Здравствуйте, друзья. Перед уходом на вторую часть майских праздников делимся с вами материалом, который мы перевели в преддверии запуска нового потока по курсу «Реляционные СУБД».

Разработчики приложений тратят много времени на сравнение нескольких операционных баз данных, чтобы выбрать ту, которая лучше всего подойдет для предполагаемой рабочей нагрузки. Потребности могут включать в себя упрощенное моделирование данных, транзакционные гарантии, производительность чтения/записи, горизонтальное масштабирование и отказоустойчивость. По традиции выбор начинается с категории базы данных, SQL или NoSQL, поскольку каждая категория предоставляет четкий набор компромиссов. Высокая производительность с точки зрения низкой задержки и высокой пропускной способности обычно рассматривается как требование не допускающее компромиссов, и поэтому является необходимым для любой базы данных из выборки.
Цель этой статьи – помочь разработчикам приложений сделать правильный выбор между SQL и NoSQL в контексте моделирования данных приложения. Мы рассмотрим одну SQL базу данных, а именно PostgreSQL и две NoSQL базы данных – Cassandra и MongoDB, чтобы рассказать про основы проектирования баз данных, такие как создание таблиц, их заполнение, чтение данных из таблицы и их удаление. В следующей статье мы обязательно рассмотрим индексы, транзакции, JOIN’ы, директивы TTL и проектирование баз данных на основе JSON.
В чем отличие SQL от NoSQL?
Учитывая их монолитную/одноузловую архитектуру и использование модели репликации master-slave для избыточности, традиционные SQL базы данных не имеют двух важных особенностей – линейной масштабируемости записи (т.е. автоматического разделения на несколько узлов) и автоматической/нулевой потери данных. Это значит, что объем получаемых данных не может превышать максимальную пропускную записи одного узла. Помимо этого, некоторая временная потеря данных должна быть учтена при отказоустойчивости (в архитектуре без разделения ресурсов). Здесь нужно иметь в виду, что недавние коммиты еще не отразились в подчиненной (slave) копии. Обновления без простоя также труднодостижимы в SQL базах данных.
NoSQL базы данных по своей натуре обычно распределенные, т.е. в них данные разбиваются на секции и распределяются по нескольким узлам. Они требуют денормализации. Это означает, что внесенные данные также должны быть скопированы несколько раз для ответа на конкретные запросы, которые вы посылаете. Общая цель состоит в том, чтобы получить высокую производительность путем уменьшения количества шардов, доступных во время чтения. Отсюда следует утверждение, что NoSQL требует от вас моделировать ваши запросы, а то время как SQL требует моделировать ваши данные.
Существует мнение, что, хотя NoSQL базы данных и обеспечивают линейную масштабируемость записи и высокую отказоустойчивость, потеря транзакционных гарантий делает их непригодными для критически важных данных.
Следующая таблица показывает, как моделирование данных в NoSQL отличается от SQL.
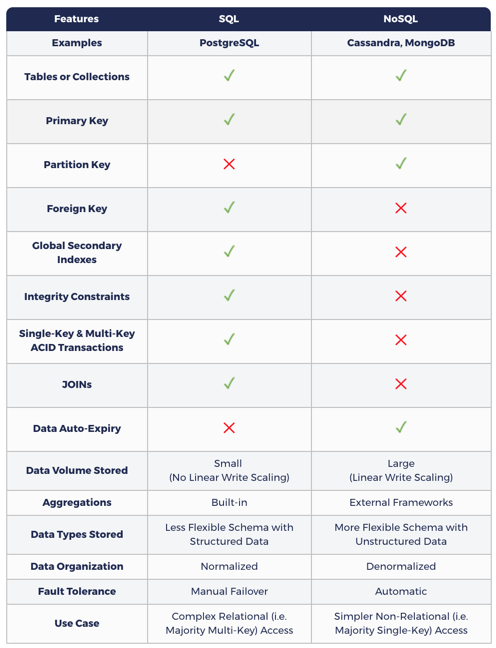
SQL и NoSQL: Почему нужны обе?
На реальных приложениях с большим количеством пользователей, таких как Amazon.com, Netflix, Uber и Airbnb лежит выполнение сложных разносортных задач. Например, приложению для электронной торговли подобному Amazon.com нужно хранить легковесные, высоко-критичные данные, такие как информация о пользователях, продуктах, заказах, счетах-фактурах, наряду с тяжелыми, но менее чувствительными данными, такими как обзоры продуктов, сообщения службы поддержки, активность пользователей, отзывы и рекомендации пользователей. Естественно, эти приложения полагаются по крайней мере на одну SQL базу данных наряду с как минимум одной NoSQL базой данных. В межрегиональных и глобальных системах, NoSQL база данных работает в качестве геораспределенного кэша для данных, хранящихся в доверенном источнике, SQL базе данных, работающей в каком-то одном регионе.
Как YugaByte DB объединяет в себе SQL и NoSQL?
Построенная на лог-ориентированном смешанном движке для хранения, авто-шардинге, шардинговой распределенной консенсусной репликации и распределенных транзакциях ACID (вдохновленных Google Spanner), YugaByte DB является первой в мире базой данных с открытым исходным кодом, которая одновременно совместима с NoSQL (Cassandra & Redis) и SQL (PostgreSQL). Как показано в таблице ниже, YSQL, API YugaByte DB совместимое с Cassandra, добавляет понятия одно- и многоключевые ACID транзакции и глобальные вторичные индексы в API NoSQL, тем самым открывая эру транзакционных NoSQL баз данных. Кроме того, YSQL, API YugaByte DB совместимое с PostgreSQL, добавляет понятия линейного масштабирования записи и автоматической отказоустойчивости к SQL API, являя миру распределенные SQL базы данных. Поскольку база данных YugaByte DB является по своей сути транзакционной, то API NoSQL теперь можно использовать в контексте критически важных данных.
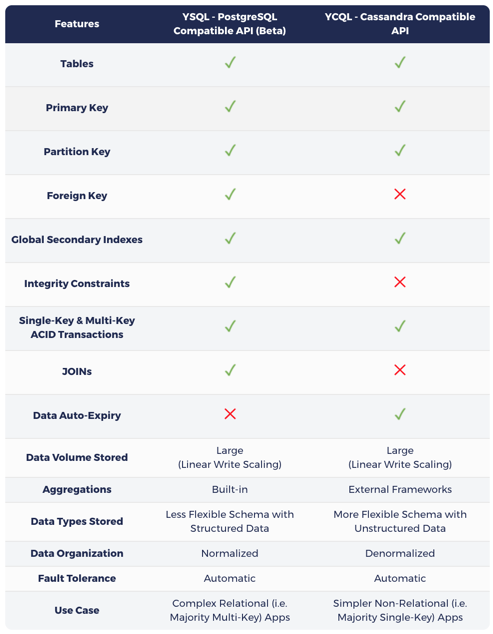
Как ранее было сказано в статье «Introducing YSQL: A PostgreSQL Compatible Distributed SQL API for YugaByte DB», выбор между SQL или NoSQL в YugaByte DB полностью зависит от характеристик основной рабочей нагрузки:
В основе лаборатории моделирования данных (Data modeling lab) в следующем разделе лежат совместимые с PostgreSQL и Cassandra API базы данных YugaByte DB в отличие от исходных баз данных. Этот подход подчеркивает простоту взаимодействия с двумя различными API (на двух разных портах) одного и того же кластера баз данных в отличие от использования полностью независимых кластеров двух разных баз данных.
В следующих разделах мы познакомимся с лабораторией моделирования данных, чтобы проиллюстрировать различие и некоторые общие черты рассматриваемых баз данных.
Лаборатория моделирования данных
Установка баз данных
Учитывая акцент на проектировании модели данных (а не на сложных архитектурах развертывания), мы установим базы данных в Docker контейнеры на локальном компьютере, а затем будем взаимодействовать с ними, используя соответствующие им оболочки командной строки.
Совместимая с PostgreSQL & Cassandra, база данных YugaByte DB
MongoDB
Доступ через командную строку
Давайте подключимся к базам данных, при помощи оболочки командной строки для соответствующих API.
PostgreSQL
psql — это оболочка командной строки для взаимодействия с PostgreSQL. Для простоты использования YugaByte DB поставляется с psql прямо в папке bin.
Cassandra
сqlsh — это оболочка командной строки для взаимодействия с Cassandra и ее совместимыми базами данных через CQL (язык запросов Cassandra). Для удобства использования YugaByte DB поставляется с
Обратите внимание, что CQL был вдохновлен SQL и имеет аналогичные понятия таблиц, строк, столбцов и индексов. Однако, как язык NoSQL, он добавляет определенный набор ограничений, большинство из которых мы также рассмотрим в других статьях.
MongoDB
mongo – это оболочка командной строки для взаимодействия с MongoDB. Ее можно найти в каталоге bin инсталляции MongoDB.
Создание таблицы
Сейчас мы можем взаимодействовать с базой данных для выполнения различных операций с помощью командной строки. Давайте начнем с создания таблицы, которая хранит информацию о песнях написанных разными исполнителями. Эти песни могут быть частью альбома. Также опциональные атрибуты для песни – год выпуска, цена, жанр и рейтинг. Нам нужно учитывать дополнительные атрибуты, которые могут понадобиться в будущем, через поле «теги». Оно может хранить полуструктурированные данные в виде пар ключ-значение.
PostgreSQL
Cassandra
Создание таблицы в Cassandra очень похоже на PostgreSQL. Одним из основных различий является отсутствие ограничений целостности (например, NOT NULL), но это входит в зону ответственности приложения, а не NoSQL базы данных. Первичный ключ состоит из ключа раздела (столбец Artist в примере ниже) и набора столбцов кластеризации (столбец SongTitle в приведенном ниже примере). Ключ раздела определяет в какой раздел/шард помесить строку, а столбцы кластеризации указывают, как должны быть организованы данные внутри текущего шарда.
MongoDB
MongoDB организует данные в базы данных (Database) (аналогично Keyspace в Cassandra), где есть коллекции (Collections) (аналогично таблицам), в которых лежат документы (Documents) (аналогично строкам в таблице). В MongoDB в принципе не требуется определение изначальной схемы. Команда «use database», показанная ниже, создает экземпляр базы данных при первом вызове и изменяет контекст для вновь созданной базы данных. Даже коллекции не нужно создавать явно, они создаются автоматически, просто при добавлении первого документа в новую коллекцию. Обратите внимание, что MongoDB по умолчанию использует тестовую базу данных, поэтому любая операция уровня коллекций без указания конкретной базы, будет выполняться в ней по умолчанию.
Получение информации о таблице PostgreSQL
Cassandra
MongoDB
Внесение данных в таблицуPostgreSQL
Cassandra
В целом выражение
MongoDB
Несмотря на то, что MongoDB является NoSQL базой данных, подобно Cassandra, ее операция внесения данных не имеет ничего общего с семантическим поведением в Cassandra. В MongoDB insert() не имеет возможностей
Запрос таблицы
Возможно, наиболее существенная разница между SQL и NoSQL с точки зрения составления запросов заключается в использовании формулировок
PostgreSQL
Далее будут приведены три примера запросов, которые с лёгкостью могут быть выполнены SQL базой данных.
Cassandra
Из перечисленных выше запросов PostgreSQL только первый будет работать в Cassandra без изменений, поскольку оператор
MongoDB
Как показано в предыдущих примерах, основным методом создания запросов в MongoDB является db.collection.find(). Этот метод явно содержит в себе имя коллекции (
Считывание всех строк таблицы
Чтение всех строк — это просто частный случай того шаблона запроса, который мы рассматривали ранее.
PostgreSQL
Cassandra
MongoDB
Редактирование данных в таблице
PostgreSQL
PostgreSQL предоставляет инструкцию
Cassandra
В Cassandra есть
MongoDB
Операция update() в MongoDB может полностью обновить существующий документ или обновить только определенные поля. По умолчанию она обновляет только один документ с отключенной семантикой
Удаление данных из таблицы
PostgreSQL
Cassandra
MongoDB
В MongoDB есть два типа операций для удаления документов — deleteOne() /deleteMany() и remove(). Оба типа удаляют документы, но возвращают разные результаты.
Удаление таблицы
PostgreSQL
Cassandra
MongoDB
Заключение
Споры о выборе между SQL и NoSQL бушуют уже более 10 лет. Есть два основных аспекта этого спора: архитектура ядра базы данных (монолитный, транзакционный SQL против распределенного, нетранзакционного NoSQL) и подход к проектированию базы данных (моделирование данных в SQL против моделирования ваших запросов в NoSQL).
С распределенной транзакционной базой данных, такой как YugaByte DB, дебаты насчет архитектуры базы данных могут быть легко развеяны. По мере того как объемы данных становятся больше, чем то, что может быть записано в один узел, полностью распределенная архитектура, которая поддерживает линейную масштабируемость записи с автоматическим шардингом/ребалансировкой, становится необходимой.
Помимо того, как сказано в одной из статей Google Cloud, транзакционные, строго согласованные архитектуры теперь шире применяются для обеспечения лучшей гибкости в разработке, чем нетранзакционные, в конечном итоге согласованные архитектуры.
Возвращаясь к обсуждению проектирования баз данных, справедливо сказать, что оба подхода к проектированию (SQL и NoSQL) необходимы для любого сложного реального приложения. Подход SQL «моделирование данных» позволяет разработчикам легче удовлетворять меняющиеся бизнес-требования, в то время как подход NoSQL «моделирование запросов» позволяет тем же разработчикам оперировать большими объемами данных имея маленькую задержку и высокую пропускную способность. Именно по этой причине YugaByte DB предоставляет SQL и NoSQL API в общем ядре, а не пропагандирует какой-то один из подходов. Кроме того, обеспечивая совместимость с популярными языками баз данных, включая PostgreSQL и Cassandra, YugaByte DB гарантирует, что разработчикам не придется изучать другой язык, чтобы работать с распределенным строго согласованным ядром базы данных.
В этой статье мы разобрались, как основы проектирования баз данных различаются в PostgreSQL, Cassandra и MongoDB. В следующих статьях мы погрузимся в передовые концепции проектирования, такие как индексы, транзакции, JOIN’ы, директивы TTL и JSON-документы.
Желаем вам отлично провести оставшиеся выходные и приглашаем на бесплатный вебинар, который пройдет уже 14 мая.
Разработчики приложений тратят много времени на сравнение нескольких операционных баз данных, чтобы выбрать ту, которая лучше всего подойдет для предполагаемой рабочей нагрузки. Потребности могут включать в себя упрощенное моделирование данных, транзакционные гарантии, производительность чтения/записи, горизонтальное масштабирование и отказоустойчивость. По традиции выбор начинается с категории базы данных, SQL или NoSQL, поскольку каждая категория предоставляет четкий набор компромиссов. Высокая производительность с точки зрения низкой задержки и высокой пропускной способности обычно рассматривается как требование не допускающее компромиссов, и поэтому является необходимым для любой базы данных из выборки.
Цель этой статьи – помочь разработчикам приложений сделать правильный выбор между SQL и NoSQL в контексте моделирования данных приложения. Мы рассмотрим одну SQL базу данных, а именно PostgreSQL и две NoSQL базы данных – Cassandra и MongoDB, чтобы рассказать про основы проектирования баз данных, такие как создание таблиц, их заполнение, чтение данных из таблицы и их удаление. В следующей статье мы обязательно рассмотрим индексы, транзакции, JOIN’ы, директивы TTL и проектирование баз данных на основе JSON.
В чем отличие SQL от NoSQL?
SQL базы данных повышают гибкость приложения благодаря транзакционным гарантиям ACID, а также благодаря своей способности запрашивать данные с помощью JOIN неожиданными способами поверх существующих нормализованных моделей реляционных баз данных.
Учитывая их монолитную/одноузловую архитектуру и использование модели репликации master-slave для избыточности, традиционные SQL базы данных не имеют двух важных особенностей – линейной масштабируемости записи (т.е. автоматического разделения на несколько узлов) и автоматической/нулевой потери данных. Это значит, что объем получаемых данных не может превышать максимальную пропускную записи одного узла. Помимо этого, некоторая временная потеря данных должна быть учтена при отказоустойчивости (в архитектуре без разделения ресурсов). Здесь нужно иметь в виду, что недавние коммиты еще не отразились в подчиненной (slave) копии. Обновления без простоя также труднодостижимы в SQL базах данных.
NoSQL базы данных по своей натуре обычно распределенные, т.е. в них данные разбиваются на секции и распределяются по нескольким узлам. Они требуют денормализации. Это означает, что внесенные данные также должны быть скопированы несколько раз для ответа на конкретные запросы, которые вы посылаете. Общая цель состоит в том, чтобы получить высокую производительность путем уменьшения количества шардов, доступных во время чтения. Отсюда следует утверждение, что NoSQL требует от вас моделировать ваши запросы, а то время как SQL требует моделировать ваши данные.
NoSQL акцентируется на достижении высокой производительности в распределенном кластере и это является основным обоснованием множества компромиссов проектирования баз данных, которые включают в себя потерю транзакций ACID, JOIN’ы и согласованные глобальные вторичные индексы.
Существует мнение, что, хотя NoSQL базы данных и обеспечивают линейную масштабируемость записи и высокую отказоустойчивость, потеря транзакционных гарантий делает их непригодными для критически важных данных.
Следующая таблица показывает, как моделирование данных в NoSQL отличается от SQL.
SQL и NoSQL: Почему нужны обе?
На реальных приложениях с большим количеством пользователей, таких как Amazon.com, Netflix, Uber и Airbnb лежит выполнение сложных разносортных задач. Например, приложению для электронной торговли подобному Amazon.com нужно хранить легковесные, высоко-критичные данные, такие как информация о пользователях, продуктах, заказах, счетах-фактурах, наряду с тяжелыми, но менее чувствительными данными, такими как обзоры продуктов, сообщения службы поддержки, активность пользователей, отзывы и рекомендации пользователей. Естественно, эти приложения полагаются по крайней мере на одну SQL базу данных наряду с как минимум одной NoSQL базой данных. В межрегиональных и глобальных системах, NoSQL база данных работает в качестве геораспределенного кэша для данных, хранящихся в доверенном источнике, SQL базе данных, работающей в каком-то одном регионе.
Как YugaByte DB объединяет в себе SQL и NoSQL?
Построенная на лог-ориентированном смешанном движке для хранения, авто-шардинге, шардинговой распределенной консенсусной репликации и распределенных транзакциях ACID (вдохновленных Google Spanner), YugaByte DB является первой в мире базой данных с открытым исходным кодом, которая одновременно совместима с NoSQL (Cassandra & Redis) и SQL (PostgreSQL). Как показано в таблице ниже, YSQL, API YugaByte DB совместимое с Cassandra, добавляет понятия одно- и многоключевые ACID транзакции и глобальные вторичные индексы в API NoSQL, тем самым открывая эру транзакционных NoSQL баз данных. Кроме того, YSQL, API YugaByte DB совместимое с PostgreSQL, добавляет понятия линейного масштабирования записи и автоматической отказоустойчивости к SQL API, являя миру распределенные SQL базы данных. Поскольку база данных YugaByte DB является по своей сути транзакционной, то API NoSQL теперь можно использовать в контексте критически важных данных.
Как ранее было сказано в статье «Introducing YSQL: A PostgreSQL Compatible Distributed SQL API for YugaByte DB», выбор между SQL или NoSQL в YugaByte DB полностью зависит от характеристик основной рабочей нагрузки:
- Если основная рабочая нагрузка – это многоключевые операции с JOIN’ами, то при выборе YSQL, понимайте, что ваши ключи могут быть распределены по нескольким узлам, что приведет к более высокой задержке и/или понижению пропускной способности, чем в NoSQL.
- В противном случае, выберите любой из двух NoSQL API, помня о том, что вы получите более высокую производительность в результате запросов, обслуживаемых с одного узла за раз. YugaByte DB может служить единой операционной базой данных для реальных сложных приложений, в которых необходимо управлять несколькими рабочими нагрузками одновременно.
В основе лаборатории моделирования данных (Data modeling lab) в следующем разделе лежат совместимые с PostgreSQL и Cassandra API базы данных YugaByte DB в отличие от исходных баз данных. Этот подход подчеркивает простоту взаимодействия с двумя различными API (на двух разных портах) одного и того же кластера баз данных в отличие от использования полностью независимых кластеров двух разных баз данных.
В следующих разделах мы познакомимся с лабораторией моделирования данных, чтобы проиллюстрировать различие и некоторые общие черты рассматриваемых баз данных.
Лаборатория моделирования данных
Установка баз данных
Учитывая акцент на проектировании модели данных (а не на сложных архитектурах развертывания), мы установим базы данных в Docker контейнеры на локальном компьютере, а затем будем взаимодействовать с ними, используя соответствующие им оболочки командной строки.
Совместимая с PostgreSQL & Cassandra, база данных YugaByte DB
mkdir ~/yugabyte && cd ~/yugabyte wget https://downloads.yugabyte.com/yb-docker-ctl && chmod +x yb-docker-ctl docker pull yugabytedb/yugabyte ./yb-docker-ctl create --enable_postgres
MongoDB
docker run --name my-mongo -d mongo:latest
Доступ через командную строку
Давайте подключимся к базам данных, при помощи оболочки командной строки для соответствующих API.
PostgreSQL
psql — это оболочка командной строки для взаимодействия с PostgreSQL. Для простоты использования YugaByte DB поставляется с psql прямо в папке bin.
docker exec -it yb-postgres-n1 /home/yugabyte/postgres/bin/psql -p 5433 -U postgres
Cassandra
сqlsh — это оболочка командной строки для взаимодействия с Cassandra и ее совместимыми базами данных через CQL (язык запросов Cassandra). Для удобства использования YugaByte DB поставляется с
cqlsh в каталоге bin.Обратите внимание, что CQL был вдохновлен SQL и имеет аналогичные понятия таблиц, строк, столбцов и индексов. Однако, как язык NoSQL, он добавляет определенный набор ограничений, большинство из которых мы также рассмотрим в других статьях.
docker exec -it yb-tserver-n1 /home/yugabyte/bin/cqlsh
MongoDB
mongo – это оболочка командной строки для взаимодействия с MongoDB. Ее можно найти в каталоге bin инсталляции MongoDB.
docker exec -it my-mongo bash cd bin mongo
Создание таблицы
Сейчас мы можем взаимодействовать с базой данных для выполнения различных операций с помощью командной строки. Давайте начнем с создания таблицы, которая хранит информацию о песнях написанных разными исполнителями. Эти песни могут быть частью альбома. Также опциональные атрибуты для песни – год выпуска, цена, жанр и рейтинг. Нам нужно учитывать дополнительные атрибуты, которые могут понадобиться в будущем, через поле «теги». Оно может хранить полуструктурированные данные в виде пар ключ-значение.
PostgreSQL
CREATE TABLE Music ( Artist VARCHAR(20) NOT NULL, SongTitle VARCHAR(30) NOT NULL, AlbumTitle VARCHAR(25), Year INT, Price FLOAT, Genre VARCHAR(10), CriticRating FLOAT, Tags TEXT, PRIMARY KEY(Artist, SongTitle) );
Cassandra
Создание таблицы в Cassandra очень похоже на PostgreSQL. Одним из основных различий является отсутствие ограничений целостности (например, NOT NULL), но это входит в зону ответственности приложения, а не NoSQL базы данных. Первичный ключ состоит из ключа раздела (столбец Artist в примере ниже) и набора столбцов кластеризации (столбец SongTitle в приведенном ниже примере). Ключ раздела определяет в какой раздел/шард помесить строку, а столбцы кластеризации указывают, как должны быть организованы данные внутри текущего шарда.
CREATE KEYSPACE myapp; USE myapp; CREATE TABLE Music ( Artist TEXT, SongTitle TEXT, AlbumTitle TEXT, Year INT, Price FLOAT, Genre TEXT, CriticRating FLOAT, Tags TEXT, PRIMARY KEY(Artist, SongTitle) );
MongoDB
MongoDB организует данные в базы данных (Database) (аналогично Keyspace в Cassandra), где есть коллекции (Collections) (аналогично таблицам), в которых лежат документы (Documents) (аналогично строкам в таблице). В MongoDB в принципе не требуется определение изначальной схемы. Команда «use database», показанная ниже, создает экземпляр базы данных при первом вызове и изменяет контекст для вновь созданной базы данных. Даже коллекции не нужно создавать явно, они создаются автоматически, просто при добавлении первого документа в новую коллекцию. Обратите внимание, что MongoDB по умолчанию использует тестовую базу данных, поэтому любая операция уровня коллекций без указания конкретной базы, будет выполняться в ней по умолчанию.
use myNewDatabase;
Получение информации о таблице PostgreSQL
\d Music Table "public.music" Column | Type | Collation | Nullable | Default --------------+-----------------------+-----------+----------+-------- artist | character varying(20) | | not null | songtitle | character varying(30) | | not null | albumtitle | character varying(25) | | | year | integer | | | price | double precision | | | genre | character varying(10) | | | criticrating | double precision | | | tags | text | | | Indexes: "music_pkey" PRIMARY KEY, btree (artist, songtitle)
Cassandra
DESCRIBE TABLE MUSIC; CREATE TABLE myapp.music ( artist text, songtitle text, albumtitle text, year int, price float, genre text, tags text, PRIMARY KEY (artist, songtitle) ) WITH CLUSTERING ORDER BY (songtitle ASC) AND default_time_to_live = 0 AND transactions = {'enabled': 'false'};
MongoDB
use myNewDatabase; show collections;
Внесение данных в таблицуPostgreSQL
INSERT INTO Music (Artist, SongTitle, AlbumTitle, Year, Price, Genre, CriticRating, Tags) VALUES( 'No One You Know', 'Call Me Today', 'Somewhat Famous', 2015, 2.14, 'Country', 7.8, '{"Composers": ["Smith", "Jones", "Davis"],"LengthInSeconds": 214}' ); INSERT INTO Music (Artist, SongTitle, AlbumTitle, Price, Genre, CriticRating) VALUES( 'No One You Know', 'My Dog Spot', 'Hey Now', 1.98, 'Country', 8.4 ); INSERT INTO Music (Artist, SongTitle, AlbumTitle, Price, Genre) VALUES( 'The Acme Band', 'Look Out, World', 'The Buck Starts Here', 0.99, 'Rock' ); INSERT INTO Music (Artist, SongTitle, AlbumTitle, Price, Genre, Tags) VALUES( 'The Acme Band', 'Still In Love', 'The Buck Starts Here', 2.47, 'Rock', '{"radioStationsPlaying": ["KHCR", "KBQX", "WTNR", "WJJH"], "tourDates": { "Seattle": "20150625", "Cleveland": "20150630"}, "rotation": Heavy}' );
Cassandra
В целом выражение
INSERT в Cassandra выглядит очень похоже на аналогичное в PostgreSQL. Однако имеется одно большое различие в семантике. В Cassandra INSERT фактически является операцией UPSERT, где в строку добавляются последние значения, в случае, если строка уже существует. Ввод данных происходит аналогично PostgreSQL INSERT вышеMongoDB
Несмотря на то, что MongoDB является NoSQL базой данных, подобно Cassandra, ее операция внесения данных не имеет ничего общего с семантическим поведением в Cassandra. В MongoDB insert() не имеет возможностей
UPSERT, что делает его похожим на PostgreSQL. Добавление данных по умолчанию без _idspecified приведет к добавлению нового документа в коллекцию.db.music.insert( {
artist: "No One You Know",
songTitle: "Call Me Today",
albumTitle: "Somewhat Famous",
year: 2015,
price: 2.14,
genre: "Country",
tags: {
Composers: ["Smith", "Jones", "Davis"],
LengthInSeconds: 214
}
}
);
db.music.insert( {
artist: "No One You Know",
songTitle: "My Dog Spot",
albumTitle: "Hey Now",
price: 1.98,
genre: "Country",
criticRating: 8.4
}
);
db.music.insert( {
artist: "The Acme Band",
songTitle: "Look Out, World",
albumTitle:"The Buck Starts Here",
price: 0.99,
genre: "Rock"
}
);
db.music.insert( {
artist: "The Acme Band",
songTitle: "Still In Love",
albumTitle:"The Buck Starts Here",
price: 2.47,
genre: "Rock",
tags: {
radioStationsPlaying:["KHCR", "KBQX", "WTNR", "WJJH"],
tourDates: {
Seattle: "20150625",
Cleveland: "20150630"
},
rotation: "Heavy"
}
}
);Запрос таблицы
Возможно, наиболее существенная разница между SQL и NoSQL с точки зрения составления запросов заключается в использовании формулировок
FROM и WHERE. SQL позволяет после выражения FROM выбирать несколько таблиц, а выражение с WHERE может быть какой угодно сложности (включая операции JOIN между таблицами). Однако NoSQL имеет тенденцию накладывать жесткое ограничение на FROM, и работать только с одной указанной таблицей, а в WHERE, всегда должен быть указан первичный ключ. Это связано со стремлением к повышению производительности NoSQL, о котором мы говорили ранее. Это стремление приводит к всяческому уменьшению любого кросс-табличного и кросс-ключевого взаимодействия. Оно может привести к большой задержке в межузловой связи при ответе на запрос и, следовательно, его лучше всего избегать в принципе. Например, Cassandra требует, чтобы запросы были ограничены определенными операторами (разрешены только =, IN, <, >, =>, <=) на ключах разделов, за исключением случаев запроса вторичного индекса (здесь разрешен только оператор =).PostgreSQL
Далее будут приведены три примера запросов, которые с лёгкостью могут быть выполнены SQL базой данных.
- Вывести все песни исполнителя;
- Вывести все песни исполнителя, совпадающие с первой частью названия;
- Вывести все песни исполнителя, имеющие определенное слово в названии и имеющие цену меньше 1.00.
SELECT * FROM Music WHERE Artist='No One You Know'; SELECT * FROM Music WHERE Artist='No One You Know' AND SongTitle LIKE 'Call%'; SELECT * FROM Music WHERE Artist='No One You Know' AND SongTitle LIKE '%Today%' AND Price > 1.00;
Cassandra
Из перечисленных выше запросов PostgreSQL только первый будет работать в Cassandra без изменений, поскольку оператор
LIKE нельзя применять к столбцам кластеризации, таких как SongTitle. В этом случае допускаются только операторы = и IN.SELECT * FROM Music WHERE Artist='No One You Know'; SELECT * FROM Music WHERE Artist='No One You Know' AND SongTitle IN ('Call Me Today', 'My Dog Spot') AND Price > 1.00;
MongoDB
Как показано в предыдущих примерах, основным методом создания запросов в MongoDB является db.collection.find(). Этот метод явно содержит в себе имя коллекции (
music в примере ниже), поэтому запрос по нескольким коллекциям запрещен.db.music.find( { artist: "No One You Know" } ); db.music.find( { artist: "No One You Know", songTitle: /Call/ } );
Считывание всех строк таблицы
Чтение всех строк — это просто частный случай того шаблона запроса, который мы рассматривали ранее.
PostgreSQL
SELECT * FROM Music;
Cassandra
Аналогично примеру в PostgreSQL выше.
MongoDB
db.music.find( {} );
Редактирование данных в таблице
PostgreSQL
PostgreSQL предоставляет инструкцию
UPDATE для изменения данных. Она не имеет возможностей UPSERT, поэтому выполнение этой инструкции завершится ошибкой, в случае если строки больше нет в базе данных.UPDATE Music SET Genre = 'Disco' WHERE Artist = 'The Acme Band' AND SongTitle = 'Still In Love';
Cassandra
В Cassandra есть
UPDATE аналогичный PostgreSQL. UPDATE имеет ту же семантику UPSERT, подобно INSERT.Аналогично примеру в PostgreSQL выше.
MongoDB
Операция update() в MongoDB может полностью обновить существующий документ или обновить только определенные поля. По умолчанию она обновляет только один документ с отключенной семантикой
UPSERT. Обновление нескольких документов и поведение аналогичное UPSERT можно применить, установив для операции дополнительные флаги. Как например в приведенном ниже примере происходит обновление жанра конкретного исполнителя по его песне.db.music.update( {"artist": "The Acme Band"}, { $set: { "genre": "Disco" } }, {"multi": true, "upsert": true} );
Удаление данных из таблицы
PostgreSQL
DELETE FROM Music WHERE Artist = 'The Acme Band' AND SongTitle = 'Look Out, World';
Cassandra
Аналогично примеру в PostgreSQL выше.
MongoDB
В MongoDB есть два типа операций для удаления документов — deleteOne() /deleteMany() и remove(). Оба типа удаляют документы, но возвращают разные результаты.
db.music.deleteMany( { artist: "The Acme Band" } );
Удаление таблицы
PostgreSQL
DROP TABLE Music;
Cassandra
Аналогично примеру в PostgreSQL выше.
MongoDB
db.music.drop();
Заключение
Споры о выборе между SQL и NoSQL бушуют уже более 10 лет. Есть два основных аспекта этого спора: архитектура ядра базы данных (монолитный, транзакционный SQL против распределенного, нетранзакционного NoSQL) и подход к проектированию базы данных (моделирование данных в SQL против моделирования ваших запросов в NoSQL).
С распределенной транзакционной базой данных, такой как YugaByte DB, дебаты насчет архитектуры базы данных могут быть легко развеяны. По мере того как объемы данных становятся больше, чем то, что может быть записано в один узел, полностью распределенная архитектура, которая поддерживает линейную масштабируемость записи с автоматическим шардингом/ребалансировкой, становится необходимой.
Помимо того, как сказано в одной из статей Google Cloud, транзакционные, строго согласованные архитектуры теперь шире применяются для обеспечения лучшей гибкости в разработке, чем нетранзакционные, в конечном итоге согласованные архитектуры.
Возвращаясь к обсуждению проектирования баз данных, справедливо сказать, что оба подхода к проектированию (SQL и NoSQL) необходимы для любого сложного реального приложения. Подход SQL «моделирование данных» позволяет разработчикам легче удовлетворять меняющиеся бизнес-требования, в то время как подход NoSQL «моделирование запросов» позволяет тем же разработчикам оперировать большими объемами данных имея маленькую задержку и высокую пропускную способность. Именно по этой причине YugaByte DB предоставляет SQL и NoSQL API в общем ядре, а не пропагандирует какой-то один из подходов. Кроме того, обеспечивая совместимость с популярными языками баз данных, включая PostgreSQL и Cassandra, YugaByte DB гарантирует, что разработчикам не придется изучать другой язык, чтобы работать с распределенным строго согласованным ядром базы данных.
В этой статье мы разобрались, как основы проектирования баз данных различаются в PostgreSQL, Cassandra и MongoDB. В следующих статьях мы погрузимся в передовые концепции проектирования, такие как индексы, транзакции, JOIN’ы, директивы TTL и JSON-документы.
Желаем вам отлично провести оставшиеся выходные и приглашаем на бесплатный вебинар, который пройдет уже 14 мая.

