«Нам нужен DevOps!»
(самая популярная фраза в конце любого хакатона)

Сначала немного лирики.
Когда разработчик является отличным девопсом, умеющим развернуть своё детище на любой машине под любой OC, это плюс. Однако, если он вообще ничего не смыслит дальше своей IDE, это не минус — в конце концов, деньги ему платят за код, а не за умение его разворачивать. Узкий глубокий специалист на рынке ценится выше, чем средней квалификации «мастер на все руки». Для таких, как мы, «пользователей IDE», хорошие люди придумали Docker.
Принцип Docker следующий: «работает у меня — работает везде». Единственная программа, необходимая для деплоя копии Вашего приложения где угодно — это Docker. Если Вы запустили своё приложение в докере у себя на машине, оно гарантированно с тем же успехом запустится в любом другом докере. И ничего, кроме докера, устанавливать не нужно. У меня, к примеру, на виртуальном сервере даже Java не стоит.
Docker создаёт образ виртуальной машины с установленными в ней приложениями. Дальше этот образ разворачивается как абсолютно автономная виртуальная машина. Запущенная копия образа называется «контейнер». Вы можете запустить на сервере любое количество образов, и каждый из них будет отдельной виртуальной машиной со своим окружением.
Что такое виртуальная машина? Это инкапсулированное место на сервере с операционкой, в которой установлены приложения. В любой операционке обычно крутится большое количество приложений, в нашей же находится одно.
Схему развёртывания контейнеров можно представить так:

Для каждого приложения мы создаём свой образ, а потом разворачиваем каждый контейнер отдельно. Также, можно положить все приложения в один образ и развернуть как один контейнер. Причём, чтобы не разворачивать каждый контейнер отдельно, мы можем использовать отдельную утилиту docker-compose, которая конфигурирует контейнеры и взаимосвязь между ними через отдельный файл. Тогда структура всего приложения может выглядеть так:

Я намеренно не стал вносить базу данных в общую сборку Docker, по нескольким причинам. Во-первых, база данных полностью независима от приложений, которые с ней работают. Это может быть далеко не одно приложение, это могут быть ручные запросы из консоли. Лично я не вижу смысла ставить базу данных в зависимость от сборки Docker, в которой она находится. Поэтому я её и вынес. Впрочем, очень часто практикуется подход, при котором база данных помещается в отдельный образ и запускается отдельным контейнером. Во-вторых, хочется показать, как Docker-контейнер взаимодействует с системами вне контейнера.
Впрочем, довольно лирики, давайте писать код. Мы напишем простейшее приложение на спринге и реакте, которое будет записывать наши обращения к фронту в базу данных, и поднимем всё это через Docker. Структура нашего приложения будет выглядеть так:

Реализовать такую структуру можно разными путями. Мы реализуем один из них. Мы создадим два образа, запустим из них два контейнера, причём, бэкенд будет подключаться к базе данных, которая установлена на конкретном сервере где-то в интернете (да, такие запросы к базе будут ходить не быстро, но нами движет не жажда оптимизации, а научный интерес).
Пост будет разбит на части:
0. Устанавливаем Docker.
1. Пишем приложения.
2. Собираем образы и запускаем контейнеры.
3. Собираем образы и запускаем контейнеры на удалённом сервере.
4. Решаем проблемы с сетью.
Для того, чтобы установить Docker, нужно зайти на сайт и следовать тому, что там написано. При установка Docker на удалённом сервере будьте готовы к тому, что с серверами на OpenVZ Docker может не работать. Равно как могут быть проблемы, если у Вас не включён iptables. Желательно заводить сервер на KVM с iptables. Но это мои рекомендации. Если у Вас всё заработает и так, я буду рад, что Вы не потратили кучу времени на выяснение, почему не работает, как это пришлось сделать мне.
Напишем простое приложение с самым примитивным бэкендом на Spring Boot, очень простым фронтендом на ReactJS и базой данных MySQL. Приложение будет иметь Single-Page с одной-единственной кнопкой, которая будет записывать время нажатия по ней в базу данных.
Я рассчитываю на то, что Вы уже умеете писать приложения на буте, но если нет, Вы можете клонировать готовый проект. Все ссылки в конце статьи.
build.gradle:
Сущность Log:
LogController, который будет работать по упрощённой логике и сразу писать в базу данных. Сервис мы опускаем.
Всё, как мы видим, очень просто. По GET-запросу мы делаем запись в базу и возвращаем результат.
Файл настроек приложения обсудим отдельно. Их два.
application.yml:
application-remote.yml:
Как это работает, Вы, наверняка, знаете, сначала Spring сканирует файл application.properties или application.yml — какой найдёт. В нём мы указываем одну-единственную настройку — какой профиль будем использовать. Обычно во время разработки у меня накапливается несколько профилей, и очень удобно их переключать при помощи дефолтного профиля. Далее Spring находит application.yml с нужным суффиксом и пользует его.
Мы указали датасорс, настройки JPA и, что важно, внешний порт нашего бэкенда.
Фронтенд тоже можно посмотреть в проекте на git, а можно даже не смотреть, а клонировать и запустить.
Отдельную работу фронтенда можно проверить, скачав проект, перейдя в терминале в корневую папку проекта (туда, где лежит файл package.json) и выполнив последовательно две команды:
Конечно, для этого Вам нужен установленный Node Package Manager (npm), и это тот самый трудный путь, которого мы избегаем при помощи Docker. Если Вы всё-таки запустили проект, Вы увидите следующее окошко:

Ну да ладно, настало время посмотреть код. Укажу лишь часть, которая обращается к бэкенду.
Фронтенд работает предсказуемо. Переходим по ссылке, дожидаемся ответа и выводим его на экран.
Стоит акцентировать внимание на следующих пунктах:
Приложение готово.
Структура нашей сборки будет следующая. Мы создадим два образа — фронтенд и бэкенд, которые будут общаться друг с другом через внешние порты. Для базы мы не будем создавать образ, мы установим её отдельно. Почему так? Почему для базы мы не создаём образ? У нас есть два приложения, которые постоянно изменяются и не хранят в себе данные. База данных хранит в себе данные, и это может быть результат нескольких месяцев работы приложения. Более того, к данной базе данных может обращаться не только наше бэкенд-приложение, но и многие другие — на то она и база данных, и мы не будем её постоянно пересобирать. Опять же, это возможность поработать с внешним API, чем, безусловно, является подключение к нашей БД.
Для запуска каждого приложения (будь то фронт или бэк) потребуется определённая последовательность действий. Для запуска приложения на React нам потребуется сделать следующее (при условии, что у нас уже есть Linux):
Именно эту последовательность действий нам и предстоит выполнить в докере. Для этого в корне проекта (там же, где находится package.json) мы должны разместить файл Dockerfile со следующим содержанием:
Разберём, что означает каждая строчка.
Этой строчкой мы даём понять докеру, что при запуске контейнера первым делом нужно будет скачать из репозитория Docker и установить NodeJS, причём, самую лёгкую (все самые лёгкие версии популярных фреймворков и библиотек в докере принято называть alpine).
В линуксе контейнера будут созданы те же стандартные папки, что и в других линуксах — /opt, /home, /etc, /usr и проч. Мы задаём рабочую директорию, с которой будем работать — /usr/app/front.
Открываем порт 3000. Дальнейшая связь с приложением, запущенным в контейнере, будет происходить через этот порт.
Копируем содержимое исходного проекта в рабочую папку контейнера.
Устанавливаем все пакеты, необходимые для запуска приложения.
Запускаем приложение командой npm start.
Именно этот сценарий будет выполнен в нашем приложении при запуске контейнера.
Давайте сразу соберём фронт. Для этого нужно в терминале, находясь в корневой папке проекта (там, где находится Dockerfile), выполнить команду:
Значения команд:
docker — вызов приложения docker, ну, это вы знаете.
build — сборка образа из целевых материалов.
-t <имя> — в дальнейшем, приложение будет доступно по тегу, указанному здесь. Можно не указывать, тогда Docker сгенерирует собственный тег, но отличить его от других будет невозможно.
. — указывает, что собирать проект нужно именно из текущей папки.

В результате, сборка должна закончиться текстом:
Если мы видим, что последний шаг выполнен и всё Successfull, значит, образ у нас есть. Мы можем проверить это, запустив его:
Смысл этой команды, я думаю, в целом понятен, за исключением записи -p 8080:3000.
docker run rebounder-chain-frontend — означает, что мы запускаем такой-то докер-образ, который мы обозвали rebounder-chain-frontend. Но такой контейнер не будет иметь выхода наружу, ему нужно задать порт. Именно команда ниже его задаёт. Мы помним, что наше React-приложение запускается на порте 3000. Команда -p 8080:3000 указывает докеру, что нужно взять порт 3000 и пробросить его на порт 8080 (который будет открыт). Таким образом, приложение, которое работает по порту 3000, будет открыто по порту 8080, и на локальной машине будет доступно именно по этому порту.
Пусть вас не смущает запись
Так думает React. Он действительно доступен в пределах контейнера по порту 3000, но мы пробросили этот порт на порт 8080, и из контейнера приложение работает по порту 8080. Можете запустить приложение локально и проверить это.
Итак, у нас есть готовый контейнер с фронтенд-приложением, теперь давайте соберём бэкенд.
Сценарий запуска приложения на Java существенно отличается от предыдущей сборки. Он состоит из следующих пунктов:
В Dockerfile этот процесс выглядит так:
Процесс сборки образа с включением джарника по некоторым пунктам напоминает таковой для нашего фронта.
Процесс сборки и запуска второго образа принципиально ничем не отличается от сборки и запуска первого.
Теперь, если у Вас запущены оба контейнера, а бэкенд подключён к БД, всё заработает. Напоминаю, что подключение к БД из бэкенда Вы должны прописать сами, и оно должно работать через внешнюю сеть.
Для того, чтобы всё заработало на удалённом сервере, нам необходимо, чтобы на нём был уже установлен Docker, после чего, достаточно запустить образы. Мы пойдём правильным путём и закоммитим наши образы в свой аккаунт в облаке Docker, после чего, они станут доступны из любой точки мира. Конечно, альтернатив данному подходу, как и всему, что описано в посте, предостаточно, но давайте ещё немного поднажмём и сделаем свою работу хорошо. Плохо, как говорил Андрей Миронов, мы всегда успеем сделать.
Первое, что Вам предстоит сделать — это обзавестись аккаунтом на хабе Docker. Для этого надо перейти на хаб и зарегаться. Это несложно.
Далее, нам нужно зайти в терминал и авторизоваться в Docker.
Вас попросят ввести логин и пароль. Если всё ок, в терминале появится уведомление, что Login Succeeded.
Далее, мы должны пометить наши образы тэгами и закоммитить их в хаб. Делается это командой по следующей схеме:
Таким образом, нам нужно указать имя нашего образа, логин/репозиторий и тэг, под которым наш образ будет закоммичен в хаб.
В моём случае, это выглядело так:

Мы можем проверить наличие данного образа в локальном репозитории при помощи команды:
Наш образ готов к коммиту. Коммитим:
Должна появиться запись об успешном коммите.
Делаем то же самое с фронтендом:
Теперь, если мы зайдём на hub.docker.com, мы увидим два закоммиченных образа. Которые доступны откуда угодно.

Поздравляю. Нам осталось перейди к заключительной части нашей работы — запустить образы на удалённом сервере.
Теперь мы можем запустить наш образ на любой машине с Docker, выполнив всего одну строчку в терминале (в нашем случае, нам надо последовательно выполнить две строчки в разных терминалах — по одной на каждый образ).
У такого запуска есть, правда, один минус. При закрытии терминала процесс завершится и приложение прекратит работу. Чтобы этого избежать, мы можем запустить приложение в «откреплённом» режиме:
Теперь приложение не будет выдавать лог в терминал (это можно, опять же, настроить отдельно), но и при закрытии терминала оно не прекратит свою работу.
Если Вы всё сделали правильно, Вас, возможно, ожидает самое большое разочарование на всём пути следования этому посту — вполне может так получиться, что ничего не работает. Например, у Вас всё великолепно собралось и заработало на локальной машине (как, например, у меня на маке), но при развёртывании на удалённом сервере контейнеры перестали друг друга видеть (как, например, у меня на удалённом сервере на Linux). В чём проблема? А проблема вот в чём, и я в начале о ней намекал. Как уже было сказано раньше, при запуске контейнера Docker создаёт отдельную виртуальную машину, накатывает туда Linux, и потом в этот Linux устанавливает приложение. Это значит, что условный localhost для запущенного контейнера ограничивается самим контейнером, и о существовании других сетей приложение не подозревает. Но нам нужно, чтобы:
а) контейнеры видели друг друга.
б) бэкенд видел базу данных.
Решения проблемы два.
1. Создание внутренней сети.
2. Вывод контейнеров на уровень хоста.
1. На уровне Docker можно создавать сети, причём, три из них в нём есть по умолчанию — bridge, none и host.
Bridge — это внутренняя сеть Docker, изолированная от сети хоста. Вы можете иметь доступ к контейнерам только через те порты, которые открываете при запуске контейнера командой -p. Можно создавать любое количество сетей типа bridge.

None — это отдельная сеть для конкретного контейнера.
Host — это сеть хоста. При выборе этой сети, Ваш контейнер полностью доступен через хост — здесь попросту не работает команда -p, и если Вы развернули контейнер в этой сети, то Вам незачем задавать внешний порт — контейнер доступен по своему внутреннему порту. Например, если в Dockerfile EXPOSE задан как 8090, именно через этот порт будет доступно приложение.

Поскольку нам нужно иметь доступ к базе данных сервера, мы воспользуемся последним способом и выложим контейнеры в сеть удалённого сервера.
Делается это очень просто, мы убираем из команды запуска контейнера упоминание о портах и и указываем сеть host:
Подключение к базе я указал
Подключение фронта к бэку пришлось указать целиком, внешнее:
Если вы пробрасываете внутренний порт на внешний, что часто бывает для удалённых серверов, то для базы нужно указывать внутренний порт, а для контейнера — внешний порт.
Если Вы хотите поэкспериментировать с подключениями, вы можете скачать и собрать проект, который я специально написал для тестирования соединения между контейнерами. Просто вводите необходимый адрес, жмёте Send и в режиме отладки смотрите, что прилетело обратно.
Проект лежит тут.
Есть масса способов собрать и запустить образ Docker. Интересующимся советую изучить docker-compose. Здесь мы разобрали лишь один из способов работы с докером. Конечно, такой подход поначалу кажется не таким уж и простым. Но вот пример — в ходе написания поста у меня возникли с исходящими подключениями на удалённом сервере. И в процессе дебага мне пришлось несколько раз менять настройки подключения к БД. Вся сборка и деплой умещались у меня в набор 4 строчек, после ввода которых я видел результат на удалённом сервере. В режиме экстремального программирования Docker окажется незаменим.
Как и обещал, выкладываю исходники приложений:
backend
frontend
(самая популярная фраза в конце любого хакатона)
Сначала немного лирики.
Когда разработчик является отличным девопсом, умеющим развернуть своё детище на любой машине под любой OC, это плюс. Однако, если он вообще ничего не смыслит дальше своей IDE, это не минус — в конце концов, деньги ему платят за код, а не за умение его разворачивать. Узкий глубокий специалист на рынке ценится выше, чем средней квалификации «мастер на все руки». Для таких, как мы, «пользователей IDE», хорошие люди придумали Docker.
Принцип Docker следующий: «работает у меня — работает везде». Единственная программа, необходимая для деплоя копии Вашего приложения где угодно — это Docker. Если Вы запустили своё приложение в докере у себя на машине, оно гарантированно с тем же успехом запустится в любом другом докере. И ничего, кроме докера, устанавливать не нужно. У меня, к примеру, на виртуальном сервере даже Java не стоит.
Как работает Docker?
Docker создаёт образ виртуальной машины с установленными в ней приложениями. Дальше этот образ разворачивается как абсолютно автономная виртуальная машина. Запущенная копия образа называется «контейнер». Вы можете запустить на сервере любое количество образов, и каждый из них будет отдельной виртуальной машиной со своим окружением.
Что такое виртуальная машина? Это инкапсулированное место на сервере с операционкой, в которой установлены приложения. В любой операционке обычно крутится большое количество приложений, в нашей же находится одно.
Схему развёртывания контейнеров можно представить так:
Для каждого приложения мы создаём свой образ, а потом разворачиваем каждый контейнер отдельно. Также, можно положить все приложения в один образ и развернуть как один контейнер. Причём, чтобы не разворачивать каждый контейнер отдельно, мы можем использовать отдельную утилиту docker-compose, которая конфигурирует контейнеры и взаимосвязь между ними через отдельный файл. Тогда структура всего приложения может выглядеть так:
Я намеренно не стал вносить базу данных в общую сборку Docker, по нескольким причинам. Во-первых, база данных полностью независима от приложений, которые с ней работают. Это может быть далеко не одно приложение, это могут быть ручные запросы из консоли. Лично я не вижу смысла ставить базу данных в зависимость от сборки Docker, в которой она находится. Поэтому я её и вынес. Впрочем, очень часто практикуется подход, при котором база данных помещается в отдельный образ и запускается отдельным контейнером. Во-вторых, хочется показать, как Docker-контейнер взаимодействует с системами вне контейнера.
Впрочем, довольно лирики, давайте писать код. Мы напишем простейшее приложение на спринге и реакте, которое будет записывать наши обращения к фронту в базу данных, и поднимем всё это через Docker. Структура нашего приложения будет выглядеть так:
Реализовать такую структуру можно разными путями. Мы реализуем один из них. Мы создадим два образа, запустим из них два контейнера, причём, бэкенд будет подключаться к базе данных, которая установлена на конкретном сервере где-то в интернете (да, такие запросы к базе будут ходить не быстро, но нами движет не жажда оптимизации, а научный интерес).
Пост будет разбит на части:
0. Устанавливаем Docker.
1. Пишем приложения.
2. Собираем образы и запускаем контейнеры.
3. Собираем образы и запускаем контейнеры на удалённом сервере.
4. Решаем проблемы с сетью.
0. Устанавливаем Docker
Для того, чтобы установить Docker, нужно зайти на сайт и следовать тому, что там написано. При установка Docker на удалённом сервере будьте готовы к тому, что с серверами на OpenVZ Docker может не работать. Равно как могут быть проблемы, если у Вас не включён iptables. Желательно заводить сервер на KVM с iptables. Но это мои рекомендации. Если у Вас всё заработает и так, я буду рад, что Вы не потратили кучу времени на выяснение, почему не работает, как это пришлось сделать мне.
1. Пишем приложения
Напишем простое приложение с самым примитивным бэкендом на Spring Boot, очень простым фронтендом на ReactJS и базой данных MySQL. Приложение будет иметь Single-Page с одной-единственной кнопкой, которая будет записывать время нажатия по ней в базу данных.
Я рассчитываю на то, что Вы уже умеете писать приложения на буте, но если нет, Вы можете клонировать готовый проект. Все ссылки в конце статьи.
Backend на Spring Boot
build.gradle:
plugins { id 'org.springframework.boot' version '2.1.4.RELEASE' id 'java' } apply plugin: 'io.spring.dependency-management' group = 'ru.xpendence' version = '0.0.2' sourceCompatibility = '1.8' repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-data-jpa' implementation 'org.springframework.boot:spring-boot-starter-web' runtimeOnly 'mysql:mysql-connector-java' testImplementation 'org.springframework.boot:spring-boot-starter-test' }
Сущность Log:
package ru.xpendence.rebounder.entity; import com.fasterxml.jackson.annotation.JsonFormat; import javax.persistence.*; import java.io.Serializable; import java.time.LocalDateTime; import java.util.Objects; /** * Author: Vyacheslav Chernyshov * Date: 14.04.19 * Time: 21:20 * e-mail: 2262288@gmail.com */ @Entity @Table(name = "request_logs") public class Log implements Serializable { private Long id; private LocalDateTime created; @Id @GeneratedValue(strategy = GenerationType.IDENTITY) public Long getId() { return id; } @Column @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss.SSS") public LocalDateTime getCreated() { return created; } @PrePersist public void prePersist() { this.created = LocalDateTime.now(); } //setters, toString, equals, hashcode, constructors
LogController, который будет работать по упрощённой логике и сразу писать в базу данных. Сервис мы опускаем.
package ru.xpendence.rebounder.controller; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import ru.xpendence.rebounder.entity.Log; import ru.xpendence.rebounder.repository.LogRepository; import java.util.logging.Logger; /** * Author: Vyacheslav Chernyshov * Date: 14.04.19 * Time: 22:24 * e-mail: 2262288@gmail.com */ @RestController @RequestMapping("/log") public class LogController { private final static Logger LOG = Logger.getLogger(LogController.class.getName()); private final LogRepository repository; @Autowired public LogController(LogRepository repository) { this.repository = repository; } @GetMapping public ResponseEntity<Log> log() { Log log = repository.save(new Log()); LOG.info("saved new log: " + log.toString()); return ResponseEntity.ok(log); } }
Всё, как мы видим, очень просто. По GET-запросу мы делаем запись в базу и возвращаем результат.
Файл настроек приложения обсудим отдельно. Их два.
application.yml:
spring: profiles: active: remote
application-remote.yml:
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://my-remote-server-database:3306/rebounder_database?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC username: admin password: 12345 jpa: hibernate: ddl-auto: update show-sql: true properties: hibernate.dialect: org.hibernate.dialect.MySQL5Dialect server: port: 8099
Как это работает, Вы, наверняка, знаете, сначала Spring сканирует файл application.properties или application.yml — какой найдёт. В нём мы указываем одну-единственную настройку — какой профиль будем использовать. Обычно во время разработки у меня накапливается несколько профилей, и очень удобно их переключать при помощи дефолтного профиля. Далее Spring находит application.yml с нужным суффиксом и пользует его.
Мы указали датасорс, настройки JPA и, что важно, внешний порт нашего бэкенда.
Фронтенд на ReactJS
Фронтенд тоже можно посмотреть в проекте на git, а можно даже не смотреть, а клонировать и запустить.
Отдельную работу фронтенда можно проверить, скачав проект, перейдя в терминале в корневую папку проекта (туда, где лежит файл package.json) и выполнив последовательно две команды:
npm install // устанавливает в проект все необходимые зависимости, аналог maven npm start // запускает проект
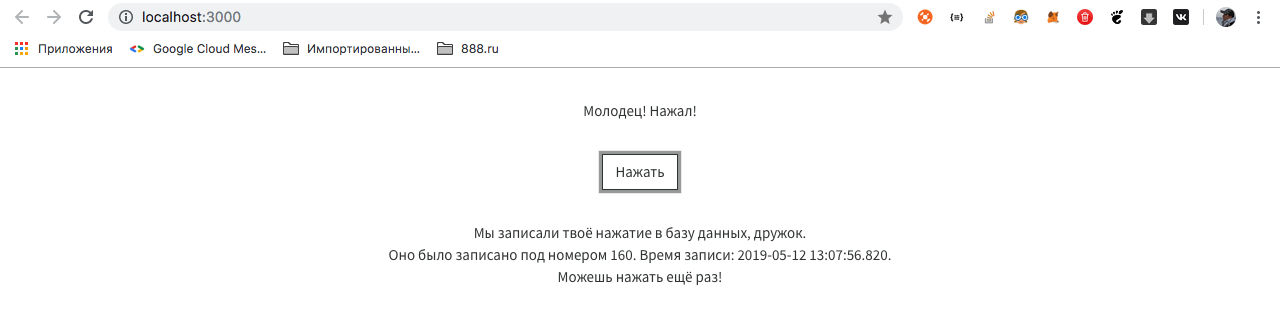
Конечно, для этого Вам нужен установленный Node Package Manager (npm), и это тот самый трудный путь, которого мы избегаем при помощи Docker. Если Вы всё-таки запустили проект, Вы увидите следующее окошко:
Ну да ладно, настало время посмотреть код. Укажу лишь часть, которая обращается к бэкенду.
export default class Api { _apiPath = 'http://localhost:8099'; _logUrl = '/log'; getResource = async () => { const res = await fetch(`${this._apiPath}${this._logUrl}`); if (!res.ok) { throw new Error(`Could not fetch ${this._logUrl}` + `, received ${res.status}`) } return await res.json(); }; };
Фронтенд работает предсказуемо. Переходим по ссылке, дожидаемся ответа и выводим его на экран.
Стоит акцентировать внимание на следующих пунктах:
- Фронт открыт внешнему миру через порт 3000. Это порт по умолчанию для React.
- Бэк открыт по порту 8099. Мы его задали в настройках приложения.
- Бэк стучится к БД через внешний интернет.
Приложение готово.
2. Собираем образы и запускаем контейнеры
Структура нашей сборки будет следующая. Мы создадим два образа — фронтенд и бэкенд, которые будут общаться друг с другом через внешние порты. Для базы мы не будем создавать образ, мы установим её отдельно. Почему так? Почему для базы мы не создаём образ? У нас есть два приложения, которые постоянно изменяются и не хранят в себе данные. База данных хранит в себе данные, и это может быть результат нескольких месяцев работы приложения. Более того, к данной базе данных может обращаться не только наше бэкенд-приложение, но и многие другие — на то она и база данных, и мы не будем её постоянно пересобирать. Опять же, это возможность поработать с внешним API, чем, безусловно, является подключение к нашей БД.
Сборка front-end
Для запуска каждого приложения (будь то фронт или бэк) потребуется определённая последовательность действий. Для запуска приложения на React нам потребуется сделать следующее (при условии, что у нас уже есть Linux):
- Установить NodeJS.
- Скопировать приложение в определённую папку.
- Проинсталлировать необходимые пакеты (команда npm install).
- Запустить приложение командой npm start.
Именно эту последовательность действий нам и предстоит выполнить в докере. Для этого в корне проекта (там же, где находится package.json) мы должны разместить файл Dockerfile со следующим содержанием:
FROM node:alpine WORKDIR /usr/app/front EXPOSE 3000 COPY ./ ./ RUN npm install CMD ["npm", "start"]
Разберём, что означает каждая строчка.
FROM node:alpine
Этой строчкой мы даём понять докеру, что при запуске контейнера первым делом нужно будет скачать из репозитория Docker и установить NodeJS, причём, самую лёгкую (все самые лёгкие версии популярных фреймворков и библиотек в докере принято называть alpine).
WORKDIR /usr/app/front
В линуксе контейнера будут созданы те же стандартные папки, что и в других линуксах — /opt, /home, /etc, /usr и проч. Мы задаём рабочую директорию, с которой будем работать — /usr/app/front.
EXPOSE 3000
Открываем порт 3000. Дальнейшая связь с приложением, запущенным в контейнере, будет происходить через этот порт.
COPY ./ ./
Копируем содержимое исходного проекта в рабочую папку контейнера.
RUN npm install
Устанавливаем все пакеты, необходимые для запуска приложения.
CMD ["npm", "start"]
Запускаем приложение командой npm start.
Именно этот сценарий будет выполнен в нашем приложении при запуске контейнера.
Давайте сразу соберём фронт. Для этого нужно в терминале, находясь в корневой папке проекта (там, где находится Dockerfile), выполнить команду:
docker build -t rebounder-chain-frontend .
Значения команд:
docker — вызов приложения docker, ну, это вы знаете.
build — сборка образа из целевых материалов.
-t <имя> — в дальнейшем, приложение будет доступно по тегу, указанному здесь. Можно не указывать, тогда Docker сгенерирует собственный тег, но отличить его от других будет невозможно.
. — указывает, что собирать проект нужно именно из текущей папки.
В результате, сборка должна закончиться текстом:
Step 7/7 : CMD ["npm", "start"] ---> Running in ee0e8a9066dc Removing intermediate container ee0e8a9066dc ---> b208c4184766 Successfully built b208c4184766 Successfully tagged rebounder-chain-frontend:latest
Если мы видим, что последний шаг выполнен и всё Successfull, значит, образ у нас есть. Мы можем проверить это, запустив его:
docker run -p 8080:3000 rebounder-chain-frontend
Смысл этой команды, я думаю, в целом понятен, за исключением записи -p 8080:3000.
docker run rebounder-chain-frontend — означает, что мы запускаем такой-то докер-образ, который мы обозвали rebounder-chain-frontend. Но такой контейнер не будет иметь выхода наружу, ему нужно задать порт. Именно команда ниже его задаёт. Мы помним, что наше React-приложение запускается на порте 3000. Команда -p 8080:3000 указывает докеру, что нужно взять порт 3000 и пробросить его на порт 8080 (который будет открыт). Таким образом, приложение, которое работает по порту 3000, будет открыто по порту 8080, и на локальной машине будет доступно именно по этому порту.
Итак, что мы видим при запуске команды выше: Mac-mini-Vaceslav:rebounder-chain-frontend xpendence$ docker run -p 8080:3000 rebounder-chain-frontend > rebounder-chain-frontend@0.1.0 start /usr/app/front > react-scripts start Starting the development server... Compiled successfully! You can now view rebounder-chain-frontend in the browser. Local: http://localhost:3000/ On Your Network: http://172.17.0.2:3000/ Note that the development build is not optimized. To create a production build, use npm run build.
Пусть вас не смущает запись
Local: http://localhost:3000/ On Your Network: http://172.17.0.2:3000/
Так думает React. Он действительно доступен в пределах контейнера по порту 3000, но мы пробросили этот порт на порт 8080, и из контейнера приложение работает по порту 8080. Можете запустить приложение локально и проверить это.
Итак, у нас есть готовый контейнер с фронтенд-приложением, теперь давайте соберём бэкенд.
Сборка back-end.
Сценарий запуска приложения на Java существенно отличается от предыдущей сборки. Он состоит из следующих пунктов:
- Устанавливаем JVM.
- Собираем jar-архив.
- Запускаем его.
В Dockerfile этот процесс выглядит так:
# back # устанавливаем самую лёгкую версию JVM FROM openjdk:8-jdk-alpine # указываем ярлык. Например, разработчика образа и проч. Необязательный пункт. LABEL maintainer="2262288@gmail.com" # указываем точку монтирования для внешних данных внутри контейнера (как мы помним, это Линукс) VOLUME /tmp # внешний порт, по которому наше приложение будет доступно извне EXPOSE 8099 # указываем, где в нашем приложении лежит джарник ARG JAR_FILE=build/libs/rebounder-chain-backend-0.0.2.jar # добавляем джарник в образ под именем rebounder-chain-backend.jar ADD ${JAR_FILE} rebounder-chain-backend.jar # команда запуска джарника ENTRYPOINT ["java","-jar","/rebounder-chain-backend.jar"]
Процесс сборки образа с включением джарника по некоторым пунктам напоминает таковой для нашего фронта.
Процесс сборки и запуска второго образа принципиально ничем не отличается от сборки и запуска первого.
docker build -t rebounder-chain-backend . docker run -p 8099:8099 rebounder-chain-backend
Теперь, если у Вас запущены оба контейнера, а бэкенд подключён к БД, всё заработает. Напоминаю, что подключение к БД из бэкенда Вы должны прописать сами, и оно должно работать через внешнюю сеть.
3. Собираем образы и запускаем контейнеры на удалённом сервере
Для того, чтобы всё заработало на удалённом сервере, нам необходимо, чтобы на нём был уже установлен Docker, после чего, достаточно запустить образы. Мы пойдём правильным путём и закоммитим наши образы в свой аккаунт в облаке Docker, после чего, они станут доступны из любой точки мира. Конечно, альтернатив данному подходу, как и всему, что описано в посте, предостаточно, но давайте ещё немного поднажмём и сделаем свою работу хорошо. Плохо, как говорил Андрей Миронов, мы всегда успеем сделать.
Создание аккаунта на хабе Docker
Первое, что Вам предстоит сделать — это обзавестись аккаунтом на хабе Docker. Для этого надо перейти на хаб и зарегаться. Это несложно.
Далее, нам нужно зайти в терминал и авторизоваться в Docker.
docker login
Вас попросят ввести логин и пароль. Если всё ок, в терминале появится уведомление, что Login Succeeded.
Коммит образов на Docker Hub
Далее, мы должны пометить наши образы тэгами и закоммитить их в хаб. Делается это командой по следующей схеме:
docker tag имя образа логин/имя_образа:версия
Таким образом, нам нужно указать имя нашего образа, логин/репозиторий и тэг, под которым наш образ будет закоммичен в хаб.
В моём случае, это выглядело так:
Мы можем проверить наличие данного образа в локальном репозитории при помощи команды:
Mac-mini-Vaceslav:rebounder-chain-backend xpendence$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE xpendence/rebounder-chain-backend 0.0.2 c8f5b99e15a1 About an hour ago 141MB
Наш образ готов к коммиту. Коммитим:
docker push xpendence/rebounder-chain-backend:0.0.2
Должна появиться запись об успешном коммите.
Делаем то же самое с фронтендом:
docker tag rebounder-chain-frontend xpendence/rebounder-chain-frontend:0.0.1 docker push xpendence/rebounder-chain-frontend:0.0.1
Теперь, если мы зайдём на hub.docker.com, мы увидим два закоммиченных образа. Которые доступны откуда угодно.
Поздравляю. Нам осталось перейди к заключительной части нашей работы — запустить образы на удалённом сервере.
Запускаем образы на удалённом сервере
Теперь мы можем запустить наш образ на любой машине с Docker, выполнив всего одну строчку в терминале (в нашем случае, нам надо последовательно выполнить две строчки в разных терминалах — по одной на каждый образ).
docker run -p 8099:8099 xpendence/rebounder-chain-backend:0.0.2 docker run -p 8080:3000 xpendence/rebounder-chain-frontend:0.0.1
У такого запуска есть, правда, один минус. При закрытии терминала процесс завершится и приложение прекратит работу. Чтобы этого избежать, мы можем запустить приложение в «откреплённом» режиме:
docker run -d -p 8099:8099 xpendence/rebounder-chain-backend:0.0.2 docker run -d -p 8080:3000 xpendence/rebounder-chain-frontend:0.0.1
Теперь приложение не будет выдавать лог в терминал (это можно, опять же, настроить отдельно), но и при закрытии терминала оно не прекратит свою работу.
4. Решаем проблемы с сетью
Если Вы всё сделали правильно, Вас, возможно, ожидает самое большое разочарование на всём пути следования этому посту — вполне может так получиться, что ничего не работает. Например, у Вас всё великолепно собралось и заработало на локальной машине (как, например, у меня на маке), но при развёртывании на удалённом сервере контейнеры перестали друг друга видеть (как, например, у меня на удалённом сервере на Linux). В чём проблема? А проблема вот в чём, и я в начале о ней намекал. Как уже было сказано раньше, при запуске контейнера Docker создаёт отдельную виртуальную машину, накатывает туда Linux, и потом в этот Linux устанавливает приложение. Это значит, что условный localhost для запущенного контейнера ограничивается самим контейнером, и о существовании других сетей приложение не подозревает. Но нам нужно, чтобы:
а) контейнеры видели друг друга.
б) бэкенд видел базу данных.
Решения проблемы два.
1. Создание внутренней сети.
2. Вывод контейнеров на уровень хоста.
1. На уровне Docker можно создавать сети, причём, три из них в нём есть по умолчанию — bridge, none и host.
Bridge — это внутренняя сеть Docker, изолированная от сети хоста. Вы можете иметь доступ к контейнерам только через те порты, которые открываете при запуске контейнера командой -p. Можно создавать любое количество сетей типа bridge.
None — это отдельная сеть для конкретного контейнера.
Host — это сеть хоста. При выборе этой сети, Ваш контейнер полностью доступен через хост — здесь попросту не работает команда -p, и если Вы развернули контейнер в этой сети, то Вам незачем задавать внешний порт — контейнер доступен по своему внутреннему порту. Например, если в Dockerfile EXPOSE задан как 8090, именно через этот порт будет доступно приложение.
Поскольку нам нужно иметь доступ к базе данных сервера, мы воспользуемся последним способом и выложим контейнеры в сеть удалённого сервера.
Делается это очень просто, мы убираем из команды запуска контейнера упоминание о портах и и указываем сеть host:
docker run --net=host xpendence/rebounder-chain-frontend:0.0.8
Подключение к базе я указал
localhost:3306
Подключение фронта к бэку пришлось указать целиком, внешнее:
http://<хост_удалённого_сервера:порт_удалённого_сервера>
Если вы пробрасываете внутренний порт на внешний, что часто бывает для удалённых серверов, то для базы нужно указывать внутренний порт, а для контейнера — внешний порт.
Если Вы хотите поэкспериментировать с подключениями, вы можете скачать и собрать проект, который я специально написал для тестирования соединения между контейнерами. Просто вводите необходимый адрес, жмёте Send и в режиме отладки смотрите, что прилетело обратно.
Проект лежит тут.
Заключение
Есть масса способов собрать и запустить образ Docker. Интересующимся советую изучить docker-compose. Здесь мы разобрали лишь один из способов работы с докером. Конечно, такой подход поначалу кажется не таким уж и простым. Но вот пример — в ходе написания поста у меня возникли с исходящими подключениями на удалённом сервере. И в процессе дебага мне пришлось несколько раз менять настройки подключения к БД. Вся сборка и деплой умещались у меня в набор 4 строчек, после ввода которых я видел результат на удалённом сервере. В режиме экстремального программирования Docker окажется незаменим.
Как и обещал, выкладываю исходники приложений:
backend
frontend

