Чуть больше года при моём участии состоялся следующий "диалог":
.Net App: Эй, Entity Framework, будь любезен дай мне много данных!
Entity Framework: Прости, не понял тебя. Что ты имеешь ввиду?
.Net App: Да просто мне прилетела коллекция из 100k транзакций. И теперь надо по-быстрому проверить корректность цен на бумаги, которые там указаны.
Entity Framework: Ааа, ну давай попробуем…
.Net App: Вот код:
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
Entity Framework:
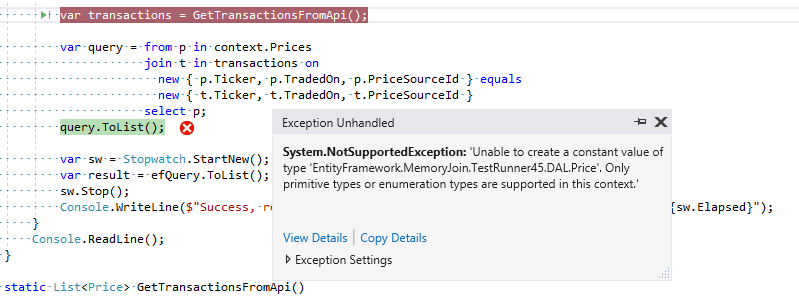
Классика! Думаю многим знакома эта ситуация: когда очень хочется “красиво” и быстро сделать поиск в базе, используя JOIN локальной коллекции и DbSet. Обычно этот опыт разочаровывает.
В данной статье (которая является вольным переводом другой моей статьи) я проведу ряд экспериментов и попробую разные способы, чтобы обойти это ограничение. Будет код (несложный), размышления и что-то вроде хэппи-энда.
Введение
Все знают про Entity Framework, многие используют его каждый день, и существует много хороших статей про то, как готовить его правильно (использовать более простые запросы, использовать параметры в Skip и Take, использовать VIEW, запрашивать только нужные поля, следить за кэшированием запросов и прочее), однако тема JOIN локальной коллекции и DbSet до сих пор является "слабым местом".
Задача
Предположим, что есть база данных с ценами и есть коллекция транзакций у которой надо проверить корректность цен. И, предположим, у нас есть следующий код.
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
Этот код не работает в Entity Framework 6 вообще. В Entity Framework Core — работает, но всё будет выполнено на стороне клиента и в случае, когда в базе миллионы записей — это не выход.
Как я уже говорил, я буду пробовать разные способы, чтобы обойти это. От простого способа к сложному. Для своих экспериментов я использую код из следующего репозитория. Код написан с использованием: C#, .Net Core, EF Core и PostgreSQL.
Я также снимал некоторые метрики: затраченное время и потребление памяти. Оговорка: если тест выполнялся более 10 минут — я его прерывал (ограничение сверху). Машина для тестов Intel Core i5, 8 GB RAM, SSD.
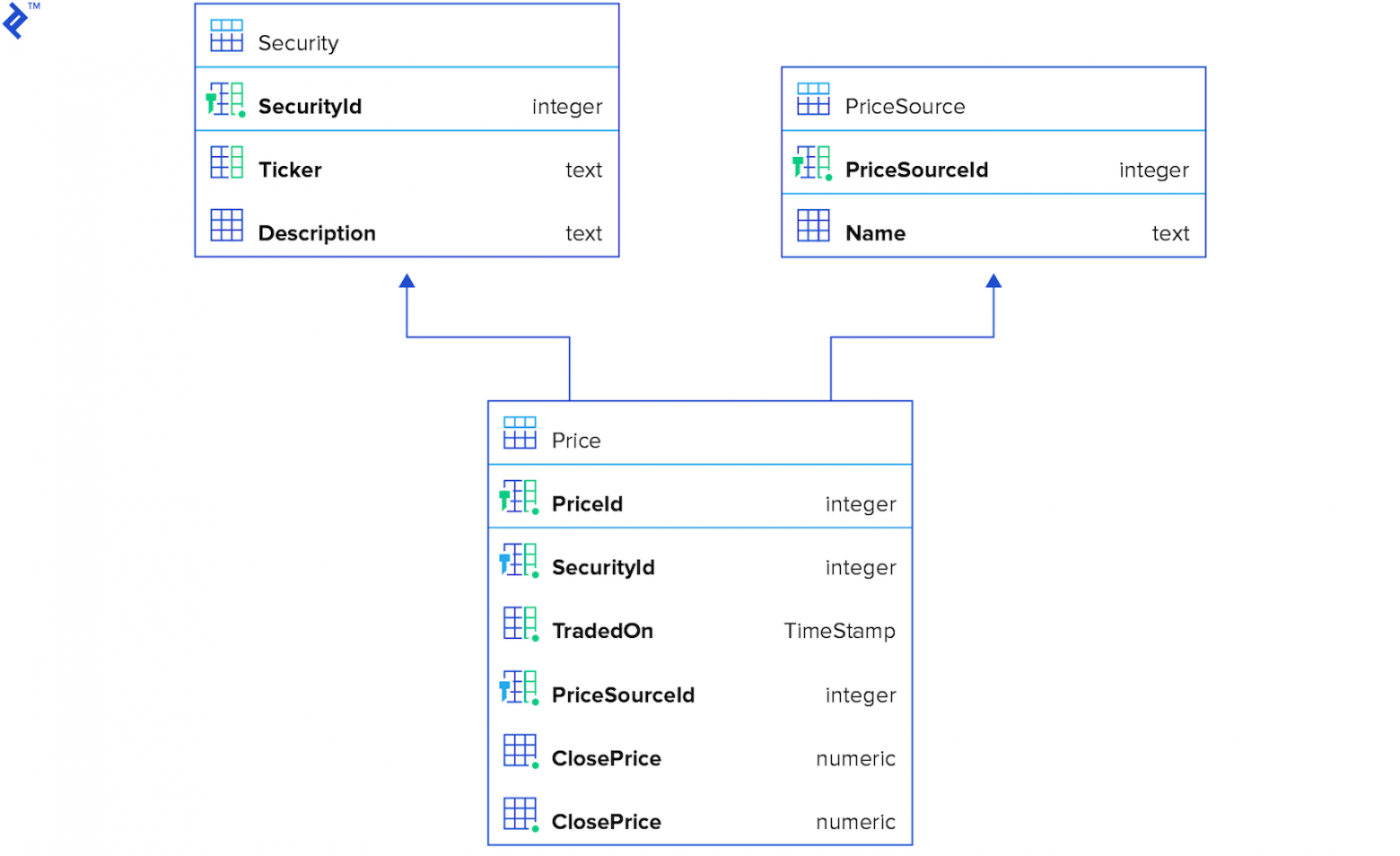
Только 3 таблицы: prices, securities and price sources. Prices — содержит 10 миллионов записей.
Способ 1. Naive
Начнём с простого и будем использовать следующий код:
var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
Идея проста: в цикле читаем записи из базы по одной и добавляем в результирующую коллекцию. У этого кода только одно преимущество — простота. И один недостаток — низкая скорость: даже при условии наличия индекса в базе, большая часть времени займёт коммуникация с сервером БД. Метрики получились такие:
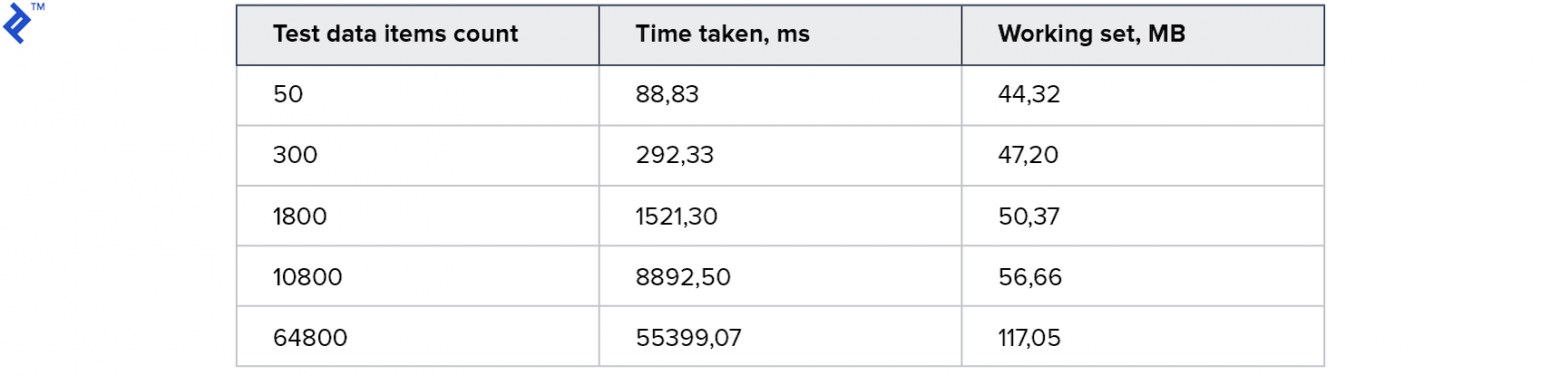
Потребление памяти невелико. Для большой коллекции требуется 1 минута. Для начала неплохо, но хочется быстрее.
Способ 2. Naive parallel
Попробуем добавить параллелизм. Идея в том, чтобы обращаться к базе из нескольких потоков.
var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
Результат:
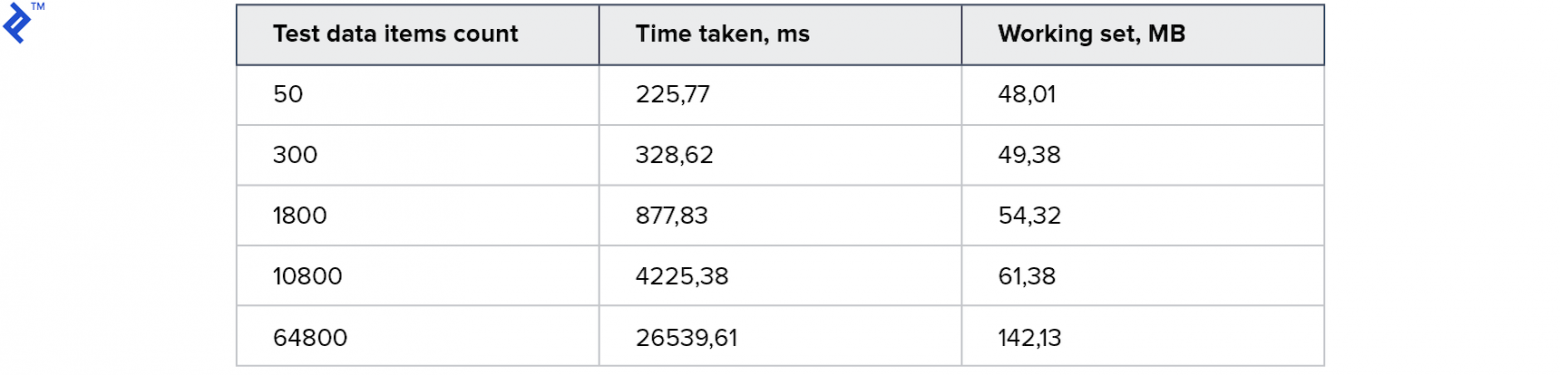
Для маленьких коллекций этот подход работает даже медленнее, чем первый способ. А для самого большого — в 2 раза быстрее. Интересно, что на моей машине было порождено 4 потока, но это не привело к 4х кратному ускорению. Это говорит о том, что накладные расходы в этом способе существенны: как на стороне клиента, так и на стороне сервера. Потребление памяти выросло, но незначительно.
Способ 3. Multiple Contains
Время попробовать нечто иное и попытаться свести задачу к выполнению одного запроса. Можно сделать следующим образом:
- Подготовить 3 коллекции уникальных значений Ticker, PriceSourceId и Date
- Выполнить запрос и использовать 3 Contains
- Перепроверить результаты локально
var result = new List<Price>(); using (var context = CreateContext()) { // Готовим коллекции var tickers = TestData.Select(x => x.Ticker).Distinct().ToList(); var dates = TestData.Select(x => x.TradedOn).Distinct().ToList(); var ps = TestData.Select(x => x.PriceSourceId).Distinct().ToList(); // Запрос с использованием 3 Contains var data = context.Prices .Where(x => tickers.Contains(x.Security.Ticker) && dates.Contains(x.TradedOn) && ps.Contains(x.PriceSourceId)) .Select(x => new { Price = x, Ticker = x.Security.Ticker, }) .ToList(); var lookup = data.ToLookup(x => $"{x.Ticker}, {x.Price.TradedOn}, {x.Price.PriceSourceId}"); // Перепроверка foreach (var el in TestData) { var key = $"{el.Ticker}, {el.TradedOn}, {el.PriceSourceId}"; result.AddRange(lookup[key].Select(x => x.Price)); } }
Проблема здесь в том, что время выполнения и объем возвращаемых данных сильно зависит от самих данных (и в запросе и в базе). То есть может вернуться набор только необходимых данных, а могут вернуться ещё и лишние записи (даже в 100 раз больше).
Это можно объяснить, используя следующий пример. Предположим есть следующая таблица с данными:
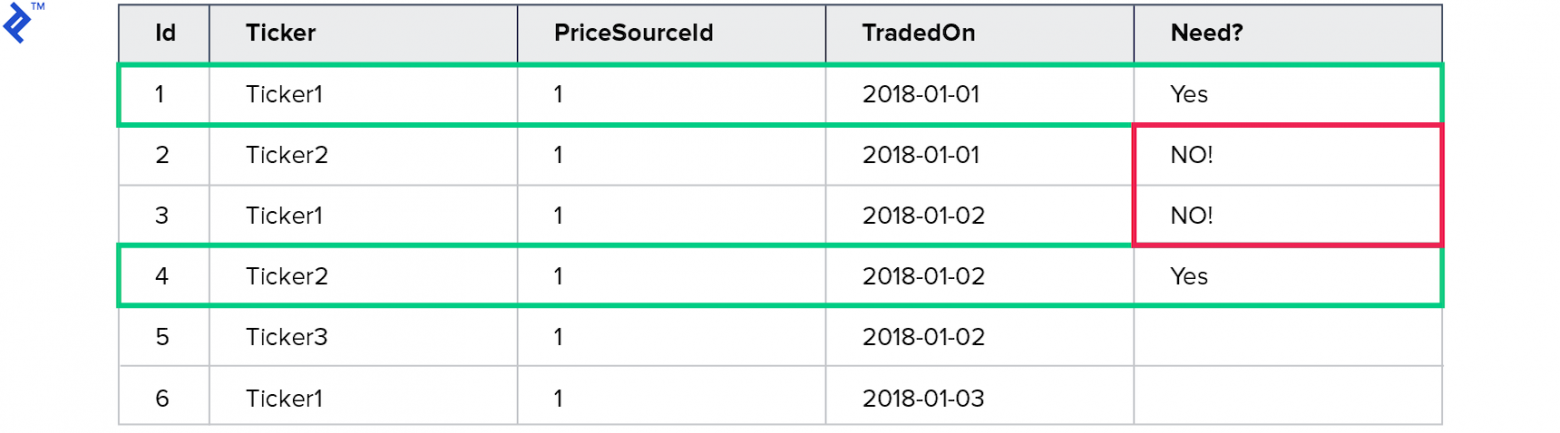
Предположим также, что мне нужны цены для Ticker1 с TradedOn = 2018-01-01 и для Ticker2 с TradedOn = 2018-01-02.
Тогда уникальные значения для Ticker = (Ticker1, Ticker2)
И уникальные значения для TradedOn = (2018-01-01, 2018-01-02)
Однако в результате будет возвращено 4 записи, потому что они действительно соответствуют этим комбинациям. Плохо это тем, что чем больше полей используется — тем больше шанс получить лишние записи в результате.
По этой причине данные, полученные этим способом необходимо дополнительно фильтровать на стороне клиента. И это же является самым большим недостатком.
Метрики получились следующими:

Потребление памяти — хуже всех предыдущих способов. Количество прочитанных строк многократно превышает количество запрошенных. Тесты для больших коллекций были прерваны так как выполнялись больше 10 минут. Этот способ не годится.
Способ 4. Predicate builder
Попробуем теперь с другой стороны: старые добрые Expression. Используя их, можно построить 1 большой запрос в следующей форме:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
Это даёт надежду на то, что удастся построить 1 запрос и получить только нужные данные за 1 заход. Код:
var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
Код получился более сложный, чем в предыдущих способах. Строить Expression вручную не самая простая и не самая быстрая операция.
Метрики:
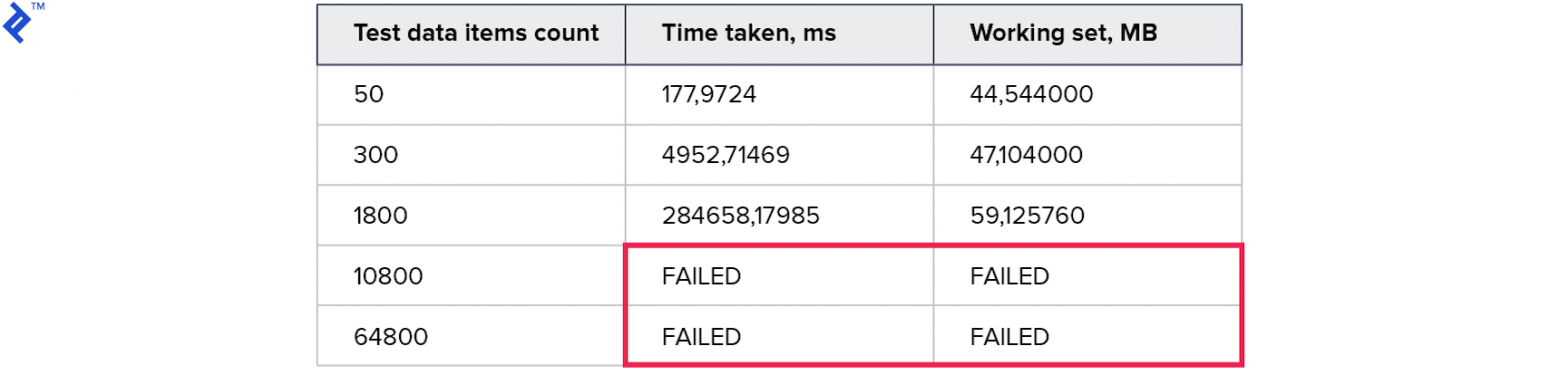
Временные результаты получились ещё хуже, чем в предыдущем способе. Похоже, что накладные расходы при построении и при проходе по дереву оказались намного больше, чем выигрыш от использования одного запроса.
Способ 5. Shared query data table
Попробуем теперь другой вариант:
Я создал в базе новую таблицу, в которую буду записывать данные, необходимые для выполнения запроса (подспудно нужен новый DbSet в контексте).
Теперь, чтобы получить результат нужно:
- Начать транзакцию
- Загрузить данные запроса в новую таблицу
- Выполнить сам запрос (используя новую таблицу)
- Откатить транзакцию (чтобы очистить таблицу данных для запросов)
Код выглядит так:
var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList(); // Временно сохраняем данные в таблицу context.QueryDataShared.AddRange(reducedData); context.SaveChanges(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in context.QueryDataShared on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; result.AddRange(query); context.Database.RollbackTransaction(); }
Сначала метрики:
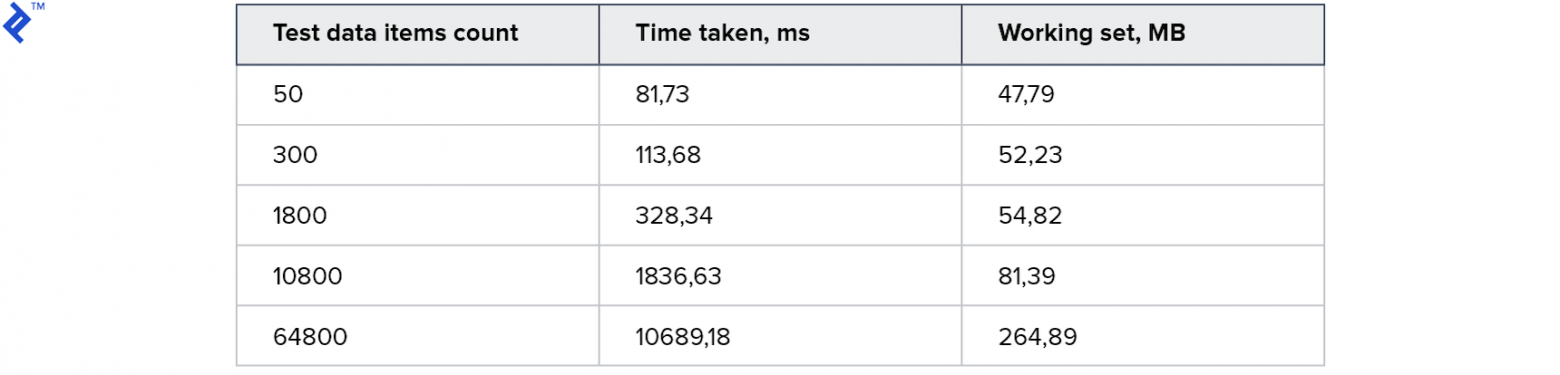
Все тесты отработали и отработали быстро! Потребление памяти тоже приемлемое.
Таким образом, благодаря использованию транзакции эта таблица может использоваться одновременно несколькими процессами. И так как это реально существующая таблица, нам доступны все возможности Entity Framework: необходимо только загрузить данные в таблицу, построить запрос с использованием JOIN и выполнить. На первый взгляд — это то, что нужно, но есть и существенные минусы:
- Необходимо создать таблицу для конкретного типа запросов
- Необходимо использовать транзакции (и тратить ресурсы СУБД на них)
- Да и сама идея, что нужно что-то ПИСАТЬ, когда нужно ЧИТАТЬ, выглядит странно. А на Read Replica это просто не будет работать.
А в остальном — решение более или менее рабочее, которое уже можно использовать.
Способ 6. MemoryJoin extension
Теперь можно попробовать улучшить предыдущий подход. Размышления такие:
- Вместо использования таблицы, которая специфичная для одного типа запроса, можно использовать некий обобщенный вариант. А именно создать таблицу с именем вроде shared_query_data, и добавить в неё по несколько полей Guid, несколько Long, несколько String и т.д. Имена можно взять простые: Guid1, Guid2, String1, Long1, Date2, и т.д. Тогда эту таблицу можно будет использовать для 95% типов запросов. Имена свойств можно будет "скорректировать" позже при помощи проекции Select.
- Далее нужно добавить DbSet для shared_query_data.
- А что если вместо записи данных в базу — передавать значения, используя конструкцию VALUES? То есть необходимо, чтобы в итоговом SQL запросе вместо обращения к shared_query_data было обращение к VALUES. Как это сделать?
- В Entity Framework Core — просто используя FromSql.
- В Entity Framework 6 — придётся использовать DbInterception — то есть менять сгенерированный SQL, добавляя конструкцию VALUES прямо перед выполнением. Это приведет к ограничению: в одном запросе — не более одной конструкции VALUES. Но работать будет!
- Раз мы не собираемся писать в базу данных, то получается таблица shared_query_data, созданная на первом шаге, вообще не нужна? Ответ: да, она не нужна, а вот DbSet всё ещё нужен, так как Entity Framework должен знать схему данных, чтобы строить запросы. Получается, нужен DbSet для некоторой обобщенной модели, которая не существует в базе и используется только для того чтобы внушить Entity Framework, что он знает что делает.
- На вход поступила коллекция объектов следующего типа:
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} } - У нас в распоряжении есть DbSet с полями String1, String2, Date1, Long1, etc
- Пусть Ticker будет храниться в String1, TradedOn в Date1, а PriceSourceId в Long1 (int маппится в long, чтобы не делать отдельно поля для int и long)
- Тогда FromSql + VALUES будет таким:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)") - Теперь можно сделать проекцию и вернуть удобный IQueryable, использующий тот же тип, который был на входе:
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
Мне удалось реализовать этот подход и даже оформить его как NuGet пакет EntityFrameworkCore.MemoryJoin (код тоже доступен). Несмотря на то, что в имени есть слово Core, Entity Framework 6 тоже поддерживается. Я назвал его MemoryJoin, но по факту он отправляет локальные данные на СУБД в конструкции VALUES и вся работа выполняется на нём.
Код получается следующим:
var result = new List<Price>(); using (var context = CreateContext()) { // ВАЖНО: нужно выбрать только поля, которые будут использоваться в запросе var reducedData = TestData.Select(x => new { x.Ticker, x.TradedOn, x.PriceSourceId }).ToList(); // Здесь IEnumerable<> превращается в IQueryable<> var queryable = context.FromLocalList(reducedData); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in queryable on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; result.AddRange(query); }
Метрики:

Это лучший результат из всех, которые я пробовал. Код получился очень простым и понятным, и в то же время рабочим для Read Replica.
SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
Здесь также видно, как обобщенная модель (с полями String1, Date1, Long1) при помощи Select превращается в ту, которая используется в коде (с полями Ticker, TradedOn, PriceSourceId).
Вся работа выполняется за 1 запрос на SQL сервере. И это и есть небольшой хэппи-энд, о котором я говорил в начале. И всё же использование этого способа требует понимания и следующих шагов:
- Необходимо добавить дополнительный DbSet в свой контекст (хотя саму таблицу можно не добавлять)
- В обобщенной модели, которая используется по умолчанию, объявлены по 3 поля типов Guid, String, Double, Long, Date и т.д. Этого должно хватить на 95% типов запросов. И если передать в FromLocalList коллекцию объектов с 20 полями, то будет выброшен Exception, говорящий, что объект слишком сложный. Это мягкое ограничение и его можно обойти — можно объявить свой тип и внести туда хоть по 100 полей. Однако, больше полей — медленней работа.
- Больше технических деталей описано в моей статье.
Заключение
В этой статье я изложил свои размышления на тему JOIN локальной коллекции и DbSet. Мне показалось, что моя разработка с использованием VALUES может быть интересна сообществу. По крайней мере я не встречал такого подхода, когда решал эту задачу сам. Лично мне этот способ помог преодолеть ряд проблем с производительностью в моих текущих проектах, может быть он поможет и Вам.
Кто-то скажет, что использование MemoryJoin слишком "заумное" и его надо дорабатывать, а до тех пор использовать его не нужно. Это именно та причина, почему я очень сомневался и почти год не писал эту статью. Я соглашусь, что хотелось бы, чтобы это работало проще (надеюсь однажды так и будет), но также скажу, что оптимизация никогда не была задачей Junior’ов. Оптимизация всегда требует понимания как инструмент работает. И если есть возможность получить ускорение в ~8 раз (Naive Parallel vs MemoryJoin), то я бы осилил 2 пункта и документации.
И в заключении, диаграммы:
Затраченное время. Только 4 способа выполнили задачу за время менее 10 минут, а MemoryJoin — единственный способ, который выполнил задачу за время менее 10 секунд.
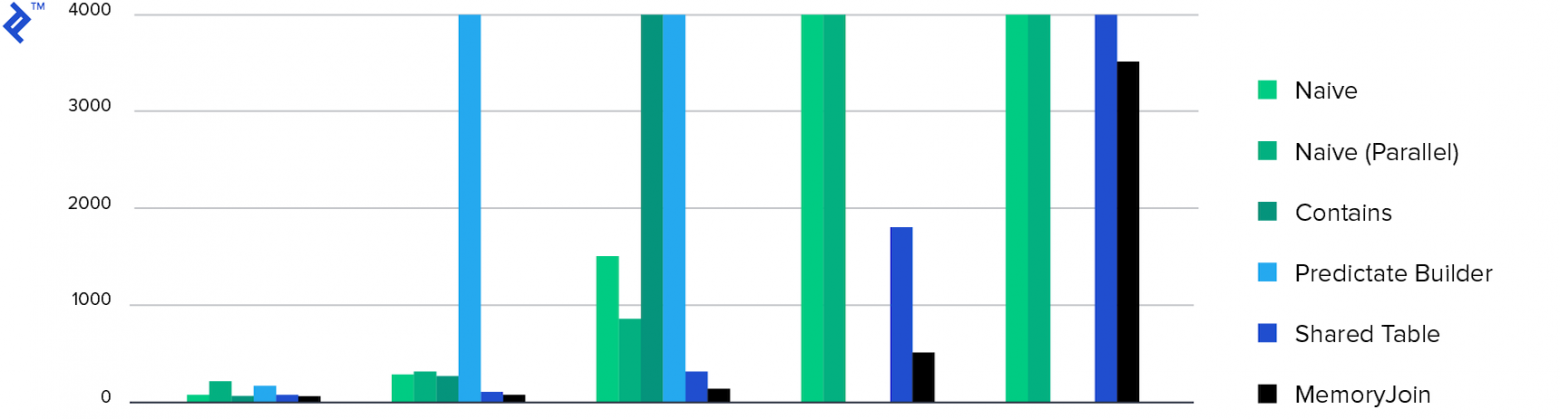
Потребление памяти. Все способы продемонстрировали примерно одинаковое потребление памяти, кроме Multiple Contains. Это связано с количеством возвращенных данных.

Thanks for reading!

