((uint32)accelerate), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // Подключили этот дескриптор к каналу CyDmaChSetInitialTd(channel, tdAccelerate); // Запустили процесс с возвратом дескриптора к исходному виду CyDmaChEnable(channel, 1); }
Сначала вызовем для тех же десяти шагов (в DMA фактически уходят 20 байт):
TestWithPacking (20);
Результат соответствует ожиданию. В начале виден разгон. А выход в IDLE (голубой луч) происходит с большой задержкой от последнего импульса, именно тогда полностью завершён последний шаг, его величина примерно равна величине первого.
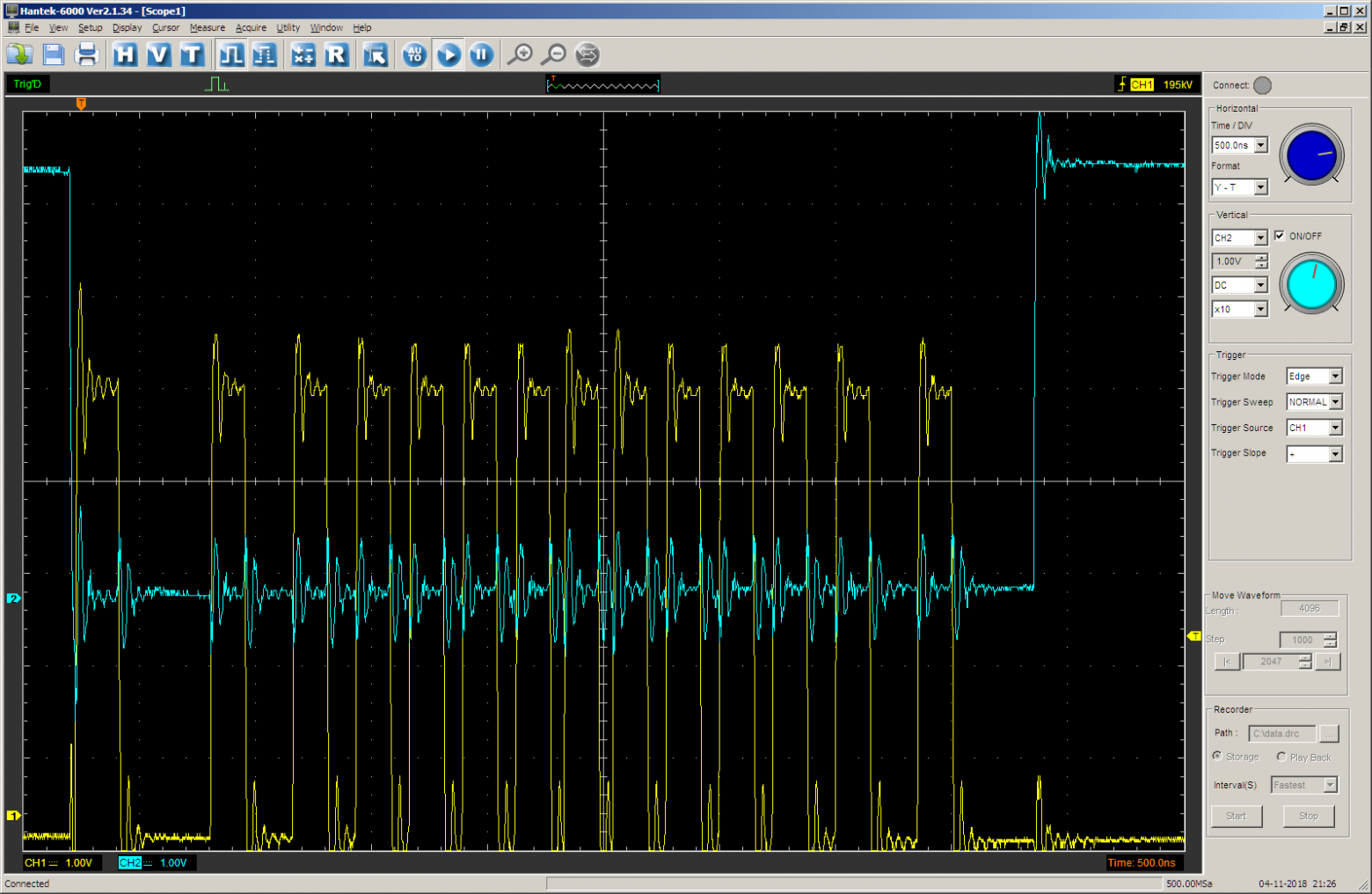
Реальный конь в обычных условиях
При переделке аппаратуры я как-то лихо перескочил с 24-битного задания длительности импульса на 16-битный. Но мы же выяснили, что так делать нельзя: минимальная частота импульсов будет слишком высокой. Я сделал это умышленно. Дело в том, что методика расширения разрядности 16-битного счётчика оказалась настолько сложна, что начни я её описывать вместе с основным автоматом, она отвлекла бы на себя всё внимание. Поэтому рассмотрим её отдельно.
Аккумулятор у нас 16-битный. Я решил добавить ему в старшие биты штатную сущность «семибитный счётчик». Что такое этот самый семибитный счётчик? Это конструкция, которая имеется в каждом блоке UDB (базовый блок UDB имеет разрядность всех регистров 8 бит, увеличение разрядности определяется объединением блоков в группы). Из тех же ресурсов могут быть реализованы регистры Control/Status. Сейчас у нас на 16 бит данных используется один счётчик и ни одной пары Control/Status. Значит, добавив ещё один счётчик в систему, мы не оттянем на себя лишних ресурсов. Мы просто возьмём то, что и так нам выделено. Вот и славно! Сделаем старший байт счётчика длительности импульса через этот механизм и получим суммарную разрядность счётчика длительности импульса, равную 23 битам.
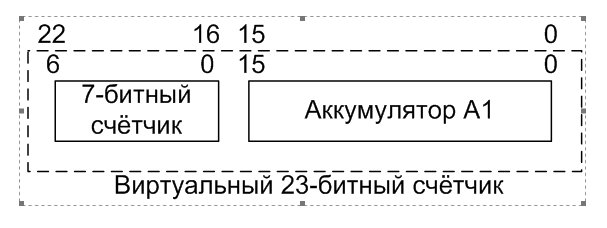
Сначала я проговорю то, о чём думал. Я думал, что после выхода из состояния Delay я буду проверять факт завершения счёта этого дополнительного счётчика. Если он ещё не закончил считать, буду уменьшать его значение и снова переходить в состояние Delay. Если досчитал, логика останется прежней, без добавления лишних тактов.
Мало того, в документации на этот счётчик сказано, что я прав. Дословно там сказано:
PeriodЖизнь показала, что всё иначе. Я вывел состояние линии terminal count на осциллограф и наблюдал его значение при предзагруженном нуле в Period и при программной загрузке. Увы и ах. Никакого constant high state не было!
Defines the initial period register value. For a period of N clocks, the period value should be set to the value of N-1. The counter will count from N-1 down to 0 which results in an N clock cycle period. A period register value of 0 is not supported and will result in the terminal count output held at a constant high state.
Методом проб и ошибок мне удалось заставить систему работать корректно, но для этого хотя бы одно вычитание из счётчика должно произойти! Новое состояние «вычитание» стоит не сбоку. Его пришлось вклинить в обязательный путь. Оно располагается перед состоянием Delay и называется Next65536.

АЛУ в этом состоянии не выполняет никаких полезных действий. Собственно, на факт нахождения в этом состоянии реагирует только новый счётчик. Вот он на схеме:

Вот его свойства более подробно:

В целом, с учётом предыдущих статей суть работы этого счётчика ясна. Выстрадана только строка Enable. Опять же, я до конца не понимаю, зачем его надо включать, когда автомат находится в состоянии LoadData (тогда счётчик перезагружает значение периода). Эту хитрость я позаимствовал из свойств счётчика, управляющего светодиодами, взятого у английского автора блока управления теми светодиодами. Без неё нулевое значение периода не работает. С нею работает.
В код API добавляем инициализацию нового счётчика. Теперь функция старта выглядит так:
void `$INSTANCE_NAME`_Start() { `$INSTANCE_NAME`_SingleVibrator_Start(); //"One" Generator start `$INSTANCE_NAME`_Plus65536_Start(); }
Давайте проверим новую систему. Вот код функции для тестирования
(в ней от уже известного отличается только первая строка):
void JustTest(int extra65536s) { // Установили число дополнительных итераций по 65536 тактов StepperController_X_Plus65536_WritePeriod((uint8) extra65536s); // Теперь программируем алгоритм Брезенхема // На пять шагов — три коротких CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // В этом тесте просто шлём массив из четырёх шагов. // Хитрый алгоритм с упаковкой будем проверять чуть позже static const uint16 steps[] = { 0x1000,0x1000,0x1000,0x1000 }; // Инициализировали DMA прямо здесь, так как массив живёт здесь uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // Так как мы всё делаем для опытов, выделили дескриптор для задачи тоже здесь uint8 td = CyDmaTdAllocate(); // Задали параметры дескриптора и длину в байтах. Также сказали, что следующего дескриптора нет. CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); // Теперь задали начальные адреса для дескриптора CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // Подключили этот дескриптор к каналу CyDmaChSetInitialTd(channel, td); // Запустили процесс с возвратом дескриптора к исходному виду CyDmaChEnable(channel, 1); }
Вызываем её вот так:
JustTest(0);
На осциллографе видим следующее (жёлтый луч — выход STEP, голубой — значение выхода TC счётчика для контроля процесса). Длительность импульсов задаётся массивом steps. На каждом шаге длительность равна 0x1000 тактов.
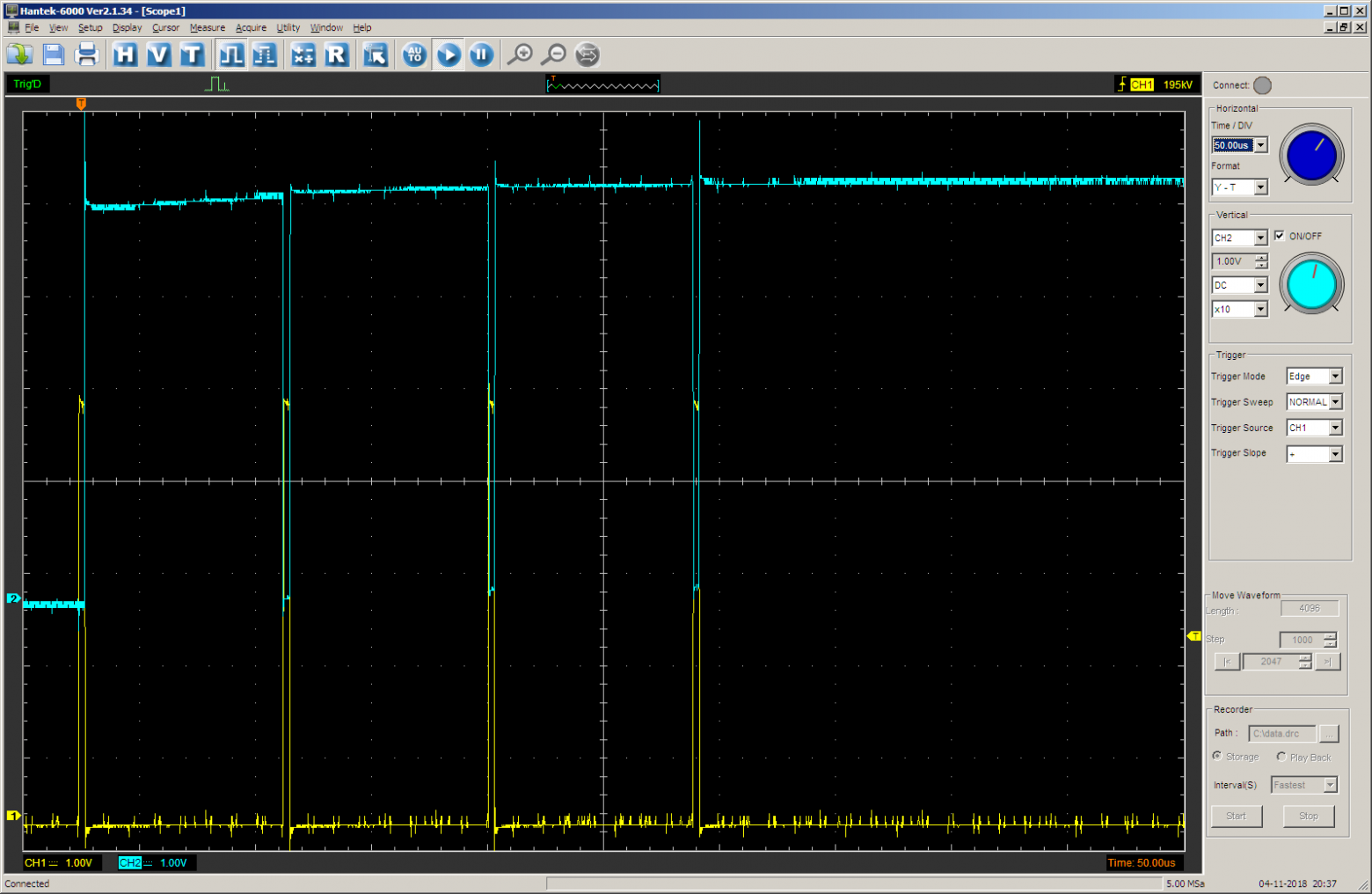
Переключимся на другую развёртку, чтобы была совместимость между разными результатами:
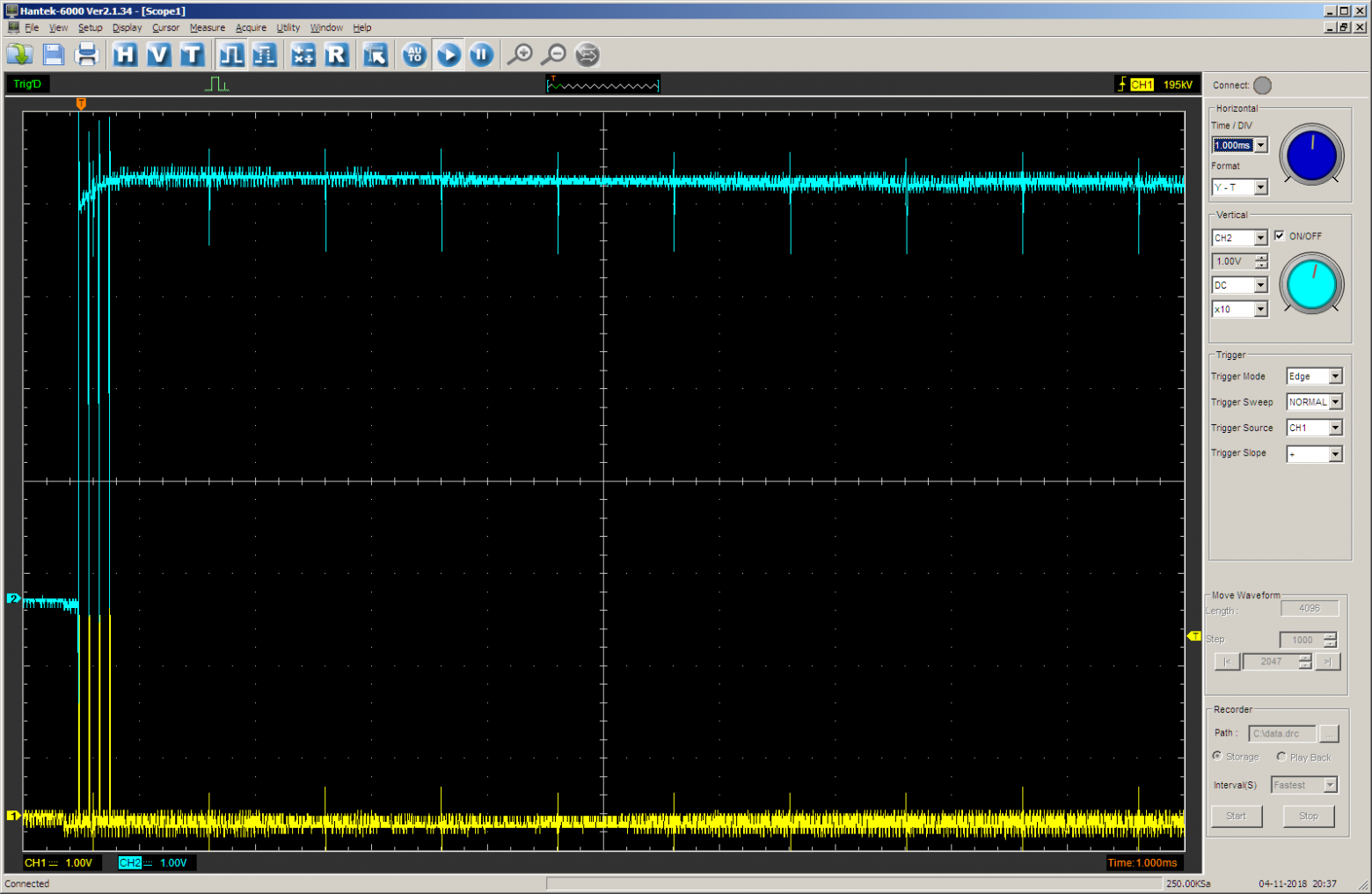
Меняем вызов функции на такой:
JustTest(1);
Результат соответствует ожиданию. Сначала выход TC равен нулю на протяжении 0x1000 тактов, затем — единицей на протяжении 0x10000 (65536д) тактов. Частота примерно равна 700 герц, это мы выяснили ещё в прошлой части статьи, так что всё верно.
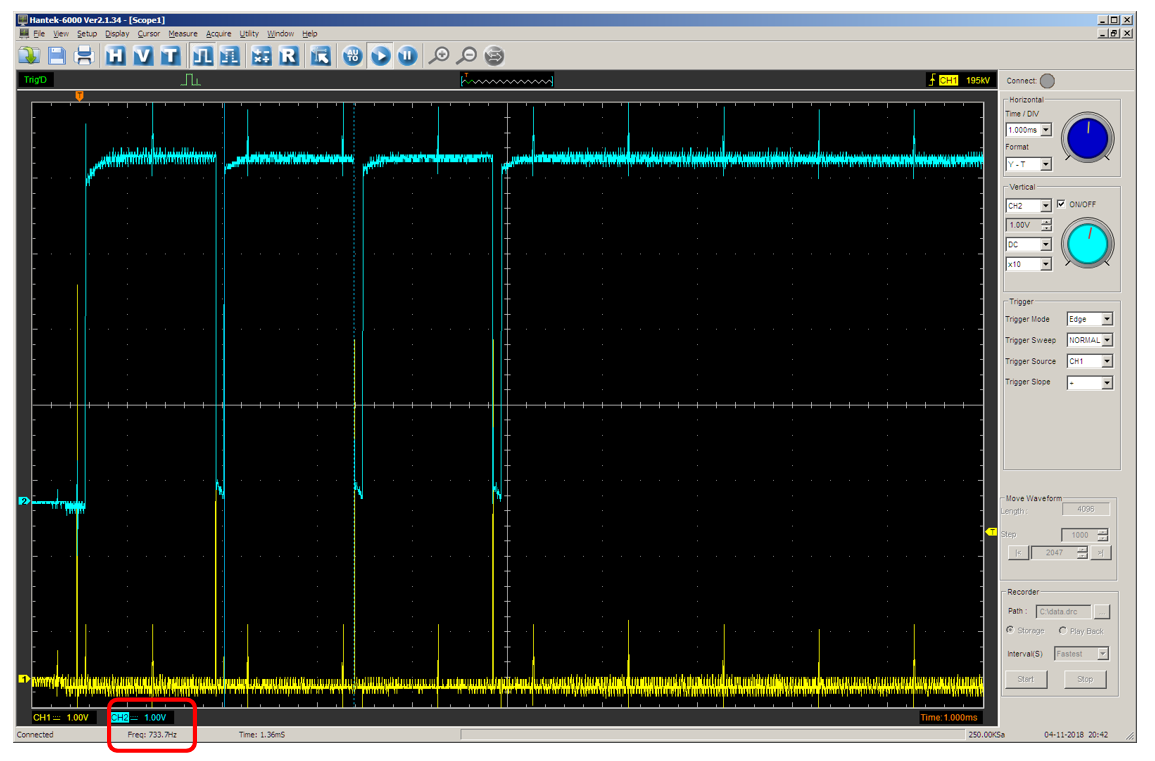
Ну, и попробуем двойку:
JustTest(2);
Получаем:

Всё верно. Выход TC перебрасывается в единицу на последних 65536 тактах. Перед этим он в нуле на протяжении 0x1000 + 0x10000 тактов.
Само собой, при таком подходе все импульсы должны идти при одном и том же значении нового счётчика. Невозможно при разгоне сделать один импульс со старшим байтом, скажем, 3, далее — 1, далее — 0. Но на самом деле, при таких низких частотах (менее семисот герц) ускорения не имеют физического смысла, поэтому данной проблемой можно пренебречь. На этой частоте можно работать с двигателем линейно.
Ложка дёгтя
Документ TRM на семейство PSoC5LP гласит:
Each transaction can be from 1 to 64 KBНо в упомянутом уже AN84810 есть такая фраза:
1. How can you buffer more than 4095 bytes using DMA?Кто прав? Если проводить эксперименты, то результаты будут склоняться в пользу худшего из утверждений, но поведение будет совершенно непонятным. Всему виной вот эта проверка в API:
The maximum transfer count of a TD is limited to 4095 bytes. If you need to transfer more than 4095 bytes using a single DMA channel, use multiple TDs and chain them as shown in Example 5.
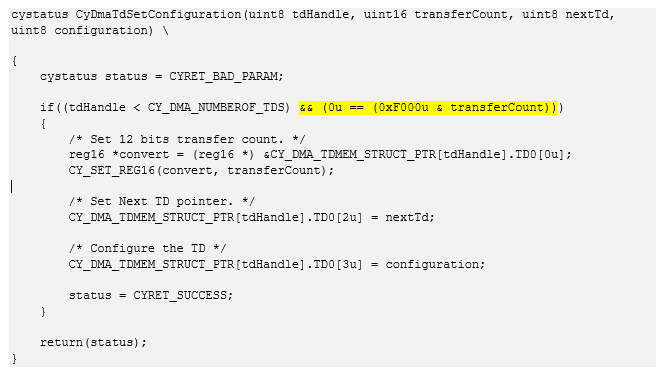
То же самое текстом.
cystatus CyDmaTdSetConfiguration(uint8 tdHandle, uint16 transferCount, uint8 nextTd, uint8 configuration) \ { cystatus status = CYRET_BAD_PARAM; if((tdHandle < CY_DMA_NUMBEROF_TDS) && (0u == (0xF000u & transferCount))) { /* Set 12 bits transfer count. */ reg16 *convert = (reg16 *) &CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[0u]; CY_SET_REG16(convert, transferCount); /* Set Next TD pointer. */ CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[2u] = nextTd; /* Configure the TD */ CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[3u] = configuration; status = CYRET_SUCCESS; } return(status); }
Если задаётся транзакция, длиннее, чем 4095 байт, будет использована предыдущая настройка. Да, я не додумался проверять коды ошибок…
Эксперименты показали, что если убрать эту проверку, фактическая длина будет обрезана по маске 0xfff (4096Д=0x1000). Увы и ах. Все надежды на приятную работу рухнули. Можно, конечно, делать цепочки связанных дескрипторов по 4К. Но, скажем, 64К — это 16 цепочек. Три активных двигателя (у экструдеров шагов будет меньше) — 48 цепочек. Ровно столько надо заполнять в худшем случае перед каждым отрезком. Возможно, оно и приемлемо по времени. Как минимум, в наличии имеется 127 дескрипторов, так что по памяти точно хватит.
Можно же досылать недостающие данные по мере надобности. Пришло прерывание, что канал DMA завершил работу, передаём в него очередной отрезок. При этом никаких вычислений не требуется, отрезок уже сформирован, всё будет быстро. И требований по быстродействию нет: когда будет выдан запрос на прерывание, в FIFO будет находиться ещё 4 элемента, которые будут обслуживаться каждый по несколько сотен или даже тысяч тактов. То есть, всё реально. Конкретную стратегию будет проще выбрать во время реальной работы. Но ошибка в документации (TRM) испортила всё настроение. Если бы это было известно заранее, может, я бы не стал и проверять методику.
Заключение
С виду, разработанный вспомогательный микропрограммный инструмент стал приемлемым для того, чтобы на его основе можно было сделать версию «Прошивки», скажем, Marlin, которая не находится постоянно в обработчике прерываний для шаговых двигателей. Насколько мне известно, это особенно актуально для принтеров «Дельта», где потребности в вычислительных ресурсах достаточно высоки. Возможно, это позволит устранить наплывы, которые возникают на моей Дельте в местах останова головки. На MZ3D в этих же местах никаких наплывов не наблюдается. Так это или нет, покажет время, а отчёт об этом надо будет размещать уже совсем в другой ветке.
Пока же мы убедились, что на блоке UDB, при всей его простоте, вполне можно реализовывать сопроцессор, работающий в паре с основным процессором и позволяющий разгрузить его. А когда этих блоков много, сопроцессоры могут работать в параллель.
Ошибка в документации на контроллер DMA смазала результат. Прерывания всё-таки требуются, но совсем не на той частоте и не с той критичностью по времени, что было в оригинальном варианте. Так что настроение испорчено, но использование «сопроцессора» на базе UDB всё равно даёт немалый выигрыш по сравнению с чисто программной работой.
Попутно выявлено, что DMA работает с достаточно низкой скоростью. По результатам этого, были проведены некоторые замеры как на PSoC5LP, так и на STM32. Результаты тянут ещё на одну статью. Возможно, я когда-нибудь её сделаю, если тема окажется интересной.
В результате опытов получилось сразу два тестовых проекта. Первый попроще для понимания. Его можно взять здесь. Второй унаследован от первого, но запутан при добавлении семибитного счётчика и связанной с ним логики. Его можно взять здесь. Разумеется, эти примеры только тестовые. На встраивание в реальную «прошивку» пока нет свободного времени. Но в рамках данных статей важнее именно попрактиковаться в работе с UDB.

