
Assembler – мой любимый язык, … но жизнь так коротка.
Продолжаю цикл изысканий по вопросу подходящих теней для некоторого рогалика. После публикаций раз и два несколько поостыл к данной теме, но эффект незавершенного действия побуждает меня возвращаться к маранию пикселей, и завершить гештальт.
Зная себя, я уверен, что игра едва получит своё воплощение, но возможно кого-то из общественности заинтересуют мои наработки на этом тернистом пути. И так приступим.
Уже в конце прошлого цикла подходил к пониманию, что расчёт графики на CPU это уже прошлый век, но природное упрямство твердило: ещё не все возможности использованы, есть ещё варианты интересных решений.
Не воплощённой оставалась обратная трассировка лучей. Точнее её разновидность, где для каждого пикселя изображения (блока пикселей) пробрасывается луч и определяется уровень освещения текущей точки. Сам алгоритм описан в прошлой статье и возвращаться к нему нет смысла. Для обратной трассировки лучей код был ещё более упрощен, убрана полностью вся тригонометрия, что в перспективе могло дать приемлемый результат.
Pascal
const tile_size = 32; // размер тайла tile_size1 : single = 0.03125; // 1/32 - обратный размер тайла block_size = 4; // Ширина/высота блока в пикселях Size_X:Byte = 32; // Количесво тайлов по X Size_Y:Byte = 24; // Количесво тайлов по Y //--------------------------------- function is_no_empty(x,y:Integer):Integer; begin if (x>=0) AND (x<Size_X) AND (y>=0) AND (y<Size_Y) then begin if map[x,y]=1 then begin is_no_empty:=1; end else if map[x,y]=2 then begin is_no_empty:=2; end else is_no_empty:=0; end else is_no_empty:=-1; end; //--------------------------------- function crossing(r_view, x,y:Single; xi,yj, i,j:Integer):Byte; var di,dj,ddi,ddj :Shortint; // коэффициенты смещения k,i2,j2 :integer; // индексы хранения ячейки key:Boolean; last_k, transp_key :Byte; sum_lenX,sum_lenY, Dx,Dy,Dx1,DY1, l :Single; // сумматоры sec1,cosec1, temp_x,temp_y, dx0,dy0 :Single; // временные переменные i0,j0 :Integer; // индекс тайла в который нужно прийти begin temp_x := i*block_size; temp_y := j*block_size; i0 := trunc(temp_x * tile_size1); j0 := trunc(temp_y * tile_size1); l := sqrt(sqr(temp_y-y) + sqr(temp_x-x)) + 0.0000001; transp_key := 0; // Затемнение когда внутри объекта if is_no_empty(xi,yj)>0 then inc(transp_key); if (xi=i0) and (yj=j0) then begin crossing := min(255,transp_key*64+ l * r_view); exit; end; dx0 := (temp_x-x)/l+0.0000001; dy0 := (temp_y-y)/l+0.0000001; key := False; last_k :=0; // Инициализация направления if dx0<0 then begin di :=-1; ddi:= 0; end else begin di := 1; ddi:= 1; end; if dy0<0 then begin dj :=-1; ddj:= 0; end else begin dj := 1; ddj:= 1; end; sum_lenX := 0; sum_lenY := 0; sec1 := 1/dx0; cosec1 := 1/dy0; // Длина начального плеча по Х и Y temp_x := x-(xi+ddi) * tile_size ; temp_y := y-(yj+ddj) * tile_size ; Dx := sqrt(sqr(temp_x) + sqr(temp_x * sec1 * dy0)); DY := sqrt(sqr(temp_y) + sqr(temp_y * cosec1 * dx0)); // Длина плеча по Х и Y Dx1 := abs(tile_size * sec1); Dy1 := abs(tile_size * cosec1); repeat if sum_lenX+DX < sum_lenY+DY then begin xi += di; k := is_no_empty(xi,yj); sum_lenX += DX; if DX<>Dx1 then DX := Dx1; end else begin yj += dj; k := is_no_empty(xi,yj); sum_lenY += DY; if DY<>Dy1 then DY := Dy1; end; if key Then begin if (xi<>i2) Or (yj<>j2) then begin // стена (дальше не расчитываем) if last_k=1 then begin crossing := 255; exit; end; // множество препятствий (дальше не расчитываем) if transp_key>2 then begin crossing := 255; exit; end; inc(transp_key); key:= false; end; end; if k>0 then begin i2:=xi; j2:=yj; key:=true; last_k:=k; end; // Обнаружили искомый тайл if (xi=i0) and (yj=j0) then begin crossing := min(255, transp_key*64+ l * r_view); exit; end; until k=-1; // Вышли за границу карты end; //--------------------------------- .................. x0:= mouse_x; y0:= mouse_y; // Деление выносим за функцию для оптимизиции x1 := x0 div tile_size; y1 := y0 div tile_size; koef := tile_size div block_size; // Для каджого пикселя вызываем трасировку (в данном случае для блока пикселей) for j:=0 to Size_Y * koef do for i:=0 to Size_X * koef do picture_mask.SetPixel(i, j, BGRA(0,0,0,crossing(x0, y0, x1, y1, i, j))); ..................
Увы, результат оказался много хуже ожиданий, стоило картинку развернуть на полный экран, FPS стремился к единицам.

Группировка пикселей в макроблоки для уменьшения расчётов и применение последующего сглаживания, ненамного, улучшали производительность. Эффект откровенно не нравился от слова совсем.

Алгоритм отлично параллелился, но задействовать множество потоков не имело смыла, эффект казался много хуже, чем в прошлой статье, даже при лучшем качестве картинки.
Это оказался тупик. Нужно было признать, CPU в расчёте графики в моих глазах себя исчерпал. Занавес.
Отступление 1
За последние десяток лет практически отсутствует прогресс в развитии процессоров общего назначения. Если подходить со стороны пользователя, то максимальный замеченный прирост производительности составляет не более 30% на ядро. Прогресс, мягко говоря, незначительный. Если опустить расширение длины векторных инструкций, и некоторого ускорения конвейерных блоков, то это увеличение числа рабочих ядер. Безопасная работа с потоками, то ещё удовольствие, а далеко не все задачи можно успешно параллелить. Хотелось бы иметь рабочее ядро, пусть одно, но раз так в 5-10 быстрее, но как говориться, увы и ах.
Здесь на Хабре есть отличный цикл статей «Жизнь в эпоху «тёмного» кремния», который объясняет некоторые предпосылки к текущему состоянию дел, но и возвращает с небес на землю. В ближайшее десятилетие можно не ожидать сколько-нибудь значительного роста вычислений в расчёте на одно ядро. Зато можно ожидать дальнейшее развитие количества ядер GPU и их общее ускорение. Даже на моём стареньком ноутбуке ориентировочная суммарная производительность GPU в 20 раз выше чем одного потока CPU. Даже если эффективно загрузить все 4 ядра процессора, это много меньше чем хотелось бы.
Отдаю дань разработчикам графики прошлого, которые делали свои шедевры не имея аппаратных ускорителей, настоящие мастера.
Здесь на Хабре есть отличный цикл статей «Жизнь в эпоху «тёмного» кремния», который объясняет некоторые предпосылки к текущему состоянию дел, но и возвращает с небес на землю. В ближайшее десятилетие можно не ожидать сколько-нибудь значительного роста вычислений в расчёте на одно ядро. Зато можно ожидать дальнейшее развитие количества ядер GPU и их общее ускорение. Даже на моём стареньком ноутбуке ориентировочная суммарная производительность GPU в 20 раз выше чем одного потока CPU. Даже если эффективно загрузить все 4 ядра процессора, это много меньше чем хотелось бы.
Отдаю дань разработчикам графики прошлого, которые делали свои шедевры не имея аппаратных ускорителей, настоящие мастера.
Итак, разбираемся с GPU. Для меня оказалось несколько неожиданно, что в настоящей практике мало кто просто разбрасывается полигонами по форме. Все мало-мальски интересные вещи создаются с использованием шейдеров. Отбросив готовые 3D движки, попробовал изучить потроха технологии как они есть на глубинном уровне. Те же процессоры тот же ассемблер, только несколько урезанный набор команд и своя специфика работы. Для пробы остановился на GLSL, С- подобный синтаксис, простота, множество обучающих уроков и примеров, в том числе и на хабре.
Поскольку я в основном привык писать на Pascal, встала задача как подключать OpenGL
к проекту. Мне удалось найти два способа подключения: библиотека GLFW и заголовочный файл dglOpenGL. Единственное в первом я не смог подключить шейдеры, но видимо это от кривизны моих рук.
Отступление 2
Многие знакомые спрашивают меня почему я пишу на Pascal? Очевидно, это вымирающий язык, его сообщество неуклонно падает, развития почти нет. Низкоуровневые системщики предпочитают С, а прикладники Java, Python, Ruby или что там сейчас на пике.
Для меня Pascal сродни первой любви. Два десятка лет назад ещё во времена Turbo Pascal 5.5, он запал мне в душу и с тех пор шагает со мной по жизни, будь это Delphi или в последние годы Lazarus. Мне нравится предсказуемость языка, относительная низкоуровневость (ассемблерные вставки и просмотр инструкция процессора), совместимость с С. Главное что код собирается и выполняется без проблем, а то что не модный, устарел, и нет некоторых фич, это ерунда. Поговаривают, есть люди, что всё ещё на LISP пишут, а ему вообще за пол века.
Для меня Pascal сродни первой любви. Два десятка лет назад ещё во времена Turbo Pascal 5.5, он запал мне в душу и с тех пор шагает со мной по жизни, будь это Delphi или в последние годы Lazarus. Мне нравится предсказуемость языка, относительная низкоуровневость (ассемблерные вставки и просмотр инструкция процессора), совместимость с С. Главное что код собирается и выполняется без проблем, а то что не модный, устарел, и нет некоторых фич, это ерунда. Поговаривают, есть люди, что всё ещё на LISP пишут, а ему вообще за пол века.
Итак, окунёмся в разработку. Для пробного шага не будем брать точные реалистичные модели затенения, а попробуем реализовать то что уже пробовали ранее, но уже с производительностью GPU, так сказать для наглядного сравнения.
Изначально думал получить тень примерно такой формы, для объекта используя треугольники.
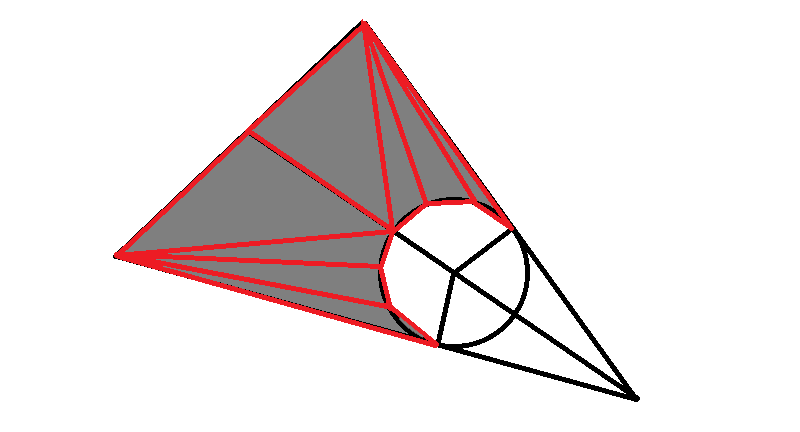
Для создания эффекта гладкой окружности нужна масса полигонов. Но что, если использовать треугольники по минимуму, использовав пиксельный шейдер для создания отверстия в фигуре. Идея ко мне пришла после прочтения статьи уважаемого мастера, в которой открылась возможность создавать сферы шейдером.
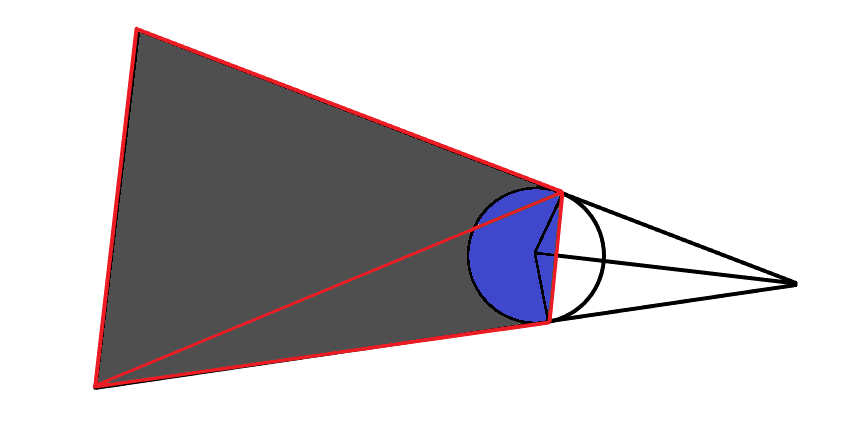
Если продлить треугольник за границы экрана, то в итоге получается такое:

Границы тени получились очень жёсткими и к тому же ступенчатыми. Но есть способ как получить приемлемый результат не используя суперсэмплинг, это использование сглаженных границ. Для этого немного изменим схему. Углы полигонов в местах пересечения касательной к окружности сделаем прозрачными.
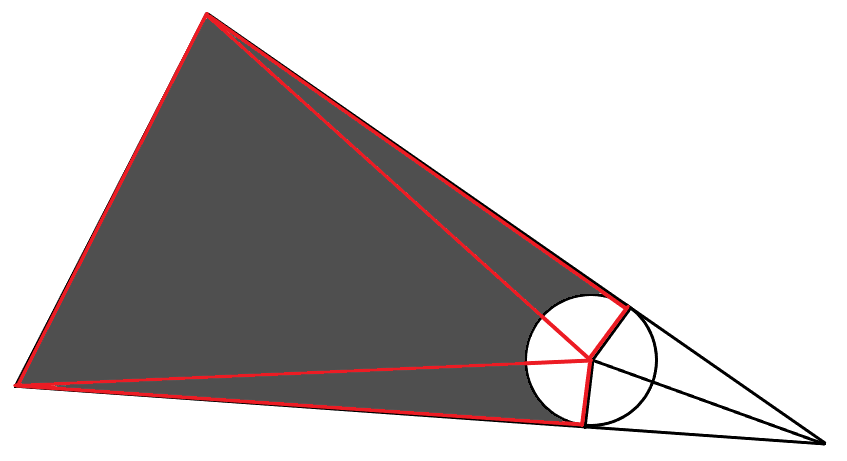
Результат, лучше, но всё ещё выглядит неестественно.

Добавим небольшое сглаживание окружности для придания мягкости, а также изменим вид градиента с линейного на степенной.

Вполне приемлемый результат.
И в итоге добавим на форму объекты имитирующие препятствия.

Код шейдера
// Вершинный шейдер
#version 330 core
layout (location = 0) in vec2 aVertexPosition;
void main(void) {
gl_Position = vec4(aVertexPosition.xy, 0, 1.0);
}
// Шейдер геометрии
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;
uniform mat4 uModelViewMatrix;
uniform float uRadius;
uniform vec2 uHeroPoint;
out float fTransparency;
out vec2 vCenter;
void main(){
vCenter = gl_in[0].gl_Position.xy;
vec2 d = uHeroPoint - vCenter;
float l = length(d);
float i = uRadius / l;
float ii = i*i;
float ij = i * sqrt(1 - ii);
vec2 p1 = vec2(vCenter.x + d.x*ii - d.y*ij , vCenter.y + d.x*ij + d.y*ii);
vec2 p2 = vec2(vCenter.x + d.x*ii + d.y*ij , vCenter.y - d.x*ij + d.y*ii);
d = uHeroPoint - p1;
vec2 p3 = vec2(p1 - d/length(d)*1000000);
d = uHeroPoint - p2;
vec2 p4 = vec2(p2 - d/length(d)*1000000);
fTransparency = 0;
gl_Position = uModelViewMatrix * vec4(p1, 0, 1);
EmitVertex();
fTransparency = 1;
gl_Position = uModelViewMatrix * vec4(p3, 0, 1);
EmitVertex();
gl_Position = uModelViewMatrix * vec4(vCenter, 0, 1);
EmitVertex();
gl_Position = uModelViewMatrix * vec4(p4, 0, 1);
EmitVertex();
fTransparency = 0;
gl_Position = uModelViewMatrix * vec4(p2, 0, 1);
EmitVertex();
EndPrimitive();
}
// Фрагментный шейдер
#version 330 core
precision mediump float;
varying float fTransparency;
varying vec2 vCenter;
uniform float uRadius;
uniform vec2 uScreenHalfSize;
uniform float uShadowTransparency;
uniform float uShadowSmoothness;
out vec4 FragColor;
void main(){
float l = distance(vec2((gl_FragCoord.xy - uScreenHalfSize.xy)/uScreenHalfSize.y), vCenter.xy);
if (l<uRadius) {discard;}
else {FragColor = vec4(0, 0, 0, min(pow(fTransparency, uShadowSmoothness), (l-uRadius)/uRadius*10)*uShadowTransparency);}
}
Надеюсь было познавательно,
Ваш покорный слуга, терзатель пикселей, Rebuilder.
Прилагаю небольшое демо. (EXE Виндовс)
P.S. Заголовок статьи содержит пасхалку, отсылка к трилогии Хроники Сиалы. Отличное произведение в стили фентези, о злоключениях роги, от Алексея Пехова.

