Когда я думаю о том, как работают наивные RPC клиенты, мне вспоминается анекдот:
Суд.
— Подсудимый, за что вы убили женщину?
— Еду я в автобусе, подходит кондуктор к женщине, с требованием купить билет. Женщина открыла сумочку, достала кошелочку, закрыла сумочку, открыла кошелочку, достала кошелек, закрыла кошелочку, открыла сумочку, положила туда кошелочку, закрыла сумочку, открыла кошелек, достала деньги, открыла сумочку, достала кошелочку, закрыла сумочку, открыла кошелочку, положила туда кошелек, закрыла кошелочку, открыла сумочку, положила туда кошелочку.
— И что?
— Контролер ей дал билет. Женщина открыла сумочку, достала кошелочку, закрыла сумочку, открыла кошелочку, достала кошелек, закрыла кошелочку, открыла сумочку, положила туда кошелочку, закрыла сумочку, открыла кошелек, положила туда билет, закрыла кошелек, открыла сумочку, достала кошелочку, закрыла сумочку, открыла кошелочку, положила туда кошелек, закрыла кошелочку, открыла сумочку, положила туда кошелочку, закрыла сумочку.
«Возьмите сдачу», раздался голос контролера. Женщина… открыла сумочку…
— Да убить её мало, — не выдерживает прокурор.
— Так я это и сделал.
© С.Альтов

Примерно то же самое происходит и в процессe "запрос-ответ", если подходить к этому несерьёзно:
- пользовательский процесс пишет сериализованный запрос "в сокет", на самом деле копируя его в буфер сокета на уровне операционки;
это довольно тяжёлая операция, т.к. необходимо сделать контекст-свитч (пусть он может быть и «лёгким»); - когда операционке кажется, что в сеть можно что-то записать, формируется пакет (запрос ещё раз копируется) и пересылается в сетевую карту;
- сетевая карта пишет пакет в сеть (возможно, предварительно буферизировав);
- (по пути пакет может несколько раз буферизироваться в маршрутизаторах);
- наконец-таки пакет прибывает в хост назначения и буферизируется в сетевой карте;
- сетевая карта посылает уведомление операционной системе, и когда операционка находит время, она копирует пакет в свой буфер и выставляет флажок готовности на файлово�� дескрипторе;
- (надо ещё не забыть послать ACK в ответ);
- через какое-то время приложение-сервер осознаёт, что на дескрипторе стоит готовность (использовав epoll), и когда-нибудь копирует запрос в буфер приложения;
- и наконец-таки приложение-сервер обрабатывает запрос.
Как вы понимаете, передача ответа происходит точно таким же образом только в обратном направлении. Таким образом, каждый запрос тратит заметное время операционной системы на своё обслуживание, и каждый ответ тратит ещё раз такое же время.
Особенно это стало заметно после Meltdown/Spectre, так как выпущенные заплатки привели к сильному удорожанию системных вызовов. В начале января 2018 года наш кластер Redis внезапно стал потреблять в полтора-два раза больше CPU, т.к. Amazon применил соответствующие патчи ядра, закрывающие эти уязвимости. (Правда, чуть позже Amazon применил новую версию заплатки, и потребление CPU уменьшилось почти до прежних уровней. Но коннектор уже начал рождаться.)
К сожалению, все широко известные Go коннекторы к Redis и Memcached работают именно так: коннектор создаёт пул коннектов, и, когда нужно послать запрос, достаёт из пула коннект, пишет в него один запрос и потом ждёт ответ. (Особенно печально, что коннектор к Memcached написан самим Брэдом Фитцпатриком.) А некоторые коннекторы имеют такую неудачную реализацию этого пула, что процесс изъятия коннекта из пула становится ботлнеком сам по себе.
Есть два способа несколько облегчить эту напряжённую работу по пересылке запрос/ответов:
- Использовать прямой доступ к сетевой карте: DPDK, netmap, PF_RING, etc.
- Не слать каждый запрос/ответ отдельным пакетом, а объединять их по возможности в более крупные пакеты, то есть размазать оверхед работы с сетью по нескольким запросам. Вместе веселее!
Первый вариант, конечно же, возможен. Но, во-первых, это для храбрых духом, ибо придётся писать реализацию TCP/IP самому (например, как в ScyllaDB). А во-вторых, так мы облегчаем ситуацию только на одной стороне — на той, которую пишем сами. Переписывать Redis мне пока не хочется (пока), так что серверы будут потреблять столько же, даже если клиент будет использовать крутой DPDK.
Второй вариант заметно проще, а главное, облегчает ситуацию сразу и на клиенте, и на сервере. Например, одна in-memory база хвастается, что может обслуживать миллионы RPS, в то время как Redis не может обслужить и пары сотен тысяч. Однако это успех не столько реализации той in-memory базы, сколько принятого когда-то решения, что протокол будет полностью асинхронным, и клиенты по возможности должны использовать эту асинхронность. Что многие клиенты (особенно используемые в бенчмарках) с успехом реализуют, посылая запросы через одно TCP соединение и, по возможности, отправляя их в сеть вместе.
Известная статья показывает, что Redis тоже может отдавать миллион ответов в секунду, если использован pipelining. Личный опыт разработки in-memory стораджей также свидетельствует о том, что пайплайнинг заметно уменьшает потребление SYS CPU и позволяет намного эффективнее использовать процессор и сеть.
Вопрос только в том, как использовать пайплайнинг, если в приложении запросы в Redis поступают зачастую по одному? А если одного сервера не хватает и используется Redis Cluster с большим числом шардов, то даже когда встречается пачка запросов, она распадается на единичные запросы на каждый шард.
Ответ, конечно же, «очевидный»: сделать неявный пайплайнинг, собрав запросы со всех параллельно работающих горутин к одному серверу Redis и послав их через одно соединение.
К слову сказать, в коннекторах на других языках неявный пайплайнинг встречается не так уж и редко: nodejs node_redis, C# RedisBoost, python's aioredis и многие другие. Многие из этих коннекторов написаны поверх ивент-лупов, и потому сбор запросов из параллельных «потоков вычисления» там выглядит естественно. В Go же пропагандируется использование синхронных интерфейсов, и, видимо, потому мало кто решает организовывать свой «луп».
Мы же хотели использовать Redis максимально эффективно и потому решили написать новый «более-лучший»(tm) коннектор: RedisPipe.
Как сделать неявный пайплайнинг?
Базовая схема:
- горутины логики приложения не пишут запросы непосредственно в сеть, а передают их горутине-коллектору;
- коллектор по возможности собирает пачку запросов, пишет их в сеть, и передаёт их горутине-читателю;
- горутина-читатель вычитывает ответы из сети, сопоставляет их с соответствующими запросами, и уведомляет горутины логики о прибывшем ответе.
О пришедшем ответе нужно как-то уведомлять. Ушлый программист на Go конечно же скажет: «Через канал!»
Но это не единственный возможный примитив синхронизации и не самый эффективный даже в среде Go. И так как потребности у разных людей разные, сделаем механизм расширяемым, предоставив возможность пользователю реализовать интерфейс (назовём его Future):
type Future interface { Resolve(val interface{}) }
И тогда базовая схема будет выглядеть так:
type future struct { req Request fut Future } type Conn struct { c net.Conn futmtx sync.Mutex wfutures []future futtimer *time.Timer rfutures chan []future } func (c *Conn) Send(r Request, f Future) { c.futmtx.Lock() defer c.futmtx.Unlock() c.wfutures = append(c.wfutures, future{req: r, fut: f}) if len(c.wfutures) == 1 { futtimer.Reset(100*time.Microsecond) } } func (c *Conn) writer() { for range c.futtimer.C { c.futmtx.Lock() futures, c.wfutures = c.wfutures, nil c.futmtx.Unlock() var b []byte for _, ft := range futures { b = AppendRequest(b, ft.req) } _, _err := c.c.Write(b) c.rfutures <- futures } } func (c *Conn) reader() { rd := bufio.NewReader(c.c) var futures []future for { response, _err := ParseResponse(rd) if len(futures) == 0 { futures = <- c.rfutures } futures[0].fut.Resolve(response) futures = futures[1:] } }
Конечно же, это очень упрощённый код. Опущены:
- установка соединения;
- таймауты ввода-вывода;
- обработка ошибок на чтении/записи;
- переустановление соединения;
- возможность отмены запроса до отправки его в сеть;
- оптимизации выделения памяти (переиспользование буфера и массивов futures).
Любая ошибка ввода-вывода (в том числе и таймаут) в реальном коде приводит к резолву ошибками всех Future, соответствующих отправленным и ожидающим отправки запросам.
Слой соединения не занимается переповтором запросов, и если нужно (и можно) сделать переповтор запроса, его можно сделать на вышележащем уровне абстракции (например, в реализации поддержки Redis Cluster, описанной ниже).
Ремарка. Изначально схема выглядела чуть сложнее. Но в процессе экспериментов упростилась до такого варианта.
Ремарка 2. К методу Future.Resolve предъявляются очень жёсткие требования: он должен быть максимально быстрым, практически не блокирующим и ни в коем случае не паниковать. Это обусловленно тем, что он зовётся синхронно в цикле reader, и любые «тормоза» неизбежно приведут к деградации. Реализация Future.Resolve должна делать необходимый минимум линейных действий: пробудить ожидающего; возможно, обработать ошибку и послать асинхронный переповтор (используется в реализации поддержки кластера).
Эффект
Хороший бенчмарк — это половина статьи!
Хороший бенчмарк — тот, который максимально приближен к боевому применению по наблюдаемым эффектам. И такой сделать нелегко.
Вариант бенчмарка, который, как мне кажется, выглядит довольно похоже на настоящий:
- основной «скрипт» эмулирует 5 параллельных клиентов,
- в каждом «клиенте» на каждые 300-1000 «желаемых» rps запускается по горутине (на 1000 rps запускается 3 горутины, на 128000 rps — 124 горутины),
- горутина использует отдельный инстанс рейт-лимитера и посылает запросы случайными сериями — от 5 до 15 запросов.
Случайность серий запросов позволяет добиться случайного распределения серий во временной шкале, что корректнее отражает реальную нагрузку.
Неправильные варианты были:
a) использовать один рейт-лимитер на все горутины «клиента» и обращаться к нему на каждый запрос — это приводит к черезмерному потреблению CPU самим рейт-лимитером, а также усиленному чередованию во времени горутин, что ухудшает характеристики RedisPipe на средних rps (но необъяснимо улучшает на высоких);
b) использовать один рейт-лимитер на все горутины «клиента» и посылать запросы сериями — рейт-лимитер уже не так сильно жрёт CPU, но чередование горутин во времени лишь усиливается;
с) использовать рейт-лимитер на каждую горутину, но посылать одинаковые серии по 10 запросов, — в этом сценарии горутины слишком одновременно просыпаются, что несправедливо улучшает результаты RedisPipe.
Тестирование проходило на четырёхъядерном AWS инстансе c5-2xlarge. Версия Redis — 5.0.
Соотношение желаемой интенсивности запросов, полученной суммарной интенсивности и потребляемого редисом цпу:
| intended rps | redigo rps / % cpu |
redispipe no wait rps / % cpu |
redispipe 50µs rps / % cpu |
redispipe 150µs rps / % cpu |
|---|---|---|---|---|
| 1000*5 | 5015 / 7% | 5015 / 6% | 5015 / 6% | 5015 / 6% |
| 2000*5 | 10022 / 11% | 10022 / 10% | 10022 / 10% | 10022 / 10% |
| 4000*5 | 20036 / 21% | 20036 / 18% | 20035 / 17% | 20035 / 15% |
| 8000*5 | 40020 / 45% | 40062 / 37% | 40060 / 26% | 40056 / 19% |
| 16000*5 | 79994 / 71% | 80102 / 58% | 80096 / 33% | 80090 / 23% |
| 32000*5 | 159590 / 96% | 160180 / 80% | 160167 / 39% | 160150 / 29% |
| 64000*5 | 187774 / 99% | 320313 / 98% | 320283 / 47% | 320258 / 37% |
| 92000*5 | 183206 / 99% | 480443 / 97% | 480407 / 52% | 480366 / 42% |
| 128000*5 | 179744 / 99% | 640484 / 97% | 640488 / 55% | 640428 / 46% |

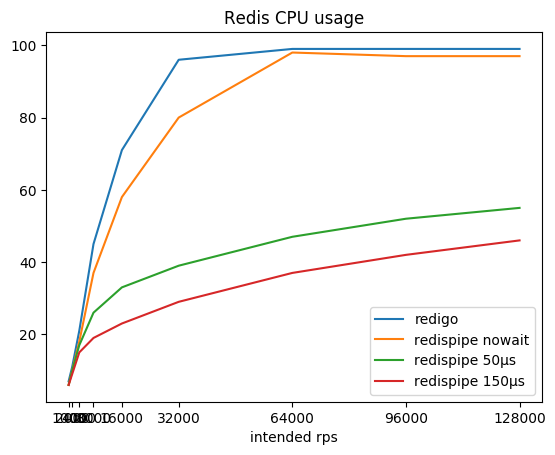
Можно заметить, что с коннектором, работающим по классической схеме (запрос/ответ + пул коннектов), Redis довольно быстро выжирает ядро процессора, после чего получить больше 190 krps становится невозможной задачей.
RedisPipe же позволяет выжать из Redis всю требуемую мощность. И чем больше мы делаем паузу на сбор параллельных запросов, тем меньше Redis потребляет CPU. Ощутимая выгода получается уже на 4krps с клиента (20krps суммарно), если используется пауза в 150 микросекунд.
Даже если явно пауза не используется, когда Redis упирается в CPU, задержка появляется сама собой. Кроме того, запросы начинают буферизироваться операционной системой. Это позволяет RedisPipe наращивать число успешно выполненных запросов, когда классический коннектор уже опускает лапки.
Это основной результат, ради которого потребовалось создавать новый коннектор.
Что же при этом происходит с потреблением CPU на клиенте и с задержкой запросов?
| intended rps | redigo %cpu / ms |
redispipe nowait %cpu / ms |
redispipe 50ms %cpu / ms |
redispipe 150ms %cpu / ms |
|---|---|---|---|---|
| 1000*5 | 13 / 0.03 | 20 / 0.04 | 46 / 0.16 | 44 / 0.26 |
| 2000*5 | 25 / 0.03 | 33 / 0.04 | 77 / 0.16 | 71 / 0.26 |
| 4000*5 | 48 / 0.03 | 60 / 0.04 | 124 / 0.16 | 107 / 0.26 |
| 8000*5 | 94 / 0.03 | 119 / 0.04 | 178 / 0.15 | 141 / 0.26 |
| 16000*5 | 184 / 0.04 | 206 / 0.04 | 228 / 0.15 | 177 / 0.25 |
| 32000*5 | 341 / 0.08 | 322 / 0.05 | 280 / 0.15 | 226 / 0.26 |
| 64000*5 | 316 / 1.88 | 469 / 0.08 | 345 / 0.16 | 307 / 0.26 |
| 92000*5 | 313 / 2.88 | 511 / 0.16 | 398 / 0.17 | 366 / 0.27 |
| 128000*5 | 312 / 3.54 | 509 / 0.37 | 441 / 0.19 | 418 / 0.29 |
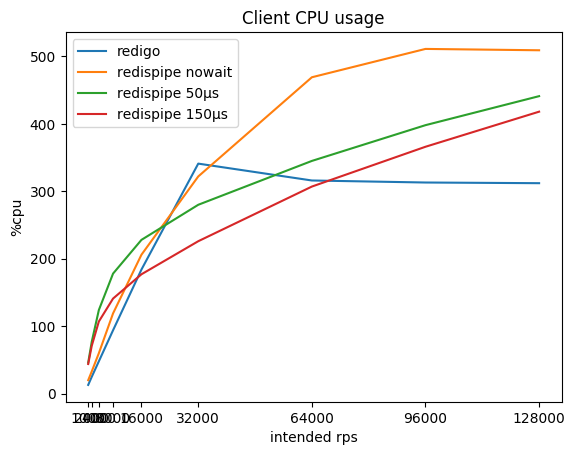
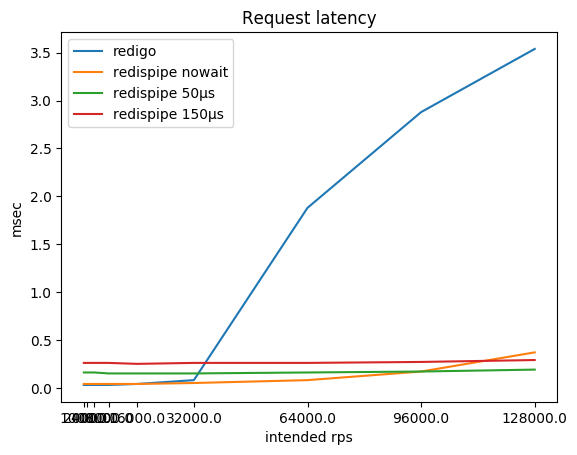
Можно заметить, что на маленьких rps RedisPipe сам потребляет больше CPU, чем «конкурент», особенно, если используется небольшая пауза. Это связанно в основном с реализацией таймеров в Go и реализацией используемых системных вызовов в операционной системе (на Linux это futexsleep), так как в режиме «без паузы» разница ощутимо меньше.
С ростом rps накладные расходы на таймеры компенсируются меньшими накладными расходами на сетевое взаимодействие, и после 16 krps на клиента использование RedisPipe с паузой 150 микросекунд начинает приносить ощутимую выгоду.
Конечно, после того как Redis упёрся в CPU, задержка запросов с использованием классического коннектора начинает безудержно расти. Не уверен, правда, что на практике вы часто достигаете 180 krps с инстанса Redis. Но если это так, то имейте в виду, что у вас могут быть проблемы.
Пока Redis не упирается в CPU, задержка запросов, конечно же, с��радает от использования паузы. Этот компромисс намеренно заложен в коннектор. Однако, этот компромисс так заметен только если Redis и клиент находятся на одном физическом хосте. В зависимости от топологии сети раундтрип до соседнего хоста может быть от ста микросекунд до миллисекунды. Соответственно, разница в задержке уже вместо девятикратной (0.26/0.03) становится трёхкратной (0.36/0.13) или же измеряется всего лишь парой десятков процентов (1.26/1.03).
В нашей нагрузке, когда Redis используется как кэш, суммарное ожидание ответов из базы данных при промахе кэша больше суммарного ожидания ответов из Redis, потому считается, что увеличение задержки не является значительным.
Главный положительный результат — это терпимость к росту нагрузки: если вдруг нагрузка на сервис увеличится в N раз, Redis не станет потреблять CPU в те же N раз больше. Чтобы выдержать учетверение нагрузки с 160 krps до 640 krps, Redis потратил всего лишь в 1.6 раза больше CPU, увеличив потребление с 29 до 46%. Это позволяет нам не бояться, что Redis внезапно загнётся. Масштабируемость приложения также не будет обусловлена работой коннектора и затратами на сетевое взаимодействие (читай: затраты на SYS CPU).
Ремарка. Код бенчмарка оперирует маленькими значениями. Для очистки совести я повторил тест со значениями размера 768 байт. Потребление CPU «редисом» заметно увеличилось (до 66% на паузе 150 µs), а потолок для классического коннектора опускается до 170 krps. Но все замеченные пропорции остались прежними, а значит, и выводы.
Кластер
Для масштабирования мы используем Redis Cluster. Это позволяет нам использовать Redis не только как кэш, но и как volatile-хранилище и при этом не терять данные при расширении/сжатии кластера.
Redis Cluster использует принцип умного клиента, т.е. клиент должен сам отслеживать состояние кластера, а также реагировать на вспомогательные ошибки, возвращаемые «редисом» когда «букет» переезжает с инстанса на инстанс.
Соответственно, клиент должен держать соединения ко всем инстансам Redis в кластере и на каждый запрос выдавать соединение к нужному. И именно в этом месте используемый до этого клиент (не будем показывать пальцем) сильно облажался. Автор, переоценивший маркетинг Go (CSP, channels, goroutines), реализовал синхронизацию работы с состоянием кластера через посылку колбэков в центральную горутину. Это стало серьёзным ботлнеком для нас. В качестве временной заплатки, нам пришлось запускать по четыре клиента к одному кластеру, каждый, в свою очередь, поднимал до сотни коннектов в пуле к каждому инстансу Redis.
Соответственно, в новом коннекторе была задача не допустить этой ошибки. Всё взаимодействие с состоянием кластера на пути выполнения запроса сделано максимально lock-free:
- состояние кластера сделано практически immutable, а не многочисленные мутации приправленны атомиками
- доступ к состоянию происходит с использованием atomic.StorePointer/atomic.LoadPointer, и потому может быть полученно без блокировки.
Таким образом, даже во время обновления состояния кластера, запросы могут использовать предыдущее состояние без боязни попасть в ожидание на блокировке.
// storeConfig atomically stores config func (c *Cluster) storeConfig(cfg *clusterConfig) { p := (*unsafe.Pointer)(unsafe.Pointer(&c.config)) atomic.StorePointer(p, unsafe.Pointer(cfg)) } // getConfig loads config atomically func (c *Cluster) getConfig() *clusterConfig { p := (*unsafe.Pointer)(unsafe.Pointer(&c.config)) return (*clusterConfig)(atomic.LoadPointer(p)) } func (cfg *clusterConfig) slot2shardno(slot uint16) uint16 { return uint16(atomic.LoadUint32(&cfg.slots[slot])) } func (cfg *clusterConfig) slotSetShard(slot, shard uint16) { atomic.StoreUint32(&cfg.slots[slot], shard) }
Состояние кластера обновляется раз в 5 секунд. Но если возникает подозрение на нестабильность кластера, обновление форсируется:
func (c *Cluster) control() { t := time.NewTicker(c.opts.CheckInterval) defer t.Stop() // main control loop for { select { case <-c.ctx.Done(): // cluster closed, exit control loop c.report(LogContextClosed{Error: c.ctx.Err()}) return case cmd := <-c.commands: // execute some asynchronous "cluster-wide" actions c.execCommand(cmd) continue case <-forceReload: // forced mapping reload c.reloadMapping() case <-t.C: // regular mapping reload c.reloadMapping() } } } func (c *Cluster) ForceReloading() { select { case c.forceReload <- struct{}{}: default: } }
Если ответ MOVED или ASK, полученный от редиса, содержит неизвестный адрес, инициируется его асинхронное добавление в конфигурацию. (Прошу прощения, не придумал, как упростить код, потому вот ссылка.) Здесь не обошлось без использования локов, но они берутся на короткий промежуток времени. Основное ожидание реализовано через сохранение колбэка в массиве — тот же future, вид сбоку.
Соединения установленны ко всем инстансам Redis, и к мастерам, и к слейвам. В зависимости от предпочитаемой политики и типа запроса (чтение или запись) запрос может быть отправлен как на мастер, так и на слейв. При этом учитывается «живость» инстанса, которая состоит как из информации, полученной при обновлении состояния кластера, так и из текущего состояния соединения.
func (c *Cluster) connForSlot(slot uint16, policy ReplicaPolicyEnum) (*redisconn.Connection, *errorx.Error) { var conn *redisconn.Connection cfg := c.getConfig() shard := cfg.slot2shard(slot) nodes := cfg.nodes var addr string switch policy { case MasterOnly: addr = shard.addr[0] // master is always first node := nodes[addr] if conn = node.getConn(c.opts.ConnHostPolicy, needConnected); conn == nil { conn = node.getConn(c.opts.ConnHostPolicy, mayBeConnected) } case MasterAndSlaves: n := uint32(len(shard.addr)) off := c.opts.RoundRobinSeed.Current() for _, needState := range []int{needConnected, mayBeConnected} { mask := atomic.LoadUint32(&shard.good) // load health information for ; mask != 0; off++ { bit := 1 << (off % n) if mask&bit == 0 { // replica isn't healthy, or already viewed continue } mask &^= bit addr = shard.addr[k] if conn = nodes[addr].getConn(c.opts.ConnHostPolicy, needState); conn != nil { return conn, nil } } } } if conn == nil { c.ForceReloading() return nil, c.err(ErrNoAliveConnection) } return conn, nil } func (n *node) getConn(policy ConnHostPolicyEnum, liveness int) *redisconn.Connection { for _, conn := range n.conns { switch liveness { case needConnected: if c.ConnectedNow() { return conn } case mayBeConnected: if c.MayBeConnected() { return conn } } } return nil }
Здесь есть загадочный RoundRobinSeed.Current(). Это, с одной стороны, источник случайности, с другой — случайности не часто меняющегося. Если выбирать новое соединение для каждого запроса, это ухудшает эффективность пайплайнинга. Именно поэтому дефолтная реализация меняет значение Current раз в несколько десятков миллисекунд. Чтобы накладки во времени были поменьше, каждый хост выбирает свой интервал.
Как вы помните, соединение использует концепцию Future для асинхронных запросов. Кластер использует ту же самую концепцию: пользовательский Future оборачивается в кластерный, и тот скармливается соединению.
Зачем оборачивать пользовательский Future? Во-первых, в режиме Cluster «редис» возвращает замечательные «ошибки» MOVED и ASK с информацией, куда нужно сходить за нужным вам ключом, и, получив такую ошибку, нужно повторить запрос на другой хост. Во-вторых, раз уж нам всё равно нужно реализовывать логику перенаправления, то почему бы не встроить и переповтор запроса при ошибке ввода-вывода (конечно, только если запрос на чтение):
type request struct { c *Cluster req Request cb Future slot uint16 policy ReplicaPolicyEnum mayRetry bool } func (c *Cluster) SendWithPolicy(policy ReplicaPolicyEnum, req Request, cb Future) { slot := redisclusterutil.ReqSlot(req) policy = c.fixPolicy(slot, req, policy) conn, err := c.connForSlot(slot, policy, nil) if err != nil { cb.Resolve(err) return } r := &request{ c: c, req: req, cb: cb, slot: slot, policy: policy, mayRetry: policy != MasterOnly || redis.ReplicaSafe(req.Cmd), } conn.Send(req, r, 0) } func (r *request) Resolve(res interface{}, _ uint64) { err := redis.AsErrorx(res) if err == nil { r.resolve(res) return } switch { case err.IsOfType(redis.ErrIO): if !r.mayRetry { // It is not safe to retry read-write operation r.resolve(err) return } fallthrough case err.HasTrait(redis.ErrTraitNotSent): // It is request were not sent at all, it is safe to retry both readonly and write requests. conn, err := r.c.connForSlot(r.slot, r.policy, r.seen) if err != nil { r.resolve(err) return } conn.Send(r.req, r) return case err.HasTrait(redis.ErrTraitClusterMove): addr := movedTo(err) ask := err.IsOfType(redis.ErrAsk) r.c.ensureConnForAddress(addr, func(conn *redisconn.Connection, cerr error) { if cerr != nil { r.resolve(cerr) } else { r.lastconn = conn conn.SendAsk(r.req, r, ask) } }) return default: // All other errors: just resolve. r.resolve(err) } }
Это так же упрощённый код. Опущены ограничение в количестве переповторов, запоминание проблемных соединений и т. д.
Комфорт
Асинхронные запросы, Future — это суперкул! Но жутко неудобно.
Интерфейс — это самое главное. Можно продать всё что угодно, если у него будет няшный интерфейс. Именно поэтому Redis и MongoDB получили свою популярность.
А значит, требуется наши асинхронные запросы превратить в синхронные.
// Sync provides convenient synchronous interface over asynchronous Sender. type Sync struct { S Sender } // Do is convenient method to construct and send request. // Returns value that could be either result or error. func (s Sync) Do(cmd string, args ...interface{}) interface{} { return s.Send(Request{cmd, args}) } // Send sends request to redis. // Returns value that could be either result or error. func (s Sync) Send(r Request) interface{} { var res syncRes res.Add(1) s.S.Send(r, &res) res.Wait() return res.r } type syncRes struct { r interface{} sync.WaitGroup } // Resolve implements Future.Resolve func (s *syncRes) Resolve(res interface{}) { s.r = res s.Done() } // Usage func get(s redis.Sender, key string) (interface{}, error) { res := redis.Sync{s}.Do("GET", key) if err := redis.AsError(res); err != nil { return nil, err } return res, nil }
AsError не выглядит родным Go-way для получения ошибки. Но мне нравится, т.к. в моём представлении результат — это Result<T,Error>, и AsError — эрзац паттерн матчинга.
Недостатки
Но, к сожалению, есть в этом благополучии ложка дёгтя.
Протокол Redis не предполагает переупорядочивания запросов. И в то же время, имеет блокирующие запросы типа BLPOP, BRPOP.
Это провал.
Как вы понимаете, если такой запрос заблокируется, он заблокирует все следующие за ним запросы. И с этим ничего не поделаешь.
После долгого обсуждения было решено запретить использовать эти запросы в RedisPipe.
Конечно, если очень нужно, то можно: выставляете параметр ScriptMode: true, и всё на вашей совести.
Альтернативы
На самом деле есть ещё альтернатива, о которой я не упомянул, но о которой осведомлённые читатели подумали, — король кластерных кешей twemproxy .
Он делает для Redis то же, что делает наш коннектор: преобразует грубый и бездушный «запрос/ответ» в нежнейший «пайплайнинг».
Но twemproxy сам будет страдать от того, что ему придётся работать по системе «запрос/ответ». Это раз. А во-вторых, мы ��спользуем «редис» в том числе как «ненадёжный сторадж» и иногда изменяем размер кластера. А twemproxy никак не облегчает задачу по ребалансингу и, кроме того, требует перезагрузки при изменении конфигурации кластера.
Влияние
Не успел написать статью, а волны от RedisPipe уже пошли. В Radix.v3 был принят патч, добавляющий пайплайнинг в их Pool:
Сheck out RedisPipe and figure out if its strategy of implicit pipelining/batching can be incorporated
Automatic pipelining for commands in Pool
По скорости они чуть-чуть уступают (судя по их бенчмаркам; но я не стану это утверждать наверняка). Но их преимущество в том, что они могут блокирующие команды направлять в другие соединения из пула.
Заключение
Вот уже скоро год, как RedisPipe вносит свой вклад в эффективность нашего сервиса.
И в предверии любых «горячих дней» одним из ресурсов, capacity которого не вызывает беспокойство, является CPU на серверах Redis.

