
Итак, сразу к делу. Писать будем под Linux, на NASM и с использованием QEMU. Установить это легко, так что пропустим этот шаг.
Подразумевается, что читатель знаком с синтаксисом NASM хотя бы на базовом уровне (впрочем, ничего особо сложного здесь не будет) и понимает, что такое регистры.
Базовая теория
Первое, что запускает процессор при включении компьютера — это код BIOS (или же UEFI, но здесь я буду говорить только про BIOS), который "зашит" в памяти материнской платы (конкретно — по адресу 0xFFFFFFF0).
Сразу после включения BIOS запускает Power-On Self-Test (POST) — самотестирование после включения. BIOS проверяет работоспособность памяти, обнаруживает и инициализирует подключенные устройства, проверяет регистры, определяет размер памяти и так далее и так далее.
Следующий шаг — определение загрузочного диска, с которого можно загрузить ОС. Загрузочный диск — это диск (или любой другой накопитель), у которого последние 2 байта первого сектора (под первым сектором подразумевается первые 512 байт накопителя, т.к. 1 сектор = 512 байт) равны 55 и AA (в шестнадцатеричном формате). Как только загрузочный диск будет найден, BIOS загрузит первые его 512 байт в оперативную память по адресу 0x7c00 и передаст управление процессору по этому адресу.
Само собой, в эти 512 байт не выйдет уместить полноценную операционную систему. Поэтому обычно в этот сектор кладут первичный загрузчик, который загружает основной код ОС в оперативную память и передает ему управление.
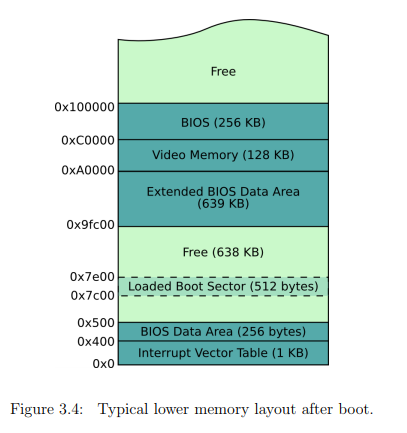
С самого начала процессор работает в Real Mode (= 16-битный режим). Это означает, что он может работать лишь с 16-битными данными и использует сегментную адресацию памяти, а также может адресовать только 1 Мб памяти. Но вторым мы пользоваться здесь не будем. Картинка ниже показывает состояние оперативной памяти при передаче управления нашему коду (картинка взята отсюда).
Последнее, о чем стоит сказать перед практической частью — прерывания. Прерывание — это особый сигнал (например, от устройства ввода, такого, как клавиатура или мышь) процессору, который говорит, что нужно немедленно прервать исполнение текущего кода и выполнить код обработчика прерывания. Все адреса обработчиков прерывания находятся в Interrupt Descriptor Table (IDT) в оперативной памяти. Каждому прерыванию соответствует свой обработчик прерывания. Например, при нажатии клавиши клавиатуры вызывается прерывание, процессор останавливается, запоминает адрес прерванной инструкции, сохраняет все значения своих регистров (на стеке) и переходит к выполнению обработчика прерывания. Как только его выполнение заканчивается, процессор восстанавливает значения регистров и переходит обратно, к прерванной инструкции и продолжает выполнение.
Например, чтобы вывести что-то на экран в BIOS используется прерывание 0x10 (шестнадцатеричный формат), а для ожидания нажатия клавиши — прерывание 0x16. По сути, это все прерывания, что нам понадобятся здесь.
Также, у каждого прерывания есть своя подфункция, определяющая особенность его поведения. Чтобы вывести что-то на экран в текстовом формате (!), нужно в регистр AH занести значение 0x0e. Помимо этого, у прерываний есть свои параметры. 0x10 принимает значения из ah (определяет конкретную подфункцию) и al (символ, который нужно вывести). Таким образом,
mov ah, 0x0e mov al, 'x' int 0x10
выведет на экран символ 'x'. 0x16 принимает значение из ah (конкретная подфункция) и загружает в регистр al значение введенной клавиши. Мы будем использовать функцию 0x0.
Практическая часть
Начнем с вспомогательного кода. Нам понадобятся функции сравнения двух строк и функция вывода строки на экран. Я попытался максимально понятно описать работу этих функций в комментариях.
str_compare.asm:
compare_strs_si_bx: push si ; сохраняем все нужные в функции регистры на стеке push bx push ax comp: mov ah, [bx] ; напрямую регистры сравнить не получится, cmp [si], ah ; поэтому переносим первый символ в ah jne not_equal ; если символы не совпадают, то выходим из функции cmp byte [si], 0 ; в обратном случае сравниваем, является ли символ je first_zero ; символом окончания строки inc si ; переходим к следующему байту bx и si inc bx jmp comp ; и повторяем first_zero: cmp byte [bx], 0 ; если символ в bx != 0, то значит, что строки jne not_equal ; не равны, поэтому переходим в not_equal mov cx, 1 ; в обратном случае строки равны, значит cx = 1 pop si ; поэтому восстанавливаем значения регистров pop bx pop ax ret ; и выходим из функции not_equal: mov cx, 0 ; не равны, значит cx = 0 pop si ; восстанавливаем значения регистров pop bx pop ax ret ; и выходим из функции
В качестве параметров функция принимает регистры SI и BX. Если строки равны, то в CX устанавливается 1, в обратном случае — 0.
Еще стоит отметить, что регистры AX, BX, CX и DX делятся на две однобайтовых части: AH, BH, CH, и DH для старшего байта, а AL, BL, CL и DL для младшего байта.
Изначально подразумевается, что в bx и si находятся указатели (!) (то есть хранит адрес в памяти) на какой-то адрес в памяти, в котором находится начало строки. Операция [bx] возьмет из bx указатель, пройдет по этому адресу и возьмет оттуда какое-то значение. inc bx значит, что теперь указатель будет ссылаться на адрес, идущий сразу после изначального адреса.
print_string.asm:
print_string_si: push ax ; сохраняем ax на стеке mov ah, 0x0e ; устанавливаем ah в 0x0e, чтобы вызвать функцию call print_next_char ; прерывания pop ax ; восстанавливаем ax ret ; и выходим print_next_char: mov al, [si] ; загрузка одного символа cmp al, 0 ; если si закончилась jz if_zero ; то выходим из функции int 0x10 ; в обратном случае печатаем al inc si ; и инкрементируем указатель jmp print_next_char ; и начинаем заново... if_zero: ret
В качестве параметра функция принимает регистр SI и байт за байтом печатает строку.
Теперь перейдем к основному коду. Для начала определимся со всеми переменными (этот код будет находиться в самом конце файла):
; 0x0d - символ возварата картки, 0xa - символ новой строки wrong_command: db "Wrong command!", 0x0d, 0xa, 0 greetings: db "The OS is on. Type 'help' for commands", 0x0d, 0xa, 0xa, 0 help_desc: db "Here's nothing to show yet. But soon...", 0x0d, 0xa, 0 goodbye: db 0x0d, 0xa, "Goodbye!", 0x0d, 0xa, 0 prompt: db ">", 0 new_line: db 0x0d, 0xa, 0 help_command: db "help", 0 input: times 64 db 0 ; размер буфера - 64 байта times 510 - ($-$$) db 0 dw 0xaa55
Символ возврата каретки перемещает каретку к левому краю экрана, то есть в начало строки.
input: times 64 db 0
значит, что мы выделяем под буфер для ввода 64 байта и заполняем их нулями.
Остальные переменные нужны для вывода какой-то информации, дальше по коду вы поймете, зачем они все нужны.
times 510 - ($-$$) db 0 dw 0xaa55
значит, что мы явно устанавливаем размер выходного файла (с расширением .bin) как 512 байт, заполняем первые 510 байт нулями (само собой, они заполняются перед исполнением всего кода), а последние два байта — теми самыми "магическими" байтами 55 и AA. $ означает адрес текущей инструкции, а $$ — адрес самой первой инструкции нашего кода.
Перейдем к собственно коду:
org 0x7c00 ; (1) bits 16 ; (2) jmp start ; сразу переходим в start %include "print_string.asm" ; импортируем наши вспомогательные функции %include "str_compare.asm" ; ==================================================== start: mov ah, 0x00 ; очистка экрана (3) mov al, 0x03 int 0x10 mov sp, 0x7c00 ; инициализация стека (4) mov si, greetings ; печатаем приветственное сообщение call print_string_si ; после чего сразу переходим в mainloop
(1). Эта команда дает понять NASM'у, что мы выполняем код, начиная с адреса 0x7c00. Это позволяет ему автоматически смещать все адреса относительно этого адреса, чтобы мы не делали это явно.
(2). Эта команда дает указание NASM'у, что мы работаем в 16-битном режиме.
(3). При запуске QEMU печатает на экране много ненужной нам информации. Для этого устанавливаем в ah 0x00, в al 0x03 и вызываем 0x10, чтобы очистить экран от всего.
(4). Чтобы сохранять регистры в стеке, необходимо указать, по какому адресу будет находиться его вершина с помощью указателя стека SP. SP будет указывать на область в памяти, в которую будет записано очередное значение. Добавляем значение на стек — SP спускается вниз по памяти на 2 байта (т.к. мы в Real Mode, где все операнды регистра — 16-битные, т.е. двухбайтные, значения). Мы указали 0x7c00, поэтому значения в стеке будут сохраняться прямо возле нашего кода в памяти. Еще раз — стек растет вниз (!). Это значит, что чем больше значений будет в стеке, тем на меньшую память будет указывать указатель стека SP.
mainloop: mov si, prompt ; печатаем стрелочку call print_string_si call get_input ; вызываем функцию ожидания ввода jmp mainloop ; повторяем mainloop...
Главный цикл. Здесь с каждой итерацией мы печатаем символ ">", после чего вызываем функцию get_input, реализующее работу с прерыванием клавиатуры.
get_input: mov bx, 0 ; инициализируем bx как индекс для хранения ввода input_processing: mov ah, 0x0 ; параметр для вызова 0x16 int 0x16 ; получаем ASCII код cmp al, 0x0d ; если нажали enter je check_the_input ; то вызываем функцию, в которой проверяем, какое ; слово было введено cmp al, 0x8 ; если нажали backspace je backspace_pressed cmp al, 0x3 ; если нажали ctrl+c je stop_cpu mov ah, 0x0e ; во всех противных случаях - просто печатаем ; очередной символ из ввода int 0x10 mov [input+bx], al ; и сохраняем его в буффер ввода inc bx ; увеличиваем индекс cmp bx, 64 ; если input переполнен je check_the_input ; то ведем себя так, будто был нажат enter jmp input_processing ; и идем заново
(1) [input+bx] значит, что мы берем адрес начала буфера ввода input и прибавляем к нему bx, то есть получаем к bx+1-ому элементу буфера.
stop_cpu: mov si, goodbye ; печатаем прощание call print_string_si jmp $ ; и останавливаем компьютер ; $ означает адрес текущей инструкции
Здесь все просто — если нажали Ctrl+C, компьютер просто бесконечно выполняет функцию jmp $.
backspace_pressed: cmp bx, 0 ; если backspace нажат, но input пуст, то je input_processing ; ничего не делаем mov ah, 0x0e ; печатаем backspace. это значит, что каретка int 0x10 ; просто передвинется назад, но сам символ не сотрется mov al, ' ' ; поэтому печатаем пробел на том месте, куда int 0x10 ; встала каретка mov al, 0x8 ; пробел передвинет каретку в изначальное положение int 0x10 ; поэтому еще раз печатаем backspace dec bx mov byte [input+bx], 0 ; и убираем из input последний символ jmp input_processing ; и возвращаемся обратно
Чтобы не стирать символ '>' при нажатии backspace, проверяем, пуст ли input. Если нет, то ничего не делаем.
check_the_input: inc bx mov byte [input+bx], 0 ; в конце ввода ставим ноль, означающий конец ; стркоки (тот же '\0' в Си) mov si, new_line ; печатаем символ новой строки call print_string_si mov si, help_command ; в si загружаем заранее подготовленное слово help mov bx, input ; а в bx - сам ввод call compare_strs_si_bx ; сравниваем si и bx (введено ли help) cmp cx, 1 ; compare_strs_si_bx загружает в cx 1, если ; строки равны друг другу je equal_help ; равны => вызываем функцию отображения ; текста help jmp equal_to_nothing ; если не равны, то выводим "Wrong command!"
Тут, думаю все понятно по комментариям.
equal_help: mov si, help_desc call print_string_si jmp done equal_to_nothing: mov si, wrong_command call print_string_si jmp done
В зависимости от того, что было введено, выводим либо текст переменной help_desc, либо текст переменной wrong_command.
; done очищает всю переменную input done: cmp bx, 0 ; если зашли дальше начала input в памяти je exit ; то вызываем функцию, идующую обратно в mainloop dec bx ; если нет, то инициализируем очередной байт нулем mov byte [input+bx], 0 jmp done ; и делаем то же самое заново exit: ret
Собственно, весь код целиком:
prompt.asm:
org 0x7c00 bits 16 jmp start ; сразу переходим в start %include "print_string.asm" %include "str_compare.asm" ; ==================================================== start: cli ; запрещаем прерывания, чтобы наш код ; ничто лишнее не останавливало mov ah, 0x00 ; очистка экрана mov al, 0x03 int 0x10 mov sp, 0x7c00 ; инициализация стека mov si, greetings ; печатаем приветственное сообщение call print_string_si ; после чего сразу переходим в mainloop mainloop: mov si, prompt ; печатаем стрелочку call print_string_si call get_input ; вызываем функцию ожидания ввода jmp mainloop ; повторяем mainloop... get_input: mov bx, 0 ; инициализируем bx как индекс для хранения ввода input_processing: mov ah, 0x0 ; параметр для вызова 0x16 int 0x16 ; получаем ASCII код cmp al, 0x0d ; если нажали enter je check_the_input ; то вызываем функцию, в которой проверяем, какое ; слово было введено cmp al, 0x8 ; если нажали backspace je backspace_pressed cmp al, 0x3 ; если нажали ctrl+c je stop_cpu mov ah, 0x0e ; во всех противных случаях - просто печатаем ; очередной символ из ввода int 0x10 mov [input+bx], al ; и сохраняем его в буффер ввода inc bx ; увеличиваем индекс cmp bx, 64 ; если input переполнен je check_the_input ; то ведем себя так, будто был нажат enter jmp input_processing ; и идем заново stop_cpu: mov si, goodbye ; печатаем прощание call print_string_si jmp $ ; и останавливаем компьютер ; $ означает адрес текущей инструкции backspace_pressed: cmp bx, 0 ; если backspace нажат, но input пуст, то je input_processing ; ничего не делаем mov ah, 0x0e ; печатаем backspace. это значит, что каретка int 0x10 ; просто передвинется назад, но сам символ не сотрется mov al, ' ' ; поэтому печатаем пробел на том месте, куда int 0x10 ; встала каретка mov al, 0x8 ; пробел передвинет каретку в изначальное положение int 0x10 ; поэтому еще раз печатаем backspace dec bx mov byte [input+bx], 0 ; и убираем из input последний символ jmp input_processing ; и возвращаемся обратно check_the_input: inc bx mov byte [input+bx], 0 ; в конце ввода ставим ноль, означающий конец ; стркоки (тот же '\0' в Си) mov si, new_line ; печатаем символ новой строки call print_string_si mov si, help_command ; в si загружаем заранее подготовленное слово help mov bx, input ; а в bx - сам ввод call compare_strs_si_bx ; сравниваем si и bx (введено ли help) cmp cx, 1 ; compare_strs_si_bx загружает в cx 1, если ; строки равны друг другу je equal_help ; равны => вызываем функцию отображения ; текста help jmp equal_to_nothing ; если не равны, то выводим "Wrong command!" equal_help: mov si, help_desc call print_string_si jmp done equal_to_nothing: mov si, wrong_command call print_string_si jmp done ; done очищает всю переменную input done: cmp bx, 0 ; если зашли дальше начала input в памяти je exit ; то вызываем функцию, идующую обратно в mainloop dec bx ; если нет, то инициализируем очередной байт нулем mov byte [input+bx], 0 jmp done ; и делаем то же самое заново exit: ret ; 0x0d - символ возварата картки, 0xa - символ новой строки wrong_command: db "Wrong command!", 0x0d, 0xa, 0 greetings: db "The OS is on. Type 'help' for commands", 0x0d, 0xa, 0xa, 0 help_desc: db "Here's nothing to show yet. But soon...", 0x0d, 0xa, 0 goodbye: db 0x0d, 0xa, "Goodbye!", 0x0d, 0xa, 0 prompt: db ">", 0 new_line: db 0x0d, 0xa, 0 help_command: db "help", 0 input: times 64 db 0 ; размер буффера - 64 байта times 510 - ($-$$) db 0 dw 0xaa55
Чтобы все это скомпилировать, введем команду:
nasm -f bin prompt.asm -o bootloader.bin
И получим на выходе бинарник с нашим кодом. Теперь запустим эмулятор QEMU с этим файлом (-monitor stdio позволяет в любой момент вывести значение регистра с помощью команды print $reg):
qemu-system-i386 bootloader.bin -monitor stdio
И получим на выходе:


