
Друзья, всем привет!
Эта статья в первую очередь будет интересна фронтенд-разработчикам, особенно тем кому актуальна тема GraphQL, но в то же время я надеюсь, что она будет полезна и бэкенд-разработчикам и поможет им понять преимущества GraphQL глазами фронтендера.
Несколько слов о себе: Я являюсь VP of Technology компании 8base. Мы разрабатываем инструменты, которые позволяют фронтенд и мобильным разработчикам быстрее создавать качественные бизнес-приложения.
Мы предоставляем платформу, в которой достаточно определить модель данных через наш UI и получить готовый GraphQL API для взаимодействия с данными. Пользователь получает настроенный сервер с ролями, правами доступа, возможностью работать с файлами, деплоить serveless-функции, CI и многое другое. Также для ускорения разработки у нас есть SDK и готовые библиотеки компонентов для React. Бэкенд пишем на Node.js
И так как основными пользователями нашей системы являются фронтенд и мобильные разработчики, мы решили сделать ставку на GraphQL, который изначально показался нам более гибким, чем REST, и дающим больше возможностей на фронте. Ну а теперь, когда мы получили достаточно обратной связи от конечных пользователей, мы можем сказать, что в нашем случае он подходит идеально.
Почему же всё-таки GraphQL?
В отличие от REST, каждый API на GraphQL предоставляет схему (schema), которая содержит информацию о входных и выходных типах данных, их полях и взаимосвязях между типами. Это позволяет использовать в API модели данных со связями, а также совершать гибкие запросы (queries) и изменения в данных (mutations), которые не зависят от представления в конкретном клиентском приложении.
Кроме того, GraphQL API позволяет клиентским разработчикам явно определять возвращаемые данные, в том числе ссылаться на связанные объекты в каждом запросе, не допускать избытка и недостатка данных (over- and under-fetching) и сокращать количество запросов к API.
Сравним GraphQL и REST
Давайте сравним GraphQL и REST на простом примере — создании интернет-блога. При выводе на экран отдельной статьи в блоге нам надо показать содержимое статьи, аватар и имя автора, список комментариев, а также аватар и имя каждого комментатора.
Если использовать REST, нам понадобятся следующие запросы к API:
GET /articles/:id — получить содержание статьи; GET /users/:id — получить URL аватара и имя автора; GET /articles/:id/comments — получить список комментариев (а если бэкенд-разработчики не встроили в него имена и аватары комментаторов, придется выполнить еще и шаг 4); GET /users/:id для каждого комментария — получить URL аватара и имя комментатора.
Обратите внимание на проблему under-fetching (когда один запрос не возвращает все что нужно) и over-fetching (когда, к примеру, запрос /users/:id возвращает больше данных, чем будет отображаться), а также на более сложный код во фронтэнде, необходимый для организации серии запросов к API.
В GraphQL вся информация может быть получена одним запросом, при условии что разработчики API указали взаимосвязи между статьями, пользователями и комментариями в схеме GraphQL API. Кроме того, ответ от API будет содержать только запрошенные поля, что уменьшит его объем.
Вот пример GraphQL-запроса, который возвратит нам сразу всю информацию в одном запросе:
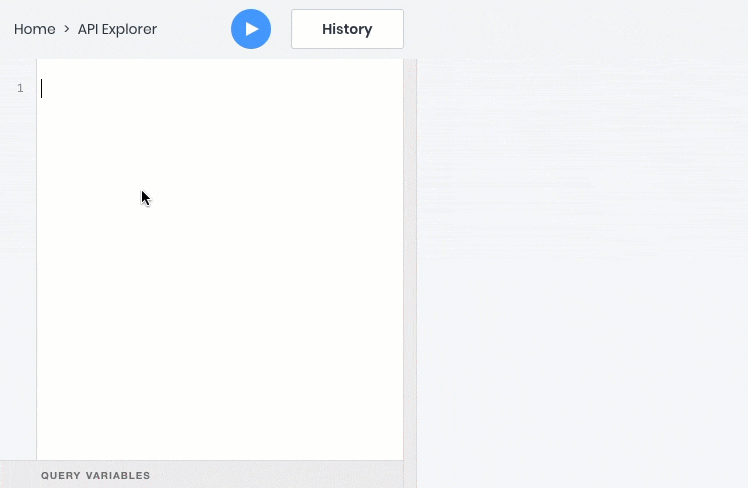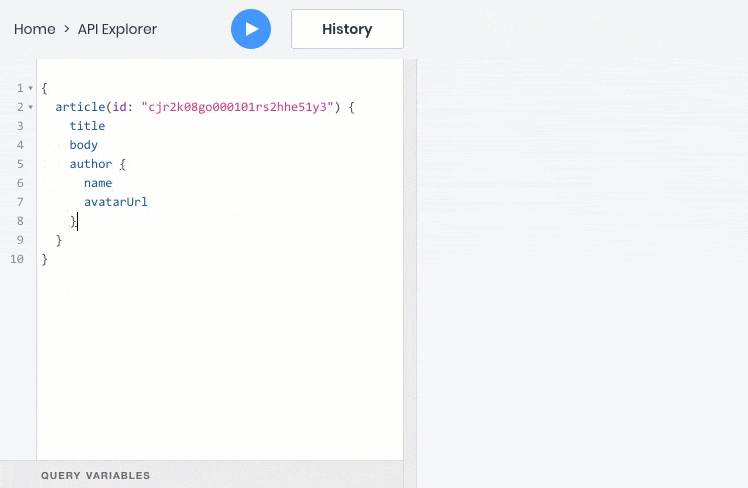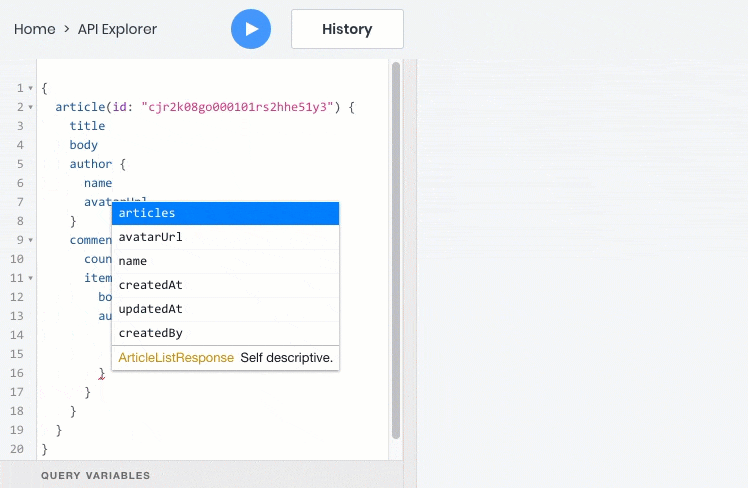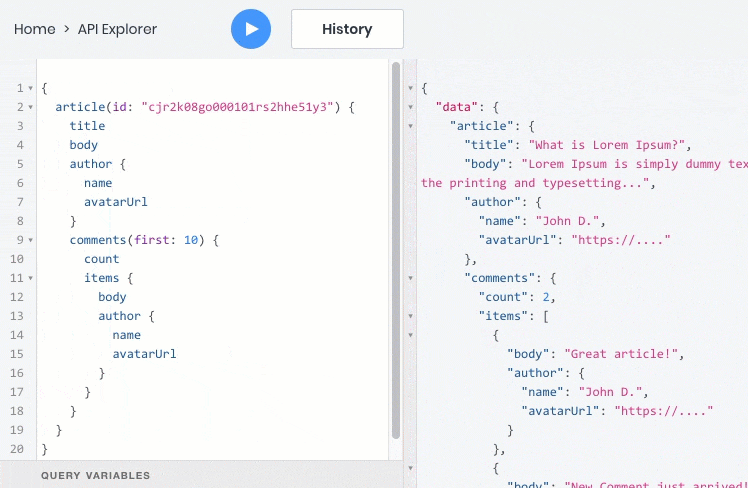
Чтобы реализовать такую возможность в REST, бэкенд-разработчикам потребовалось бы создать особый API endpoint, который возвращал бы эту информацию. Однако то же самое пришлось бы делать для каждого подобного случая с отображением данных из связанных таблиц, а заодно и обновлять API, как только фронтенду понадобятся дополнительные поля.
Этот пример показывает, как GraphQL выравнивает «баланс сил» в пользу фронтенд-разработчиков, позволяя им запрашивать любые необходимые данные, и дает бэкенд-разработчикам возможность реализовывать API так, чтобы охватить в нем всю предметную область, а не конкретное представление на клиенте.
Все это в сочетании с набором библиотек и инструментов выводит качество и удобство работы фронтенд-разработчика на новый уровень — именно поэтому популярность GraphQL среди команд разработки растет по всему миру.
Как это выглядит на практике
Один из недостатков GraphQL — более сложная реализация, чем у REST. Чтобы представить данные в удобном для самых разных клиентских приложений виде, необходим большой объем работы на бэкенде. Реализовывать CRUD-операции, связи, фильтры, сортировку и разбивку на страницы для каждого типа данных довольно утомительно. Организовать такие важные возможности, как права доступа к данным и прикрепление файлов к объектам данных, тоже не так-то просто.
Сейчас я покажу какие возможности дает использование GraphQL на примере нашей реализации:
- получить один объект по идентификатору или любому уникальному полю
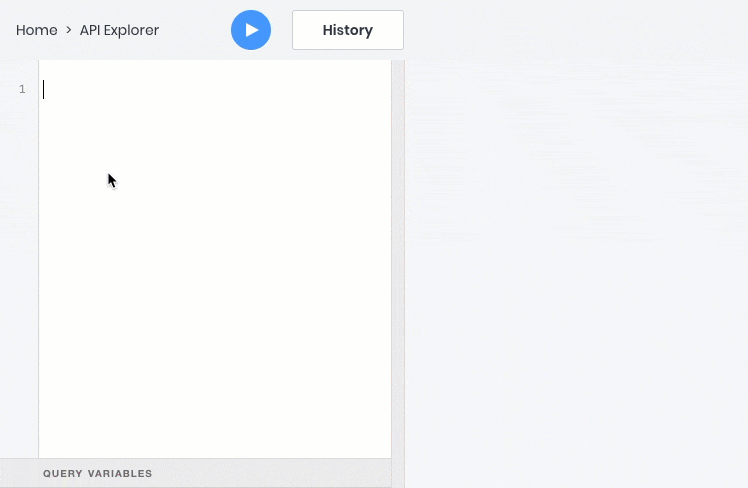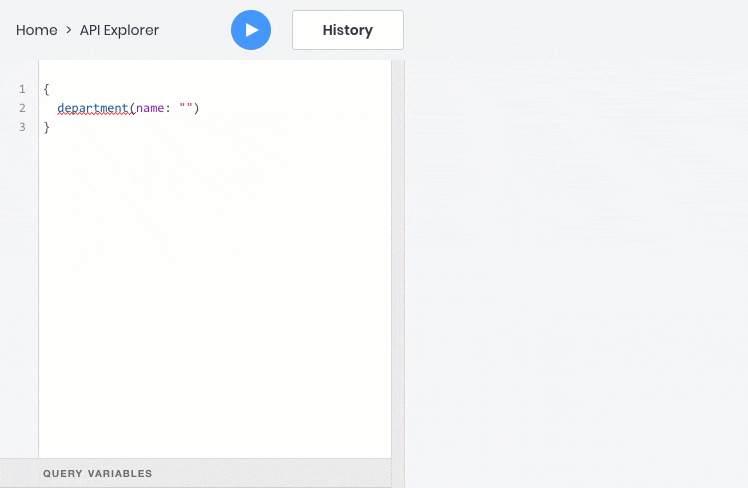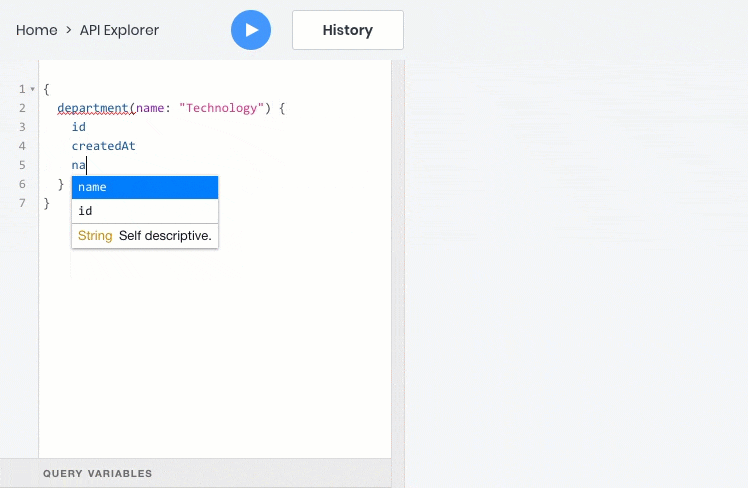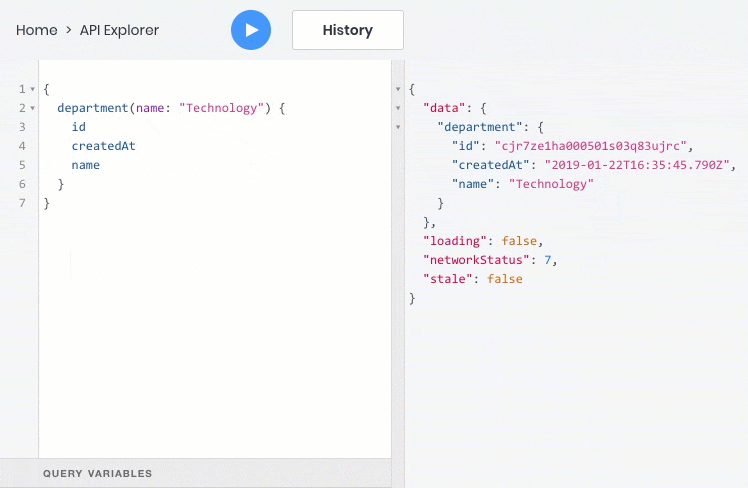
- получить список объектов на основе фильтров, сортировки, разбивки на страницы и критериев полнотекстового поиска

- создать, обновить или удалить объект

- подписаться на события данных в реальном времени через веб сокет
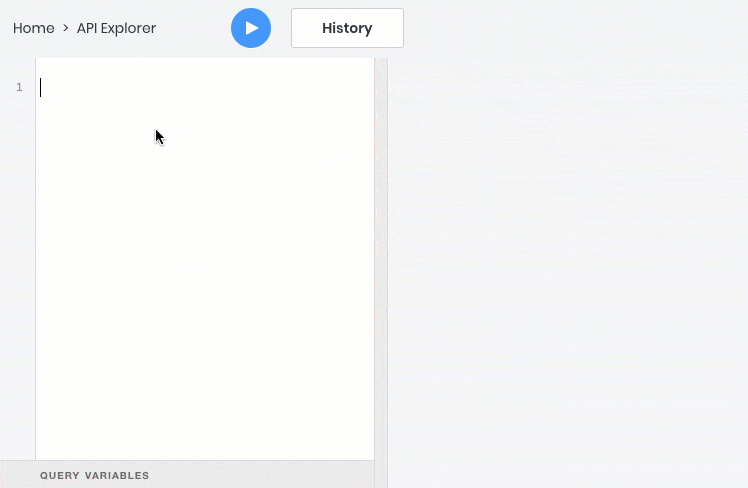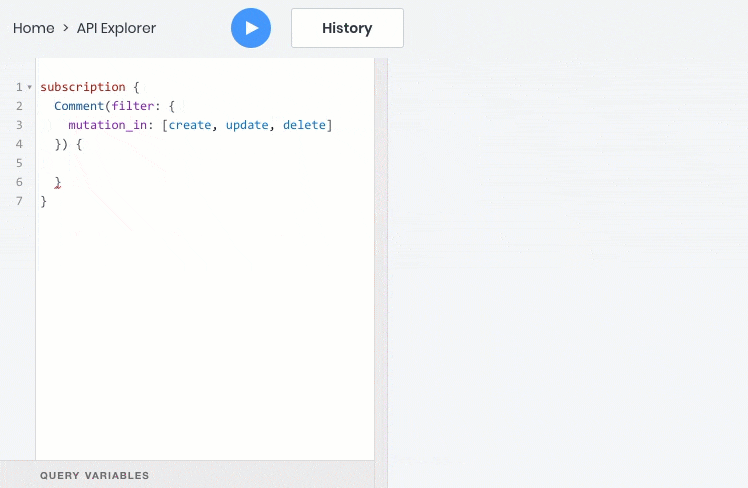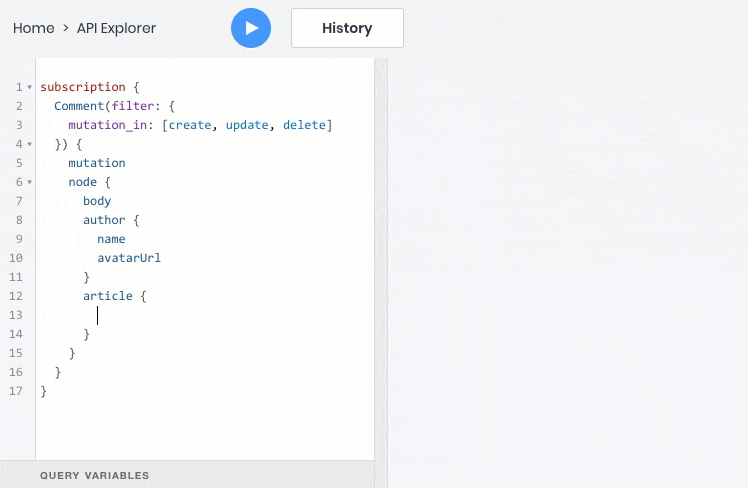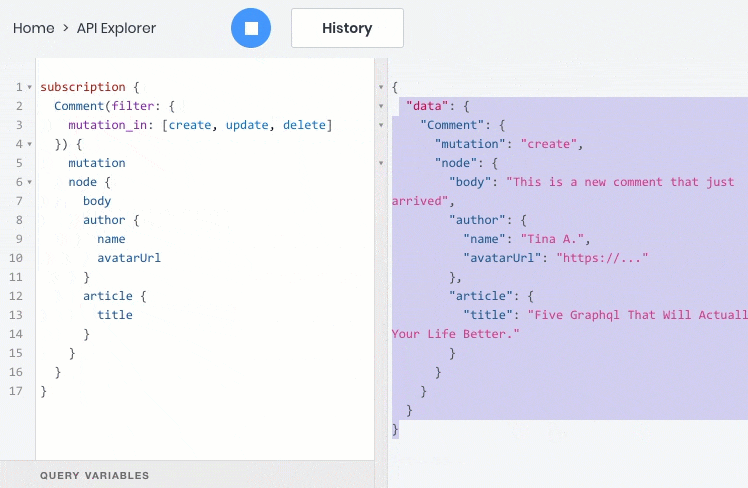
- все эти операции отлично работают со взаимосвязями между объектами, поэтому дочерние объекты можно запрашивать, создавать и обновлять вместе с родительскими:
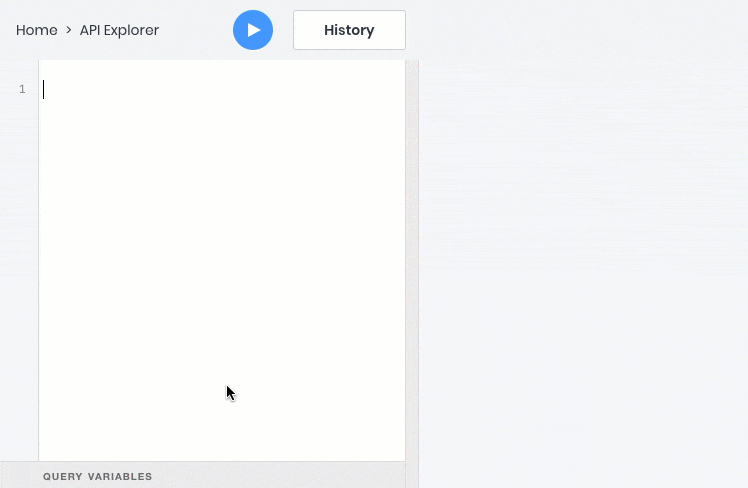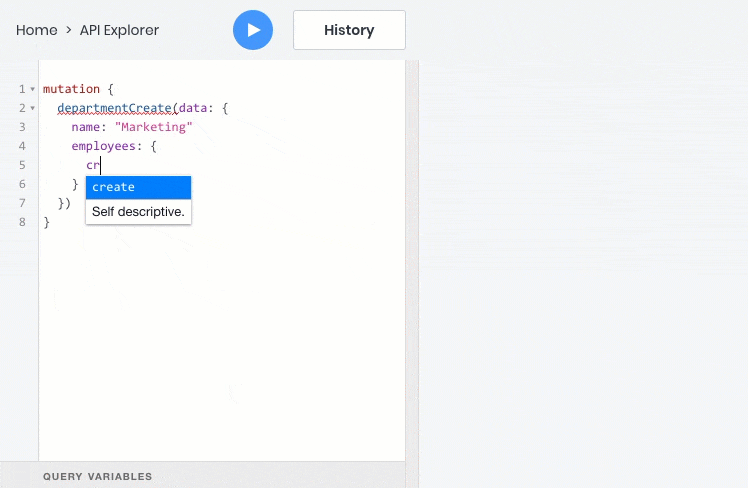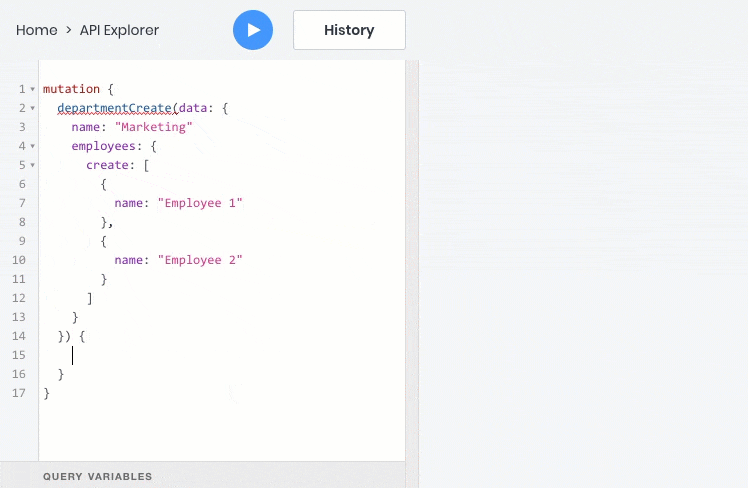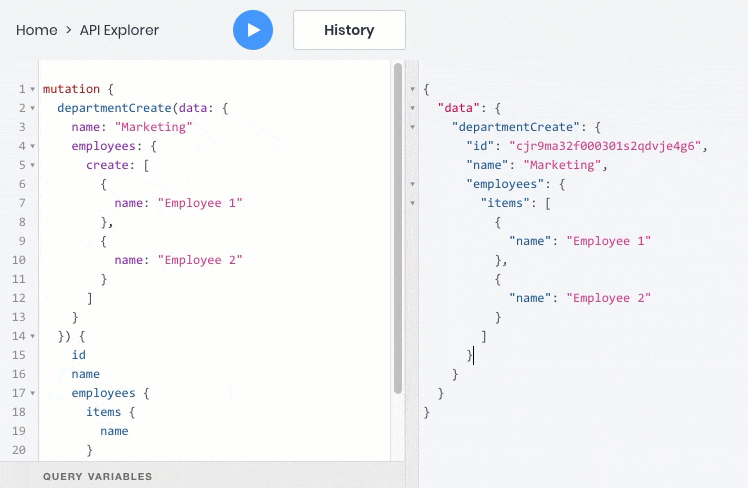
Резюме
Спасибо за внимание! Очень хотелось бы услышать ваше мнение о GraphQL или о опыте его использования, его проблемах, а так же буду рад ответить на вопросы.
Также, друзья, возможно вам было бы интересно почитать серию технических статей о нашем стеке или может быть что-то ещё?
P.S. Чуть более подробно узнать о преимуществах GraphQL для фронтенд разработчиков и о том, как мы используем GraphQL, можно на видео с выступления нашего бэкенд-разработчика Андрея Горинова

