В прошлый раз мы поговорили о согласованности данных, посмотрели на отличие между разными уровнями изоляции транзакций глазами пользователя и разобрались, почему это важно знать. Теперь мы начинаем изучать, как в PostgreSQL реализованы изоляция на основе снимков и механизм многоверсионности.
В этой статье мы посмотрим на то, как данные физически располагаются в файлах и страницах. Это уводит нас в сторону от темы изоляции, но такое отступление необходимо для понимания дальнейшего материала. Нам потребуется разобраться, как устроено хранение данных на низком уровне.
Если заглянуть внутрь таблиц и индексов, то окажется, что они устроены схожим образом. И то, и другое — объекты базы, которые содержат некоторые данные, состоящие из строк.
То, что таблица состоит из строк, не вызывает сомнений; для индекса это менее очевидно. Тем не менее, представьте B-дерево: оно состоит из узлов, которые содержат индексированные значения и ссылки на другие узлы или на табличные строки. Вот эти узлы и можно считать индексными строками — фактически, так оно и есть.
На самом деле есть еще некоторое количество объектов, устроенных похожим образом: последовательности (по сути однострочные таблицы), материализованные представления (по сути таблицы, помнящие запрос). А еще есть обычные представления, которые сами по себе не хранят данные, но во всех остальных смыслах похожи на таблицы.
Все эти объекты в PostgreSQL называются общим словом отношение (по-английски relation). Слово крайне неудачное, потому что это термин из реляционной теории. Можно провести параллель между отношением и таблицей (представлением), но уж никак не между отношением и индексом. Но так уж сложилось: дают о себе знать академические корни PostgreSQL. Мне думается, что сначала так называли именно таблицы и представления, а остальное наросло со временем.
Дальше мы для простоты будем говорить только о таблицах и индексах, но и остальные отношения устроены точно так же.
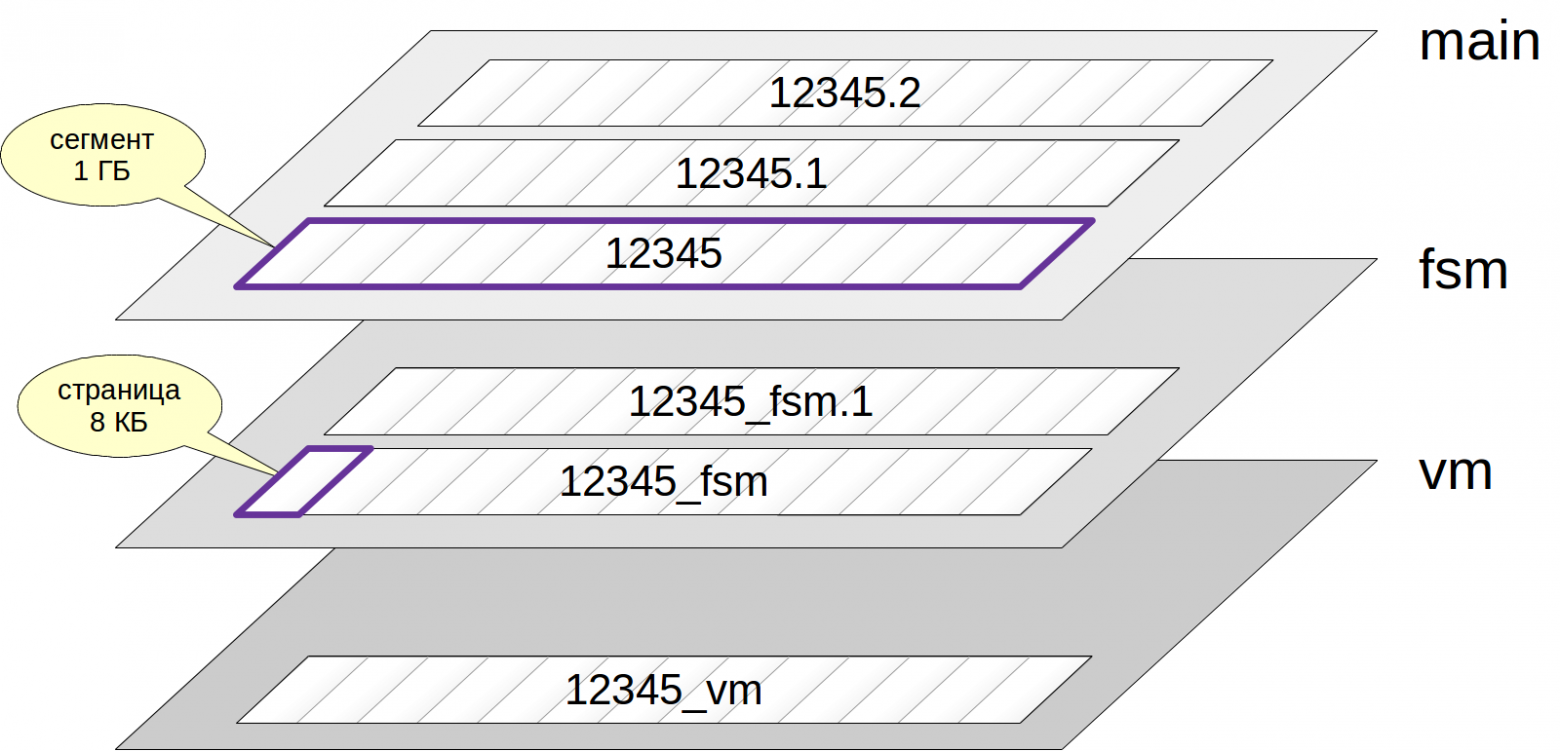
Обычно каждому отношению соответствует несколько слоев (forks). Слои бывают нескольких типов и каждый из них содержит определенный вид данных.
Если слой есть, то вначале он представлен одним-единственным файлом. Имя файла состоит из числового идентификатора, к которому может быть добавлено окончание, соответствующее имени слоя.
Файл постепенно растет и, когда его размер доходит до 1 ГБ, создается следующий файл этого же слоя (такие файлы иногда называют сегментами). Порядковый номер сегмента добавляется в конец имени файла.
Ограничение размера файла в 1 ГБ возникло исторически для поддержки различных файловых систем, некоторые из которых не умеют работать с файлами большого размера. Ограничение можно изменить при сборке PostgreSQL (
Таким образом, одному отношению на диске может соответствовать несколько файлов. Например, для небольшой таблицы их будет 3 штуки.
Все файлы объектов, принадлежащих одному табличному пространству и одной БД, будут помещены в один каталог. Это необходимо учитывать, потому что файловые системы обычно не очень хорошо работают с большим количеством файлов в каталоге.
Сразу заметим, что файлы, в свою очередь, разделены на страницы (или блоки), обычно по 8 КБ. О внутренней структуре страниц поговорим чуть ниже.
Посмотрим теперь на типы слоев.
Основной слой — это собственно данные: те самые табличные или индексные строки. Основной слой существует для любых отношений (кроме представлений, которые не содержат данных).
Имена файлов основного слоя состоят только из числового идентификатора. Вот для примера путь к файлу таблицы, которую мы создавали в прошлый раз:
Откуда берутся эти идентификаторы? Каталог base соответствует табличному пространству pg_default, следующий подкаталог — базе данных, и уже в нем находится интересующий нас файл:
Путь относительный, он отсчитывается от каталога данных (PGDATA). Более того, практически все пути в PostgreSQL отсчитываются от PGDATA. Благодаря этому можно безболезненно переносить PGDATA на другое место — его ничего не держит (разве что может потребоваться настроить путь до библиотек в LD_LIBRARY_PATH).
Дальше смотрим в файловой системе:
Слой инициализации существует только для нежурналируемых таблиц (созданных с указанием UNLOGGED) и их индексов. Такие объекты ничем не отличаются от обычных, кроме того, что действия с ними не записываются в журнал предзаписи. За счет этого работа с ними происходит быстрее, но в случае сбоя невозможно восстановить данные в согласованном состоянии. Поэтому при восстановлении PostgreSQL просто удаляет все слои таких объектов и записывает слой инициализации на место основного слоя. В результате получается «пустышка». Про журналирование мы будем говорить подробно, но в другом цикле.
Таблица accounts журналируемая, поэтому для нее слоя инициализации нет. Но для эксперимента можно отключить журналирование:
Возможность включать и выключать журналирование на лету, как видно из примера, сопряжена с перезаписью данных в файлы с другими именами.
Слой инициализации имеет такое же имя, как и основной слой, но с суффиксом "_init":
Карта свободного пространства (free space map) — слой, в котором отмечено наличие пустого места внутри страниц. Это место постоянно меняется: при добавлении новых версий строк уменьшается, при очистке — увеличивается. Карта свободного пространства используется при вставке новых версий строк, чтобы быстро найти подходящую страницу, на которую поместятся добавляемые данные.
Карта свободного пространства имеет суффикс "_fsm". Но файл появляется не сразу, а только при необходимости. Самый простой способ добиться этого — выполнить очистку таблицы (почему — поговорим в свое время):
Карта видимости (visibility map) — слой, в котором одним битом отмечены страницы, которые содержат только актуальные версии строк. Грубо говоря, это означает, что когда транзакция пытается прочитать строку из такой страницы, строку можно показывать, не проверяя ее видимость. Мы будем подробно рассматривать, как это происходит, в следующих статьях.
Как мы уже говорили, файлы логически поделены на страницы.
Обычно страница имеет размер 8 КБ. Размер в некоторых пределах можно поменять (16 КБ или 32 КБ), но только при сборке (
Независимо от того, к какому слою принадлежат файлы, они используются сервером примерно одинаково. Страницы сначала читаются в буферный кеш, где их могут читать и изменять процессы; затем при необходимости страницы вытесняются обратно на диск.
Каждая страница имеет внутреннюю разметку и в общем случае содержит следующие разделы:
Размер этих разделов легко узнать с помощью «исследовательского» расширения pageinspect:
Тут мы смотрим на заголовок самой первой (нулевой) страницы таблицы. Кроме размеров остальных областей заголовок содержит и другую информацию о странице, но она нас пока не интересует.
Внизу страницы расположена специальная область, в нашем случае пустая. Она используется только для индексов, и то не для всех. «Внизу» здесь соответствует картинке; возможно, корректнее было бы сказать «в старших адресах».
Следом за специальной областью располагаются версии строк — те самые данные, которые мы храним в таблице, плюс некоторая служебная информация.
Вверху страницы, сразу за заголовком, находится оглавление: массив указателей на имеющиеся в странице версии строк.
Между версиями строк и указателями может оставаться свободное место (которое и отмечено в карте свободного пространства). Заметим, что никакой фрагментации внутри страницы не бывает, все свободное место всегда представлено одним фрагментом.
Зачем нужны указатели на версии строк? Дело в том, что индексные строки должны как-то ссылаться на версии строк в таблице. Понятно, что ссылка должна содержать номер файла, номер страницы в файле и какое-то указание на версию строки. В качестве такого указания можно было бы использовать смещение относительно начала страницы, но это неудобно. Мы не смогли бы перемещать версию строки внутри страницы, потому что это сломало бы существующие ссылки. А это привело бы к фрагментации места внутри страниц и другим неприятным последствиям. Поэтому индекс ссылается на номер указателя, а указатель — на текущую позицию версии строки в странице. Получается косвенная адресация.
Каждый указатель занимает ровно 4 байта и содержит:
Формат данных на диске полностью совпадает с представлением данных в оперативной памяти. Страница читается в буферный кеш «как есть», без каких бы то ни было преобразований. Поэтому файлы данных с одной платформы оказываются несовместимыми с другими платформами.
Например, в архитектуре x86 принят порядок байтов от младших разрядов к старшим (little-endian), z/Architecture использует обратный порядок (big-endian), а в ARM порядок переключаемый.
Многие архитектуры предусматривают выравнивание данных по границам машинных слов. Например, на 32-битной системе x86 целые числа (тип integer, занимает 4 байта) будут выровнены по границе 4-байтных слов, как и числа с плавающей точкой двойной точности (тип double precision, 8 байт). А на 64-битной системе значения double будут выровнены по границе 8-байтных слов. Это еще одна причина несовместимости.
Из-за выравнивания размер табличной строки зависит от порядка расположения полей. Обычно этот эффект не сильно заметен, но в некоторых случаях он может привести к существенному увеличению размера. Например, если располагать поля типов char(1) и integer вперемешку, между ними, как правило, будет впустую пропадать 3 байта. Подробнее об этом можно посмотреть в презентации Николая Шаплова "Что у него внутри".
Про то, как изнутри устроены версии строк, мы будем подробно говорить в следующий раз. Пока для нас важно лишь то, что каждая версия должна помещаться целиком на одну страницу: в PostgreSQL не предусмотрено способа «продолжить» строку на следующей странице. Вместо этого используется технология, названная TOAST (The Oversized Attributes Storage Technique). Само имя подсказывает, что строка может нарезаться на тосты.
Если говорить серьезно, то TOAST подразумевает несколько стратегий. «Длинные» значения атрибутов можно отправить в отдельную служебную таблицу, предварительно нарезав на небольшие фрагменты-тосты. Другой вариант — сжать значение так, чтобы версия строки все-таки поместилась на обычную табличную страницу. А можно и то, и другое: сначала сжать, а уже потом нарезать и отправить.
Для каждой основной таблицы при необходимости создается отдельная, но одна для всех атрибутов, TOAST-таблица (и к ней специальный индекс). Необходимость определяется наличием в таблице потенциально длинных атрибутов. Например, если в таблице есть столбец типа numeric или text, TOAST-таблица будет сразу же создана, даже если длинные значения не будут использоваться.
Поскольку TOAST-таблица по сути обычная таблица, у нее есть все тот же набор слоев. А это еще в два раза увеличивает число файлов, которые «обслуживают» таблицу.
Изначально стратегии определяются типами данных столбцов. Посмотреть их можно командой
Названия стратегий имеют следующий смысл:
В общих чертах алгоритм выглядит следующим образом. PostgreSQL стремится к тому, чтобы на странице помещалось хотя бы 4 строки. Поэтому если размер строки превышает четвертую часть страницы с учетом заголовка (при обычной 8К-странице это 2040 байт), к части значений необходимо применить TOAST. Действуем в порядке, описанном ниже, и прекращаем, как только строка перестает превышать порог:
Иногда может оказаться полезным изменить стратегию для некоторых столбцов. Например, если заранее известно, что данные в столбце не сжимаются, можно установить для него стратегию external — это позволить сэкономить на бесполезных попытках сжатия. Это выполняется следующим образом:
Повторив запрос, получим:
TOAST-таблицы и индексы располагаются в отдельной схеме pg_toast и поэтому обычно не видны. Для временных таблиц используется схема pg_toast_temp_N аналогично обычной pg_temp_N.
Конечно, при желании никто не мешает подглядеть за внутренней механикой процесса. Скажем, в таблице accounts есть три потенциально длинных атрибута, поэтому TOASТ-таблица обязана быть. Вот она:
Логично, что для «тостов», на которые нарезается строка, применяется стратегия plain: TOAST второго уровня не существует.
Индекс PostgreSQL прячет более тщательно, но и его нетрудно найти:
Столбец client использует стратегию extended: значения в нем будут сжиматься. Проверим:
В TOAST-таблице ничего нет: повторяющиеся символы прекрасно сжимаются и после этого значение поместилось в обычной табличной странице.
А теперь пусть имя клиента состоит из случайных символов:
Такую последовательность сжать не получается, и она попадает в TOAST-таблицу:
Как видим, данные нарезаются на фрагменты по 2000 байт.
При обращении к «длинному» значению PostgreSQL автоматически, прозрачно для приложения, восстанавливает исходное значение и возвращает его клиенту.
Разумеется, и на сжатие с нарезкой, и на последующее восстановление тратится довольно много ресурсов. Поэтому хранить объемные данные в PostgreSQL — не лучшая идея, особенно если они активно используются и при этом для них не требуется транзакционная логика (как пример: отсканированные оригиналы бухгалтерских документов). Более выгодной альтернативой может оказаться хранение таких данных на файловой системе, а в СУБД — имен соответствующих файлов.
TOAST-таблица используется только при обращении к «длинному» значению. Кроме того, для toast-таблицы поддерживается своя версионность: если обновление данных не затрагивает «длинное» значение, новая версия строки будет ссылаться на то же самое значение в TOAST-таблице — это экономит место.
Отметим, что TOAST работает только для таблиц, но не для индексов. Это накладывает ограничение на размер индексируемых ключей.
В этой статье мы посмотрим на то, как данные физически располагаются в файлах и страницах. Это уводит нас в сторону от темы изоляции, но такое отступление необходимо для понимания дальнейшего материала. Нам потребуется разобраться, как устроено хранение данных на низком уровне.
Отношения (relations)
Если заглянуть внутрь таблиц и индексов, то окажется, что они устроены схожим образом. И то, и другое — объекты базы, которые содержат некоторые данные, состоящие из строк.
То, что таблица состоит из строк, не вызывает сомнений; для индекса это менее очевидно. Тем не менее, представьте B-дерево: оно состоит из узлов, которые содержат индексированные значения и ссылки на другие узлы или на табличные строки. Вот эти узлы и можно считать индексными строками — фактически, так оно и есть.
На самом деле есть еще некоторое количество объектов, устроенных похожим образом: последовательности (по сути однострочные таблицы), материализованные представления (по сути таблицы, помнящие запрос). А еще есть обычные представления, которые сами по себе не хранят данные, но во всех остальных смыслах похожи на таблицы.
Все эти объекты в PostgreSQL называются общим словом отношение (по-английски relation). Слово крайне неудачное, потому что это термин из реляционной теории. Можно провести параллель между отношением и таблицей (представлением), но уж никак не между отношением и индексом. Но так уж сложилось: дают о себе знать академические корни PostgreSQL. Мне думается, что сначала так называли именно таблицы и представления, а остальное наросло со временем.
Дальше мы для простоты будем говорить только о таблицах и индексах, но и остальные отношения устроены точно так же.
Слои (forks) и файлы
Обычно каждому отношению соответствует несколько слоев (forks). Слои бывают нескольких типов и каждый из них содержит определенный вид данных.
Если слой есть, то вначале он представлен одним-единственным файлом. Имя файла состоит из числового идентификатора, к которому может быть добавлено окончание, соответствующее имени слоя.
Файл постепенно растет и, когда его размер доходит до 1 ГБ, создается следующий файл этого же слоя (такие файлы иногда называют сегментами). Порядковый номер сегмента добавляется в конец имени файла.
Ограничение размера файла в 1 ГБ возникло исторически для поддержки различных файловых систем, некоторые из которых не умеют работать с файлами большого размера. Ограничение можно изменить при сборке PostgreSQL (
./configure --with-segsize).Таким образом, одному отношению на диске может соответствовать несколько файлов. Например, для небольшой таблицы их будет 3 штуки.
Все файлы объектов, принадлежащих одному табличному пространству и одной БД, будут помещены в один каталог. Это необходимо учитывать, потому что файловые системы обычно не очень хорошо работают с большим количеством файлов в каталоге.
Сразу заметим, что файлы, в свою очередь, разделены на страницы (или блоки), обычно по 8 КБ. О внутренней структуре страниц поговорим чуть ниже.
Посмотрим теперь на типы слоев.
Основной слой — это собственно данные: те самые табличные или индексные строки. Основной слой существует для любых отношений (кроме представлений, которые не содержат данных).
Имена файлов основного слоя состоят только из числового идентификатора. Вот для примера путь к файлу таблицы, которую мы создавали в прошлый раз:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
Откуда берутся эти идентификаторы? Каталог base соответствует табличному пространству pg_default, следующий подкаталог — базе данных, и уже в нем находится интересующий нас файл:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
Путь относительный, он отсчитывается от каталога данных (PGDATA). Более того, практически все пути в PostgreSQL отсчитываются от PGDATA. Благодаря этому можно безболезненно переносить PGDATA на другое место — его ничего не держит (разве что может потребоваться настроить путь до библиотек в LD_LIBRARY_PATH).
Дальше смотрим в файловой системе:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
Слой инициализации существует только для нежурналируемых таблиц (созданных с указанием UNLOGGED) и их индексов. Такие объекты ничем не отличаются от обычных, кроме того, что действия с ними не записываются в журнал предзаписи. За счет этого работа с ними происходит быстрее, но в случае сбоя невозможно восстановить данные в согласованном состоянии. Поэтому при восстановлении PostgreSQL просто удаляет все слои таких объектов и записывает слой инициализации на место основного слоя. В результате получается «пустышка». Про журналирование мы будем говорить подробно, но в другом цикле.
Таблица accounts журналируемая, поэтому для нее слоя инициализации нет. Но для эксперимента можно отключить журналирование:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
Возможность включать и выключать журналирование на лету, как видно из примера, сопряжена с перезаписью данных в файлы с другими именами.
Слой инициализации имеет такое же имя, как и основной слой, но с суффиксом "_init":
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
Карта свободного пространства (free space map) — слой, в котором отмечено наличие пустого места внутри страниц. Это место постоянно меняется: при добавлении новых версий строк уменьшается, при очистке — увеличивается. Карта свободного пространства используется при вставке новых версий строк, чтобы быстро найти подходящую страницу, на которую поместятся добавляемые данные.
Карта свободного пространства имеет суффикс "_fsm". Но файл появляется не сразу, а только при необходимости. Самый простой способ добиться этого — выполнить очистку таблицы (почему — поговорим в свое время):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
Карта видимости (visibility map) — слой, в котором одним битом отмечены страницы, которые содержат только актуальные версии строк. Грубо говоря, это означает, что когда транзакция пытается прочитать строку из такой страницы, строку можно показывать, не проверяя ее видимость. Мы будем подробно рассматривать, как это происходит, в следующих статьях.
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
Страницы
Как мы уже говорили, файлы логически поделены на страницы.
Обычно страница имеет размер 8 КБ. Размер в некоторых пределах можно поменять (16 КБ или 32 КБ), но только при сборке (
./configure --with-blocksize). Собранный и запущенный экземпляр может работать со страницами только одного размера.Независимо от того, к какому слою принадлежат файлы, они используются сервером примерно одинаково. Страницы сначала читаются в буферный кеш, где их могут читать и изменять процессы; затем при необходимости страницы вытесняются обратно на диск.
Каждая страница имеет внутреннюю разметку и в общем случае содержит следующие разделы:
0 +-----------------------------------+
| заголовок |
24 +-----------------------------------+
| массив указателей на версии строк |
lower +-----------------------------------+
| свободное пространство |
upper +-----------------------------------+
| версии строк |
special +-----------------------------------+
| специальная область |
pagesize +-----------------------------------+
Размер этих разделов легко узнать с помощью «исследовательского» расширения pageinspect:
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
Тут мы смотрим на заголовок самой первой (нулевой) страницы таблицы. Кроме размеров остальных областей заголовок содержит и другую информацию о странице, но она нас пока не интересует.
Внизу страницы расположена специальная область, в нашем случае пустая. Она используется только для индексов, и то не для всех. «Внизу» здесь соответствует картинке; возможно, корректнее было бы сказать «в старших адресах».
Следом за специальной областью располагаются версии строк — те самые данные, которые мы храним в таблице, плюс некоторая служебная информация.
Вверху страницы, сразу за заголовком, находится оглавление: массив указателей на имеющиеся в странице версии строк.
Между версиями строк и указателями может оставаться свободное место (которое и отмечено в карте свободного пространства). Заметим, что никакой фрагментации внутри страницы не бывает, все свободное место всегда представлено одним фрагментом.
Указатели
Зачем нужны указатели на версии строк? Дело в том, что индексные строки должны как-то ссылаться на версии строк в таблице. Понятно, что ссылка должна содержать номер файла, номер страницы в файле и какое-то указание на версию строки. В качестве такого указания можно было бы использовать смещение относительно начала страницы, но это неудобно. Мы не смогли бы перемещать версию строки внутри страницы, потому что это сломало бы существующие ссылки. А это привело бы к фрагментации места внутри страниц и другим неприятным последствиям. Поэтому индекс ссылается на номер указателя, а указатель — на текущую позицию версии строки в странице. Получается косвенная адресация.
Каждый указатель занимает ровно 4 байта и содержит:
- ссылку на версию строки;
- длину этой версии строки;
- несколько бит, определяющих статус версии строки.
Формат данных
Формат данных на диске полностью совпадает с представлением данных в оперативной памяти. Страница читается в буферный кеш «как есть», без каких бы то ни было преобразований. Поэтому файлы данных с одной платформы оказываются несовместимыми с другими платформами.
Например, в архитектуре x86 принят порядок байтов от младших разрядов к старшим (little-endian), z/Architecture использует обратный порядок (big-endian), а в ARM порядок переключаемый.
Многие архитектуры предусматривают выравнивание данных по границам машинных слов. Например, на 32-битной системе x86 целые числа (тип integer, занимает 4 байта) будут выровнены по границе 4-байтных слов, как и числа с плавающей точкой двойной точности (тип double precision, 8 байт). А на 64-битной системе значения double будут выровнены по границе 8-байтных слов. Это еще одна причина несовместимости.
Из-за выравнивания размер табличной строки зависит от порядка расположения полей. Обычно этот эффект не сильно заметен, но в некоторых случаях он может привести к существенному увеличению размера. Например, если располагать поля типов char(1) и integer вперемешку, между ними, как правило, будет впустую пропадать 3 байта. Подробнее об этом можно посмотреть в презентации Николая Шаплова "Что у него внутри".
Версии строк и TOAST
Про то, как изнутри устроены версии строк, мы будем подробно говорить в следующий раз. Пока для нас важно лишь то, что каждая версия должна помещаться целиком на одну страницу: в PostgreSQL не предусмотрено способа «продолжить» строку на следующей странице. Вместо этого используется технология, названная TOAST (The Oversized Attributes Storage Technique). Само имя подсказывает, что строка может нарезаться на тосты.
Если говорить серьезно, то TOAST подразумевает несколько стратегий. «Длинные» значения атрибутов можно отправить в отдельную служебную таблицу, предварительно нарезав на небольшие фрагменты-тосты. Другой вариант — сжать значение так, чтобы версия строки все-таки поместилась на обычную табличную страницу. А можно и то, и другое: сначала сжать, а уже потом нарезать и отправить.
Для каждой основной таблицы при необходимости создается отдельная, но одна для всех атрибутов, TOAST-таблица (и к ней специальный индекс). Необходимость определяется наличием в таблице потенциально длинных атрибутов. Например, если в таблице есть столбец типа numeric или text, TOAST-таблица будет сразу же создана, даже если длинные значения не будут использоваться.
Поскольку TOAST-таблица по сути обычная таблица, у нее есть все тот же набор слоев. А это еще в два раза увеличивает число файлов, которые «обслуживают» таблицу.
Изначально стратегии определяются типами данных столбцов. Посмотреть их можно командой
\d+ в psql, но, поскольку она заодно выводит много другой информации, мы воспользуемся запросом к системному каталогу:=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
Названия стратегий имеют следующий смысл:
- plain — TOAST не используется (применяется для заведомо “коротких” типов данных, как integer);
- extended — допускается как сжатие, так и хранение в отдельной TOAST-таблице;
- external — длинные значения хранятся в TOAST-таблице несжатыми;
- main — длинные значения в первую очередь сжимаются, а в TOAST-таблицу попадают только если сжатие не помогло.
В общих чертах алгоритм выглядит следующим образом. PostgreSQL стремится к тому, чтобы на странице помещалось хотя бы 4 строки. Поэтому если размер строки превышает четвертую часть страницы с учетом заголовка (при обычной 8К-странице это 2040 байт), к части значений необходимо применить TOAST. Действуем в порядке, описанном ниже, и прекращаем, как только строка перестает превышать порог:
- Сначала перебираем атрибуты со стратегиями external и extended, двигаясь от самых длинных к более коротким. Extended-атрибуты сжимаются (если это дает эффект) и, если значение само по себе превосходит четверть страницы, оно сразу же отправляется в TOAST-таблицу. External-атрибуты обрабатываются так же, но не сжимаются.
- Если после первого прохода версия строки все еще не помещается, отправляем в TOAST-таблицу оставшиеся атрибуты со стратегиями external и extended.
- Если и это не помогло, пытаемся сжать атрибуты со стратегией main, оставляя их при этом в табличной странице.
- И только если после этого строка все равно недостаточно коротка, main-атрибуты отправляются в TOAST-таблицу.
Иногда может оказаться полезным изменить стратегию для некоторых столбцов. Например, если заранее известно, что данные в столбце не сжимаются, можно установить для него стратегию external — это позволить сэкономить на бесполезных попытках сжатия. Это выполняется следующим образом:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
Повторив запрос, получим:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
TOAST-таблицы и индексы располагаются в отдельной схеме pg_toast и поэтому обычно не видны. Для временных таблиц используется схема pg_toast_temp_N аналогично обычной pg_temp_N.
Конечно, при желании никто не мешает подглядеть за внутренней механикой процесса. Скажем, в таблице accounts есть три потенциально длинных атрибута, поэтому TOASТ-таблица обязана быть. Вот она:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
Логично, что для «тостов», на которые нарезается строка, применяется стратегия plain: TOAST второго уровня не существует.
Индекс PostgreSQL прячет более тщательно, но и его нетрудно найти:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
Столбец client использует стратегию extended: значения в нем будут сжиматься. Проверим:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
В TOAST-таблице ничего нет: повторяющиеся символы прекрасно сжимаются и после этого значение поместилось в обычной табличной странице.
А теперь пусть имя клиента состоит из случайных символов:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
Такую последовательность сжать не получается, и она попадает в TOAST-таблицу:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
Как видим, данные нарезаются на фрагменты по 2000 байт.
При обращении к «длинному» значению PostgreSQL автоматически, прозрачно для приложения, восстанавливает исходное значение и возвращает его клиенту.
Разумеется, и на сжатие с нарезкой, и на последующее восстановление тратится довольно много ресурсов. Поэтому хранить объемные данные в PostgreSQL — не лучшая идея, особенно если они активно используются и при этом для них не требуется транзакционная логика (как пример: отсканированные оригиналы бухгалтерских документов). Более выгодной альтернативой может оказаться хранение таких данных на файловой системе, а в СУБД — имен соответствующих файлов.
TOAST-таблица используется только при обращении к «длинному» значению. Кроме того, для toast-таблицы поддерживается своя версионность: если обновление данных не затрагивает «длинное» значение, новая версия строки будет ссылаться на то же самое значение в TOAST-таблице — это экономит место.
Отметим, что TOAST работает только для таблиц, но не для индексов. Это накладывает ограничение на размер индексируемых ключей.
Более детально про внутреннюю организацию данных можно прочитать в документации.Продолжение.

