Привет. Меня зовут Андрей, я студент-магистрант в одном из технических ВУЗов Москвы и по совместительству очень скромный начинающий предприниматель и разработчик. В этой статье я решил поделиться своим опытом перехода от PHP (который когда-то мне нравился из-за своей простоты, но со временем стал ненавидим мною — под катом объясняю почему) к NodeJS. Здесь могут приводиться очень банальные и кажущиеся элементарными задачи, которые, тем не менее, лично мне было любопытно решать в ходе моего знакомства с NodeJS и особенностями серверной разработки на JavaScript. Я попытаюсь объяснить и наглядно доказать, что PHP уже окончательно ушёл в закат и уступил своё место NodeJS. Возможно, кому-то даже будет полезно узнать некоторые особенности рендеринга HTML-страниц в Node, который изначально не приспособлен к этому от слова совсем.
Введение
Во время написания движка я использовал простейшие техники. Никаких менеджеров пакетов, никакого роутинга. Только хардкор — папки, чьё название соответствовало запрашиваемому маршруту, да index.php в каждой из них, настроенный PHP-FPM для поддержания пула процессов. Позднее возникла необходимость использовать Composer и Laravel, что и стало последней каплей для меня. Перед тем, как перейти к рассказу о том, зачем же я вообще взялся переписывать всё с PHP на NodeJS, расскажу немного о предыстории.
Менеджер пакетов
В конце 2018 года довелось работать с одним проектом, написанным на Laravel. Нужно было исправить несколько багов, внести правки в существующий функционал, добавить несколько новых кнопок в интерфейсе. Начался процесс с установки менеджера пакетов и зависимостей. В PHP для этого используется Composer. Тогда заказчик предоставил сервер с 1 ядром и 512 мегабайтами оперативной памяти и это был мой первый опыт работы с Composer. При установке зависимостей на виртуальном приватном сервере с 512 мегабайтами памяти процесс аварийно завершился из-за нехватки памяти.

Для меня, как человека знакомого с Linux и имеющего опыт работы с Debian и Ubuntu решение такой проблемы было очевидно — установка SWAP-файла (файл подкачки — для тех, кто не знаком с администрированием в Linux). Начинающий неопытный разработчик, установивший свой первый Laravel-дистрибутив на Digital Ocean, например, просто пойдёт в панель управления и будет поднимать тариф до тех пор, пока установка зависимостей не перестанет завершаться с ошибкой сегментации памяти. А как там обстоят дела с NodeJS?
А в NodeJS есть свой собственный менеджер пакетов — npm. Он значительно проще в использовании, компактнее, может работать даже в среде с минимальным количеством оперативной памяти. В целом, ругать Composer на фоне NPM особо не за что, однако в случае возникновения каких-то ошибок при установке пакетов Composer вылетит с ошибкой как обычное PHP-приложение и вы никогда не узнаете, какая часть пакета успела установиться и установилась ли она в конце-концов. И вообще, для администратора Linux вылетевшая установка = флэшбеки в Rescue Mode и dpkg --configure -a. К тому времени, как меня настигли такие "сюрпризы", я уже недолюбливал PHP, но это уже были последние гвозди в крышку гроба моей некогда великой любви к PHP.
Long-term support и проблема версионирования
Помните, какой ажиотаж и изумление вызвал PHP7, когда разработчики впервые презентовали его? Увеличение производительности более чем в 2 раза, а в некоторых компонентах до 5 раз! А помните, когда появился на свет PHP седьмой версии? А как быстро-то заработал WordPress! Это был декабрь 2015 года. А знали ли вы, что PHP 7.0 уже сейчас считается устаревшей версией PHP и крайне рекомендуется обновить его… Нет, не до версии 7.1, а до версии 7.2. По утверждениям разработчиков, версия 7.1 уже лишена активной поддержки и получает лишь обновления безопасности. А через 8 месяцев прекратится и это. Прекратится, вместе с активной поддержкой и версии 7.2. Выходит, что к концу текущего года у PHP останется лишь одна актуальная версия — 7.3.

На самом деле, это не было бы придиркой и я бы не отнёс это к причинам моего ухода от PHP, если бы написанные мной проекты на PHP 7.0.* уже сейчас не вызывали deprecation warning при открытии. Вернёмся к тому проекту, где вылетала установка зависимостей. Это был проект, написанный в 2015 году на Laravel 4 с PHP 5.6. Казалось, прошло же всего 4 года, ан-нет — куча deprecation-предупреждений, устаревшие модули, невозможность нормально обновиться до Laravel 5 из-за кучи корневых обновлений движка.
И это касается не только самого Laravel. Попробуйте взять любое приложение на PHP, написанное во времена активной поддержки первых версий PHP 7.0 и будьте готовы потратить свой вечер на поиск решений проблем, возникших в устаревших модулях PHP. Напоследок интересный факт: поддержка PHP 7.0 была прекращена раньше, чем поддержка PHP 5.6. На секундочку.
А как дела с этим обстоят у NodeJS? Я бы не сказал, что здесь всё значительно лучше и что сроки поддержки у NodeJS кардинально отличаются от PHP. Нет, здесь всё примерно так же — каждая LTS-версия поддерживается в течение 3 лет. Вот только у NodeJS немного больше этих самых актуальных версий.
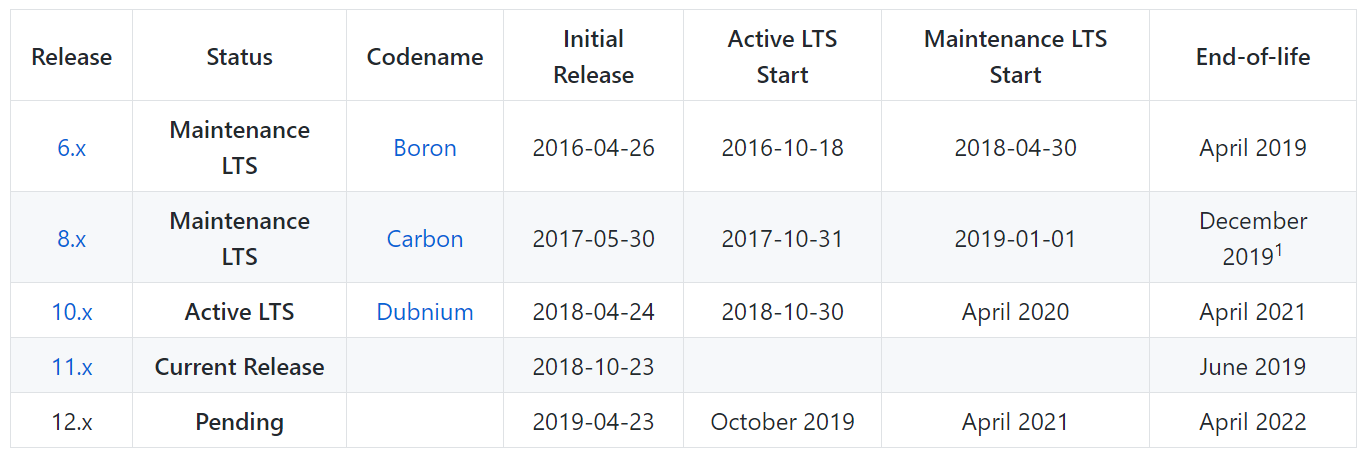
Если у вас возникнет необходимость развернуть приложение, написанное в 2016 году, то будьте уверены, что у вас не будет с этим совершенно никаких проблем. Кстати говоря, версия 6.* перестанет поддерживаться только в апреле этого года. А впереди ещё 8, 10, 11 и готовящаяся 12.
О трудностях и сюрпризах при переходе на NodeJS
Начну, пожалуй, с самого волнующего меня вопроса о том, как же всё-таки рендерить HTML-страницы в NodeJS. Но давайте для начала вспомним, как это делается в PHP:
- Встраивать HTML напрямую в PHP-код. Так делают все новички, кто ещё не добрался до MVC. И так сделано в WordPress, что категорически ужасающе.
- Использовать MVC, что как бы должно упростить взаимодействие разработчика и обеспечить какое-то разбиение проекта на части, но на деле этот подход лишь усложняет всё в разы.
- Использовать шаблонизатор. Наиболее удобный вариант, но не в PHP. Просто посмотрите синтаксис, предлагаемый в Twig или Blade с фигурными скобками и процентами.
Я являюсь ярым противником совмещения или слияния нескольких технологий воедино. HTML должен существовать отдельно, стили для него — отдельно, JavaScript-отдельно (в React это вообще выглядит чудовищно — HTML и JavaScript вперемешку). Именно поэтому идеальный вариант для разработчиков с предпочтениями как у меня — шаблонизатор. Искать его для веб-приложения на NodeJS долго не пришлось и я сделал выбор в пользу Jade (PugJS). Просто оцените простоту его синтаксиса:
div.row.links div.col-lg-3.col-md-3.col-sm-4 h4.footer-heading Флот.ру div.copyright div.copy-text 2017 - #{current_year} Флот.ру div.contact-link span Контакты: a(href='mailto:hello@flaut.ru') hello@flaut.ru
Здесь всё достаточно просто: написал шаблон, загрузил его в приложение, скомпилировал один раз и далее используешь в любом удобном месте в любое удобное время. По моим ощущениям, производительность PugJS примерно в 2 раза лучше, чем рендеринг с помощью внедрения HTML в PHP-код. Если раньше в PHP статическая страница генерировалась сервером примерно за 200-250 миллисекунд, то теперь это время составляет примерно 90-120 миллисекунд (речь идёт не о самом рендеринге в PugJS, а о времени, затраченном от запроса страницы до ответа сервера клиенту с готовым HTML). Так выглядит загрузка и компиляция шаблонов и их компонентов на стадии запуска приложения:
const pugs = {} fs.readdirSync(__dirname + '/templates/').forEach(file => { if(file.endsWith('.pug')) { try { var filepath = __dirname + '/templates/' + file pugs[file.split('.pug')[0]] = pug.compile(fs.readFileSync(filepath, 'utf-8'), { filename: filepath }) } catch(e) { console.error(e) } } }) // и далее рендеринг уже скомпилированного шаблона return pugs.tickets({ ...config })
Выглядит невероятно просто, но с Jade возникла небольшая сложность на этапе работы с уже скомпилированным HTML. Дело в том, что для внедрения скриптов на странице используется асинхронная функция, которая забирает все .js файлы из директории и добавляет к каждому из них дату их последнего изменения. Функция имеет следующий вид:
for(let i = 0; i < files.length; i++) { let period = files[i].lastIndexOf('.') // get last dot in filename let filename = files[i].substring(0, period) let extension = files[i].substring(period + 1) if(extension === 'js') { let fullFilename = filename + '.' + extension if(env === 'production') { scripts.push({ path: paths.production.web + fullFilename, mtime: await getMtime(paths.production.code + fullFilename)}) } else { if(files[i].startsWith('common') || files[i].startsWith('search')) { scripts.push({ path: paths.developer.scripts.web + fullFilename, mtime: await getMtime(paths.developer.scripts.code + fullFilename)}) } else { scripts.push({ path: paths.developer.vendor.web + fullFilename, mtime: await getMtime(paths.developer.vendor.code + fullFilename)}) } } } }
На выходе получаем массив объектов с двумя свойствами — путь к файлу и время его последнего редактирования в timestamp (для обновления клиентского кэша). Проблема в том, что ещё на этапе сбора файлов скриптов из директории они все загружаются в память строго по алфавиту (так они расположены в самой директории, а сбор файлов в ней осуществляется сверху вниз — от первого до последнего). Это приводило к тому, что сначала загружался файл app.js, а уже после него шёл файл core.min.js с полифиллами, и в самом конце — vendor.min.js. Решилась эта проблема достаточно просто — очень банальной сортировкой:
scripts.sort((a, b) => { if(a.path.includes('core.min.js')) { return -1 } else if(a.path.includes('vendor.min.js')) { return 0 } return 1 })
В PHP же это всё имело монструозный вид в виде заранее записанных в строку путей к JS-файлам. Просто, но непрактично.
NodeJS держит своё приложение в оперативной памяти
Это огромный плюс. У меня всё устроено так, что на сервере параллельно и независимо друг от друга существуют два отдельных сайта — версия для разработчика и production-версия. Представим, что я сделал какие-то изменения в PHP-файлы на сайте для разработки и мне нужно выкатить эти изменения на production. Для этого нужно останавливать сервер или ставить заглушку "извините, тех. работы" и в это время копировать файлы по отдельности из папки developer в папку production. Это вызывает какой-никакой простой и может вылиться в потерю конверсий. Преимущество in-memory application в NodeJS заключается для меня в том, что все изменения в файлы движка будут внесены только после его перезагрузки. Это очень удобно, поскольку можно скопировать все необходимые файлы с изменениями и только после этого перезагрузить сервер. Процесс занимает не более 1-2 секунд и не вызовет даунтайма.
Такой же подход используется в nginx, например. Вы сначала редактируете конфигурацию, проверяете её при помощи nginx -t и только потом вносите изменения с service nginx reload
Кластеризация NodeJS-приложения
В NodeJS есть очень удобный инструмент — менеджер процессов pm2. Как мы обычно запускаем приложения в Node? Заходим в консоль и пишем node index.js. Как только мы закрываем консоль — приложение закрывается. По крайней мере, так происходит на сервере с Ubuntu. Чтобы избежать этого и держать приложение запущенным всегда, достаточно добавить его в pm2 простой командой pm2 start index.js --name production. Но это ещё не всё. Инструмент позволяет проводить мониторинг (pm2 monit) и кластеризацию приложения.
Давайте вспомним о том, как организованы процессы в PHP. Допустим, у нас есть nginx, обслуживающий http-запросы и нам нужно передать запрос на PHP. Можно либо сделать это напрямую и тогда при каждом запросе будет спавниться новый процесс PHP, а при его завершении — убиваться. А можно использовать fastcgi-сервер. Думаю, все знают что это такое и нет необходимости вдаваться в подробности, но на всякий случай уточню, что в качестве fastcgi чаще всего используется PHP-FPM и его задача — заспавнить множество процессов PHP, которые в любой момент готовы принять и обработать новый запрос. В чём недостаток такого подхода?
Во-первых, в том, что вы никогда не знаете, сколько памяти будет потреблять ваше приложение. Во-вторых, вы всегда будете ограничены в максимальном количестве процессов, а соответственно, при резком скачке трафика ваше PHP-приложение либо использует всю доступную память и упадёт, либо упрётся в допустимый предел процессов и начнёт убивать старые. Это можно предотвратить, установив не-помню-какой-параметр в конфигурационном файле PHP-FPM в dynamic и тогда будет спавниться столько процессов, сколько необходимо в данное время. Но снова-таки, элементарная DDoS-атака выест всю оперативную память и положит ваш сервер. Или, например, багнутый скрипт съест всю оперативную память и сервер зависнет на какое-то время (были прецеденты в процессе разработки).
Кардинальное отличие в NodeJS заключается в том, что приложение не может потребить более чем 1,5 гигабайта оперативной памяти. Нет никаких ограничений по процессам, есть только ограничение по памяти. Это стимулирует писать максимально легковесные программы. К тому же очень просто рассчитать количество кластеров, которые мы можем себе позволить в зависимости от имеющегося ресурса CPU. Рекомендуется на каждое ядро "вешать" не более одного кластера (ровно как и в nginx — не более одного воркера на одно ядро CPU).

Преимущество такого подхода ещё и в том, что PM2 перезагружает все кластеры по очереди. Возвращаясь к предыдущему абзацу, в котором говорилось о 1-2 секундном даунтайме при перезагрузке. В Cluster-Mode при перезагрузке сервера ваше приложение не испытает ни миллисекунды даунтайма.
NodeJS — это хороший швейцарский нож
Ныне сложилась такая ситуация, когда PHP выступает в качестве языка для написания сайтов, а Python выступает в качестве инструмента для краулинга этих самых сайтов. NodeJS — это 2 в 1, с одной стороны вилка, с другой — ложка. Вы можете писать быстрые и производительные приложения и веб-краулеры на одном сервере в пределах одного приложения. Звучит заманчиво. Но как это может быть реализовано, спросите вы? Сама компания Google выкатила официальное API с Chromium — Puppeteer. Вы можете запускать Headless Chrome (браузер без интерфейса пользователя — "безголовый" Chrome) и получить максимально широкий доступ к API-браузера для обхода страниц. Максимально просто и доступно о работе Puppeteer.
Например, в нашей группе ВКонтакте происходит регулярный постинг скидок и специальных предложений на различные направления из городов СНГ. Мы генерируем изображения для постов в автоматическом режиме, а чтобы они были ещё и красивыми — нам нужны красивые картинки. Я не любитель подвязываться на различные API и заводить на десятках сайтов аккаунты, поэтому я написал простое приложение, имитирующее обычного пользователя с браузером Google Chrome, который ходит по сайту со стоковыми картинками и забирает случайным образом изображение, найденное по ключевому слову. Раньше для этого я использовал Python и BeautifulSoup, но теперь в этом отпала необходимость. А самая главная особенность и преимущество Puppeteer заключается в том, что вы можете с лёгкостью краулить даже SPA-сайты, ведь вы имеете в своём распоряжении полноценный браузер, понимающий и исполняющий JavaScript-код на сайтах. Это до боли просто:
const browser = await puppeteer.launch({headless: true, args:['--no-sandbox']}) const page = (await browser.pages())[0] await page.goto(`https://pixabay.com/photos/search/${imageKeyword}/?cat=buildings&orientation=horizontal`, { waitUntil: 'networkidle0' })
Вот так в 3 строчки кода мы запустили браузер и открыли страницу сайта со стоковыми изображением. Теперь мы можем выбрать случайный блок с изображением на странице и добавить к нему класс, по которому в дальнейшем сможем точно так же обратиться и уже перейти на страницу непосредственно с самим изображением для его дальнейшей загрузки:
var imagesLength = await page.evaluate(() => { var photos = document.querySelectorAll('.search_results > .item') if(photos.length > 0) { photos[Math.floor(Math.random() * photos.length)].className += ' --anomaly_selected' } return photos.length })
Вспомните, сколько бы потребовалось кода, чтобы написать подобное на PhantomJS (который, кстати, закрылся и вступил в тесное сотрудничество с командой разработки Puppeteer). Разве наличие такого чудесного инструмента может остановить кого-нибудь от перехода к NodeJS?
В NodeJS заложена асинхронность на фундаментальном уровне
Это можно считать огромным преимуществом NodeJS и JavaScript, особенно с приходом async/await в ES2017. В отличии от PHP, где любой вызов выполняется синхронно. Приведу простой пример. Раньше у нас в поисковике страницы генерировались на сервере, но кое-что нужно было выводить на страницу уже в клиенте с помощью JavaScript, а на тот момент Яндекс ещё не умел в JavaScript на сайтах и специально для него пришлось реализовывать механизм снапшотов (снимков страниц) при помощи Prerender. Снапшоты хранились у нас на сервере и выдавались роботу при запросе. Дилемма заключалась в том, что эти снимки генерировались в течение 3-5 секунд, что совершенно недопустимо и может повлиять на ранжирование сайта в поисковой выдаче. Для решения этой задачи был придуман простой алгоритм: когда робот запрашивает какую-то страницу, снимок которой у нас уже есть, то мы просто отдаём ему уже имеющийся у нас снимок, после чего "в фоне" выполняем операцию по созданию нового снимка и заменяем им уже имеющийся. Как это было делано в PHP:
exec('/usr/bin/php ' . __DIR__ . '/snapshot.php -a ' . $affiliation_type . ' -l ' . urlencode($full_uri) . ' > /dev/null 2>/dev/null &');
Никогда так не делайте.
В NodeJS этого можно добиться вызовом асинхронной функции:
async function saveSnapshot() { getSnapshot().then((res) => { db.saveSnapshot().then((status) => { if(status.err) console.error(err) }) }) } /** * И вызываем функцию без await * Т.е. не будем дожидаться resolve() от промиса */ saveSnapshot()
Вкратце, вы не пытаетесь обойти синхронность, а сами определяете, когда использовать синхронное выполнение кода, а когда асинхронное. И это действительно удобно. Особенно когда вы узнаете о возможностях Promise.all()
Сам движок поисковика авиабилетов устроен таким образом, что он отсылает запрос на второй сервер, собирающий и агрегирующий данные, и затем обращается к нему за уже готовыми к выдаче данными. Для привлечения трафика из органики используются страницы направлений.
Например, по запросу "Авиабилеты Москва Санкт-Петербург" будет выдана страница с адресом /tickets/moscow/saint-petersburg/, а на ней нужны данные:
- Цены авиабилетов по этому направлению на текущий месяц
- Цены авиабилетов по этому направлению на год вперёд (средняя цена по каждому месяцу для следующих 12 месяцев)
- Расписание авиарейсов по этому направлению
- Популярные направления из города отправки — из Москвы (для перелинковки)
- Популярные направления из города прибытия — из Санкт-Петербурга (для перелинковки)
В PHP все эти запросы выполнялись синхронно — один за другим. Среднее время ответа API по одному запросу — 150-200 миллисекунд. Умножаем 200 на 5 и получаем в среднем секунду только на выполнение запросов к серверу с данными. В NodeJS есть замечательная функция Promise.all, которая выполняет все запросы параллельно, но записывает результат поочерёдно. Например, так выглядел бы код выполнения всех пяти выше описанных запросов:
var [montlyPrices, yearlyPrices, flightsSchedule, originPopulars, destPopulars] = await Promise.all([ getMontlyPrices(), getYearlyPrices(), getFlightSchedule(), getOriginPopulars(), getDestPopulars() ])
И получаем все данные за 200-300 миллисекунд, сократив время генерации данных для страницы с 1-1,5 секунд до ~500 миллисекунд.
Заключение
Переход с PHP на NodeJS помог мне ближе познакомиться с асинхронным JavaScript, научиться работе с промисами и async/await. После того, как движок был переписан, скорость загрузки страниц была оптимизирована и отличалась разительно от результатов, которые показывал движок на PHP. В этой статье можно было бы ещё рассказать о том, насколько просто используются модули для работы с кэшем (Redis) и pg-promise (PostgreSQL) в NodeJS и устроить сравнение их с Memcached и php-pgsql, но эта статья итак получилась достаточно объёмной. А зная мой "талант" к писательству, она получилась ещё и плохо структурированной. Цель написания этой статьи — привлечь внимание разработчиков, которые до сих пор работают с PHP и не знают о прелестях NodeJS и разработки веб-ориентированных приложений на нём на примере реально существующего проекта, который когда-то был написан на PHP, но из-за предпочтений своего владельца ушёл на другую платформу.
Надеюсь, что мне удалось донести мои мысли и более-менее структурировано изложить их в этом материале. По крайней мере, я старался :)
Пишите любые комментарии — доброжелательные или гневные. Буду отвечать на любой конструктив.

