С чего начинается родина мы все знаем, а глубокое обучение начинается с данных. Без них невозможно обучить модель, оценить ее, да и вообще использовать. Занимаясь исследованиями, увеличивая индекс Хирша статьями о новых архитектурах нейронных сетей и экспериментируя, мы опираемся на простейшие локальные источники данных; обычно — файлы в различных форматах. Это работает, но неплохо было бы помнить про боевую систему, содержащую терабайты постоянно меняющихся данных. А это значит, что нужно упростить и ускорить передачу данных в продакшене, а также иметь возможность работы с большими данными. Вот тут и наступает время Apache Ignite.
Apache Ignite – это распределенная memory-centric база данных, а также платформа для кэширования и обработки операций, связанных с транзакциями, аналитикой и потоковыми нагрузками. Система способна перемалывать петабайты данных со скоростью оперативной памяти. В статье речь пойдет об интеграции между Apache Ignite и TensorFlow, которая позволяет применять Apache Ignite в качестве источника данных для обучения нейронной сети и инференса, а также в качестве хранилища обучаемых моделей и системы управления кластером при распределенном обучении.
Apache Ignite позволяет хранить и обрабатывать столько данных, сколько вам требуется в распределенном кластере. Чтобы воспользоваться этим преимуществом Apache Ignite при обучении нейронных сетей в TensorFlow, используйте Ignite Dataset.
Обратите внимание: Apache Ignite – это не просто одно из звеньев в конвейере ETL между базой данных или хранилищем данных и TensorFlow. Apache Ignite сам по себе — это HTAP (гибридная система для транзакционной/аналитической обработки данных). Выбирая Apache Ignite и TensorFlow, вы получаете единую систему для транзакционной и аналитической обработки и в то же время — возможность использовать операционные и исторические данные для обучения нейронной сети и инференса.
Следующие бенчмарки демонстрируют, что Apache Ignite хорошо подходит для сценариев, когда данные хранятся на единственном узле. Такая система позволяет достигать пропускной способности свыше 850 Мб/с, если хранилище данных и клиент расположены на одном узле. Если хранилище находится на удаленном узле, то пропускная способность составляет около 800 Мб/с.
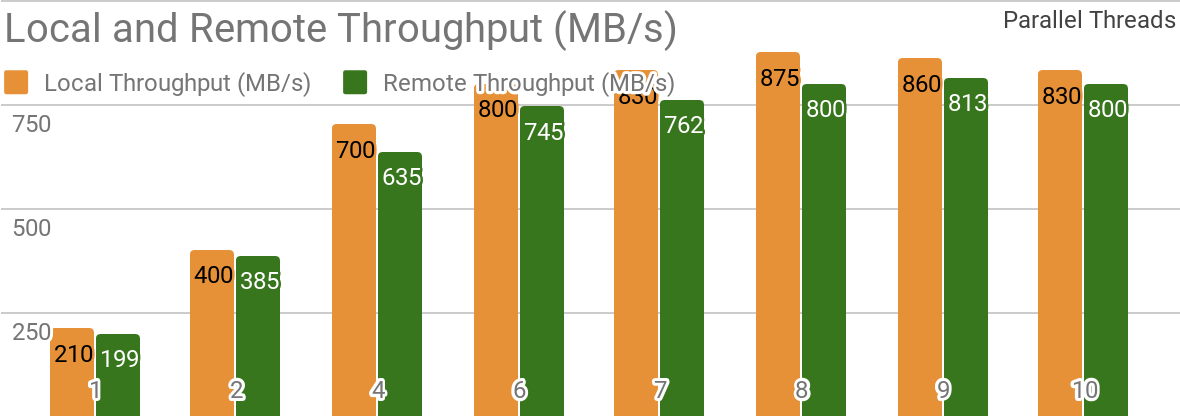
На графике показана пропускная способность для Ignite Dataset для отдельно взятого локального узла Apache Ignite. Эти результаты были получены на процессоре 2x Xeon E5-2609 v4 1.7Ггц с 16Гб оперативной памяти и в сети с пропускной способностью 10 Гб/с (каждая запись имеет размер 1Мб, размер страницы — 20Мб).
Еще один бенчмарк демонстрирует, как Ignite Dataset работает с распределенным кластером Apache Ignite. Именно такая конфигурация выбирается по умолчанию при использовании Apache Ignite в качестве HTAP-системы и позволяет достичь пропускной способности для отдельно взятого клиента свыше 1 ГБ/с на кластере с пропускной способностью 10 Гб/с.
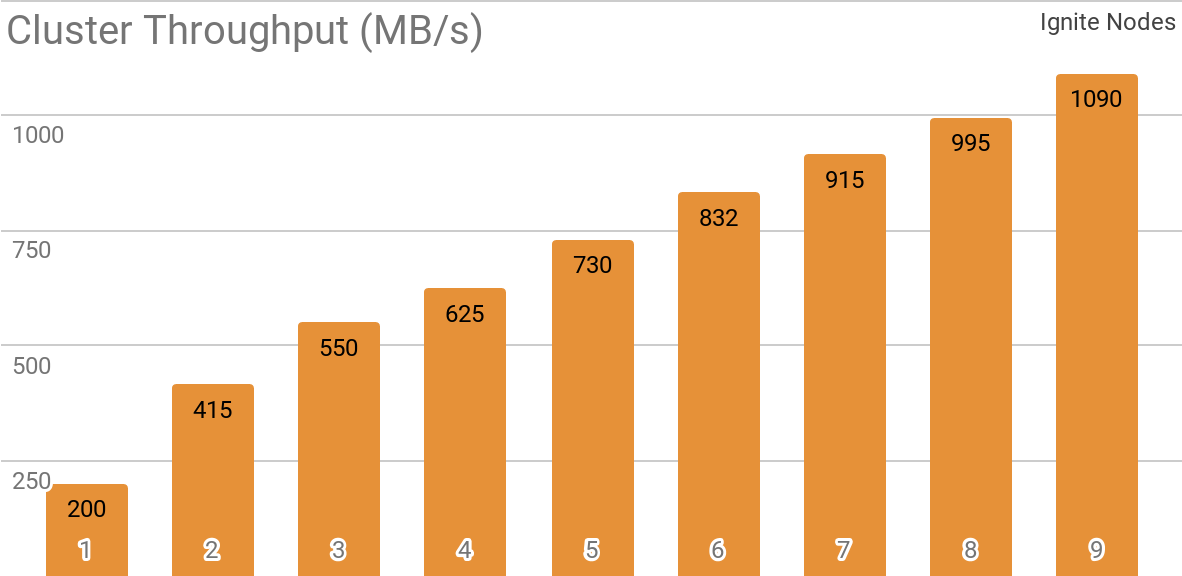
На графике показана пропускная способность Ignite Dataset для распределенного кластера Apache Ignite с разным количеством узлов (от 1 до 9). Эти результаты были получены на процессоре 2x Xeon E5-2609 v4 1.7Ггц с 16Гб оперативной памяти и в сети с пропускной способностью 10 Гб/с (каждая запись имеет размер 1Мб, размер страницы — 20Мб).
Тестировался следующий сценарий: кэш Apache Ignite (с переменным количеством партиций в первом наборе тестов и с 2048 партициями во втором) заполняется 10K строк по 1Мб каждая, после чего клиент TensorFlow считывает данные при помощи Ignite Dataset. Кластер был построен из машин с 2x Xeon E5-2609 v4 1.7ГГц, 16 Гб памяти и соединенных по сети, работающей со скоростью 10Гб/с. На каждом узле работал Apache Ignite в стандартной конфигурации.
Apache Ignite легко использовать как классическую базу данных с SQL-интерфейсом и одновременно как источник данных для TensorFlow.
Apache Ignite позволяет хранить объекты любого типа, которые можно выстраивать в любой иерархии. Работать с ним можно через Ignite Dataset.
Обучение нейронной сети и другие вычисления требуют предварительной обработки, которая может выполняться в рамках конвейера tf.data, если вы пользуетесь Ignite Dataset.
TensorFlow – это фреймворк для машинного обучения, поддерживающий распределенное обучение нейронных сетей, инференс и другие вычисления. Как известно, обучение нейронной сети основано на вычислении градиентов функции потерь. В случае распределенного обучения мы можем вычислить эти градиенты на каждой партиции, затем агрегировать их. Именно такой метод позволяет вычислять градиенты для отдельных узлов, на которых хранятся данные, суммировать их и, наконец, обновлять параметры модели. А, раз мы избавились от передачи данных обучающей выборки между узлами, сеть не становится “бутылочным горлышком” системы.
Apache Ignite использует горизонтальное партиционирование (шардирование) для хранения данных в распределенном кластере. Создавая кэш Apache Ignite (или таблицу, выражаясь в терминах SQL), можно указать количество партиций, между которыми будут распределены данные. Например, если кластер Apache Ignite состоит из 100 машин, а мы создаем кэш с 1000 партиций, то каждая машина будет отвечать примерно за 10 партиций с данными.
Ignite Dataset позволяет использовать два этих аспекта для распределенного обучения нейронных сетей. Ignite Dataset – это узел вычислительного графа, являющегося основой архитектуры TensorFlow. И, как любой узел графа, он может выполняться на удаленном узле кластера. Такой удаленный узел способен переопределять параметры Ignite Dataset (например,
Apache Ignite также позволяет проводить распределенное обучение при помощи высокоуровневого Estimator API библиотеки TensorFlow. Эта функциональность основана на так называемом standalone client mode распределенного обучения в TensorFlow, где Apache Ignite выступает в качестве источника данных и системы управления кластером. Следующая статья будет целиком посвящена этой теме.
Кроме возможностей базы данных у Apache Ignite также есть распределенная файловая система IGFS. Функционально она напоминает файловую систему Hadoop HDFS, но только в оперативной памяти. Наряду с собственными API файловая система IGFS реализует Hadoop FileSystem API и может прозрачно подключаться к развернутым Hadoop или Spark. Библиотека TensorFlow на Apache Ignite обеспечивает интеграцию между IGFS и TensorFlow. Интеграция базируется на собственном плагине файловой системы со стороны TensorFlow и нативном API IGFS со стороны Apache Ignite. Существуют разнообразные варианты сценариев ее использования, например:
Такая функциональность появилась в релизе TensorFlow 1.13.0.rc0, а также войдет в состав tensorflow/io в релизе TensorFlow 2.0.
Apache Ignite позволяет защищать каналы передачи данных при помощи SSL и аутентификации. Ignite Dataset поддерживает SSL-соединения как с аутентификацией, так и без нее. Более подробно об этом рассказано в документации Apache Ignite SSL/TLS.
Ignite Dataset полностью совместим с Windows. Его можно использовать в составе TensorFlow на рабочей станции Windows, а также в системах Linux/MacOS.
Примеры ниже помогут вам начать работу с модулем.
Простейший способ начать работу с Ignite Dataset – запустить контейнер Docker с Apache Ignite и загруженными данными MNIST, а затем работать с ним при помощи Ignite Dataset. Такой контейнер доступен в Docker Hub: dmitrievanthony/ignite-with-mnist. Нужно запустить контейнер на своей машине:
После этого вы сможете работать с ним следующим образом:
Поддержка IGFS в TensorFlow появилась в релизе TensorFlow 1.13.0rc0, а также войдет в состав релиза tensorflow/io в TensorFlow 2.0. Чтобы опробовать IGFS с TensorFlow, проще всего запустить контейнер Docker с Apache Ignite + IGFS, а затем работать с ним при помощи TensorFlow tf.gfile. Такой контейнер доступен в Docker Hub: dmitrievanthony/ignite-with-igfs. Этот контейнер можно запустить на своей машине:
Затем вы сможете работать с ним вот так:
В настоящее время при работе с Ignite Dataset предполагается, что все объекты в кэше имеют одинаковую структуру (однородные объекты), и что в кэше содержится как минимум один объект, необходимый для извлечения схемы. Другое ограничение касается структурированных объектов: Ignite Dataset не поддерживает UUID, Maps и массивы Object, которые могут входить в состав объекта. Снятие этих ограничений, а так же стабилизация и синхронизация версий TensorFlow и Apache Ignite — одна из задач ведущейся разработки.
Предстоящие изменения в версии TensorFlow 2.0 приведут к выделению этих возможностей в модуль tensorflow/io. После чего работу с ними можно будет выстроить более гибко. Примеры немного изменятся, и это будет отражено на гихабе и в документации.
Apache Ignite – это распределенная memory-centric база данных, а также платформа для кэширования и обработки операций, связанных с транзакциями, аналитикой и потоковыми нагрузками. Система способна перемалывать петабайты данных со скоростью оперативной памяти. В статье речь пойдет об интеграции между Apache Ignite и TensorFlow, которая позволяет применять Apache Ignite в качестве источника данных для обучения нейронной сети и инференса, а также в качестве хранилища обучаемых моделей и системы управления кластером при распределенном обучении.
Распределенный источник данных в оперативной памяти
Apache Ignite позволяет хранить и обрабатывать столько данных, сколько вам требуется в распределенном кластере. Чтобы воспользоваться этим преимуществом Apache Ignite при обучении нейронных сетей в TensorFlow, используйте Ignite Dataset.
Обратите внимание: Apache Ignite – это не просто одно из звеньев в конвейере ETL между базой данных или хранилищем данных и TensorFlow. Apache Ignite сам по себе — это HTAP (гибридная система для транзакционной/аналитической обработки данных). Выбирая Apache Ignite и TensorFlow, вы получаете единую систему для транзакционной и аналитической обработки и в то же время — возможность использовать операционные и исторические данные для обучения нейронной сети и инференса.
Следующие бенчмарки демонстрируют, что Apache Ignite хорошо подходит для сценариев, когда данные хранятся на единственном узле. Такая система позволяет достигать пропускной способности свыше 850 Мб/с, если хранилище данных и клиент расположены на одном узле. Если хранилище находится на удаленном узле, то пропускная способность составляет около 800 Мб/с.
На графике показана пропускная способность для Ignite Dataset для отдельно взятого локального узла Apache Ignite. Эти результаты были получены на процессоре 2x Xeon E5-2609 v4 1.7Ггц с 16Гб оперативной памяти и в сети с пропускной способностью 10 Гб/с (каждая запись имеет размер 1Мб, размер страницы — 20Мб).
Еще один бенчмарк демонстрирует, как Ignite Dataset работает с распределенным кластером Apache Ignite. Именно такая конфигурация выбирается по умолчанию при использовании Apache Ignite в качестве HTAP-системы и позволяет достичь пропускной способности для отдельно взятого клиента свыше 1 ГБ/с на кластере с пропускной способностью 10 Гб/с.
На графике показана пропускная способность Ignite Dataset для распределенного кластера Apache Ignite с разным количеством узлов (от 1 до 9). Эти результаты были получены на процессоре 2x Xeon E5-2609 v4 1.7Ггц с 16Гб оперативной памяти и в сети с пропускной способностью 10 Гб/с (каждая запись имеет размер 1Мб, размер страницы — 20Мб).
Тестировался следующий сценарий: кэш Apache Ignite (с переменным количеством партиций в первом наборе тестов и с 2048 партициями во втором) заполняется 10K строк по 1Мб каждая, после чего клиент TensorFlow считывает данные при помощи Ignite Dataset. Кластер был построен из машин с 2x Xeon E5-2609 v4 1.7ГГц, 16 Гб памяти и соединенных по сети, работающей со скоростью 10Гб/с. На каждом узле работал Apache Ignite в стандартной конфигурации.
Apache Ignite легко использовать как классическую базу данных с SQL-интерфейсом и одновременно как источник данных для TensorFlow.
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
Структурированные объекты
Apache Ignite позволяет хранить объекты любого типа, которые можно выстраивать в любой иерархии. Работать с ним можно через Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
Обучение нейронной сети и другие вычисления требуют предварительной обработки, которая может выполняться в рамках конвейера tf.data, если вы пользуетесь Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
Распределенное обучение
TensorFlow – это фреймворк для машинного обучения, поддерживающий распределенное обучение нейронных сетей, инференс и другие вычисления. Как известно, обучение нейронной сети основано на вычислении градиентов функции потерь. В случае распределенного обучения мы можем вычислить эти градиенты на каждой партиции, затем агрегировать их. Именно такой метод позволяет вычислять градиенты для отдельных узлов, на которых хранятся данные, суммировать их и, наконец, обновлять параметры модели. А, раз мы избавились от передачи данных обучающей выборки между узлами, сеть не становится “бутылочным горлышком” системы.
Apache Ignite использует горизонтальное партиционирование (шардирование) для хранения данных в распределенном кластере. Создавая кэш Apache Ignite (или таблицу, выражаясь в терминах SQL), можно указать количество партиций, между которыми будут распределены данные. Например, если кластер Apache Ignite состоит из 100 машин, а мы создаем кэш с 1000 партиций, то каждая машина будет отвечать примерно за 10 партиций с данными.
Ignite Dataset позволяет использовать два этих аспекта для распределенного обучения нейронных сетей. Ignite Dataset – это узел вычислительного графа, являющегося основой архитектуры TensorFlow. И, как любой узел графа, он может выполняться на удаленном узле кластера. Такой удаленный узел способен переопределять параметры Ignite Dataset (например,
host, port или part), устанавливая соответствующие переменные окружения для рабочего процесса (например, IGNITE_DATASET_HOST, IGNITE_DATASET_PORT или IGNITE_DATASET_PART ). Используя такое переопределение, можно присвоить каждому узлу кластера конкретную партицию. Тогда один узел отвечает за одну партицию и в то же время пользователь получает единый фасад работы с датасетом.import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES") # Локально вычисляем градиенты на каждом рабочем узле. gradients = [] for i in range(5): with tf.device("/job:WORKER/task:%d" % i): device_iterator = tf.compat.v1.data.make_one_shot_iterator(dataset) device_next_obj = device_iterator.get_next() gradient = compute_gradient(device_next_obj) gradients.append(gradient) # Агрегируем их на ведущем узле result_gradient = tf.reduce_sum(gradients) with tf.Session("grpc://localhost:10000") as sess: print(sess.run(result_gradient))
Apache Ignite также позволяет проводить распределенное обучение при помощи высокоуровневого Estimator API библиотеки TensorFlow. Эта функциональность основана на так называемом standalone client mode распределенного обучения в TensorFlow, где Apache Ignite выступает в качестве источника данных и системы управления кластером. Следующая статья будет целиком посвящена этой теме.
Хранилище контрольных точек обучения
Кроме возможностей базы данных у Apache Ignite также есть распределенная файловая система IGFS. Функционально она напоминает файловую систему Hadoop HDFS, но только в оперативной памяти. Наряду с собственными API файловая система IGFS реализует Hadoop FileSystem API и может прозрачно подключаться к развернутым Hadoop или Spark. Библиотека TensorFlow на Apache Ignite обеспечивает интеграцию между IGFS и TensorFlow. Интеграция базируется на собственном плагине файловой системы со стороны TensorFlow и нативном API IGFS со стороны Apache Ignite. Существуют разнообразные варианты сценариев ее использования, например:
- Контрольные точки состояния сохраняются в IGFS для обеспечения надежности и отказоустойчивости.
- Процессы обучения взаимодействуют с TensorBoard, записывая файлы событий в каталог, отслеживаемый TensorBoard. IGFS обеспечивает работоспособность такой связи, даже когда TensorBoard запущен в другом процессе или на другой машине.
Такая функциональность появилась в релизе TensorFlow 1.13.0.rc0, а также войдет в состав tensorflow/io в релизе TensorFlow 2.0.
SSL-соединение
Apache Ignite позволяет защищать каналы передачи данных при помощи SSL и аутентификации. Ignite Dataset поддерживает SSL-соединения как с аутентификацией, так и без нее. Более подробно об этом рассказано в документации Apache Ignite SSL/TLS.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
Поддержка Windows
Ignite Dataset полностью совместим с Windows. Его можно использовать в составе TensorFlow на рабочей станции Windows, а также в системах Linux/MacOS.
Попробуйте сами
Примеры ниже помогут вам начать работу с модулем.
Ignite Dataset
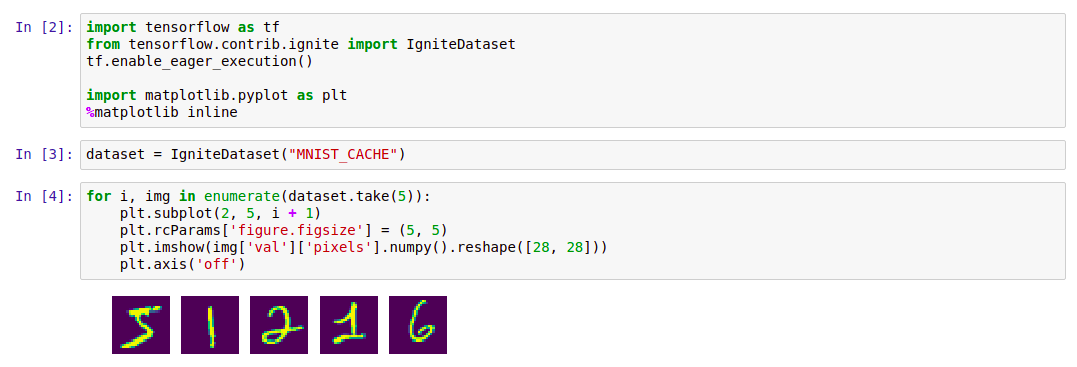
Простейший способ начать работу с Ignite Dataset – запустить контейнер Docker с Apache Ignite и загруженными данными MNIST, а затем работать с ним при помощи Ignite Dataset. Такой контейнер доступен в Docker Hub: dmitrievanthony/ignite-with-mnist. Нужно запустить контейнер на своей машине:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
После этого вы сможете работать с ним следующим образом:
Код
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
Поддержка IGFS в TensorFlow появилась в релизе TensorFlow 1.13.0rc0, а также войдет в состав релиза tensorflow/io в TensorFlow 2.0. Чтобы опробовать IGFS с TensorFlow, проще всего запустить контейнер Docker с Apache Ignite + IGFS, а затем работать с ним при помощи TensorFlow tf.gfile. Такой контейнер доступен в Docker Hub: dmitrievanthony/ignite-with-igfs. Этот контейнер можно запустить на своей машине:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
Затем вы сможете работать с ним вот так:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
Ограничения
В настоящее время при работе с Ignite Dataset предполагается, что все объекты в кэше имеют одинаковую структуру (однородные объекты), и что в кэше содержится как минимум один объект, необходимый для извлечения схемы. Другое ограничение касается структурированных объектов: Ignite Dataset не поддерживает UUID, Maps и массивы Object, которые могут входить в состав объекта. Снятие этих ограничений, а так же стабилизация и синхронизация версий TensorFlow и Apache Ignite — одна из задач ведущейся разработки.
Ожидаемая версия TensorFlow 2.0
Предстоящие изменения в версии TensorFlow 2.0 приведут к выделению этих возможностей в модуль tensorflow/io. После чего работу с ними можно будет выстроить более гибко. Примеры немного изменятся, и это будет отражено на гихабе и в документации.

