В статье опишу использование Spring Data.
Spring Data — дополнительный удобный механизм для взаимодействия с сущностями базы данных, организации их в репозитории, извлечение данных, изменение, в каких то случаях для этого будет достаточно объявить интерфейс и метод в нем, без имплементации.
Содержание:
Основное понятие в Spring Data — это репозиторий. Это несколько интерфейсов которые используют JPA Entity для взаимодействия с ней. Так например интерфейс
обеспечивает основные операции по поиску, сохранения, удалению данных (CRUD операции)
и др. операции.
Есть и другие абстракции, например PagingAndSortingRepository.
Т.е. если того перечня что предоставляет интерфейс достаточно для взаимодействия с сущностью, то можно прямо расширить базовый интерфейс для своей сущности, дополнить его своими методами запросов и выполнять операции. Сейчас я покажу коротко те шаги что нужны для самого простого случая (не отвлекаясь пока на конфигурации, ORM, базу данных).
1. Создаем сущность
2. Наследоваться от одного из интерфейсов Spring Data, например от CrudRepository
3. Использовать в клиенте (сервисе) новый интерфейс для операций с данными
Здесь я воспользовался готовым методом findById. Т.е. вот так легко и быстро, без имплементации, получим готовый перечень операций из CrudRepository:
Понятно что этого перечня, скорее всего не хватит для взаимодействия с сущностью, и тут можно расширить свой интерфейс дополнительными методами запросов.
Запросы к сущности можно строить прямо из имени метода. Для этого используется механизм префиксов find…By, read…By, query…By, count…By, и get…By, далее от префикса метода начинает разбор остальной части. Вводное предложение может содержать дополнительные выражения, например, Distinct. Далее первый By действует как разделитель, чтобы указать начало фактических критериев. Можно определить условия для свойств сущностей и объединить их с помощью And и Or. Примеры
В документации определен весь перечень, и правила написания метода. В качестве результата могут быть сущность T, Optional, List, Stream. В среде разработки, например в Idea, есть подсказка для написания методов запросов.
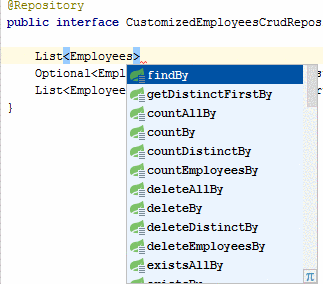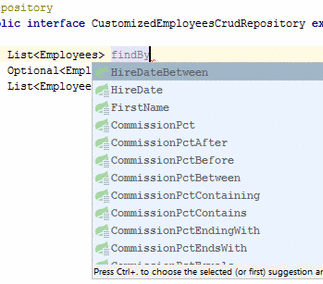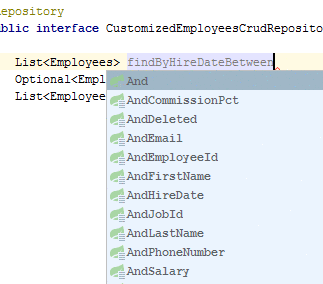
Достаточно только определить подобным образом метод, без имплементации и Spring подготовит запрос к сущности.
Весь проект доступен на github
github DemoSpringData
Здесь лишь коснусь некоторых особенностей.
В context.xml определенны бины transactionManager, dataSource и entityManagerFactory. Важно указать в нем также
путь где определены репозитории.
EntityManagerFactory настроен на работу с Hibernate ORM, а он в свою очередь с БД Oracle XE, тут возможны и другие варианты, в context.xml все это видно. В pom файле есть все зависимости.
В методах запросов, в их параметрах можно использовать специальные параметры Pageable, Sort, а также ограничения Top и First.
Например вот так можно взять вторую страницу (индекс с -0), размером в три элемента и сортировкой по firstName, предварительно указав в методе репозитория параметр Pageable, также будут использованы критерии из имени метода — «Искать по FirstName начиная с % „
Предположим что в репозиторие нужен метод, который не получается описать именем метода, тогда можно реализовать с помощью своего интерфейса и класса его имплементирующего. В примере ниже добавлю в репозиторий метод получения сотрудников с максимальной оплатой труда.
Объявляю интерфейс
Имплементирую интерфейс. С помощью HQL (SQL) получаю сотрудников с максимальной оплатой, возможны и другие реализации.
А также расширяю Crud Repository Employees еще и CustomizedEmployees.
Здесь есть одна важная особенность. Класс имплементирующий интерфейс, должен заканчиваться (postfix) на Impl, или в конфигурации надо поставить свой postfix
Проверяем работу этого метода через репозиторий
Другой случай, когда надо изменить поведение уже существующего метода в интерфейсе Spring, например delete в CrudRepository, мне надо что бы вместо удаления из БД, выставлялся признак удаления. Техника точно такая же. Ниже пример:
Теперь если в employeesCrudRepository вызвать delete, то объект будет только помечен как удаленный.
В предыдущем примере я показал как переопределить delete в Crud репозитории сущности, но если это надо делать для всех сущностей проекта, делать для каждой свой интерфейс как то не очень..., тогда в Spring data можно настроить свой базовый репозиторий. Для этого:
Объявляется интерфейс и в нем метод для переопределения (или общий для всех сущностей проекта). Тут я еще для всех своих сущностей ввел свой интерфейс BaseEntity (это не обязательно), для удобства вызова общих методов, его методы совпадают с методами сущности.
В конфигурации надо указать этот базовый репозиторий, он будет общий для всех репозиториев проекта
Теперь Employees Repository (и др.) надо расширять от BaseRepository и уже его использовать в клиенте.
Проверяю работу EmployeesBaseRepository
Теперь также как и ранее, объект будет помечен как удаленный, и это будет выполняться для всех сущностей, которые расширяют интерфейс BaseRepository. В примере был применен метод поиска — Query by Example (QBE), я не буду здесь его описывать, из примера видно что он делает, просто и удобно.
Ранее я писал, что если нужен специфичный метод или его реализация, которую нельзя описать через имя метода, то это можно сделать через некоторый Customized интерфейс ( CustomizedEmployees) и сделать реализацию вычисления. А можно пойти другим путем, через указание запроса (HQL или SQL), как вычислить данную функцию.
Для моего примера c getEmployeesMaxSalary, этот вариант реализации даже проще. Я еще усложню его входным параметром salary. Т.е. достаточно объявить в интерфейсе метод и запрос вычисления.
Проверяю
Упомяну лишь еще, что запросы могут быть и модифицирующие, для этого к ним добавляется еще аннотация @Modifying
Еще одной из замечательных возможностей Query аннотации — это подстановка типа домена сущности в запрос по шаблону #{#entityName}, через SpEL выражения.
Так например в моем гипотетическом примере, когда мне надо для всех сущностей иметь признак “удален», я сделаю базовый интерфейс с методом получения списка объектов с признаком «удален» или «активный»
Далее все репозитории для сущностей можно расширять от него. Интерфейсы которые не являются репозиториями, но находятся в «base-package» папке конфигурации, надо аннотировать @NoRepositoryBean.
Репозиторий Employees
Теперь когда будет выполняться запрос, в тело запроса будет подставлено имя сущности T для конкретного репозитория который будет расширять ParentEntityRepository, в данном случае Employees.
Проверка
Материалы
Spring Data JPA — Reference Documentation
Проект на github.
Spring Data — дополнительный удобный механизм для взаимодействия с сущностями базы данных, организации их в репозитории, извлечение данных, изменение, в каких то случаях для этого будет достаточно объявить интерфейс и метод в нем, без имплементации.
Содержание:
- Spring Repository
- Методы запросов из имени метода
- Конфигурация и настройка
- Специальная обработка параметров
- Пользовательские реализации для репозитория
- Пользовательский Базовый Репозиторий
- Методы запросов — Query
1. Spring Repository
Основное понятие в Spring Data — это репозиторий. Это несколько интерфейсов которые используют JPA Entity для взаимодействия с ней. Так например интерфейс
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID>обеспечивает основные операции по поиску, сохранения, удалению данных (CRUD операции)
T save(T entity); Optional findById(ID primaryKey); void delete(T entity);
и др. операции.
Есть и другие абстракции, например PagingAndSortingRepository.
Т.е. если того перечня что предоставляет интерфейс достаточно для взаимодействия с сущностью, то можно прямо расширить базовый интерфейс для своей сущности, дополнить его своими методами запросов и выполнять операции. Сейчас я покажу коротко те шаги что нужны для самого простого случая (не отвлекаясь пока на конфигурации, ORM, базу данных).
1. Создаем сущность
@Entity @Table(name = "EMPLOYEES") public class Employees { private Long employeeId; private String firstName; private String lastName; private String email; // . . .
2. Наследоваться от одного из интерфейсов Spring Data, например от CrudRepository
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long>
3. Использовать в клиенте (сервисе) новый интерфейс для операций с данными
@Service public class EmployeesDataService { @Autowired private CustomizedEmployeesCrudRepository employeesCrudRepository; @Transactional public void testEmployeesCrudRepository() { Optional<Employees> employeesOptional = employeesCrudRepository.findById(127L); //.... }
Здесь я воспользовался готовым методом findById. Т.е. вот так легко и быстро, без имплементации, получим готовый перечень операций из CrudRepository:
S save(S var1); Iterable<S> saveAll(Iterable<S> var1); Optional<T> findById(ID var1); boolean existsById(ID var1); Iterable<T> findAll(); Iterable<T> findAllById(Iterable<ID> var1); long count(); void deleteById(ID var1); void delete(T var1); void deleteAll(Iterable<? extends T> var1); void deleteAll();
Понятно что этого перечня, скорее всего не хватит для взаимодействия с сущностью, и тут можно расширить свой интерфейс дополнительными методами запросов.
2. Методы запросов из имени метода
Запросы к сущности можно строить прямо из имени метода. Для этого используется механизм префиксов find…By, read…By, query…By, count…By, и get…By, далее от префикса метода начинает разбор остальной части. Вводное предложение может содержать дополнительные выражения, например, Distinct. Далее первый By действует как разделитель, чтобы указать начало фактических критериев. Можно определить условия для свойств сущностей и объединить их с помощью And и Or. Примеры
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long> { // искать по полям firstName And LastName Optional<Employees> findByFirstNameAndLastName(String firstName, String lastName); // найти первые 5 по FirstName начинающихся с символов и сортировать по FirstName List<Employees> findFirst5ByFirstNameStartsWithOrderByFirstName(String firstNameStartsWith);
В документации определен весь перечень, и правила написания метода. В качестве результата могут быть сущность T, Optional, List, Stream. В среде разработки, например в Idea, есть подсказка для написания методов запросов.
Достаточно только определить подобным образом метод, без имплементации и Spring подготовит запрос к сущности.
@SpringBootTest public class DemoSpringDataApplicationTests { @Autowired private CustomizedEmployeesCrudRepository employeesCrudRepository; @Test @Transactional public void testFindByFirstNameAndLastName() { Optional<Employees> employeesOptional = employeesCrudRepository.findByFirstNameAndLastName("Alex", "Ivanov");
3. Конфигурация и настройка
Весь проект доступен на github
github DemoSpringData
Здесь лишь коснусь некоторых особенностей.
В context.xml определенны бины transactionManager, dataSource и entityManagerFactory. Важно указать в нем также
<jpa:repositories base-package="com.example.demoSpringData.repositories"/>
путь где определены репозитории.
EntityManagerFactory настроен на работу с Hibernate ORM, а он в свою очередь с БД Oracle XE, тут возможны и другие варианты, в context.xml все это видно. В pom файле есть все зависимости.
4. Специальная обработка параметров
В методах запросов, в их параметрах можно использовать специальные параметры Pageable, Sort, а также ограничения Top и First.
Например вот так можно взять вторую страницу (индекс с -0), размером в три элемента и сортировкой по firstName, предварительно указав в методе репозитория параметр Pageable, также будут использованы критерии из имени метода — «Искать по FirstName начиная с % „
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long> { List<Employees> findByFirstNameStartsWith(String firstNameStartsWith, Pageable page); //.... } // пример вызова @Test @Transactional public void testFindByFirstNameStartsWithOrderByFirstNamePage() { List<Employees> list = employeesCrudRepository .findByFirstNameStartsWith("A", PageRequest.of(1,3, Sort.by("firstName"))); list.forEach(e -> System.out.println(e.getFirstName() + " " +e.getLastName())); }
5. Пользовательские реализации для репозитория
Предположим что в репозиторие нужен метод, который не получается описать именем метода, тогда можно реализовать с помощью своего интерфейса и класса его имплементирующего. В примере ниже добавлю в репозиторий метод получения сотрудников с максимальной оплатой труда.
Объявляю интерфейс
public interface CustomizedEmployees<T> { List<T> getEmployeesMaxSalary(); }
Имплементирую интерфейс. С помощью HQL (SQL) получаю сотрудников с максимальной оплатой, возможны и другие реализации.
public class CustomizedEmployeesImpl implements CustomizedEmployees { @PersistenceContext private EntityManager em; @Override public List getEmployeesMaxSalary() { return em.createQuery("from Employees where salary = (select max(salary) from Employees )", Employees.class) .getResultList(); } }
А также расширяю Crud Repository Employees еще и CustomizedEmployees.
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long>, CustomizedEmployees<Employees>
Здесь есть одна важная особенность. Класс имплементирующий интерфейс, должен заканчиваться (postfix) на Impl, или в конфигурации надо поставить свой postfix
<repositories base-package="com.repository" repository-impl-postfix="MyPostfix" />
Проверяем работу этого метода через репозиторий
public class DemoSpringDataApplicationTests { @Autowired private CustomizedEmployeesCrudRepository employeesCrudRepository; @Test @Transactional public void testMaxSalaryEmployees() { List<Employees> employees = employeesCrudRepository.getEmployeesMaxSalary(); employees.stream() .forEach(e -> System.out.println(e.getFirstName() + " " + e.getLastName() + " " + e.getSalary())); }
Другой случай, когда надо изменить поведение уже существующего метода в интерфейсе Spring, например delete в CrudRepository, мне надо что бы вместо удаления из БД, выставлялся признак удаления. Техника точно такая же. Ниже пример:
public interface CustomizedEmployees<T> { void delete(T entity); // ... } // Имплементация CustomizedEmployees public class CustomizedEmployeesImpl implements CustomizedEmployees { @PersistenceContext private EntityManager em; @Transactional @Override public void delete(Object entity) { Employees employees = (Employees) entity; employees.setDeleted(true); em.persist(employees); }
Теперь если в employeesCrudRepository вызвать delete, то объект будет только помечен как удаленный.
6. Пользовательский Базовый Репозиторий
В предыдущем примере я показал как переопределить delete в Crud репозитории сущности, но если это надо делать для всех сущностей проекта, делать для каждой свой интерфейс как то не очень..., тогда в Spring data можно настроить свой базовый репозиторий. Для этого:
Объявляется интерфейс и в нем метод для переопределения (или общий для всех сущностей проекта). Тут я еще для всех своих сущностей ввел свой интерфейс BaseEntity (это не обязательно), для удобства вызова общих методов, его методы совпадают с методами сущности.
public interface BaseEntity { Boolean getDeleted(); void setDeleted(Boolean deleted); } // Сущность Employees @Entity @Table(name = "EMPLOYEES") public class Employees implements BaseEntity { private Boolean deleted; @Override public Boolean getDeleted() { return deleted; } @Override public void setDeleted(Boolean deleted) { this.deleted = deleted; } // Базовый пользовательский интерфейс @NoRepositoryBean public interface BaseRepository <T extends BaseEntity, ID extends Serializable> extends JpaRepository<T, ID> { void delete(T entity); } //Базовый пользовательский класс имплементирующий BaseRepository public class BaseRepositoryImpl <T extends BaseEntity, ID extends Serializable> extends SimpleJpaRepository<T, ID> implements BaseRepository<T, ID> { private final EntityManager entityManager; public BaseRepositoryImpl(JpaEntityInformation<T, ?> entityInformation, EntityManager entityManager) { super(entityInformation, entityManager); this.entityManager = entityManager; } @Transactional @Override public void delete(BaseEntity entity) { entity.setDeleted(true); entityManager.persist(entity); } }
В конфигурации надо указать этот базовый репозиторий, он будет общий для всех репозиториев проекта
<jpa:repositories base-package="com.example.demoSpringData.repositories" base-class="com.example.demoSpringData.BaseRepositoryImpl"/>
Теперь Employees Repository (и др.) надо расширять от BaseRepository и уже его использовать в клиенте.
public interface EmployeesBaseRepository extends BaseRepository <Employees, Long> { // ... }
Проверяю работу EmployeesBaseRepository
public class DemoSpringDataApplicationTests { @Resource private EmployeesBaseRepository employeesBaseRepository; @Test @Transactional @Commit public void testBaseRepository() { Employees employees = new Employees(); employees.setLastName("Ivanov"); // Query by Example (QBE) Example<Employees> example = Example.of(employees); Optional<Employees> employeesOptional = employeesBaseRepository.findOne(example); employeesOptional.ifPresent(employeesBaseRepository::delete); }
Теперь также как и ранее, объект будет помечен как удаленный, и это будет выполняться для всех сущностей, которые расширяют интерфейс BaseRepository. В примере был применен метод поиска — Query by Example (QBE), я не буду здесь его описывать, из примера видно что он делает, просто и удобно.
7. Методы запросов — Query
Ранее я писал, что если нужен специфичный метод или его реализация, которую нельзя описать через имя метода, то это можно сделать через некоторый Customized интерфейс ( CustomizedEmployees) и сделать реализацию вычисления. А можно пойти другим путем, через указание запроса (HQL или SQL), как вычислить данную функцию.
Для моего примера c getEmployeesMaxSalary, этот вариант реализации даже проще. Я еще усложню его входным параметром salary. Т.е. достаточно объявить в интерфейсе метод и запрос вычисления.
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long>, CustomizedEmployees<Employees> { @Query("select e from Employees e where e.salary > :salary") List<Employees> findEmployeesWithMoreThanSalary(@Param("salary") Long salary, Sort sort); // ... }
Проверяю
@Test @Transactional public void testFindEmployeesWithMoreThanSalary() { List<Employees> employees = employeesCrudRepository.findEmployeesWithMoreThanSalary(10000L, Sort.by("lastName"));
Упомяну лишь еще, что запросы могут быть и модифицирующие, для этого к ним добавляется еще аннотация @Modifying
@Modifying @Query("update Employees e set e.firstName = ?1 where e.employeeId = ?2") int setFirstnameFor(String firstName, String employeeId);
Еще одной из замечательных возможностей Query аннотации — это подстановка типа домена сущности в запрос по шаблону #{#entityName}, через SpEL выражения.
Так например в моем гипотетическом примере, когда мне надо для всех сущностей иметь признак “удален», я сделаю базовый интерфейс с методом получения списка объектов с признаком «удален» или «активный»
@NoRepositoryBean public interface ParentEntityRepository<T> extends Repository<T, Long> { @Query("select t from #{#entityName} t where t.deleted = ?1") List<T> findMarked(Boolean deleted); }
Далее все репозитории для сущностей можно расширять от него. Интерфейсы которые не являются репозиториями, но находятся в «base-package» папке конфигурации, надо аннотировать @NoRepositoryBean.
Репозиторий Employees
@Repository public interface EmployeesEntityRepository extends ParentEntityRepository <Employees> { }
Теперь когда будет выполняться запрос, в тело запроса будет подставлено имя сущности T для конкретного репозитория который будет расширять ParentEntityRepository, в данном случае Employees.
Проверка
@SpringBootTest public class DemoSpringDataApplicationTests { @Autowired private EmployeesEntityRepository employeesEntityRepository; @Test @Transactional public void testEntityName() { List<Employees> employeesMarked = employeesEntityRepository.findMarked(true); // ...
Материалы
Spring Data JPA — Reference Documentation
Проект на github.

