Ну что ж, мы уже знаем всё, что нужно для программирования UDB. Но одно дело – знать, и совсем другое – уметь. Поэтому сегодня мы обсудим, где и как можно черпать вдохновение для повышения собственного мастерства, где набираться опыта. Как видно из перевода документации, там есть сухие знания, которые даже не всегда привязаны к реальной практике (я заострил на этом внимание в достаточно пространном примечании, к последнему на сегодняшний день переводу). Собственно, статистика просмотров статей показывает, что переводы читает всё меньше и меньше людей. Было даже предложение прервать этот цикл, как неинтересный, но осталось всего две части, поэтому, в конце концов, просто было решено снизить темп их подготовки. В общем, документация на контроллер – штука нужная, но не самодостаточная. Где же ещё черпать вдохновение?

В первую очередь, могу порекомендовать отличный документ AN82156 Designing PSoC Creator Components with UDB Datapaths. В нём вы найдёте типовые решения, а также несколько типовых проектов. Причём в начале документа разработка идёт при помощи UDB Editor, а ближе к концу – при помощи Datapath Config Tool, то есть, документ охватывает все аспекты разработки. Но к сожалению, глядя на цену одной микросхемы PSoC, я бы сказал, что если она может решить только вопросы, описанные в этом документе, то контроллер сильно переоценен. ШИМы и стандартные последовательные порты можно делать и без PSoC. К счастью, диапазон решаемых PSoC задач намного шире. Поэтому, закончив чтение AN82156, начинаем искать иные источники вдохновения.
Следующий полезный источник – примеры, которые прилагаются к PSoC Creator. Я уже ссылался на них в примечании к одной из частей перевода фирменной документации (можно посмотреть здесь). Они хранятся примерно здесь (диск может отличаться):
E:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\psoc\content\CyComponentLibrary.
Искать следует файлы *.v, то есть, verilog тексты, либо *.vhd, так как синтаксис языка VHDL требует описывать чуть больше, и на этом языке иногда можно найти интересные нюансы, скрытые от глаз программиста на Verilog. Вся беда в том, что это всё-таки не примеры, а готовые решения. Это замечательно, они отлично отлажены, но у нас, простых программистов, с программистами фирмы Cypress разные цели. Наша задача – сделать что-то вспомогательное за короткий срок, после чего начать его использование в своих проектах, на которые основное время и будет потрачено. Оно должно идеально решать поставленные перед нами сегодня задачи, а если мы завтра захотим вставить этот же код в другой проект, где всё будет слегка отличаться, то завтра мы его под ту ситуацию и доточим. У разработчиков же Cypress компонент – это конечный продукт, поэтому основное время они могут потратить на него. И они должны предусмотреть всё-всё-всё. Так что, когда я смотрел эти тексты, мне становилось грустно. Они слишком сложны для того, кто только что начал искать, где бы почерпнуть вдохновения для своих первых разработок. А вот как справочники эти тексты вполне годятся. В них встречается много ценных конструкций, нужных при создании собственных вещей.
Также там есть очень интересные уголки. Например, имеются, сейчас я скажу в стиле «масло масляное», модели для моделирования (давным-давно один суровый преподаватель отбил у меня охоту переводить simulation как-то иначе, чем «моделирование»). Их можно найти в каталоге
E:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\warp\lib\sim.
Самый интересный для программиста на Верилоге каталог – это:
E:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\warp\lib\sim\presynth\vlg.
Описание компонентов в документации – это хорошо. Но здесь описаны поведенческие модели для всех стандартных компонентов. Иногда это лучше, чем документация (которая написана тяжёлым языком, плюс в ней опущены некоторые существенные детали). Когда непонятно поведение того или иного компонента, стоит начинать попытки понять его именно с просмотра файлов из этого каталога. Я сначала пытался искать на Гугле, но очень часто встречал на найденных форумах только рассуждения и никакой конкретики. Здесь же имеется именно конкретика.
Но тем не менее, справочник – это замечательно, а где искать учебник, на чём же учиться? Честно говоря, особо и не на чем. Хороших готовых примеров для UDB Editor вообще мало. Мне страшно повезло, что когда я вдруг решил поиграть в RGB светодиоды, мне попался красивый пример именно под UDB Editor (о нём я писал в статье, с которой начался весь цикл). Но если много работать поисковиком, то примеры для Datapath Config Tool всё-таки найдутся, именно поэтому я и сделал предыдущую статью, чтобы все понимали, как этим инструментом пользоваться. И замечательная страничка, на которой собрана масса примеров, расположена тут.
На этой странице лежат разработки, сделанные сторонними разработчиками, но проверенные фирмой Cypress. То есть, как раз то, что нам нужно: мы же тоже сторонние разработчики, но хотим учиться на чём-то, что точно проверено. Давайте рассмотрим пример, благодаря которому я нашёл эту страницу, – аппаратный вычислитель квадратного корня. Конечные пользователи включают его в тракт обработки сигнала, бросая компонент на схему. На этом примере мы натренируемся анализировать подобный код, а дальше каждый уже сможет пуститься в самостоятельное плавание. Итак, нужный пример может быть скачан по ссылке.
Осматриваем его. Там есть примеры (которые каждый рассмотрит самостоятельно) и есть – библиотеки, расположенные в каталоге \CJCU_SquareRoot\Library\CJCU_SquareRoot.cylib.
Для каждого типа (целочисленный или с фиксированной точкой) и для каждой разрядности имеется своё решение. Это нам следует отметить. Универсальность хороша при разработке в UDB Editor, но при разработке с использованием Datapath Edit Tool, как видим, люди мучаются вот так. Не стоит пугаться, если у вас не получится универсально (но если получится – тем лучше).
На верхнем уровне (схемотехническом) я останавливаться не буду, мы же изучаем не работу с PSoC, а работу с UDB. Давайте посмотрим вариант средней сложности – 16 битный, но целочисленный. Он расположен в каталоге CJCU_B_Isqrt16_v1_0.
Первое, что стоит сделать, это раскрыть граф переходов микропрограммного автомата. Без него мы даже не догадаемся, какой именно алгоритм вычисления квадратного корня применён, так как Гугл предлагает на выбор несколько принципиально разных алгоритмов.

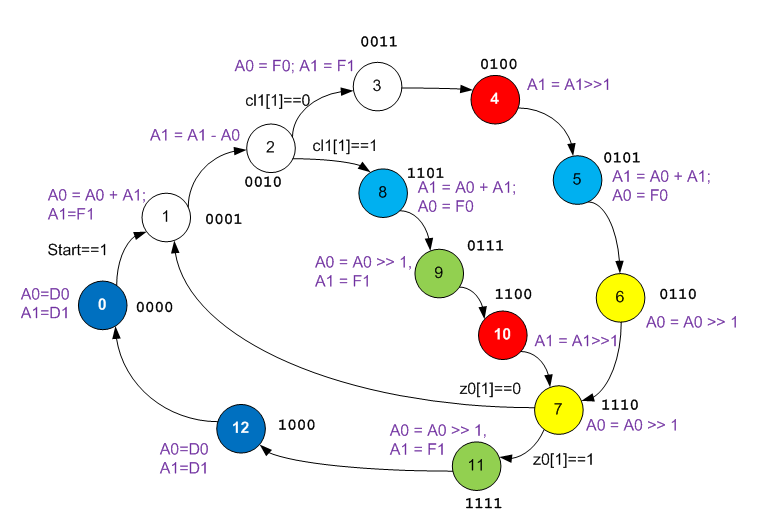
Пока что ничего не понятно, но это предсказуемо. Надо добавить больше информации. Смотрим на кодирование состояний. Бросается в глаза, что они закодированы не в обычном нарастающем двоичном коде.

Я уже упоминал о таком подходе в своих статьях, но ни разу не доводилось его использовать в конкретных примерах. Напомню, что у ОЗУ динамической конфигурации АЛУ имеется всего три адресных входа. То есть АЛУ может выполнять одну из восьми операций. Если состояний у автомата больше, то правило «на каждое состояние своя операция» становится невыполнимо. Поэтому выбираются состояния, в которых операции для АЛУ идентичны, у них три бита, подаваемых на адрес ОЗУ динамической конфигурации (обычно – младших), кодируются одинаково, а остальные – по-разному. Как сложить такой пасьянс – это уже проблемы разработчика. Разработчики изучаемого кода сложили именно так, как показано выше.
Добавим эту информацию на граф, плюс покрасим в сходные цвета состояния, выполняющие одну и ту же функцию в АЛУ.

Никаких закономерностей пока не проявилось, но продолжаем раскрывать граф. Открываем Datapath Edit Tool и изучаем логику уже в нём.
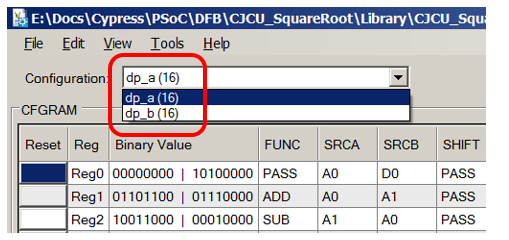
Обращаем внимание на то, что у нас имеется два блока Datapath, соединённые в цепочку. Когда мы будем делать что-то своё, нам тоже может понадобиться такое (правда, Datapath Edit Tool может создавать уже объединённые в цепочку блоки, так что это не страшно):
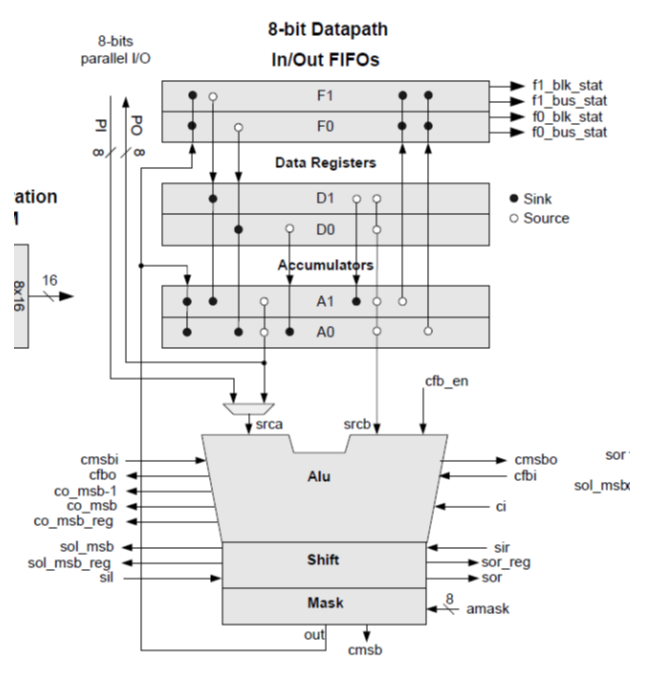
При чтении (да и при заполнении) граф, соответствующих АЛУ, всегда открываем документ с таким рисунком:
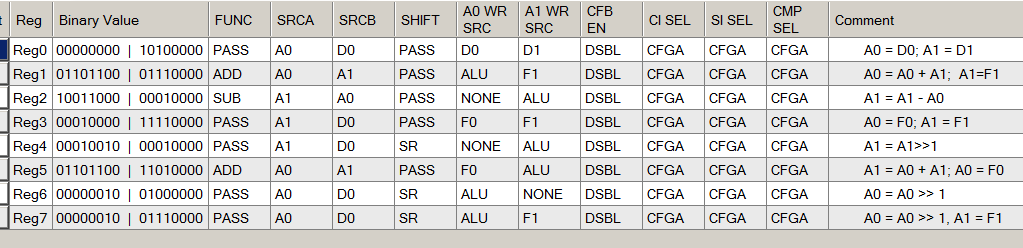
Правда, разработчики данного примера позаботились о нас и заполнили поля комментариев. Сейчас мы можем воспользоваться ими, чтобы понять, что зачем настроено. Заодно отмечаем для себя, что писать комментарии всегда полезно как для тех, кто будет сопровождать код, так и для нас, когда через полгода мы всё о нём забудем.
Смотрим код X000, соответствующий состояниям 0 и 12:

Из комментария уже ясно, что там к чему (в регистр A0 копируется содержимое регистра D0, а в регистр A1 копируется содержимое D1. Зная это, тренируем свою интуицию на будущее и находим аналогичную запись в полях настройки:

Там же видим, что АЛУ работает в режиме PASS, регистр сдвига – тоже PASS, так что никаких иных действий действительно не выполняется.
Попутно заглядываем в Verilog текст и видим там, чему равняется значение регистров D0 и D1:

При желании, то же самое можно посмотреть и в Datapath Config Tool, выбрав меню View->Initial Register Values:


Для просмотра удобнее прямой анализ Verilog кода, для создания своего варианта — работа через редактор, чтобы не держать в голове синтаксис.
Аналогично разбираем (сначала подглядывая в комментарии) все остальные функции АЛУ:
Переделываем граф переходов автомата с учётом новых знаний:
Что-то уже вырисовывается, но пока что я не могу с уверенностью положить на этот граф ни один из найденных Гуглом алгоритмов. Вернее, про некоторые можно уверенно сказать, что это не они, но даже на правдоподобные до конца ещё не могу дать уверенный ответ, что это именно они. Смущает активное использование регистров FIFO F0 и F1. Вообще, в файле
\CJCU_SquareRoot\Library\CJCU_SquareRoot.cylib\CJCU_Isqrt_v1_0\API\CJCU_Isqrt.c
видно, что F1 используется для передачи аргумента и возврата результата:

Но один аргумент и один результат. А зачем так много обращений к FIFO по ходу работы? И при чём тут FIFO0? Режьте меня на куски, а кажется, что авторы воспользовались режимом, который встречался в переводах документации, когда вместо полноценного FIFO этот блок выступал в виде одиночного регистра. Допустим, авторы решили расширить регистровый набор. Если это так, то их методика нам пригодится при нашей практической работе, давайте изучать детали. На самом деле, документация рассказывает про разные подходы к работе с FIFO. Можно — так, можно – так, а можно – эдак. И никакой конкретики. Снова у нас есть шанс изучить передовой зарубежный практический опыт. Что с FIFO делают авторы?
Во-первых, вот такие присвоения сигналов:
Во-вторых, вот такое подключение к Datapath:
Из описания контроллера особо не ясно, что всё это значит. Но из Application Note я выяснил, что во всём виновата вот эта настройка:

Кстати, именно из-за этой настройки данный блок невозможно описать при помощи UDB Editor. Когда эти управляющие биты находятся в состоянии ON, FIFO может работать на разные источники и приёмники. Если Dx_LOAD равен единице, то Fx обменивается с системной шиной, если нулю, то с регистром, выбранным здесь:

Получается, что F0 всегда обменивается с регистром A0, а F1 в состояниях 12 и 0 — с системной шиной (для выгрузки результата и загрузки аргумента), в остальных состояниях – с A1.
Дальше, из Verilog кода, мы выяснили, что в F0 данные будут загружены в состояниях 1 и 4, а в F1 – в состояниях 1, 3, 9, 11.
Добавим полученные знания на граф. Чтобы избежать путаницы при последовательности выполнения операций, также пришла пора заменить знак присвоения «а-ля UDB Editor» на Верилоговские стрелки, чтобы подчеркнуть, что источником является значение сигнала, которое он имел до входа в блок.

С точки зрения разбора алгоритма, уже всё ясно. Перед нами модификация такого алгоритма:
Только применительно к нашей системе он будет выглядеть, скорее, так:
Состояния 4 и 10 явно кодируют строку:
для разных веток.
Строка же:
явно кодируется либо парой состояний 6 и 7, либо парой состояний 9 и 7. Пока что хочется воскликнуть: «Ну и затейники же авторы!», но очень скоро станет ясно, зачем такая сложность с двумя ветками (в коде на Си же есть ветка и обход).
Состояние 2 кодирует условный переход. Состояние 7 кодирует оператор цикла. Операция сравнения на шаге 2 очень дорогая. Вообще, на большинстве шагов регистр A0 содержит переменную one. Но на шаге 1 переменная one выгружается в F0, а вместо неё загружается значение res + one, затем на шаге 2 производится вычитание с целью сравнения, а на шагах 3 и 8 – восстановление значения one. Зачем на шаге 4 A0 снова копируется в F0, я не понял. Возможно, это какой-то рудимент.
Осталось разобраться, кто здесь res, а кто – op. Мы знаем, что в условии сравниваются op и сумма res+one. В состоянии 1 суммируются A0 (one) и A1. Значит там A1 – это res. Получается, что в состоянии 11 A1 – тоже res, и именно он попадёт в F1, подаваемый на выход функции. F1 в состоянии 1 – это явно op. Предлагаю ввести цветовую дифференциациюштанов переменных. Обозначим res – красным, op – зелёным, а one – коричневым (не совсем контрастно, но остальные цвета ещё менее контрастны).

Собственно, вся правда раскрыта. Мы видим, как A1 лихо временно меняется с F1 для проведения сравнения и вычислений, как одна и та же разность используется и для сравнения (собственно, выработки бита C), так и для участия в формуле. Мы даже видим, зачем пустое место (обход) в алгоритме на Си закодировано длинной веткой графа переходов автомата (в этой ветке производится обмен регистров, идентичный обмену, происходящему в основной ветке кода). Мы всё видим.
Единственный вопрос, который не перестаёт меня мучить, как авторы переключили FIFO в однобайтный режим? Документация гласит, что для этого надо поднять в единицу биты CLR в Auxiliary Control register, но я не вижу, чтобы в API были подобные записи. Возможно, кто-нибудь поймёт это и напишет в комментариях.
Ну, а разрабатывать что-то своё – в обратной последовательности, пользуясь полученными навыками.
Для развития навыков разработки «прошивок» на базе UDB полезно не только читать документацию, но и черпать вдохновение в чужих разработках. Код, прилагаемый к PSoC Creator, может быть полезен, как справочник, а поведенческие модели из поставки компилятора позволят лучше понять, что имелось в виду в документации. Также в статье дана ссылка на набор примеров от сторонних производителей и показан процесс разбора одного из таких примеров.
На этом цикл авторских статей по работе с UDB можно считать завершённым. Буду рад, если кому-либо он помог получить знания, полезные на практике. Впереди ещё пара переводов документации, но статистика показывает, что их уже почти никто не читает. Они запланированы чисто, чтобы не бросать тему на полуслове.
В первую очередь, могу порекомендовать отличный документ AN82156 Designing PSoC Creator Components with UDB Datapaths. В нём вы найдёте типовые решения, а также несколько типовых проектов. Причём в начале документа разработка идёт при помощи UDB Editor, а ближе к концу – при помощи Datapath Config Tool, то есть, документ охватывает все аспекты разработки. Но к сожалению, глядя на цену одной микросхемы PSoC, я бы сказал, что если она может решить только вопросы, описанные в этом документе, то контроллер сильно переоценен. ШИМы и стандартные последовательные порты можно делать и без PSoC. К счастью, диапазон решаемых PSoC задач намного шире. Поэтому, закончив чтение AN82156, начинаем искать иные источники вдохновения.
Следующий полезный источник – примеры, которые прилагаются к PSoC Creator. Я уже ссылался на них в примечании к одной из частей перевода фирменной документации (можно посмотреть здесь). Они хранятся примерно здесь (диск может отличаться):
E:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\psoc\content\CyComponentLibrary.
Искать следует файлы *.v, то есть, verilog тексты, либо *.vhd, так как синтаксис языка VHDL требует описывать чуть больше, и на этом языке иногда можно найти интересные нюансы, скрытые от глаз программиста на Verilog. Вся беда в том, что это всё-таки не примеры, а готовые решения. Это замечательно, они отлично отлажены, но у нас, простых программистов, с программистами фирмы Cypress разные цели. Наша задача – сделать что-то вспомогательное за короткий срок, после чего начать его использование в своих проектах, на которые основное время и будет потрачено. Оно должно идеально решать поставленные перед нами сегодня задачи, а если мы завтра захотим вставить этот же код в другой проект, где всё будет слегка отличаться, то завтра мы его под ту ситуацию и доточим. У разработчиков же Cypress компонент – это конечный продукт, поэтому основное время они могут потратить на него. И они должны предусмотреть всё-всё-всё. Так что, когда я смотрел эти тексты, мне становилось грустно. Они слишком сложны для того, кто только что начал искать, где бы почерпнуть вдохновения для своих первых разработок. А вот как справочники эти тексты вполне годятся. В них встречается много ценных конструкций, нужных при создании собственных вещей.
Также там есть очень интересные уголки. Например, имеются, сейчас я скажу в стиле «масло масляное», модели для моделирования (давным-давно один суровый преподаватель отбил у меня охоту переводить simulation как-то иначе, чем «моделирование»). Их можно найти в каталоге
E:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\warp\lib\sim.
Самый интересный для программиста на Верилоге каталог – это:
E:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\warp\lib\sim\presynth\vlg.
Описание компонентов в документации – это хорошо. Но здесь описаны поведенческие модели для всех стандартных компонентов. Иногда это лучше, чем документация (которая написана тяжёлым языком, плюс в ней опущены некоторые существенные детали). Когда непонятно поведение того или иного компонента, стоит начинать попытки понять его именно с просмотра файлов из этого каталога. Я сначала пытался искать на Гугле, но очень часто встречал на найденных форумах только рассуждения и никакой конкретики. Здесь же имеется именно конкретика.
Но тем не менее, справочник – это замечательно, а где искать учебник, на чём же учиться? Честно говоря, особо и не на чем. Хороших готовых примеров для UDB Editor вообще мало. Мне страшно повезло, что когда я вдруг решил поиграть в RGB светодиоды, мне попался красивый пример именно под UDB Editor (о нём я писал в статье, с которой начался весь цикл). Но если много работать поисковиком, то примеры для Datapath Config Tool всё-таки найдутся, именно поэтому я и сделал предыдущую статью, чтобы все понимали, как этим инструментом пользоваться. И замечательная страничка, на которой собрана масса примеров, расположена тут.
На этой странице лежат разработки, сделанные сторонними разработчиками, но проверенные фирмой Cypress. То есть, как раз то, что нам нужно: мы же тоже сторонние разработчики, но хотим учиться на чём-то, что точно проверено. Давайте рассмотрим пример, благодаря которому я нашёл эту страницу, – аппаратный вычислитель квадратного корня. Конечные пользователи включают его в тракт обработки сигнала, бросая компонент на схему. На этом примере мы натренируемся анализировать подобный код, а дальше каждый уже сможет пуститься в самостоятельное плавание. Итак, нужный пример может быть скачан по ссылке.
Осматриваем его. Там есть примеры (которые каждый рассмотрит самостоятельно) и есть – библиотеки, расположенные в каталоге \CJCU_SquareRoot\Library\CJCU_SquareRoot.cylib.
Для каждого типа (целочисленный или с фиксированной точкой) и для каждой разрядности имеется своё решение. Это нам следует отметить. Универсальность хороша при разработке в UDB Editor, но при разработке с использованием Datapath Edit Tool, как видим, люди мучаются вот так. Не стоит пугаться, если у вас не получится универсально (но если получится – тем лучше).
На верхнем уровне (схемотехническом) я останавливаться не буду, мы же изучаем не работу с PSoC, а работу с UDB. Давайте посмотрим вариант средней сложности – 16 битный, но целочисленный. Он расположен в каталоге CJCU_B_Isqrt16_v1_0.
Первое, что стоит сделать, это раскрыть граф переходов микропрограммного автомата. Без него мы даже не догадаемся, какой именно алгоритм вычисления квадратного корня применён, так как Гугл предлагает на выбор несколько принципиально разных алгоритмов.
Пока что ничего не понятно, но это предсказуемо. Надо добавить больше информации. Смотрим на кодирование состояний. Бросается в глаза, что они закодированы не в обычном нарастающем двоичном коде.
Я уже упоминал о таком подходе в своих статьях, но ни разу не доводилось его использовать в конкретных примерах. Напомню, что у ОЗУ динамической конфигурации АЛУ имеется всего три адресных входа. То есть АЛУ может выполнять одну из восьми операций. Если состояний у автомата больше, то правило «на каждое состояние своя операция» становится невыполнимо. Поэтому выбираются состояния, в которых операции для АЛУ идентичны, у них три бита, подаваемых на адрес ОЗУ динамической конфигурации (обычно – младших), кодируются одинаково, а остальные – по-разному. Как сложить такой пасьянс – это уже проблемы разработчика. Разработчики изучаемого кода сложили именно так, как показано выше.
Добавим эту информацию на граф, плюс покрасим в сходные цвета состояния, выполняющие одну и ту же функцию в АЛУ.
Никаких закономерностей пока не проявилось, но продолжаем раскрывать граф. Открываем Datapath Edit Tool и изучаем логику уже в нём.
Обращаем внимание на то, что у нас имеется два блока Datapath, соединённые в цепочку. Когда мы будем делать что-то своё, нам тоже может понадобиться такое (правда, Datapath Edit Tool может создавать уже объединённые в цепочку блоки, так что это не страшно):
При чтении (да и при заполнении) граф, соответствующих АЛУ, всегда открываем документ с таким рисунком:
Правда, разработчики данного примера позаботились о нас и заполнили поля комментариев. Сейчас мы можем воспользоваться ими, чтобы понять, что зачем настроено. Заодно отмечаем для себя, что писать комментарии всегда полезно как для тех, кто будет сопровождать код, так и для нас, когда через полгода мы всё о нём забудем.
Смотрим код X000, соответствующий состояниям 0 и 12:
Из комментария уже ясно, что там к чему (в регистр A0 копируется содержимое регистра D0, а в регистр A1 копируется содержимое D1. Зная это, тренируем свою интуицию на будущее и находим аналогичную запись в полях настройки:
Там же видим, что АЛУ работает в режиме PASS, регистр сдвига – тоже PASS, так что никаких иных действий действительно не выполняется.
Попутно заглядываем в Verilog текст и видим там, чему равняется значение регистров D0 и D1:
При желании, то же самое можно посмотреть и в Datapath Config Tool, выбрав меню View->Initial Register Values:
Для просмотра удобнее прямой анализ Verilog кода, для создания своего варианта — работа через редактор, чтобы не держать в голове синтаксис.
Аналогично разбираем (сначала подглядывая в комментарии) все остальные функции АЛУ:
Переделываем граф переходов автомата с учётом новых знаний:
Что-то уже вырисовывается, но пока что я не могу с уверенностью положить на этот граф ни один из найденных Гуглом алгоритмов. Вернее, про некоторые можно уверенно сказать, что это не они, но даже на правдоподобные до конца ещё не могу дать уверенный ответ, что это именно они. Смущает активное использование регистров FIFO F0 и F1. Вообще, в файле
\CJCU_SquareRoot\Library\CJCU_SquareRoot.cylib\CJCU_Isqrt_v1_0\API\CJCU_Isqrt.c
видно, что F1 используется для передачи аргумента и возврата результата:
То же самое текстом:
void `$INSTANCE_NAME`_ComputeIsqrtAsync(uint`$regWidth` square) { /* Set up FIFOs, start the computation. */ CY_SET_REG`$dpWidth`(`$INSTANCE_NAME`_F1, square); CY_SET_REG8(`$INSTANCE_NAME`_CTL, 0x01); } … uint`$resultWidth` `$INSTANCE_NAME`_ReadIsqrtAsync() { /* Read back result. */ return CY_GET_REG`$dpWidth`(`$INSTANCE_NAME`_F1); }
Но один аргумент и один результат. А зачем так много обращений к FIFO по ходу работы? И при чём тут FIFO0? Режьте меня на куски, а кажется, что авторы воспользовались режимом, который встречался в переводах документации, когда вместо полноценного FIFO этот блок выступал в виде одиночного регистра. Допустим, авторы решили расширить регистровый набор. Если это так, то их методика нам пригодится при нашей практической работе, давайте изучать детали. На самом деле, документация рассказывает про разные подходы к работе с FIFO. Можно — так, можно – так, а можно – эдак. И никакой конкретики. Снова у нас есть шанс изучить передовой зарубежный практический опыт. Что с FIFO делают авторы?
Во-первых, вот такие присвоения сигналов:
wire f0_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_4); wire f1_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_3 || state == B_SQRT_STATE_9 || state == B_SQRT_STATE_11); wire fifo_dyn = (state == B_SQRT_STATE_0 || state == B_SQRT_STATE_12);
Во-вторых, вот такое подключение к Datapath:
/* input */ .f0_load(f0_load), /* input */ .f1_load(f1_load), /* input */ .d0_load(1'b0), /* input */ .d1_load(fifo_dyn),
Из описания контроллера особо не ясно, что всё это значит. Но из Application Note я выяснил, что во всём виновата вот эта настройка:
Кстати, именно из-за этой настройки данный блок невозможно описать при помощи UDB Editor. Когда эти управляющие биты находятся в состоянии ON, FIFO может работать на разные источники и приёмники. Если Dx_LOAD равен единице, то Fx обменивается с системной шиной, если нулю, то с регистром, выбранным здесь:
Получается, что F0 всегда обменивается с регистром A0, а F1 в состояниях 12 и 0 — с системной шиной (для выгрузки результата и загрузки аргумента), в остальных состояниях – с A1.
Дальше, из Verilog кода, мы выяснили, что в F0 данные будут загружены в состояниях 1 и 4, а в F1 – в состояниях 1, 3, 9, 11.
Добавим полученные знания на граф. Чтобы избежать путаницы при последовательности выполнения операций, также пришла пора заменить знак присвоения «а-ля UDB Editor» на Верилоговские стрелки, чтобы подчеркнуть, что источником является значение сигнала, которое он имел до входа в блок.
С точки зрения разбора алгоритма, уже всё ясно. Перед нами модификация такого алгоритма:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 30; // The second-to-top bit is set: use 1u << 14 for uint16_t type; use 1uL<<30 for uint32_t type // "one" starts at the highest power of four <= than the argument. while (one > op) { one >>= 2; } while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Только применительно к нашей системе он будет выглядеть, скорее, так:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 14; // The second-to-top bit is set while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Состояния 4 и 10 явно кодируют строку:
res >>= 1;
для разных веток.
Строка же:
one >>= 2;
явно кодируется либо парой состояний 6 и 7, либо парой состояний 9 и 7. Пока что хочется воскликнуть: «Ну и затейники же авторы!», но очень скоро станет ясно, зачем такая сложность с двумя ветками (в коде на Си же есть ветка и обход).
Состояние 2 кодирует условный переход. Состояние 7 кодирует оператор цикла. Операция сравнения на шаге 2 очень дорогая. Вообще, на большинстве шагов регистр A0 содержит переменную one. Но на шаге 1 переменная one выгружается в F0, а вместо неё загружается значение res + one, затем на шаге 2 производится вычитание с целью сравнения, а на шагах 3 и 8 – восстановление значения one. Зачем на шаге 4 A0 снова копируется в F0, я не понял. Возможно, это какой-то рудимент.
Осталось разобраться, кто здесь res, а кто – op. Мы знаем, что в условии сравниваются op и сумма res+one. В состоянии 1 суммируются A0 (one) и A1. Значит там A1 – это res. Получается, что в состоянии 11 A1 – тоже res, и именно он попадёт в F1, подаваемый на выход функции. F1 в состоянии 1 – это явно op. Предлагаю ввести цветовую дифференциацию
Собственно, вся правда раскрыта. Мы видим, как A1 лихо временно меняется с F1 для проведения сравнения и вычислений, как одна и та же разность используется и для сравнения (собственно, выработки бита C), так и для участия в формуле. Мы даже видим, зачем пустое место (обход) в алгоритме на Си закодировано длинной веткой графа переходов автомата (в этой ветке производится обмен регистров, идентичный обмену, происходящему в основной ветке кода). Мы всё видим.
Единственный вопрос, который не перестаёт меня мучить, как авторы переключили FIFO в однобайтный режим? Документация гласит, что для этого надо поднять в единицу биты CLR в Auxiliary Control register, но я не вижу, чтобы в API были подобные записи. Возможно, кто-нибудь поймёт это и напишет в комментариях.
Ну, а разрабатывать что-то своё – в обратной последовательности, пользуясь полученными навыками.
Заключение
Для развития навыков разработки «прошивок» на базе UDB полезно не только читать документацию, но и черпать вдохновение в чужих разработках. Код, прилагаемый к PSoC Creator, может быть полезен, как справочник, а поведенческие модели из поставки компилятора позволят лучше понять, что имелось в виду в документации. Также в статье дана ссылка на набор примеров от сторонних производителей и показан процесс разбора одного из таких примеров.
На этом цикл авторских статей по работе с UDB можно считать завершённым. Буду рад, если кому-либо он помог получить знания, полезные на практике. Впереди ещё пара переводов документации, но статистика показывает, что их уже почти никто не читает. Они запланированы чисто, чтобы не бросать тему на полуслове.

