В прошлом году, нашей команде повезло принять участие в разработке программного обеспечения для социально значимого проекта – системы ввода архивных данных военных комиссариатов Хабаровского края времен Великой Отечественной войны. Кратко говоря, когда был призван, куда убыл и другую связанную с этим информацию – оцифровать и дать возможность искать эти данные кому угодно. Дальневосточный центр социальных технологий в 2018 году, при поддержке Фонда президентских грантов, реализовывал проект — «Вспомнить каждого». А мы, разработали приложение на нашем опенсорсном продукте IONDV. Framework. Итоговое приложение сейчас доступно под лицензией GPLv3.
Делимся нашим решением и опытом работы над проектом.

Спойлер, немного технических деталей.
В ходе разработки мы создали веб-приложение, с корпоративным названием War archive — для хранения, группировки и демонстрации архивных документов о Великой Отечественной войне. Мы активно работали с января по март 2018 года и в процессе исправляли баги фреймворка – так как опыт работы с таким количеством сканов у нас был первый.
Результатом работы проекта «Вспомнить каждого» стал реестр данных с 25к записей (сейчас уже 35к). В апреле этого года Дальневосточный центр социальных технологий опубликовал исходный код приложения под лицензией GPLv3 на GitHub. В репозитории вы найдете метаданные, шаблоны оформления и специальные утилиты – всё то, что составляет основу приложения для IONDV. Framework. Сам фреймворк распространяется под лицензией Apache 2.0 и также доступен на GitHub, вместе с готовыми модулями.
Также развернуто демо приложения. Тестовый запрос для поиска «Иванов Иван». Можно посмотреть и бэкофис по ссылке. Логин – demo, пароль — ion-demo. Кстати можно получить и готовый докер образ.
Цель проекта «Вспомнить каждого» сохранить память о людях времен ВОВ, предоставив безвозмездный доступ к документам тех лет. Мария Степко, директор Дальневосточного центра социальных технологий как-то сказала: «Сохранение и анализ полученных данных о прошлом – это задача, необходимая для моделирования будущего».
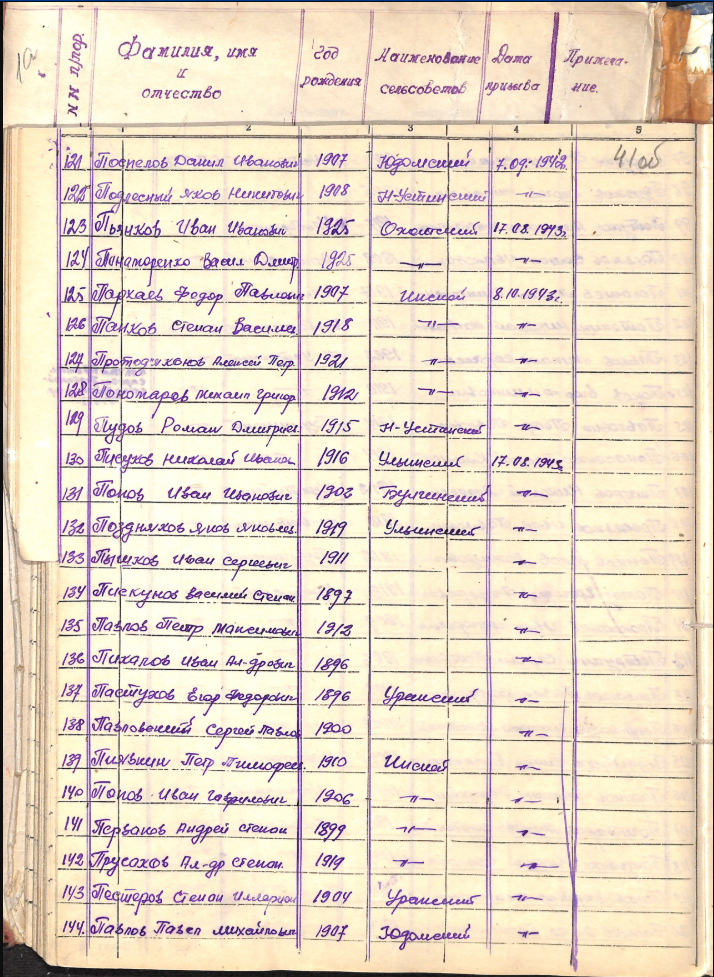
Добровольцы проекта оцифровали 10 тыс. страниц документов и внесли данные в реестр о дальневосточниках, участниках Великой Отечественной войны. В базе можно найти информацию о звании призванного, о части, дате, причине смерти и месте захоронения. Кроме того, доступен оцифрованный источник записи с указанием номера описи, дела, листа в соответствии с нумерацией государственного архива. Пример скана документа.
Мы очень благодарны за эту возможность и за отзыв о нашей работе:
Вчера мы закончили перенос проекта на Яндекс. Облако и сделали доступным по новому адресу dvarchive.ru.
Заодно провели нагрузочное тестирование, о чем тоже хотели бы поделиться.
Ресурсы сервера минимальные, так как он оплачивается за счет фаундрайзинговой компании: 2 CPU с 20% приоритетом и 2Gb памяти.
Типовая реакция на небольшую нагрузку выглядит так – 2% загрузки CPU и 36% загрузки памяти.
Мы провели тестирование запросов пользователей без статичных файлов, только запросы на данные и результат нам понравился.
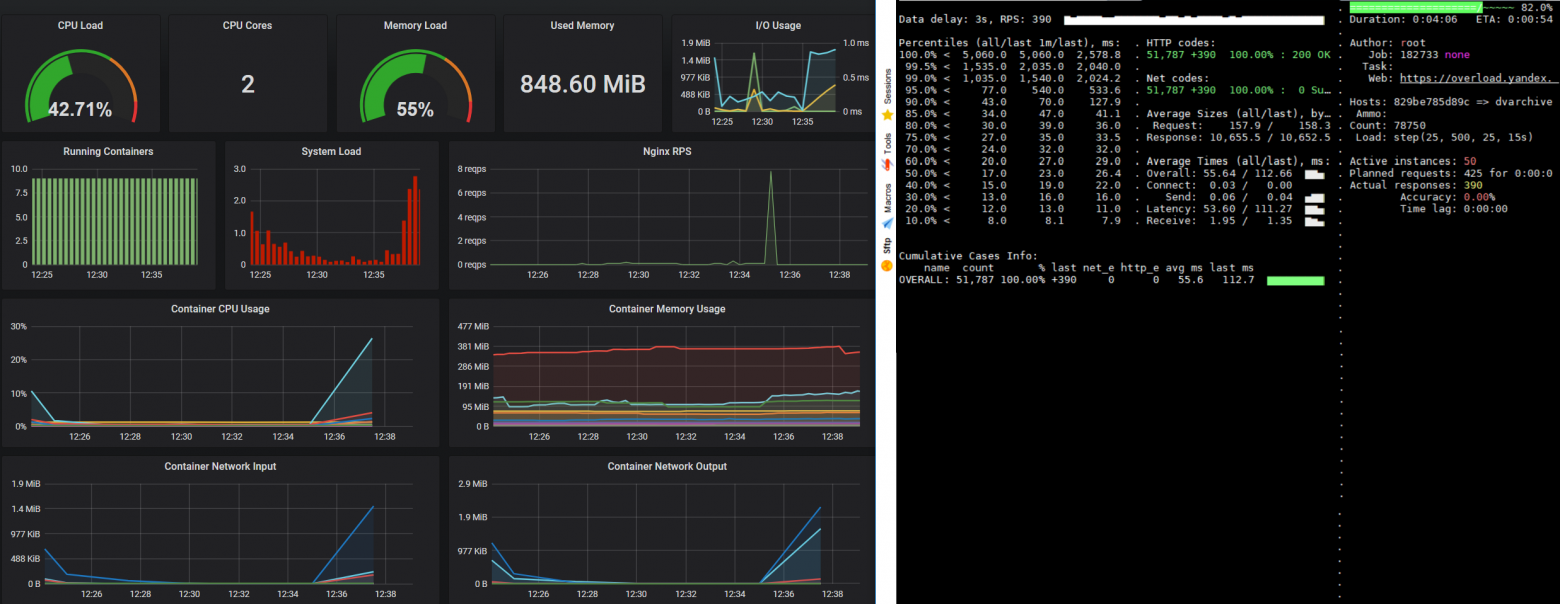
Получилось, что приложение в докер контейнере обрабатывает 400 запросов в секунду (без статики). И при этом нагружает только один процессор, что характерно при запуске только одной инстанции node.js. Второй обрабатывает остальные задачи (СУБД, nginx, мониторинг).
Даже не нужна кластеризация. Для режима обычной нагрузки социального проекта имеется большой запас, несмотря на минимум ресурсов.
Для нас это был первый опыт участия в работе над проектом, связанным с памятью о Великой Отечественной войне, о дальневосточниках.
Тем более мы гордимся тем, что этим результатом, разработанным на Дальнем Востоке – регионе не очень активном в области ИТ, может воспользоваться любой, кто занимается подобными проектами, в особенности по модели опенсорс.
Делимся нашим решением и опытом работы над проектом.
Спойлер, немного технических деталей.
IONDV. Framework
IONDV. Framework – опенсорс фреймворк на node.js по созданию высокоуровневых веб-приложений на основе метаданных, что не требует серьезных навыков программирования.
Основу функциональности приложения составляет реестр данных — модуль Регистри. Это ключевой модуль, предназначенный непосредственно для работы с данными на основе структур метаданных – в том числе по ведению проектов, программ, мероприятий и др. Также в проекте используется модуль портала для отображения произвольных шаблонов данных – на нем реализован фронт реестра архивных дел.
Для СУБД используется MongoDb — в ней хранятся и настройки приложения, метаданные и сами данные.
Основу функциональности приложения составляет реестр данных — модуль Регистри. Это ключевой модуль, предназначенный непосредственно для работы с данными на основе структур метаданных – в том числе по ведению проектов, программ, мероприятий и др. Также в проекте используется модуль портала для отображения произвольных шаблонов данных – на нем реализован фронт реестра архивных дел.
Для СУБД используется MongoDb — в ней хранятся и настройки приложения, метаданные и сами данные.
В ходе разработки мы создали веб-приложение, с корпоративным названием War archive — для хранения, группировки и демонстрации архивных документов о Великой Отечественной войне. Мы активно работали с января по март 2018 года и в процессе исправляли баги фреймворка – так как опыт работы с таким количеством сканов у нас был первый.
Результатом работы проекта «Вспомнить каждого» стал реестр данных с 25к записей (сейчас уже 35к). В апреле этого года Дальневосточный центр социальных технологий опубликовал исходный код приложения под лицензией GPLv3 на GitHub. В репозитории вы найдете метаданные, шаблоны оформления и специальные утилиты – всё то, что составляет основу приложения для IONDV. Framework. Сам фреймворк распространяется под лицензией Apache 2.0 и также доступен на GitHub, вместе с готовыми модулями.
Также развернуто демо приложения. Тестовый запрос для поиска «Иванов Иван». Можно посмотреть и бэкофис по ссылке. Логин – demo, пароль — ion-demo. Кстати можно получить и готовый докер образ.
Подробнее о проекте
Цель проекта «Вспомнить каждого» сохранить память о людях времен ВОВ, предоставив безвозмездный доступ к документам тех лет. Мария Степко, директор Дальневосточного центра социальных технологий как-то сказала: «Сохранение и анализ полученных данных о прошлом – это задача, необходимая для моделирования будущего».
Добровольцы проекта оцифровали 10 тыс. страниц документов и внесли данные в реестр о дальневосточниках, участниках Великой Отечественной войны. В базе можно найти информацию о звании призванного, о части, дате, причине смерти и месте захоронения. Кроме того, доступен оцифрованный источник записи с указанием номера описи, дела, листа в соответствии с нумерацией государственного архива. Пример скана документа.
Мы очень благодарны за эту возможность и за отзыв о нашей работе:
«Техническое решение, созданное дальневосточной компанией-разработчиком IONDV уходит в свободное распространение. Система подходит НКО, инициативным гражданам, музеям, архивам. Поможет сэкономить ресурсы и сделать доброе дело для людей. Программисты нашего региона знают, что такое «свободное ПО». Сообща, мы сделаем это ПО более функциональным.
Результат развертывания и тестирования
Вчера мы закончили перенос проекта на Яндекс. Облако и сделали доступным по новому адресу dvarchive.ru.
Заодно провели нагрузочное тестирование, о чем тоже хотели бы поделиться.
Ресурсы сервера минимальные, так как он оплачивается за счет фаундрайзинговой компании: 2 CPU с 20% приоритетом и 2Gb памяти.
Типовая реакция на небольшую нагрузку выглядит так – 2% загрузки CPU и 36% загрузки памяти.
Мы провели тестирование запросов пользователей без статичных файлов, только запросы на данные и результат нам понравился.
Получилось, что приложение в докер контейнере обрабатывает 400 запросов в секунду (без статики). И при этом нагружает только один процессор, что характерно при запуске только одной инстанции node.js. Второй обрабатывает остальные задачи (СУБД, nginx, мониторинг).
Даже не нужна кластеризация. Для режима обычной нагрузки социального проекта имеется большой запас, несмотря на минимум ресурсов.
Итог
Для нас это был первый опыт участия в работе над проектом, связанным с памятью о Великой Отечественной войне, о дальневосточниках.
Тем более мы гордимся тем, что этим результатом, разработанным на Дальнем Востоке – регионе не очень активном в области ИТ, может воспользоваться любой, кто занимается подобными проектами, в особенности по модели опенсорс.

