Цифровая трансформация является мировым трендом для крупного бизнеса и жизненно важна для адаптации предприятия к современным потребностям клиента. Кроме обычной для крупных компаний проблематики централизации систем и объединения биллинговых систем и абонентских БД добавляются требования к высокой доступности и режиму работы в реальном времени к которому клиенты уже привыкли у лидеров индустрии (Google, Amazon, Netflix).
Новые вызовы требуют новых технологий и подходов, которые необходимы для сокращения времени внедрения удобных клиенту функций, персонализированных коммерческих предложений, быстрой реакции на предложения конкурентов, а так же контроля затрат на системы, ИТ инфраструктуру, датацентры и квалифицированного персонала. Эти тенденции несут и большой минус: усложнение архитектуры и раздутые транзакционные базы данных, которые не справляются с потоком и обработкой информации. Технологии предыдущего поколения имеют потолок вертикального масштабирования. К примеру, экземпляр СУБД Oracle работает на пределе самого мощного сервера на процессорах x86 при нагрузке в миллиард транзакций в сутки.

Для того, чтобы выдержать подобную загрузку с которой уже давно сталкивается интернет индустрия используется новый стек технологий, таких как In-Memory кэши и NoSQL базы данных. Так, Apple применяет Cassandra, Сбербанк – Ignite (GridGain), в МегаФон мы применяем Couchbase и Tarantool.
В МегаФон используются разные архитектурные шаблоны для In-Memory СУБД:
- Простой кэш, обновляемый по расписанию или по событию из БД и приложений
- Все изменения в БД осуществляются через кэш (write-through сценарий), например, подключение Oracle клиента к DCP Couchbase
Для одной из наших систем принятия решений по жизненному циклу абонента мы используем первый шаблон, так как только одно приложение по совокупности данных принимает решение и отправляет его на все системы, в том числе и БД Oracle. Один из ярких кейсов использования жизненного цикла абонента – это блокировка и разблокировка по отрицательному балансу. Ведь все абоненты сотовых операторов после пополнения баланса хотят сразу быть на связи и совершать звонки. Благодаря вынесенному отдельному приложению и Couchbase, мы смогли сократить время выхода из блокировки с 90 секунд до 30 и это еще не предел. В основную базу попадет только запись об изменении статуса абонента (рис. 1)
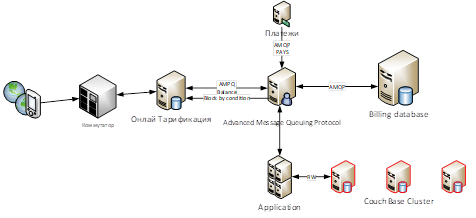
Рисунок 1 (Пример взаимодействия)
С применением новых технологий нам удалось в 3 раза уменьшить время выхода из финансовой блокировки. Но для того, чтобы получить текущие результаты, нами был пройден долгий путь архитектурной трансформации биллингового контура и выбора NoSQL базы данных.
Почему мы остановили выбор именно на Couchbase? Для этого существует несколько причин.
Требование к производительности
- Обработка до 200000 запросов в секунду.
- Среднее время отклика (50%) — до 5 мс (в рамках одного ЦОД).
- Максимальное время отклика (99%) — до 15 мс (в рамках одного ЦОД).
- Максимальная производительность вставки 500 MB/sec
- Максимальное количество операций вставок 100000/с
- Максимальное количество операций изменений (обновлений документов) 100000/с
- Максимальная производительность изменений (обновлений документов) 500 MB/sec
- Максимальное количество операций чтений 100000/с
- Максимальная скорость чтения 500 MB/sec
Высокопроизводительный поиск по ключу и доступ к данным
В основе Couchbase лежит распределенное хранилище ключей (KV). Хранилище KV представляет собой чрезвычайно простой подход к управлению данными, который хранит уникальный идентификатор (ключ) вместе с частью произвольной информации. Само хранилище KV может принимать любые данные, будь то бинарный blob или JSON-документ. Благодаря простоте реализации KV доступ к данным обеспечивается с минимальной задержкой. Как показывает наш опыт, чаще задержки по сети в 2-3 раза выше, чем предоставление данных по ключу на стороне Couchbase.
Динамическая схема хранения(JSON)
Документы хранятся на сервере Couchbase в формате JSON. Формат поддерживает как базовые типы данных, такие как числа, строки и сложные типы, так и встроенные словари и массивы.
Схема данных в Couchbase является логической конструкцией, определяемой приложением и разработчиком. За счет ее гибкости и возможности использовать несколько вариантов, мы можем использовать в документе тег, например, с информацией о версии. Это дает возможность приложению определить, в каком режиме обрабатывать документ, а также обеспечить плавную миграцию базы на новую схему данных.
Высокая доступность
Одним из составляющих параметров информационной системы является ее доступность. Couchbase обеспечивает высокую доступность данных с помощью множества различных функций. Одной из них является репликация данных (распределение нескольких копий данных на разных серверах кластера), что позволяет предоставлять сервис при регламентных работах или же выходе части серверов из строя.
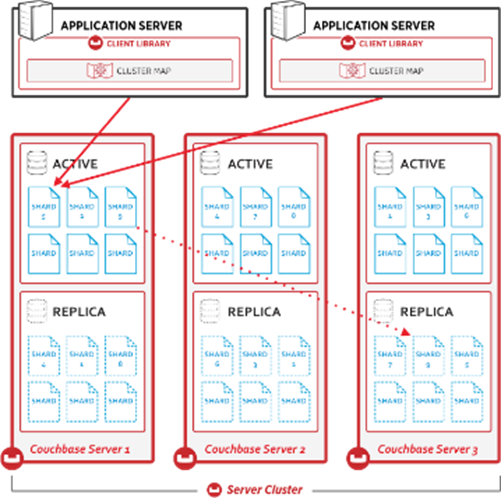
Рисунок 2 (Реплики сервера Couchbase)
Второй важной функцией для обеспечения высокой доступности является внутренний протокол DCP (Database Change Protocol). Он обеспечивает высокоскоростную передачу изменений во все копии данных, вторичные индексы (GSI), межкластерную репликацию (XDCR) и внешним потребителям.
Двунаправленная репликация
Правильной практикой в компаниях является использование резервирования всех бизнес-процессов и оборудования. В идеальном варианте это резервирование в режиме Active-Active, когда переключение между проблемными узлами происходит автоматически. Двунаправленная репликация в Couchbase позволяет обеспечить режим A-A. Но тестирование репликации показало, что она эффективна только в близко стоящих ЦОД. При разнесении более 100 км появляются конфликты. У Couchbase есть механизмы решения конфликтов: на основе Timestamp и Sequence Number. Однако, из-за временной задержки на сети, в базу попадают устаревшие данные. Мы отказались от использования двунаправленной репликации (cross-cluster consistency). Все изменения проводятся только на одном кластере. Доступность данных в режиме «чтение» обеспечивается во всех ЦОДах (A-A).
Горизонтальное масштабирование
Одной из важных характеристик большинства NoSQL БД является горизонтальное масштабирование (рис. 3). Основным отличием Couchbase является поддержка многомерного масштабирования, когда мы в кластере можем наращивать по производительности только нужную службу. Например, игра Pokemon GO использует разделение архитектуры. На старте проекта использовалось 5 серверов с совмещенными службами. После увеличения нагрузки ими была применена разнесенная архитектура: 5 серверов с данными и 55 серверов для обработки запросов и индексов. Одним из минусов масштабирования у Couchbase является возникновение проблем у оркестратора, при наличии в кластере свыше 50 дата нод.
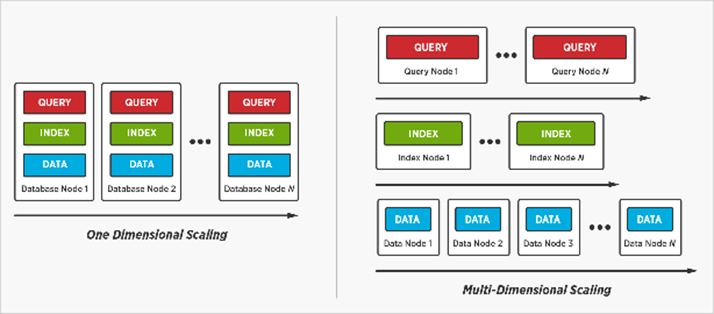
Рисунок 3 MDS
Требования ИБ
Требования информационной безопасности влияли на наш выбор в меньшей степени, но их наличие у системы выступило дополнительным аргументом в пользу той или иной БД. Так как в кэше могут содержаться персональные данные, то в обязательном порядке мы должны соблюдать требования регулятора. Стоит определиться: будем ли мы использовать дополнительное оборудование или сможем это обеспечить самой базой данных?!
В энтерпрайз версии Couchbase поддерживает шифрование трафика, шифрование данных и персонализированный доступ. Это позволяет сэкономить на оборудовании, например Cisco ASA.
Простота обновления
Одним из существенных плюсов Couchbase является прозрачный механизм обновления и поддержка API старых версий. На время обновления кластера, он работает в режиме совместимости. Новые механизмы заработают только после полного обновления кластера. Влияния на работающие приложения минимальны за счет поддержки старого API.
PS: Обновление/даунгрейд допускается только на соседних мажорных версиях
Дополнительная функциональность
Логическое распределение
Еще одной из интересных возможностей является объединение серверов в кластере в логические группы, с привязкой к ним реплик. Это позволяет распределять полные копии реплик одного кластера по разным автозалам. Что позволяет при выходе из строя одного из автозалов иметь полную копию данных во втором
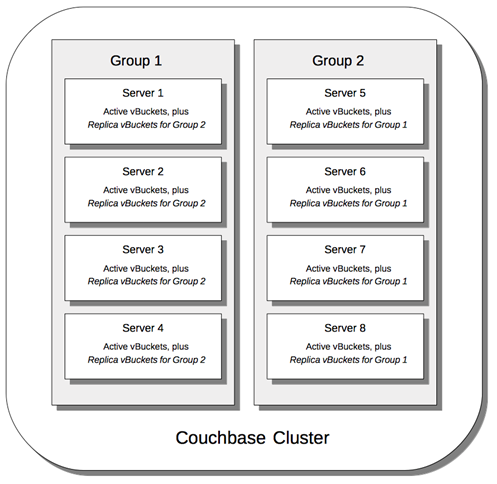
Рисунок 4 Server Gropus
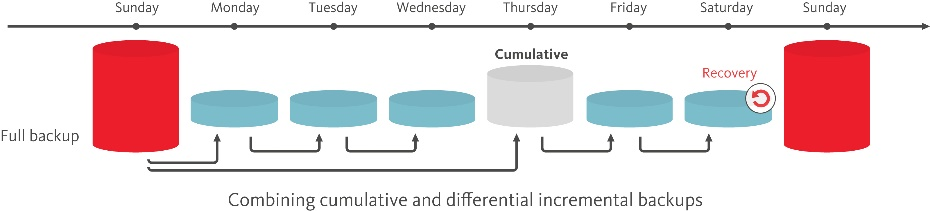
Резервное копирование и восстановление
Couchbase содержит в себе готовые инструменты для резервного копирования и восстановления. Процесс бекапа может работать в трёх режимах: полном, дифференциальном и накопительном. Это позволяет в некоторых случаях сэкономить место на дисках и процессорные ресурсы.
Couchbase vs Mongo
На вопрос выбора альтернативных NoSQL БД ответить сложно, и зачастую, лучший Unix – тот, который знает твой админ. Попытаемся сформулировать, почему мы отдали предпочтение Couchbase, а не другой очень популярной платформе – MongoDB.
Довольно сложно сравнивать два разных проекта с отличающейся архитектурой и функциональностью. Одним из параметров, на который мы обращали внимание, это простота обслуживания и возможности быстрой реконфигурации системы под потребности бизнеса.
Таблица 1 Сравнение
|
Couchbase |
MongoDB |
Масштабирование |
Автоматическое для всего набора данных |
Ручной выбор ключа |
Распределение данных |
Данные всегда равномерно распределены по всем дата нодам |
Неправильная разметка может привести к перекосу распределения данных |
Добавление/удаление узла или реплики |
Добавляется в один шаг через GUI, с ребалансировкой |
Довольно сложная задача с расчетами веса для каждой коллекции |
Распределение реплик по стойкам/ЦОД |
Реализовано через логические группы |
Не реализовано |
Автоматическое распределение нагрузки |
Каждая нода имеет одинаковое количество активных записей доступных на чтение и запись |
Не сбалансировано. Вторичные узлы не поддерживают запись |
Масштабирование индексов |
Гибкое, можно добавлять отдельные индекс ноды за счет разнесенной архитектуры |
Жесткое, масштабирование индекса связано с масштабирование данных. |
Метаданные кластера |
Распределяются по всем узлам кластера |
Требуются сервера конфигурации |
Интегрированный поиск |
N1LQ(SQL++) |
JSON запрос |
Таблица 2 Сравнение репликации
|
Couchbase |
MongoDB |
Архитектура |
Межкластерная репликация не имеет зависимостей, кластера независимы друг от друга |
Только внутрикластерное расширение |
Гибкость настройки |
Гибкая(настройка отдельных бакетов, фильтры, тюнинг) |
Тюнинг скорости |
Топология |
Двунаправленая репликация, звезда, цепь и т.д. |
Звезда |
Режим Active-Active |
Поддерживается |
Не поддерживается |
В целом, Couchbase гибче и проще в настройках, требуемых для наших задач и быстро меняющейся гибридной архитектуры.
Опыт эксплуатации
Для начала нам бы хотелось привести цифры, с которыми сейчас оперирует система и кластер на Couchbase.
- Более 80 миллионов абонентов[i]
- 380 миллионов JSON документов с информацией о клиентах
- 3,5 ТБ HDD (мы используем memcached, информация на диске хранится для быстрого старта)
- 3 ТБ ОЗУ
- 50 тыс. операций в секунду (рис 5)
- 50 микросервисов, обрабатывающих весь поток сообщений
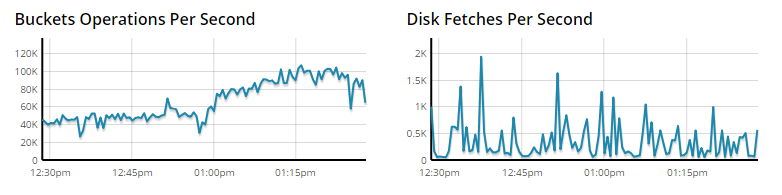
Рисунок 5 Нагрузка
Первые вехи трансформации мы начинали с третьей версией Couchbase. На первом этапе, на запуске проекта, все приложения работали стабильно. Но при переводе дополнительной логики на новый механизм, мы столкнулись с тем, что механизм вьюх (View) стал работать непредсказуемо. Т.е. в какой-то момент процесс зависал и данные вьюхи с такой ноды переставали возвращаться. При этом доступ к данным и их обработки не прерывался. Проблема исправлялась достаточно легко – перезапуском ноды, что в целом снижало доступность сервиса. В ходе общения с техподдержкой Couchbase нам предложили недокументируемую команду, перезапускающую только процесс вьюх
curl -s --data 'cb_couch_sup:restart_couch().' -u Administrator:pass http://127.0.0.1:8091/diag/eval[ii]
Команда действует только в версиях 3.x.
curl -s --data 'couch_server_sup:restart_core_server().' -u Administrator:Administrator http://127.0.0.1:8091/diag/eval
Команда действует только в версиях 4.x.
Еще одной проблемой третьей версии был ломающийся механизм сжатия данных (compaction). Его приходилось запускать вручную по сработавшим метрикам мониторинга. Обе проблемы держали в напряжении не только дежурную смену, но и функциональных инженеров.
В связи с этим, мы приняли решение о миграции на четвёртую версию. Миграция с минимальным влиянием на сервис заняла около двух недель. Сам процесс обновления не требует сложных действий и контроля, но при добавлении или удалении ноды запускается ребаланс занимающий не менее двух часов. В процессе работы мы нашли способ, как ускорить процесс обновления через буферный сервер: в этом случае запускается не чистый процесс ребалансировки, а перенос данных с одной ноды на другую. Это позволило сократить процесс обновления до 30 минут.
При обновлении промышленного кластера нужно учитывать следующий нюанс: работа в режиме совместимости, когда кластер работает в режиме самой младшей версии ПО. Положительной стороной выступает то, что процесс обновления идет плавно и безболезненно, но тем не менее новыми функциями, такими как новый механизм сжатия, N1QL, воспользоваться не получится, пока не обновится полностью весь кластер.
После обновления у нас получилось исправить только одну проблему – сжатие. Оно стало работать исправно. С механизмом View проблема всё же осталась, хотя повторялась гораздо реже. Скорректировать её удалось только силами разработчиков Couchbase в версии 4.6.4.
В рамках решения проблем с техподдержкой выяснилось: механизм вьюх больше обновляться не будет. Сделано это было на основании того, что большинство клиентов Couchbase используют вьюхи не для тех целей, для которых создавались, а Couchbase сделал новый механизм N1QL. Выполнен он отдельным сервисом и теперь не зависит от нод с данными (рис. 7)

Рисунок 7 Роли нод
Все критичные проблемы мы закрыли версией 4.6.4. Но в связи с увеличением объема данных приняли решение о миграции на пятую версию, где добавили новую БД для индексов и на наших данных объем в памяти и дисках уменьшился в полтора раза. Но, к сожалению, уменьшения объема данных на дата-нодах мы не увидели.
Выводы
В целом, Couchbase показал себя зрелой системой, держащей высокую нагрузку, даже в неспецифичных кейсах (Viber – используется как БД). В рамках гибридной архитектуры МегаФона кластер можно легко адаптировать под любые цели без простоя оборудования и без серьезной реконфигурации серверов, что в целом дает возможность компании сократить затраты на персонал и сделать сервис для абонента максимально удобным.
ПАО МегаФон
2018 Ковальчук Егор
[i] Системой обрабатываются не только абоненты, но и устройства со встроенными симкартами, модемы и прочее
[ii] Перед употреблением проконсультируйтесь со специалистом

