Предыстория
За последние пару лет я поучаствовал в немалом количестве собеседований. На каждом из них я спрашивал соискателей о принципе единственной ответственности(далее SRP). И большинство людей о принципе ничего не знают. И даже из тех, кто мог зачитать определение, почти никто не мог сказать как они используют этот принцип в своей работе. Не могли сказать, как SRP влияет на код, который они пишут или на ревью кода коллег. Некоторые из них также имели заблуждение, что SRP, как и весь SOLID, имеет отношение только к объектно ориентированному программированию. Также, зачастую люди не могли определить явные случаи нарушения этого принципа, просто потому что код был написан в стиле, рекомендованном известным фреймворком.
Redux — яркий пример фреймворка, гайдлайн которого нарушает SRP.
SRP имеет значение
Хочу начать с ценности этого принципа, с пользы которую он несет. А также хочу отметить, что принцип распространяется не только на ООП, но и на процедурное программирование, функциональное и даже декларативное. HTML, как представителя последнего тоже можно и нужно декомпозировать, тем более сейчас, когда он управляется UI-фреймворками, такими как React или Angular. Кроме этого принцип распространяется и на другие инженерные области. И не только инженерные, было такое выражение в военной тематике: «divide and conquer», что по большому счету воплощение того же принципа. Сложность убивает, раздели ее на части и ты победишь.
Касательно же других инженерных областей, здесь, на хабре, была интересная статья о том как у разрабатываемого самолета отказали двигатели, не перешли на реверс по команде пилота. Проблема была в том, что они неверно интерпретировали состояние шасси. Вместо того, чтобы полагаться на системы контролирующие шасси, контроллер двигателя напрямую считывал датчики, концевики и пр. находящиеся в шасси. Также в статье было упомянуто, что двигатель должен проходить длительную сертификацию до того как его поставят даже на прототип самолета. И нарушение SRP в данном случае явно приводило к тому, что при изменении конструкции шасси, код в контроллере двигателя нужно было модифицировать и заново проходить сертификацию. Хуже того, нарушение этого принципа чуть было не стоило самолета и жизни пилота. К счастью наше обыденное программирование не грозит такими последствиями, однако пренебрегать принципами написания хорошего кода все равно не стоит. И вот почему:
- Декомпозиция кода уменьшает его сложность. К примеру если решение задачи требует от вас написать код c цикломатической сложностью равной четырем, то метод несущий ответственность за решение двух таких задач одновременно потребует кода со сложностью 16. Если же это разделить на два метода, то суммарная сложность будет 8. Конечно это не всегда сводится к сумме против произведения, однако тенденция будет примерно такая в любом случае.
- Unit-тестирование декомпозированого кода упрощается и становится более эффективным.
- Декомпозированый код создает меньше сопротивления изменениям. При внесении изменений меньше вероятность внести ошибку.
- Код становится лучше структурирован. Искать что-то в коде разложеном по файлам и папкам намного легче чем в одной большой портянке.
- Отделение boilerplate кода от бизнес логики приводит к тому, что в проекте можно применить кодогенерацию.
И все эти признаки идут вместе, это признаки одного и того же кода. Вам не нужно выбирать между, например, хорошо тестируемым кодом и хорошо структурированым.
Существующие определения не работают
Одно из определений звучит так: «должна быть только одна причина, для изменения кода (класса или функции)». Проблема этого определения в том, что оно конфликтует с Open-Close принципом, вторым из группы принципов SOLID. Его определение: «код должен быть открыт для расширения и закрыт для изменения». Одна причина для изменения против полного запрета на изменения. Если подробнее раскрыть то что тут подразумевается, то окажется, что между принципами конфликта нет, однако между нечеткими определениями конфликт определенно есть.
Второе, более прямое определение звучит так: «у кода должна быть только одна ответственность». Проблема этого определения в том, что человеку свойственно все обобщать.
К примеру есть ферма, выращивающая куриц, и в этот момент у фермы только одна ответственность. И вот принимается решение разводить там еще и уток. Инстинктивно мы назовем это фермой для домашней птицы, нежели признаем, что там теперь стало две ответственности. Добавим туда овец, и это теперь ферма для домашних животных. Потом захотим выращивать там помидоры или грибы, и придумаем следующее еще более обобщенное название. Это же распространяется на «одну причину» для изменения. Эта причина может быть настолько обобщенной, насколько хватает фантазии.
Еще один пример это класс управляющий космической станцией. Он же ничего больше не делает, только космической станцией управляет. Как вам такой класс с одной ответственностью?
И, поскольку я упомянул Redux, когда соискатель знаком с этой технологией, я также задаю вопрос, а не нарушает ли типичный редюсер SRP?
Редюсер, напомню, включает в себя оператор switch, и случается что он разрастается до десятков а то и сотен case-ов. И единственная ответственность редюсера — управлять переходами состояния вашего приложения. Именно так, дословно, отвечали некоторые соискатели. И никакие намеки не могли сдвинуть это мнение с мертвой точки.
Итого, если какой то код вроде бы удовлетворяет принципу SRP, но при этом неприятно «пахнет» — знайте почему так происходит. Потому что определение «у кода должна быть одна ответственность» просто не работает.
Более подходящее определение
Из проб и ошибок у меня родилось определение получше:
Ответственность кода не должна быть слишком большой
Да, теперь нужно «измерять» ответственность у класса или функции. И если она слишком велика, то нужно эту большую ответственность разбить на несколько ответственностей меньшего размера. Возвращаясь к примеру с фермой, даже отвественность по разведению куриц может оказаться слишком большой и имеет смысл как то разделить бройлеров от несушек, например.
Но как ее померить, как определить что ответственность данного кода слишком большая?
К сожалению у меня нет математически точных методов, есть только эмпирические. И больше всего это приходит с опытом, начинающие разработчики совсем не умеют декомпозировать код, более продвинутые все лучше владеют этим, хоть и не всегда могут описать зачем они это делают и как это ложится на теории вроде SRP.
- Метрика cyclomatic complexity. К сожалению есть способы эту метрику маскировать, однако если вы ее будете собирать, то есть вероятность, что она покажет самые уязвимые места вашего приложения.
- Размер функций и классов. Функцию из 800 строк не нужно читать, чтобы понять, что с ней что то не так.
- Много импортов. Однажды я открыл файл в проекте соседней команды и увидел целый экран импортов, нажал page down и опять на экране были только импорты. Только после второго нажатия я увидел начало кода. Вы можете сказать, что все современные IDE умеют скрывать импорты под «плюсик», я же говорю, что хороший код не нуждается в сокрытии «запахов». Кроме этого, мне понадобилось переиспользовать небольшой кусочек кода и я вынес его из этого файла в другой, и за этим кусочком переехала четверть, а то и треть импортов. Этому коду явно было там не место.
- Модульные тесты. Если у вас все еще есть трудности с определением размера ответственности, заставьте себя написать тесты. Если на основное назначение функции нужно написать два десятка тестов, не считая пограничных случаев и т.д., значит нужна декомпозиция.
- То же относится к слишком большому числу подготовительных действий в начале теста и проверкам в конце. В интернете, кстати, можно встретить утопическое утверждение, что т.н. assert в тесте вообще должен быть только один. Я же считаю, что любая сколь угодно хорошая идея, будучи возведенной в абсолют, может стать до абсурдного непрактичной.
- Бизнес логика не должна напрямую зависеть от внешних инструментов. Драйвер Oracle, роуты Express-а, все это желательно отделить от бизнес логики и/или спрятать за интерфейсами.
Пара моментов:
Конечно, как я уже упомянул, есть оборотная сторона медали, и 800 методов по одной строчке может быть не лучше, чем один метод на 800 строк, во всем должен быть баланс.
Второе — я не освещаю вопрос куда положить тот или иной код в соответствии с его отвественностью. К примеру, иногда у разработчиков также возникают трудности с тем, что они тянут слишком много логики в DAL слой.
Третье — я не предлагаю каких либо конкретных жестких ограничений вроде «не более 50 строк на функцию». Данный подход предполагает лишь направление для развития разработчиков, и может быть, команд. Он работает у меня, должен заработать и для других.
И последнее, если вы будете проходить через TDD, одно только это наверняка заставить вас декомпозировать код задолго до того, как вы напишете те 20 тестов по 20 assert-ов в каждом.
Отделение бизнес логики от boilerplate кода
Разговаривая о правилах хорошего кода нельзя не обойтись без примеров. Первый пример посвящен отделению boilerplate кода.
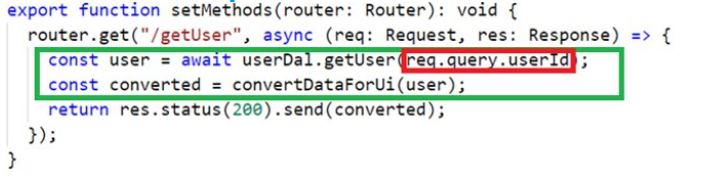
Этот пример демонстрирует то, как обычно пишут back-end код. Люди обычно пишут логику неотрывно от кода указывающего Web-серверу Express такие параметры как URL, метод запроса и т.д.
Зеленым маркером я обозначил собственно бизнес-логику, а красным — инородное вкрапление кода, взаимодействующего с параметрами запроса (query string).
Я же всегда разделяю эти две ответственности таким образом:

В этом примере все взаимодействие с Express вынесено в отдельный файл.
На первый взгляд может показаться, что второй пример не принес улучшений, стало 2 файла вместо одного, появились дополнительные строчки, которых до этого не было — имя класса и сигнатура метода. И что же тогда такое разделение кода дает? В первую очередь — «точка входа приложения» теперь не Express. Теперь это обычная Typescript функция. Или javascript функция, ли C#, кто на чем пишет WebAPI.
Это в свою очередь позволяет совершать различные действия, недоступные в первом примере. Например вы можете писать behavior-тесты без необходимости поднимать Express, без использования http запросов внутри теста. И даже нет необходимости производить какое либо мокирование, подменять Router объект своим «тестовым» объектом, теперь код приложения можно просто вызвать из теста напрямую.
Еще одна интересная возможность, которую дает такая декомпозиция — теперь можно написать генератор кода, который будет парсить userApiService и на его основе генерировать код, связующий этот сервис с Express. В своих будущих публикациях я планирую обозначить следующее: кодогенерация не сбережет время в процессе написания кода. Затраты на кодогенератор не окупятся тем, что теперь не нужно копипастить этот boilerplate. Кодогенерация окупится тем, что код ей произведенный не нуждается в поддержке, что сэкономит время и главное — нервы разработчиков в долговременной перспективе.
Divide and conquer
Этот метод написания кода существует давно, я не придумывал его сам. Я лишь пришел к тому, что он очень удобен при написании бизнес логики. И для этого я придумал еще один вымышленный пример, показывающий как можно быстро и легко писать код, который сразу хорошо декомпозирован, а также самодокументирован посредством именования методов.
Скажем, вы получаете от бизнес-аналитика задачу сделать метод, отправляющий отчет о сотрудниках в страховую компанию. Для этого:
- Данные нужно взять из БД
- Преобразовать в нужный формат
- Отправить получившийся отчет
Не всегда такие требования пишут явно, иногда такая последовательность может подразумеваться или выясниться из разговора с аналитиком. В процессе реализации метода не бросайтесь открывать соединения с базой данных или сетью, вместо этого попробуйте транслировать этот простой алгоритм в код «как есть». Примерно так:
async function sendEmployeeReportToProvider(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await networkService.sendReport(formatted); }
С таким подходом получается достаточно простой, легко читаемый и тестируемый код, хотя я и считаю, что этот код тривиален и в тестировании не нуждается. И ответственнось этого метода не отправлять отчет, его ответственность — разбиение этой сложной задачи на три подзадачи.
Далее, возвращаемся к требованиям и узнаём что отчет должен состоять из зарплатной секции и секции с отработанными часами.
function prepareEmployeeReport(reportData){ const salarySection = prepareSalarySection(reportData); const workHoursSection = prepareWorkHoursSection(reportData); return { salarySection, workHoursSection }; }
И так и дальше продолжаем разбивать задачу до тех пор пока не останется реализация маленьких методов, близких к тривиальным.
Взаимодействие с Open-Close принципом
Вначале статьи я рассказал, что определения принципов SRP и Open-Close противоречат друг другу. Первый говорит, что должна быть одна причина для изменения, второй говорит, что код должен быть закрыт для изменения. А сами принципы, не только не противоречат друг другу, наоборот, они работают в синергии друг с другом. Все 5 принципов SOLID направлены на одну благую цель — указать разработчику какой код «плохой», и как можно его поменять чтобы он стал «хороший». Ирония — я только что подменил 5 ответственностей на одну ответсвенность побольше.
Итак, в дополнение к предыдущему примеру с отсылкой отчета в страховую компанию, представим, что к нам приходит бизнес аналитик и говорит, что теперь нужно добавить вторую функциональность в проект. Этот же отчет нужно выводить на печать.
Представим, что нашелся разработчик, который считает, что SRP «не про декомпозицию».
Соответственно ему этот принцип не указал на на необходимость декомпозиции, и он реализовал всю первую задачу в одной функции. После того, как ему пришла задача, он, объединяет две отвественности в одну, т.к. между ними много общего и обобщает ее название. Теперь эта ответственность называется «обслужить отчет». Реализация этого выглядит примерно так:
async function serveEmployeeReportToProvider(reportId, serveMethod){ /* lots of code to read and convert the report */ switch(serveMethod) { case sendToProvider: /* implementation of sending */ case print: /* implementation of printing */ default: throw; } }
Напоминает какой то код в вашем проекте? Как я уже говорил, оба прямых определения SRP не работают. Не передают разработчику информации о том, что такой код писать нельзя. И на то какой код писать можно. Для разработчика по прежнему осталась всего одна причина, для того, чтобы изменить этот код. Он просто переобозвал предыдущую причину, добавил switch и спокоен. И тут на сцену выходит принцип Open-Close принцип, который прямо говорит, что изменять уже существующий файл было нельзя. Надо было писать код так, чтобы при добавлении новой функциональности нужно было добавить новый файл, а не править уже существующий. То есть такой код плох с точки зрения сразу двух принципов. И если первый не помог это увидеть, второй должен помочь.
И как решает эту же задачу метод «divide and conquer»:
async function printEmployeeReport(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await printService.printReport(formatted); }
Добавляем новую функцию. Я их иногда еще называю «функция-сценарий», потому что они не несут реализации, они определяют последовательность вызова декомпозированных кусочков нашей ответственности. Очевидно, первые две строчки, первые две декомпозированные ответственности совпадают с первыми двумя строчками реализованной ранее функции. Точно также как совпадают первые два шага двух описанных бизнес аналитиком задач.
Таким образом для добавления новой функциональности в проект мы добавили новый метод сценарий и новый printService. Старые файлы изменению не подверглись. То есть этот метод написания кода хорош сразу с позиции двух принципов. И SRP и Open-Close
Альтернатива
Также я хотел упомянуть альтернативный, конкурирующий способ получать хорошо декомпозированный код, который выглядит примерно так — сначала пишем код «в лоб», затем рефакторим его используя различные приемы, например по книге Фаулера «Рефакторинг». Эти методы напомнили мне математический подход к игре в шахматы, где вы не понимаете что именно вы делаете с точки зрения стратегии, вы лишь вычисляете «вес» вашей позиции и пытаетесь максимизировать его делая ходы. Мне этот подход не нравился по одной небольшой причине — именовать методы и переменные и без того сложно, а когда у них нет бизнес-значения это становится невозможным. К примеру если эти методики подсказывают, что нужно выделить 6 одинаковых строк отсюда и оттуда, то выделив их, как назвать этот метод? someSixIdenticalLines()?
Хочу оговориться — я не считаю этот метод плохим, я лишь не смог приучиться его использовать.
Итого
В следовании приципу можно найти выгоду.
Определение «должна быть одна ответственность» — не работает.
Есть определение получше и ряд косвенных признаков, т.н. code smells, сигнализирующих о необходимости декомпозировать.
Подход «divide and conquer» позволит сразу писать хорошо структурированый и самодокументированый код.

