Привет, Хабр! Предлагаю вашему вниманию перевод статьи Rudy Gilman и Katherine Wang Intuitive RL: Intro to Advantage-Actor-Critic (A2C).

Специалисты по обучению с подкреплением (RL) подготовили множество отличных учебных пособий. Большинство, однако, описывают RL в терминах математических уравнений и абстрактных диаграмм. Нам нравится думать о предмете с другой точки зрения. Сама RL вдохновлена тем, как учатся животные, так почему бы не перевести лежащий в основе этого механизм RL обратно в природные явления, которые он призван имитировать? Люди учатся лучше всего через истории.
Это история о модели Actor Advantage Critic (A2C). Модель «Субъект-критик» — это популярная форма модели Policy Gradient, которая сама по себе является традиционным алгоритмом RL. Если вы понимаете A2C, вы понимаете глубокий RL.
После того, как вы приобретете интуитивное понимание A2C, проверьте:
- Нашу простую реализацию кода A2C (для обучения) или нашу промышленную версию PyTorch, основанную на модели OpenAI TensorFlow Baselines;
- Введение в RL от Barto & Sutton, канонический курс Дэвида Сильвера, обзор Юси Ли и репозиторий Денни Бритса на GitHub для глубокого погружения в RL;
- Удивительный курс fast.ai для интуитивного и практического освещения глубокого обучения в целом, реализованный в PyTorch;
- Учебные пособия Артура Джулиани по RL, реализованные в TensorFlow.
Иллюстрации @embermarke
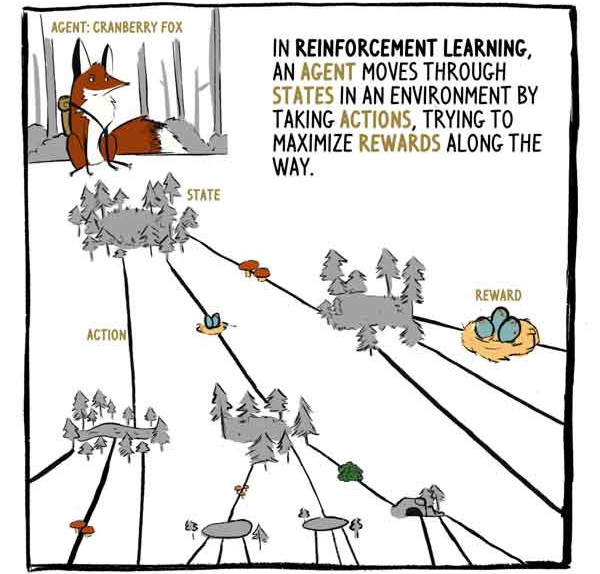
В RL, агент (agent) — лиса Клюковка, — двигается по состояниям (states) в окружении путем совершения действий (actions), пытаясь максимизировать вознаграждения (rewards) в течении пути.
A2C принимает на вход состояния — сенсорные входы в случае Клюковки — и генерирует два выхода:
1) Оценка того, сколько вознаграждения будет получено, начиная с момента текущего состояния, за исключением текущего (уже имеющегося) вознаграждения.
2) Рекомендацию, какое действие предпринять (политика).
«Критик»: вау, какая чудесная долина! Это будет плодотворный день для фуражировки! Могу поспорить, сегодня до заката я соберу 20 очков.
«Субъект»: эти цветы выглядят красиво, я чувствую тягу к «А».

Глубокие модели RL — это машины отображения «вход-выход», как и любые другие модели классификации или регрессии. Вместо распределения изображений или текста по категориям, глубокие модели RL приводят состояния к действиям и/или состояния к значениям состояний. A2C делает и то, и другое.


Этот набор состояние-действие-вознаграждение составляет одно наблюдение. Она будет записывать эту строку данных в свой журнал, но она пока не собирается об этом думать. Она заполнит его, когда остановится, чтобы подумать.
Некоторые авторы связывают вознаграждение 1 с шагом времени 1, другие ассоциируют его с шагом 2, но все имеют в виду одну и ту же концепцию: вознаграждение связано с состоянием, а действие непосредственно предшествует ему.

Клюковка снова повторяет процесс. Сначала она воспринимает свое окружение и вырабатывает функцию V(S) и рекомендацию к действию.
«Критик»: Эта долина выглядит довольно стандартно. V(S) = 19.
«Субъект»: Варианты действий выглядят очень похожими. Думаю, я просто пойду по дорожке «C».

Далее она действует.

Получает вознаграждение +20! И записывает наблюдение.

Она снова повторяет процесс.
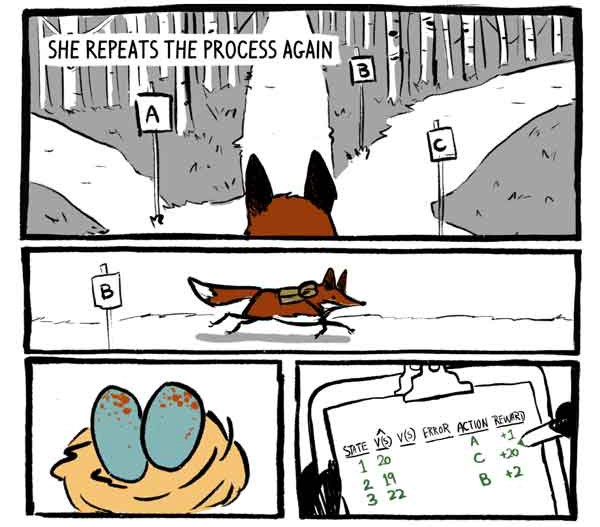
После сбора трех наблюдений, Клюковка останавливается подумать.
Другие семейства моделей ждут момента размышления до самого конца дня (Монте-Карло), в то время как другие размышляют после каждого шага (one-steps).
Прежде чем она сможет настроить своего внутреннего критика, Клюковке необходимо рассчитать, сколько очков она фактически получит в каждом данном состоянии.
Но сначала!
Давайте рассмотрим, как двоюродный брат Клюковки, Лис Монте-Карло, вычислит истинное значение каждого состояния.
Модели Монте-Карло не отражают свой опыт до конца игры, и поскольку значение последнего состояния равно нулю, найти истинное значение данного предыдущего состояния очень просто, как сумму вознаграждений, полученных после этого момента.

На самом деле, это просто образец V(S) с высокой дисперсией. Агент мог легко следовать по другой траектории из того же состояния, получая, таким образом, другое совокупное вознаграждение.
Но Клюковка идет, останавливается и размышляет много раз, пока день не подойдет к концу. Она хочет знать, как много очков она действительно получит от каждого состояния до конца игры, потому что до конца игры осталось несколько часов.
Вот где она делает что-то действительно умное — лиса Клюковка оценивает, сколько очков она получит за последнее состояние в этом наборе. К счастью, у нее есть правильная оценка состояния — ее критик.
С этой оценкой, Клюковка может рассчитывать «правильные» значения предшествующих состояний именно так, как делает лис Монте-Карло.
Лис Монте-Карло оценивает целевые метки, делая развертывание траектории и добавляя вознаграждения вперед от каждого состояния. A2C обрезает эту траекторию и заменяет ее оценкой своего критика. Эта начальная загрузка снижает дисперсию оценки и позволяет A2C работать непрерывно, хоть и за счет внесения небольшого смещения.

Вознаграждения часто снижаются для отражения того факта, что вознаграждение сейчас лучше, чем в будущем. Для простоты, Клюковка не снижает свои вознаграждения.

Теперь Клюковка может проходить по каждой строке данных и сравнивать ее оценки значений состояний со своими действительными значениями. Она использует разность между этими числами для оттачивания навыков предсказания. Каждые три шага на протяжении дня, Клюковка собирает ценный опыт, над которым стоит задуматься.
«Я плохо оценила состояния 1 и 2. Что я сделала неправильно? Ага! В следующий раз, когда увижу перья вроде этих, я увеличу V(S).
Это может показаться сумасшедшим, что Клюковка способна использовать свою оценку V(S) как основу, чтобы сравнивать ее с другими прогнозами. Но животные (включая нас) делают это все время! Если вы чувствуете, что дела идут хорошо, не нужно переобучать действия, которые привели вас в это состояние.

Обрезая наши рассчитанные выходы и заменяя их оценкой с начальной загрузкой, мы заменили большую дисперсию Монте-Карло на небольшое смещение. Модели RL обычно страдают от высокой дисперсии (представляя все возможные траектории), и такая замена обычно стоит того.
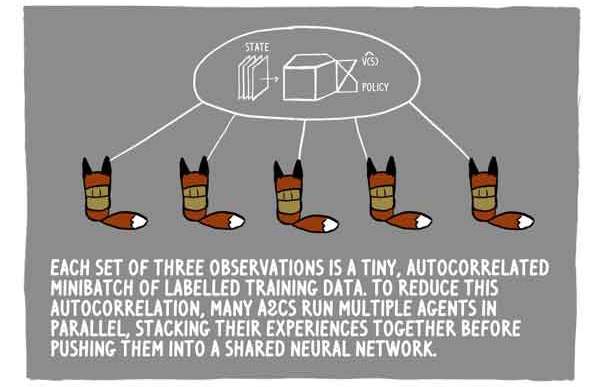
Клюковка повторяет этот процесс весь день, собирая по три наблюдения состояние-действие-вознаграждение и размышляя над ними.

Каждый набор трех наблюдений — это маленькая, автокоррелированная серия размеченных тренировочных данных. Для уменьшения этой автокорреляции, много A2C обучают множество агентов параллельно, складывая их опыт вместе перед его отсылкой в общую нейронную сеть.
День, наконец, подходит к концу. Осталось всего два шага.
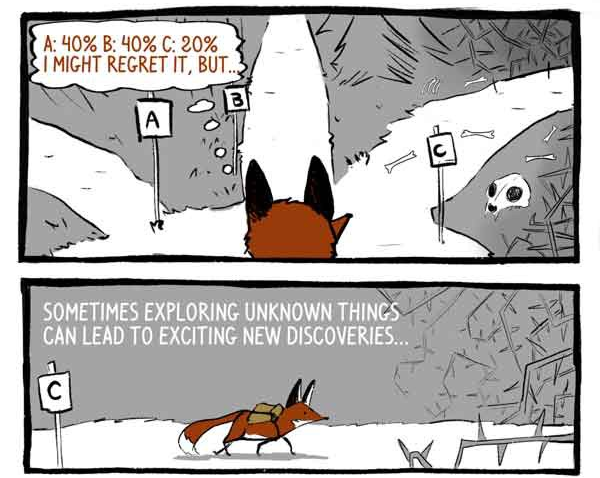
Как мы сказали ранее, рекомендации действий Клюковки выражены в процентных уверенностях о ее возможностях. Вместо того, чтобы просто выбрать самый надежный выбор, Клюковка выбирает из этого распределения действий. Это гарантирует, что она не всегда соглашается на безопасные, но потенциально посредственные действия.
Я могла бы пожалеть об этом, но… Порой, исследуя неизвестные вещи, можно прийти к захватывающим новым открытиям...
Для дальнейшего поощрения исследования значение, называемое энтропией, вычитается из функции потерь. Энтропия значит „размах“ распределения действий.
— Похоже, что игра окупилась!

Или нет?
Иногда агент оказывается в состоянии, когда все действия приводят к отрицательным исходам. A2C, тем не менее, отлично справляются с плохими ситуациями.


Когда солнце зашло, Клюковка размышляла над последним набором решений.

Мы говорили о том, как Клюковка настраивает своего внутреннего критика. Но как она подстраивает своего внутреннего „субъекта“? Как она учится делать такие изысканные выборы?
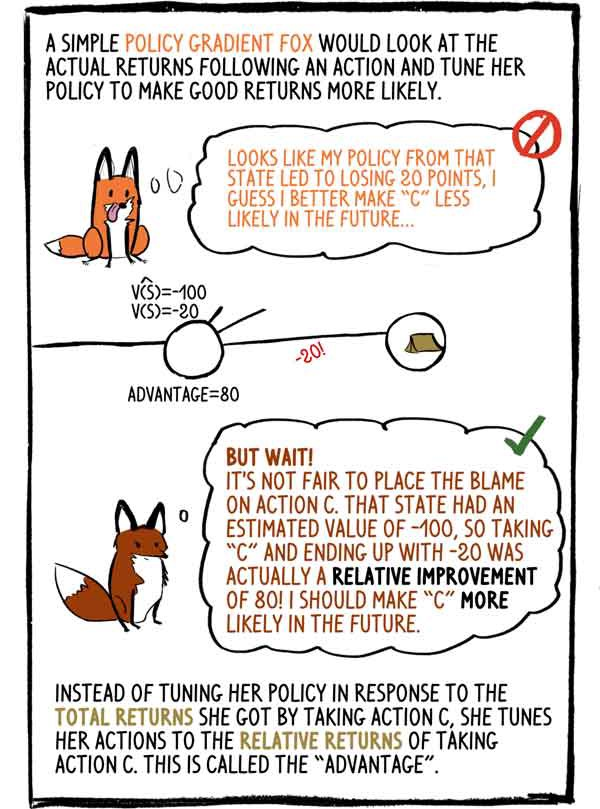
Простодушная лиса Gradient-Policy смотрела бы на фактические доходы после действия и настраивала бы свою политику, чтобы сделать хорошие доходы более вероятными:- Похоже, моя политика в этом состоянии привела к потере 20 баллов, я думаю, что в будущем лучше сделать „C“ менее вероятным.
— Но подождите! Несправедливо возлагать вину на действие „C“. Это состояние имело оценочную величину -100, поэтому выбор „C“ и его окончание с -20 на самом деле было относительным улучшением на 80! Я должна сделать „C“ более вероятным в будущем.
Вместо того, чтобы настраивать свою политику в ответ на общий доход, который она получила, выбрав действие C, она настраивает свое действие на относительные доходы от действия C. Это называется «преимуществом».
То, что мы назвали преимуществом, это просто ошибка. Как преимущество, Клюковка использует его, чтобы сделать действия, которые были на удивление хорошими, более вероятными. Как ошибку, она использует ту же величину, чтобы подтолкнуть своего внутреннего критика для улучшения оценки значения состояния.
Субъект использует преимущество:
— »Вау, это сработало лучше, чем я думал, действие C, должно быть, хорошая идея."
Критик использует ошибку:
«Но почему я был удивлен? Вероятно, я не должен был оценивать это состояние так негативно.»
Теперь мы можем показать, как рассчитываются общие потери — эту функцию мы минимизируем для улучшения нашей модели.
«Полная потеря = потеря действия + потеря стоимости — энтропия»
Обратите внимание, для вычисления градиентов трех качественно разных типов мы берем значения «через одно». Это эффективно, но может сделать схождение более трудным.

Как и все животные, по мере взросления Клюковка будет оттачивать свою способность прогнозировать значения состояний, приобретать все большую уверенность в своих действиях и реже удивляться наградам.
Агенты RL, такие как Клюковка, не только генерируют все необходимые данные, просто взаимодействуя с окружающей средой, но и сами оценивают целевые метки. Все так, модели RL обновляют предыдущие оценки, чтобы лучше соответствовать новым и улучшенным оценкам.
Как об этом говорит доктор Дэвид Сильвер, глава группы RL в Google Deepmind: AI = DL + RL. Когда такой агент, как Клюковка, может настравивать свой собственный интеллект, возможности безграничны ...


