
Если какой-то из ваших проектов использует данные хранящиеся в Ажуровской базе, то вполне возможно, что у вас есть возможность задействовать поиск по данным с помощью Azure search. Совершать поиск можно не только по базам (Azure Cosmos DB, Azure SQL Database, SQL Server hosted in an Azure VM), но и по Blob (Azure Blob Storage, Azure Table Storage).
У Search имеется бесплатный тариф, который позволяет создать до трех индексов общим размером до 50 Mb. Бесплатный тариф не обладает возможностями балансировки нагрузки, но вполне себе пригоден для использования.
Разобраться с поиском мне показалось довольно просто (хоть и не всегда все очевидно). Есть 3 типа объектов: datasource, index и indexer. Главным объектом, пожалуй, является index. Именно он отвечает за то как искать и что именно искать. Datasource это подключение к данным, а indexer это job который обновляет данные index.
UI интерфейс портала позволяет импортировать данные и создать все три объекта. Мимоходом будет возможность и добавить к поиску когнитивные возможности. Если база данных SQL находится в подписке, то ее можно выбрать при создании datasource. Хотя пароль почему-то все-равно приходится ввести. Если вы захотите использовать Cosmos DB, то строку подключения вам необходимо будет ввести вручную. Не забудьте указать в строке и базу данных, добавив в конце строки Database=ИМЯ_ВАШЕЙ_БАЗЫ
После выбора источника данных вам будет предложено использовать возможности когнитивного поиска. Набор дефолтных скиллов пока что довольно небольшой: можно определять язык, извлекать имена, названия организаций, мест и ключевые фразы. Еще есть интересная возможность определить характер текста на положительные или отрицательные эмоции с помощью sentiment detection. Этот скилл должно быть удобно использовать с отзывами на товары в интернет-магазинах. Имеется возможность и создать свой скилл используя описание API.

Для файлов загруженных в blob возможно использование OCR (Optical Character Recognition). Возможно распознавание рукописного (пока что только английского языка) и печатного текста. С помощью когнитивных сервисов возможно определение различных объектов на фото. Например, известных мест или знаменитостей.
Следующим этапом идет создание индекса. Единственным на текущий день вариантом Search mode является «analyzingInfixMatching»
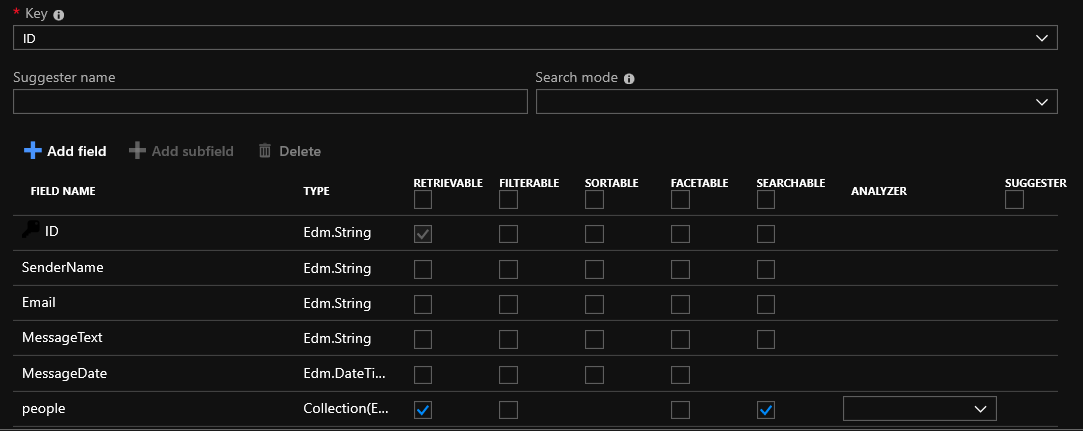
На этом этапе вы можете расставить галочки напротив полей вашей таблицы или добавить какое-то новое поле в индекс. На всякий случай объясню возможности полей:
Retrievable – поле будет присутствовать в результатах поиска
Filterable – значение поля можно будет отфильтровать
Sortable – можно отсортировать результат по этому полю
Facetable – своеобразная группировка по определенным признакам. Например с помощью следующего выражения facet=listPrice,values:10|25|100|500|1000|2500 можно получить следующую разбивку результатов по группам

Searchable – по этому полю будет вестись поиск
Поле Analyzer предлагает выбрать анализатор для различных языков. Используются 2 версии – Lucene и Microsoft. Для того чтобы понять в чем разница необходимо разобраться в чем разница между двумя следующими терминами:
Сте́мминг — это процесс нахождения основы слова для заданного исходного слова. Stem (англ.) – основа, стебель, происхождение. Стемминг использует алгоритмы. Зачастую обрезает слова удаляя суффиксы и окончания, получая основу слова.
Лемматиза́ция — процесс приведения словоформы к лемме — её нормальной (словарной) форме. Лемма — каноническая, основная форма слова. Лемматизация использует поиск по словарям содержащим различные формы слов.
Lucene анализатор использует стемминг. Microsoft анализатор использует лемматизацию.
По умолчанию, если ничего не выбрано используется Lucene. Но если вы ищете по данным на каком-то определенном языке, то несомненно лучше использовать анализатор для этого языка.
Suggester – позволяет по начальным буквам поиска выдать подсказки с документами содержащими введеный текст.
При использовании suggester в Azure Search в клиентском приложении у вас будет 2 варианта его использования: сам suggester или autocomplete. Если коротко, то suggester предлагает полностью всю строку из поля таблицы, а autocomplete предлагает только завершить слово или выражение из пары слов. Лучше всего о различиях между режимами suggester и autocomplete расскажет следующий артикул: Autocomplete in Azure Search now in public preview В этом артикуле очень наглядные гифки.
На этапе создания indexer необходимо указать high watermark column. Это поле которое изменяется при каждом изменении записи. Обычно это что-то вроде поля с датой последнего изменения или поля _ts в Cosmos DB. При индексации, в случае если значение поля изменено, то изменится и индекс.
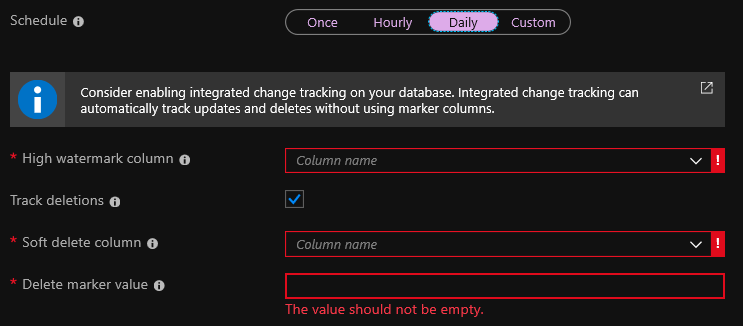
Track deletions это вариант удалять записи из индекса автоматически. Но для этого у вас в базе данных должен быть настроен soft delete. Если у вас используется soft delete, то при удалении записи она не удаляется, а просто помечается как удаленная. Стандартным вариантом предлагается добавить в базу поле isDeleted и задавать ему значение true, в случае если запись удалена.
Альтернативно можно при каждом удалении записи из базы отправлять запрос на удаление из поиска к API Azure Search. В этом случае галочку Trak deletions можно не ставить. Но мне такой вариант не особо нравится, так как если запрос на удаление не отработает, то запись останется в индексе. Как по мне, не хватает возможности перестраивать индекс раз в определенный промежуток времени полностью.
Несмотря на все удобства портала, после создания вы сможете добавить какие-то новые поля в индекс, но изменить существующие уже у вас не получится. Что же делать если нужно что-то изменить? Можно пересоздать индекс. Удалить существующий и создать новый содержащий необходимые изменения. Делать это с помощью портала довольно муторное занятие. Я использую для этих целей API. С помощью приложения вроде Postman можно получить JSON индекса и использовать его для написания запроса создания индекса. Необходимо лишь сделать небольшие изменения (например, убрать системные поля "@odata.context" и "@odata.etag").
Для того чтобы работать с API необходимо взять с портала ключ, который должен быть добавлен в заголовок каждого API запроса. Ключ берется здесь:
Запрос для получения данных индекса такой:
GET https://[service name].search.windows.net/indexes/[index name]?api-version=[api-version]
В заголовок необходимо добавить api-key: [admin key]
Создание индекса возможно с помощью одного из двух следующих запросов:
POST https://[servicename].search.windows.net/indexes?api-version=[api-version] Content-Type: application/json api-key: [admin key]
или
PUT https://[servicename].search.windows.net/indexes/[index name]?api-version=[api-version]
В body необходимо указать JSON с содержимым индекса. Последней версией на данный момент является 2019-05-06, а до нее долгое время использовалась 2017-11-11
Работая через API вы сможете использовать какие-то возможности поиска, которые отсутствуют на портале.
Для того чтобы дать каким-то полям приоритет при поиске можно использовать scoring profiles.
Следующий JSON, добавленный в запрос дает полю «title» двойное преимущество над полем «info»:
"scoringProfiles": [ { "name": "profileForTitle", "document": { "weights": { "title": 2, “info": 1 } } ]
Кроме возможности дать каким-то полям приоритет с помощью weights, имеется возможность использовать какие-то предопределенные функции: freshness, magnitude, distance, и tag.
Freshness используется только с полями DateTime и позволяет поднять в поиске последние записи. Magnitude используется с полями int и double. Ну и соответственно, эту функцию хорошо использовать с полями хранящими цены, количество скачиваний и другую числовую информацию. Distance используется только с полями типа Edm.GeographyPoint и поднимают в поиске по расстоянию от определенной локации. В случае если типом функции указан tag, то в поиске поднимутся документы содержащие тэги, которые присутствуют в строке поиска.
Один из самых популярных вариантов – поднять в поиске последние документы выглядит так:
"scoringProfiles": [{ "name":"newDocs", "functions": [ { "type": "freshness", "fieldName": "documentDate", "boost": 10, "interpolation": "quadratic", "freshness": { "boostingDuration": "P7D" } } ] } ]
Документы, у которых поле documentDate содержит дату последних семи дней ("P7D") будут подняты вверх.
После того как вы создали scoring profile, вы можете указывать в запросах его имя. Только в этом случае нужные поля будут подняты в поиске.
Подробнее читайте в официальной документации: Add scoring profiles to an Azure Search index
Data Change Detection Policy
API предоставляет чуть больше возможностей и для datasource. Как вы могли прочитать выше, при создании datasource можно указать поле по изменению которого будет определяться изменились ли данные. В виде JSON это выглядит так:
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy", "highWaterMarkColumnName" : "[a rowversion or last_updated column name]" } Но для идентификации удаленного поля при использовании soft delete необходимо добавлять еще одно policy: "dataDeletionDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" }
Если вы используете SQL Server и ваша база поддерживает Change Tracking, то удаленные записи могут удаляться из индекса автоматически. Указывать highWaterMarkColumnName в этом случае не потребуется. Достаточно указать SqlIntegratedChangeTrackingPolicy вместо HighWaterMarkChangeDetectionPolicy
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SqlIntegratedChangeTrackingPolicy" }
Это очень удобно. Но есть нюансы, которые не дают насладится этой фичей полностью.
Во-первых, SqlIntegratedChangeTrackingPolicy нельзя использовать с views. Во-вторых, в таблице не должно быть композитных первичных ключей. Само-собой разумеется, что версия SQL Server-а должна быть более-менее новой. Ну и, наконец, для базы данных и используемых поиском таблиц должен быть включен Change Tracking. Для базы включается он так:
ALTER DATABASE AdventureWorks2012 SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
А для таблицы так:
ALTER TABLE Person.Contact ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
Но это не все. Очень рекомендуется включить для базы snapshot isolation.
ALTER DATABASE AdventureWorks2012 SET ALLOW_SNAPSHOT_ISOLATION ON;
Кроме плясок с бубном при установке Change Traсking для базы данных для меня минусом является еще и невозможность использования views. Так что я все-таки как правило вынужденно использую HighWaterMarkChangeDetectionPolicy
Поиск по данным
По умолчанию Azure search использует simple query syntax. Как это не казалось бы удивительным, но он довольно простой:
wifi+luxury ищет слова wifi и luxury одновременно
"luxury hotel" ищет фразу
wifi | luxury ищет или слово wifi или слово luxury
wifi –luxury ищет тексты со словом wifi но без слова luxury
lux ищет слова, которые начинаются с lux
Вполне можно комбинировать правила поиска используя скобки. Например, правило motel+(wifi | luxury) ищет слово motel и либо слово wifi либо слово luxury
Приятно, что Azure Search может использовать синтаксис Lucene. Для того чтобы использовался именно он, необходимо добавить в запрос поиска queryType=full
Отличие Azure-овского от классического Lucene синтаксиса только в отсутствии range.
Вот так в Azure Search нельзя: mod_date:[20020101 TO 20030101]
Зато в Azure Search можно использовать $filter с синтаксисом ODATA. Вот пример фильтра:
{ "name": "Scott", "filter": "(age ge 25 and and lt 50) or surname eq 'Guthrie'" }
Фильтры можно использовать также и с simple query syntax.
В Lucene логика «или» реализуется с помощью OR или ||
Оба значения можно найти, указав инструкцию «и» с помощью: AND, && или +
Для «не» можно использовать что-то из следующего: NOT, ! или –
Инструкция «не» имеет общую особенность и для simple syntax и для Lucene. Ее поведение зависит от режима поиска, который может быть установлен как в searchMode=all, так и в searchMode=any (по умолчанию используется это значение). В режиме any поиск wifi -luxury найдет документы со словом wifi или документы без слова luxury. В режим all по тому же запросу найдет доки со словом wifi и одновременно без слова luxury.
Давайте рассмотрим какие-то интересные возможности Lucene.
Fuzzy search позволяет искать слова, которые отличаются от искомого на одну или несколько букв. То есть помогает бороться с опечатками. Например, поиск по "blue~" или "blue~1" вернет вам и "blue" и "blues" и даже "glue". Но при этом поиск по "business~analyst" будет означать business или analyst
Proximity позволяет искать слова которые расположены рядом. Например, "hotel airport"~5 найдет слова "hotel" и "airport" которые располагаются в тексте не дальше чем в 5 слов друг от друга.
Term boosting позволяет задать приоритет какому-то слову в поиске. Пример: "rock^2 electronic" ищет слова rock и electronic, но записи со словом rock в поиске будут отображены выше.
Regular expressions – использование регулярных выражений. Здесь все в соответствии с официальной документацией Lucene по регулярным выражениям. Найти ее можно по следующей сылке. При поиске регулярные выражения необходимо размещать между прямыми слешами "/". Например, вот так: /[mh]otel/
Если ваша строка поиска содержит специальные символы, то они должны быть экранированы с помощью обратного слеша. Пример символов, которые необходимо экранировать: + — && ||! ( ) { } [ ] ^ " ~ * ? : \ /
Поиск можно совершить с помощью GET запроса. Официальный пример такой:
GET /indexes/hotels/docs?search=category:budget AND \"recently renovated\"^3&searchMode=all&api-version=2019-05-06&querytype=full
Но можно использовать и POST запрос с body. Опять же официальный пример:
POST /indexes/hotels/docs/search?api-version=2019-05-06 { "search": "category:budget AND \"recently renovated\"^3", "queryType": "full", "searchMode": "all" }
Если вы используете GET запрос или POST с типом данных application/x-www-form-urlencoded, то вам необходимо энкодировать unsafe и reserved символы.
Символы ; /?: @ = & являются зарезервированными
Символы " ` < > # % { } | \ ^ ~ [ ] являются unsafe.
Например, символ # станет %23 а символ ? станет %3F
Пара ссылок для разработчиков.
Если в .NET разработчик, то вы можете использовать NuGet пакет Microsoft.Azure.Search Кроме того, имеются примеры на NodeJS и Java.
Пример простого приложения на .NET Core вы можете найти тут ASP.NET Core Azure search sample

